聊天机器人(chatbot)终极指南:自然语言处理(NLP)和深度机器学习(Deep Machine Learning)
为了这份爱
在过去的几个月中,我一直在收集自然语言处理(NLP)以及如何将NLP和深度学习(Deep Learning)应用到聊天机器人(Chatbots)方面的最好的资料。
时不时地我会发现一个出色的资源,因此我很快就开始把这些资源编制成列表。 不久,我就发现自己开始与bot开发人员和bot社区的其他人共享这份清单以及一些非常有用的文章了。
在这个过程中,我的名单变成了一个指南,经过一些好友的敦促和鼓励,我决定和大家分享这个指南,或许是一个精简的版本 - 由于长度的原因。
这个指南主要基于Denny Britz所做的工作,他深入地探索了机器人开发中深度学习技术的利用。 文章中包含代码片段和Github仓,好好利用!
闲话不扯了…让我们开始吧!
概述:聊天机器人开发中的深度学习技术

聊天机器人是一个热门话题,许多公司都希望能够开发出让人无法分辨真假的聊天机器人,许多人声称可以使用自然语言处理(NLP)和深度学习(Deep Learning)技术来实现这一点。 但是人工智能(AI)现在吹得有点过了,让人有时候很难从科幻中分辨出事实。
在本系列中,我想介绍一些用于构建对话式代理(conversational agents)的深度学习技术,首先我会解释下,现在我们所处的位置,然后我会介绍下,哪些是可能做到的事情,哪些是至少在一段时间内几乎不可能实现的事情。
模型分类

基于检索的模型 VS. 生成式模型
基于检索的模型(retrieval-based model)更容易实现,它使用预定义响应的数据库和某种启发式推理来根据输入(input)和上下文(context)选择适当的响应(response)。 启发式推理可以像基于规则(rule based)的表达式匹配一样简单,或者像机器学习中的分类器集合(classifier ensemble)一样复杂。 这些系统不会产生任何新的文本,他们只是从固定的集合中选择一个响应。
成式模型(generative model)要更难一些,它不依赖于预定义的响应,完全从零开始生成新的响应。 生成式模型通常基于机器翻译技术,但不是从一种语言翻译到另一种语言,而是从输入到输出(响应)的“翻译”:
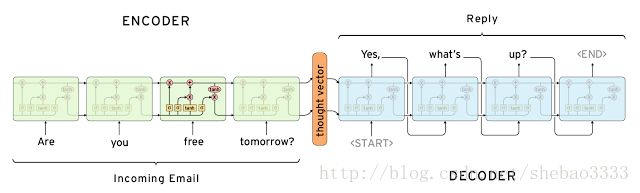
两种方法都有明显的优点和缺点。 由于使用手工打造的存储库,基于检索的方法不会产生语法错误。 但是,它们可能无法处理没有预定义响应的场景。 出于同样的原因,这些模型不能引用上下文实体信息,如前面提到的名称。 生成式模型更“更聪明”一些。 它们可以引用输入中的实体,给人一种印象,即你正在与人交谈。 然而,这些模型很难训练,而且很可能会有语法错误(特别是在较长的句子上),并且通常需要大量的训练数据。
深度学习技术既可以用于基于检索的模型,也可以用于生成式模型,但是chatbot领域的研究似乎正在向生成式模型方向发展。 像seq2seq这样的深度学习体系结构非常适合l来生成文本,研究人员希望在这个领域取得快速进展。 然而,我们仍然处于建立合理、良好的生成式模型的初期阶段。现在上线的生产系统更可能是采用了基于检索的模型。
对话的长短

对话越长,就越难实现自动化。 一种是短文本对话(更容易实现) ,其目标是为单个输入生成单个响应。 例如,你可能收到来自用户的特定问题,并回复相应的答案。 另一种是很长的谈话(更难实现) ,谈话过程会经历多个转折,需要跟踪之前说过的话。 客户服务中的对话通常是涉及多个问题的长时间对话。
开放领域 VS. 封闭领域
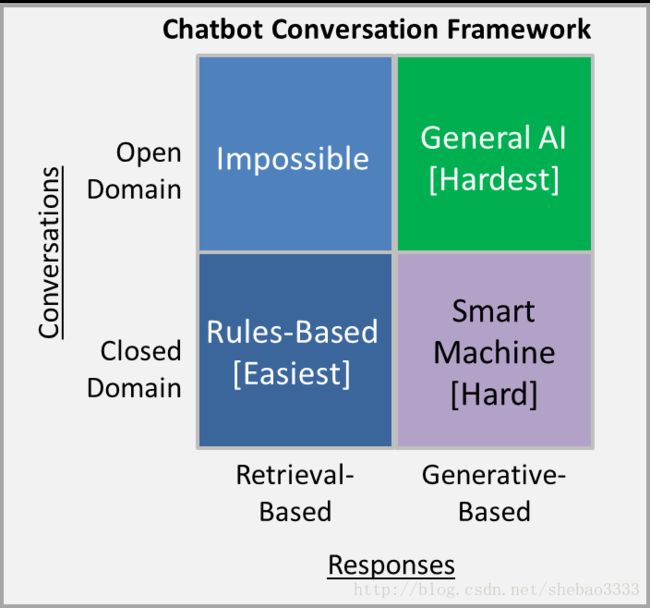
开放领域的chatbot更难实现,因为用户 不一定有明确的目标或意图。 像Twitter和Reddit这样的社交媒体网站上的对话通常是开放领域的 - 他们可以谈论任何方向的任何话题。 无数的话题和生成合理的反应所需要的知识规模,使得开放领域的聊天机器人实现相当困难。
