PyTorch:view() 与 reshape() 区别详解
1、PyTorch张量存储的底层原理
tensor数据采用头信息区(Tensor)和存储区 (Storage)分开存储的形式,如图1所示。变量名以及其存储的数据是分为两个区域分别存储的。比如,我们定义并初始化一个tensor,tensor名为A,A的形状size、步长stride、数据的索引等信息都存储在头信息区,而A所存储的真实数据则存储在存储区。另外,如果我们对A进行截取、转置或修改等操作后赋值给B,则B的数据共享A的存储区,存储区的数据数量没变,变化的只是B的头信息区对数据的索引方式。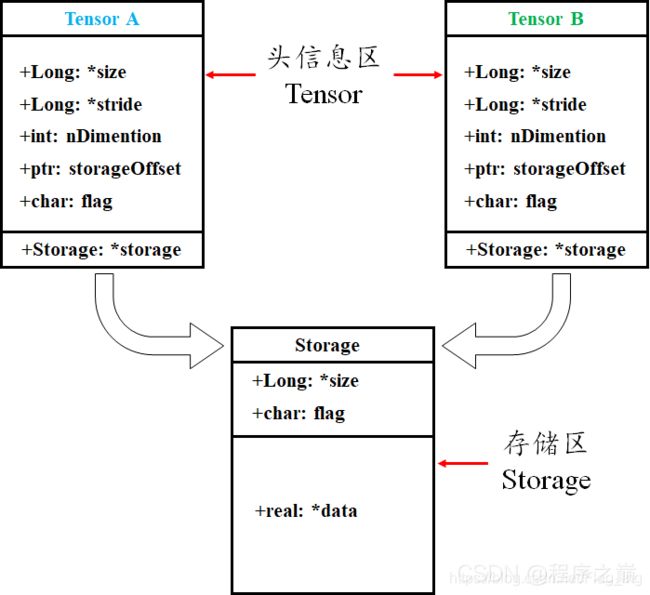
图1 Torch中Tensor的存储结构
举个例子:
import torch
a = torch.arange(5) # 初始化张量 a 为 [0, 1, 2, 3, 4]
b = a[2:] # 截取张量a的部分值并赋值给b,b其实只是改变了a对数据的索引方式
print('a:', a)
print('b:', b)
print('ptr of storage of a:', a.storage().data_ptr()) # 打印a的存储区地址
print('ptr of storage of b:', b.storage().data_ptr()) # 打印b的存储区地址,可以发现两者是共用存储区
print('==================================================================')
b[1] = 0 # 修改b中索引为1,即a中索引为3的数据为0
print('a:', a)
print('b:', b)
print('ptr of storage of a:', a.storage().data_ptr()) # 打印a的存储区地址,可以发现a的相应位置的值也跟着改变,说明两者是共用存储区
print('ptr of storage of b:', b.storage().data_ptr()) # 打印b的存储区地址
''' 运行结果 '''
a: tensor([0, 1, 2, 3, 4])
b: tensor([2, 3, 4])
ptr of storage of a: 2862826251264
ptr of storage of b: 2862826251264
==================================================================
a: tensor([0, 1, 2, 0, 4])
b: tensor([2, 0, 4])
ptr of storage of a: 2862826251264
ptr of storage of b: 28628262512642、PyTorch张量的步长(stride)属性
tensor的步长可以理解为从每个轴上或者维度上从一个元素跨到相邻元素所跨越基本shape的个数。为方便理解,就直接用图1说明了,您细细品(^-^):
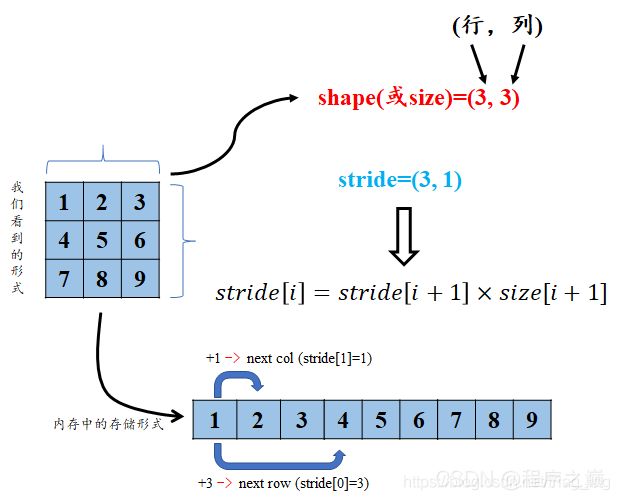
图2 对张量的stride属性的理解
举个例子:
import torch
a = torch.arange(6).reshape(2, 3) # 初始化张量 a
b = torch.arange(6).view(3, 2) # 初始化张量 b
print('a:', a)
print('stride of a:', a.stride()) # 打印a的stride
print('b:', b)
print('stride of b:', b.stride()) # 打印b的stride
''' 运行结果 '''
a: tensor([[0, 1, 2],
[3, 4, 5]])
stride of a: (3, 1)
b: tensor([[0, 1],
[2, 3],
[4, 5]])
stride of b: (2, 1)二、对“视图(view)”字眼的理解
视图是数据的一个别称或引用,通过该别称或引用亦便可访问、操作原有数据,但原有数据不会产生拷贝。如果我们对视图进行修改,它会影响到原始数据,物理内存在同一位置,这样避免了重新创建张量的高内存开销。由上面介绍的PyTorch的张量存储方式可以理解为:对张量的大部分操作就是视图操作!