“开放领域 :可以提出一个关于任何主题的问题,并期待相关的回应,这很难实现。考虑一下,如果就抵押贷款再融资问题进行交谈的话,实际上你可以问任何事情“ —— 马克·克拉克
封闭领域的chatbot比较容易实现,可能的输入和输出的空间是有限的,因为系统试图实现一个非常特定的目标。 技术支持或购物助理是封闭领域问题的例子。 这些系统不需要谈论政治,只需要尽可能有效地完成具体任务。 当然,用户仍然可以在任何他们想要的地方进行对话,但系统并不需要处理所有这些情况 - 用户也不期望这样做。
“封闭领域 :可以问一些关于特定主题的有限的问题,更容易实现。比如,迈阿密天气怎么样?“
“Square 1迈出了一个聊天机器人的可喜的第一步,它表明了可能不需要智能机器的复杂性,也可以提供商业和用户价值。
”Square 2使用了可以生成响应的智能机器技术。 生成的响应允许Chatbot处理常见问题和一些不可预见的情况,而这些情况没有预定义的响应。 智能机器可以处理更长的对话并且看起来更像人。 但是生成式响应增加了系统的复杂性,而且往往是增加了很多的复杂性。
我们现在在客服中心解决这个问题的方法是,当有一个无法预知的情况时,在自助服务中将没有预定义的回应 ,这时我们会把呼叫传递给一个真人“ Mark Clark
共同的挑战
在构建聊天机器人时,有一些挑战是显而易见的,还有一些则不那么明显,这些挑战中的大部分都是现在很活跃的研究领域。
使用上下文信息

为了产生明智的反应,系统可能需要结合语言上下文和实物上下文 。 在长时间的对话中,人们会跟踪说过的内容以及所交换的信息。上图是使用语言上下文的一个例子。最常见的实现方法是将对话嵌入到向量(vector)中,但是长时间的对话对这一技术带来了挑战。两个相关的论文:“使用生成式层级神经网络模型构建端到端的对话系统”以及“在神经网络对话模型中使用有目的的注意力”,都在朝着这个方向发展。此外,还可能需要在上下文中合并其他类型的数据,例如日期/时间,位置或关于用户的信息。
一致的个性

理想情况下,当生成响应时代理应当对语义相同的输入产生一致的答案。 例如,对于这两个问题:“你几岁了?”和“你的年龄是?”,你会期望得到同样的回答。 这听起来很简单,但是如何将这种固定的知识或者说“个性”纳入到模型里,还是一个需要研究的问题。许多系统学可以生成语言上合理的响应,但是它们的训练目标并不包括产生语义一致的反应。 通常这是因为它们接受了来自多个不同用户的大量数据的训练。 类似于论文“基于角色的神经对话模型”中的模型,正在向为个性建模的方向迈出第一步。 
模型的评估
评估聊天代理的理想方法是衡量是否在给定的对话中完成其任务,例如解决客户支持问题。 但是这样的标签(label)的获取成本很高,因为它们需要人为的判断和评估。有时候没有良好定义的目标,就像在开放领域域的模型一样。通用的衡量指标,如BLEU, 最初是用于机器翻译的,它基于文本的匹配,因此并不是特别适合于对话模型的衡量,因为一个明智的响应可能包含完全不同的单词或短语。 事实上,在论文“ 对话响应生成的无监督评估指标的实证研究”中,研究人员发现,没有任何常用指标与人类的判断具有真正相关性。

意图和多样性
生成式系统的一个常见问题是,它们往往会生成一些类似于“很棒!”或“我不知道”之类的没有营养的响应,这些响应可以应对很多输入。 谷歌智能答复的早期版本倾向于用“我爱你”来回应几乎任何事情。这一现象的部分根源在于这些系统是如何训练的,无论是在数据方面还是在实际的训练目标和算法方面。 一些研究人员试图通过各种目标函数(Object function)来人为地促进多样性 。 然而,人类通常会产生特定于输入的反应并带有意图。 因为生成式系统(特别是开放域系统)没有经过专门的意图训练,所以缺乏这种多样性。
现在能实现到什么程度?
基于目前所有前沿的研究,我们现在处于什么阶段,这些系统的实际工作情况到底怎么样? 再来看看我们的模型分类。 基于检索的开放领域系统显然是不可能实现的,因为你永远不可能手工制作足够的响应来覆盖所有的情况。 生成式的开放域系统几乎是通用人工智能(AGI:Artificial General Intelligence),因为它需要处理所有可能的场景。 我们离这个的实现还很远(但是在这个领域正在进行大量的研究)。
这就给我们剩下了一些限定领域的问题,在这些领域中,生成式和基于检索的方法都是合适的,对话越长,情境越重要,问题就越困难。
(前)百度首席科学家Andrew Ng 最近接受采访时说:
现阶段深度学习的大部分价值可以体现在一个可以获得大量的数据的狭窄领域。 下面是一个它做不到的例子:进行一个真正有意义的对话。 经常会有一些演示,利用一些精挑细选过的对话,让它看起来像是在进行有意义的对话,但如果你真的自己去尝试和它对话,它就会很快地偏离正常的轨道。
许多公司开始将他们的聊天外包给人力工作者,并承诺一旦他们收集了足够的数据就可以“自动化”。 这只有在一个非常狭窄的领域运行时才会发生 - 比如说一个叫Uber的聊天界面。 任何开放的领域(比如销售电子邮件)都是我们目前无法做到的。 但是,我们也可以通过提出和纠正答案来利用这些系统来协助工作人员。 这更可行。
生产系统中的语法错误是非常昂贵的,因为它们可能会把用户赶跑。 这就是为什么大多数系统可能最好采用基于检索的方法,这样就没有语法错误和攻击性的反应。 如果公司能够以某种方式掌握大量的数据,那么生成式模型就变得可行 - 但是它们必须辅以其他技术,以防止它们像微软的Tay那样脱轨。
用TENSORFLOW实现一个基于检索的模型
本教程的代码和数据在Github上。
基于检索的博客
当今绝大多数的生产系统都是基于检索的,或者是基于检索的和生成式相结合。 Google的Smart Reply就是一个很好的例子。 生成式模型是一个活跃的研究领域,但我们还不能很好的实现。 如果你现在想构建一个聊天代理,最好的选择就是基于检索的模型。
UBUNTU DIALOG CORPUS
在这篇文章中,我们将使用Ubuntu对话语料库( 论文 , github )。 Ubuntu 对话语料库(UDC)是可用的最大的公共对话数据集之一。 它基于公共IRC网络上的Ubuntu频道的聊天记录。 论文详细说明了这个语料库是如何创建的,所以在这里我不再重复。 但是,了解我们正在处理的是什么样的数据非常重要,所以我们先做一些数据方面的探索。
训练数据包括100万个样例,50%的正样例(标签1)和50%的负样例(标签0)。 每个样例都包含一个上下文 ,即直到这一点的谈话记录,以及一个话语 (utterance),即对上下文的回应。 一个正标签意味着话语是对当前语境上下文的实际响应,一个负标签意味着这个话语不是真实的响应 - 它是从语料库的某个地方随机挑选出来的。 这是一些示例数据:

请注意,数据集生成脚本已经为我们做了一堆预处理 - 它使用NLTK工具对输出进行了分词(tokenize), 词干处理(stem)和词形 规范化(lemmatize) 。 该脚本还用特殊的标记替换了名称,位置,组织,URL和系统路径等实体(entity)。 这个预处理并不是绝对必要的,但它可能会提高几个百分点的性能。 上下文的平均长度是86字,平均话语长17字。 使用Jupyter notebook来查看数据分析 。
数据集拆分为测试集和验证集。 这些格式与训练数据的格式不同。 测试/验证集合中的每个记录都包含一个上下文,一个基准的真实话语(真实的响应)和9个不正确的话语,称为干扰项(distractors) 。 这个模型的目标是给真正的话语分配最高的分数,并调低错误话语的分数。
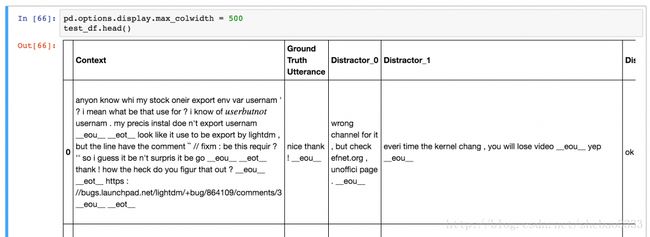
有多种方式可以用来评估我们的模型做得如何。 常用的衡量指标是k召回(recall@k ),它表示我们让模型从10个可能的回答中选出k个最好的回答(1个真实和9个干扰)。 如果正在选中的回答中包含正确的,我们就将该测试示例标记为正确的。 所以,更大的k意味着任务变得更容易。 如果我们设定k = 10,我们得到100%的召回,因为我们只有10个回答。 如果我们设置k = 1,模型只有一个机会选择正确的响应。