与之对应的概念就是副本。副本是一个数据的完整的拷贝,如果我们对副本进行修改,它不会影响到原始数据,物理内存不在同一位置。
有关视图与副本,在NumPy中也有着重要的应用。可参考这里。
三、view() 和reshape() 的比较
1、对 torch.Tensor.view() 的理解
定义:
view(*shape) → Tensor
作用:类似于reshape,将tensor转换为指定的shape,原始的data不改变。返回的tensor与原始的tensor共享存储区。返回的tensor的size和stride必须与原始的tensor兼容。每个新的tensor的维度必须是原始维度的子空间,或满足以下连续条件:

式1 张量连续性条件
否则需要先使用contiguous()方法将原始tensor转换为满足连续条件的tensor,然后就可以使用view方法进行shape变换了。或者直接使用reshape方法进行维度变换,但这种方法变换后的tensor就不是与原始tensor共享内存了,而是被重新开辟了一个空间。
如何理解tensor是否满足连续条件呐?下面通过一系列例子来慢慢理解下:
首先,我们初始化一个张量 a ,并查看其stride、storage等属性:
import torch
a = torch.arange(9).reshape(3, 3) # 初始化张量a
print('struct of a:\n', a)
print('size of a:', a.size()) # 查看a的shape
print('stride of a:', a.stride()) # 查看a的stride
''' 运行结果 '''
struct of a:
tensor([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
size of a: torch.Size([3, 3])
stride of a: (3, 1) # 注:满足连续性条件把上面的结果带入式1,可以发现满足tensor连续性条件。
我们再看进一步处理——对a进行转置后的结果:
import torch
a = torch.arange(9).reshape(3, 3) # 初始化张量a
b = a.permute(1, 0) # 对a进行转置
print('struct of b:\n', b)
print('size of b:', b.size()) # 查看b的shape
print('stride of b:', b.stride()) # 查看b的stride
''' 运行结果 '''
struct of b:
tensor([[0, 3, 6],
[1, 4, 7],
[2, 5, 8]])
size of b: torch.Size([3, 3])
stride of b: (1, 3) # 注:此时不满足连续性条件将a转置后再看最后的输出结果,带入到式1中,是不是发现等式不成立了?所以此时就不满足tensor连续的条件了。这是为什么那?我们接着往下看:
首先,输出a和b的存储区来看一下有没有什么不同:
import torch
a = torch.arange(9).reshape(3, 3) # 初始化张量a
print('ptr of storage of a: ', a.storage().data_ptr()) # 查看a的storage区的地址
print('storage of a: \n', a.storage()) # 查看a的storage区的数据存放形式
b = a.permute(1, 0) # 转置
print('ptr of storage of b: ', b.storage().data_ptr()) # 查看b的storage区的地址
print('storage of b: \n', b.storage()) # 查看b的storage区的数据存放形式
''' 运行结果 '''
ptr of storage of a: 2767173747136
storage of a:
0
1
2
3
4
5
6
7
8
[torch.LongStorage of size 9]
ptr of storage of b: 2767173747136
storage of b:
0
1
2
3
4
5
6
7
8
[torch.LongStorage of size 9]由结果可以看出,张量a、b仍然共用存储区,并且存储区数据存放的顺序没有变化,这也充分说明了b与a共用存储区,b只是改变了数据的索引方式。那么为什么b就不符合连续性条件了呐(T-T)?其实原因很简单,我们结合图3来解释下:
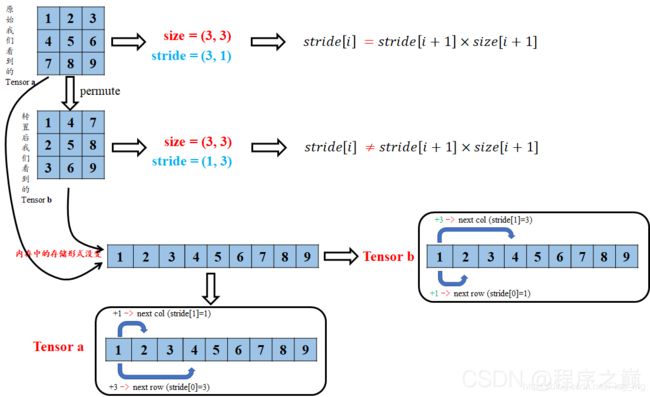
图3 对张量连续性条件的理解
转置后的tensor只是对storage区数据索引方式的重映射,但原始的存放方式并没有变化.因此,这时再看tensor b的stride,从b第一行的元素1到第二行的元素2,显然在索引方式上已经不是原来+1了,而是变成了新的+3了,你在仔细琢磨琢磨是不是这样的(^-^)。所以这时候就不能用view来对b进行shape的改变了,不然就报错咯,不信你看下面;
import torch
a = torch.arange(9).reshape(3, 3) # 初始化张量a
print(a.view(9))
print('============================================')
b = a.permute(1, 0) # 转置
print(b.view(9))
''' 运行结果 '''
tensor([0, 1, 2, 3, 4, 5, 6, 7, 8])
============================================
Traceback (most recent call last):
File "此处打码", line 23, in
print(b.view(9))