此时你可能想知道如何选择9个干扰项。 在这个数据集中,9个干扰项是随机挑选的。 然而,在现实世界中,你可能有数以百万计的可能的反应,你不知道哪一个是正确的。 你不可能评估一百万个潜在的答案,选择一个分数最高的答案 - 这个成本太高了。 Google的“ 智能答复”使用集群技术来提出一系列可能的答案,以便从中选择。 或者,如果你只有几百个潜在的回应,你可以对所有可能的回应进行评估。
基准
在开始研究神经网络模型之前,我们先建立一些简单的基准模型,以帮助我们理解可以期待什么样的性能。 我们将使用以下函数来评估我们的recall@ k指标:
-
def evaluate_recall(y, y_test, k=1): -
num_examples = float(len(y)) -
num_correct = 0 -
for predictions, label in zip(y, y_test): -
if label in predictions[:k]: -
num_correct += 1 -
return num_correct/num_examples
这里,y是我们按照降序排序的预测列表,y_test是实际的标签。 例如,[0,3,1,2,5,6,4,7,8,9]中的ay表示话语0得分最高,话语9得分最低。 请记住,对于每个测试样例,我们有10个话语,第一个(索引0)始终是正确的,因为我们数据中的话语列位于干扰项之前。
直觉是,一个完全随机的预测器也应该可以在recall@ 1指标上拿10分,在recall@2指标上得20分,依此类推。 让我们来看看是否是这种情况:
-
# Random Predictor -
def predict_random(context, utterances): -
return np.random.choice(len(utterances), 10, replace=False) -
# Evaluate Random predictor -
y_random = [predict_random(test_df.Context[x], test_df.iloc[x,1:].values) for x in range(len(test_df))] -
y_test = np.zeros(len(y_random)) -
for n in [1, 2, 5, 10]: -
print(“Recall @ ({}, 10): {:g}”.format(n, evaluate_recall(y_random, y_test, n)))
测试结果:
-
Recall @ (1, 10): 0.0937632 -
Recall @ (2, 10): 0.194503 -
Recall @ (5, 10): 0.49297 -
Recall @ (10, 10): 1
很好,看起来符合预期。 当然,我们不只是想要一个随机预测器。 原始论文中讨论的另一个基准模型是一个tf-idf预测器。 tf-idf代表“term frequency - inverse document frequency”,它衡量文档中的单词与整个语料库的相对重要性。 这里不阐述具体的的细节了(你可以在网上找到许多关于tf-idf的教程),那些具有相似内容的文档将具有类似的tf-idf向量。 直觉上讲,如果上下文和响应具有相似的词语,则它们更可能是正确的配对。 至少比随机更可能。 许多库(如scikit-learn 都带有内置的tf-idf函数,所以它非常易于使用。 现在,让我们来构建一个tf-idf预测器,看看它的表现如何。
-
class TFIDFPredictor: -
def __init__(self): -
self.vectorizer = TfidfVectorizer() -
def train(self, data): -
self.vectorizer.fit(np.append(data.Context.values, -
data.Utterance.values)) -
def predict(self, context, utterances): -
# Convert context and utterances into tfidf vector -
vector_context = self.vectorizer.transform([context]) -
vector_doc = self.vectorizer.transform(utterances) -
# The dot product measures the similarity of the resulting vectors -
result = np.dot(vector_doc, vector_context.T).todense() -
result = np.asarray(result).flatten() -
# Sort by top results and return the indices in descending order -
return np.argsort(result, axis=0)[::-1] -
# Evaluate TFIDF predictor -
pred = TFIDFPredictor() -
pred.train(train_df) -
y = [pred.predict(test_df.Context[x], test_df.iloc[x,1:].values) for x in range(len(test_df))] -
for n in [1, 2, 5, 10]: -
print(“Recall @ ({}, 10): {:g}”.format(n, evaluate_recall(y, y_test, n)))
运行结果:
-
Recall @ (1, 10): 0.495032 -
Recall @ (2, 10): 0.596882 -
Recall @ (5, 10): 0.766121 -
Recall @ (10, 10): 1
我们可以看到tf-idf模型比随机模型表现得更好。 尽管如此,这还不够完美。 我们所做的假设不是很好。 首先,响应不一定需要与上下文相似才是正确的。 其次,tf-idf忽略了词序,这可能是一个重要的改进信号。 使用一个神经网络模型,我们应该可以做得更好一点。
双编码器LSTM
我们将在本文中构建的深度学习模型称为双编码器LSTM网络(Dual Encoder LSTM Network)。 这种类型的网络只是可以应用于这个问题的众多网络之一,并不一定是最好的。 你可以尝试各种深度学习架构 - 这是一个活跃的研究领域。 例如,经常在机器翻译中使用的seq2seq模型在这个任务上可能会做得很好。 我们打算使用双编码器的原因是因为据报道 它在这个数据集上性能不错。 这意味着我们知道该期待什么,并且可以肯定我们的丝线代码是正确的。 将其他模型应用于这个问题将是一个有趣的项目。
我们将建立的双编码器LSTM看起来像这样( 论文 ): 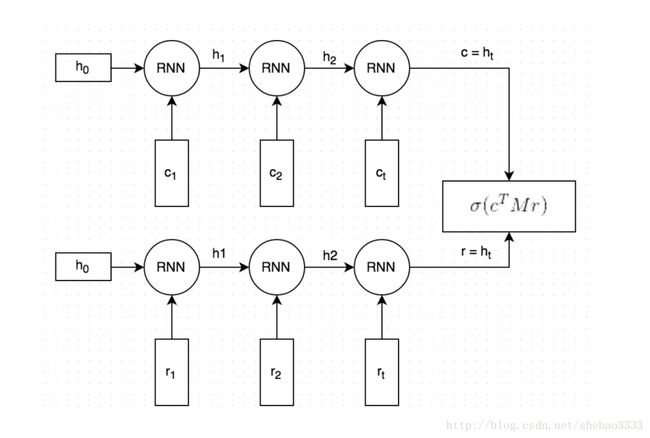
它的大致工作原理如下:
- 上下文和响应文本都是按照单词分割的,每个单词都嵌入到一个向量中。 词嵌入是用斯坦福大学的GloVe矢量进行初始化的,并且在训练过程中进行了微调(注:这是可选的,并且没有在图片中显示,我发现用GloVe进行初始化对模型性能没有太大的影响)。
- 嵌入的上下文和响应都逐字地输入到相同的递归神经网络(
Recurrent Neural Network)中。RNN生成一个矢量表示,不严格地说,这个表示捕捉了上下文和响应(图片中的c和r)中的“含义”。 我们可以自由选择矢量的大小,不过先选择256个维度吧。 - 我们用矩阵
M乘以c来“预测”一个响应r'。 如果c是256维向量,则M是256×256维矩阵,结果是另一个256维向量,我们可以将其解释为产生的响应。 矩阵M是在训练中学习到的。 - 我们通过取这两个向量的点积来度量预测响应
r'和实际响应r的相似度。 大的点积意味着两个向量更相似,因此应该得到高分。 然后,我们应用sigmoid函数将该分数转换为概率。 请注意,步骤3和4在图中组合在一起。