RuntimeError: view size is not compatible with input tensor's size and stride (at least one dimension spans across two contiguous subspaces). Use .reshape(...) instead. 但是嘛,上有政策下有对策,这种情况下,直接用view不行,那我就先用contiguous()方法将原始tensor转换为满足连续条件的tensor,在使用view进行shape变换,值得注意的是,这样的原理是contiguous()方法开辟了一个新的存储区给b,并改变了b原始存储区数据的存放顺序!同样的例子:
import torch
a = torch.arange(9).reshape(3, 3) # 初始化张量a
print('storage of a:\n', a.storage()) # 查看a的stride
print('+++++++++++++++++++++++++++++++++++++++++++++++++')
b = a.permute(1, 0).contiguous() # 转置,并转换为符合连续性条件的tensor
print('size of b:', b.size()) # 查看b的shape
print('stride of b:', b.stride()) # 查看b的stride
print('viewd b:\n', b.view(9)) # 对b进行view操作,并打印结果
print('+++++++++++++++++++++++++++++++++++++++++++++++++')
print('storage of a:\n', a.storage()) # 查看a的存储空间
print('storage of b:\n', b.storage()) # 查看b的存储空间
print('+++++++++++++++++++++++++++++++++++++++++++++++++')
print('ptr of a:\n', a.storage().data_ptr()) # 查看a的存储空间地址
print('ptr of b:\n', b.storage().data_ptr()) # 查看b的存储空间地址
''' 运行结果 '''
storage of a:
0
1
2
3
4
5
6
7
8
[torch.LongStorage of size 9]
+++++++++++++++++++++++++++++++++++++++++++++++++
size of b: torch.Size([3, 3])
stride of b: (3, 1)
viewd b:
tensor([0, 3, 6, 1, 4, 7, 2, 5, 8])
+++++++++++++++++++++++++++++++++++++++++++++++++
storage of a:
0
1
2
3
4
5
6
7
8
[torch.LongStorage of size 9]
storage of b:
0
3
6
1
4
7
2
5
8
[torch.LongStorage of size 9]
+++++++++++++++++++++++++++++++++++++++++++++++++
ptr of a:
1842671472000
ptr of b:
18426714721282、对 torch.reshape() 的理解
定义:
torch.reshape(input, shape) → Tensor
作用:与view方法类似,将输入tensor转换为新的shape格式。
但是reshape方法更强大,可以认为a.reshape = a.view() + a.contiguous().view()。
即:在满足tensor连续性条件时,a.reshape返回的结果与a.view()相同,否则返回的结果与a.contiguous().view()相同。
不信你就看人家官方的解释嘛,您在细细品:
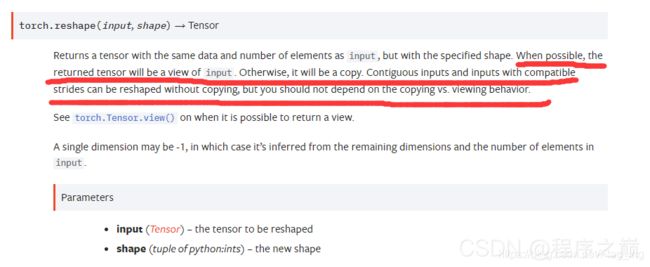
关于两者区别,还可以参考这个链接:
https://stackoverflow.com/questions/49643225/whats-the-difference-between-reshape-and-view-in-pytorch
2021.03.30更新:最近又发现了pytorch官网对view及reshape原理的阐述,说的很清晰明了,大家可以参考下:
https://pytorch.org/docs/stable/tensor_view.html
放一张该网站上的截图:

四、总结
torch的view()与reshape()方法都可以用来重塑tensor的shape,区别就是使用的条件不一样。view()方法只适用于满足连续性条件的tensor,并且该操作不会开辟新的内存空间,只是产生了对原存储空间的一个新别称和引用,返回值是视图。而reshape()方法的返回值既可以是视图,也可以是副本,当满足连续性条件时返回view,否则返回副本[ 此时等价于先调用contiguous()方法在使用view() ]。因此当不确能否使用view时,可以使用reshape。如果只是想简单地重塑一个tensor的shape,那么就是用reshape,但是如果需要考虑内存的开销而且要确保重塑后的tensor与之前的tensor共享存储空间,那就使用view()。
参考链接:
- https://blog.csdn.net/Flag_ing/article/details/109129752
- https://stackoverflow.com/questions/49643225/whats-the-difference-between-reshape-and-view-in-pytorch