为了训练网络,我们还需要一个损失(成本)函数。 我们将使用分类问题中常见的二项交叉熵损失(binary cross-entropy loss)。 让我们将上下文响应的真实标签称为y。 这可以是1(实际响应)或0(不正确的响应)。 让我们把上面第4条中提到的预测概率称为y'。 然后,交叉熵损的计算公式为L = -y * ln(y') - (1-y)* ln(1-y')。 这个公式背后的直觉很简单。 如果y = 1,则剩下L = -ln(y'),这意味着对远离1的预测加以惩罚;如果y = 0,则剩下L = -ln(1-y'),这惩罚了远离0的预测。
我们的实现将使用numpy ,pandas , Tensorflow和TF Learn ( Tensorflow的高层API)的组合。
数据预处理
原始的数据集是CSV格式。 我们可以直接使用CSV,但最好将我们的数据转换成Tensorflow专有的example格式。 (顺便说一下:还有一个tf.SequenceExample,但tf.learn似乎不支持这一格式)。 example格式的主要好处是它允许我们直接从输入文件加载张量(tensor),并让Tensorflow来对输入进行随机排序(shuffle),批次处理(batch)和队列处理(queue)。 作为预处理的一部分,我们还创建了一个词表。 这意味着我们将每个单词映射到一个整数,例如“cat”可能变成2631.我们将生成的TFRecord文件,存储的就是这些整数而不是字串。 我们会保留词表,以便后续可以从整数映射回单词。
每个样例包含以下字段:
- context:表示上下文文本的词序列,例如
[231,2190,737,0,912] - context_len:上下文的长度,例如上面例子中的5
- utterance:表示话语(响应)的一系列单词id
- utterance_len:话语的长度
- label:标签,在训练数据中才有。 0或1。
- distractor_ [N]:仅在测试/验证数据中。 N的范围从0到8.代表干扰项的词序列id。
- distractor_ [N] _len:仅在测试/验证数据中。 N的范围是从0到8.发音的长度。
预处理由Python脚本prepare_data.py 完成,该脚本生成3个文件:train.tfrecords,validation.tfrecords和test.tfrecords。 你可以自己运行脚本或者在这里下载数据文件 。
创建一个输入函数
为了使用Tensorflow内置的训练和评估支持,我们需要创建一个输入函数 - 一个返回批量输入数据的函数。 事实上,由于我们的训练和测试数据有不同的格式,我们需要不同的输入功能。 输入函数应返回一批特征和标签(如果可用)。 模板如下:
-
def input_fn(): -
# TODO Load and preprocess data here -
return batched_features, labels
因为在训练和评估过程中我们需要不同的输入函数,并且因为我们讨厌复制代码,所以我们创建了一个名为create_input_fn的包装器,以便为相应的模式(mode)创建一个输入函数。 它也需要一些其他参数。 这是我们使用的定义:
-
def create_input_fn(mode, input_files, batch_size, num_epochs=None): -
def input_fn(): -
# TODO Load and preprocess data here -
return batched_features, labels -
return input_fn
完整的代码可以在udc_inputs.py中找到。 这个函数主要执行以下操作:
- 创建描述样例文件中字段的特征定义(
feature definition) - 使用
tf.TFRecordReader从输入文件中读取记录 - 根据特征定义解析记录
- 提取训练标签
- 将多个样例和培训标签构造成一个批次
- 返回批次
定义评估指标
我们已经提到,我们要使recall@ k指标来评估我们的模型。 幸运的是,Tensorflow预置了很多我们可以使用的标准的评估指标,包括recall@ k。 要使用这些指标,我们需要创建一个从指标名称映射到函数(以预测和标签为参数)的字典:
-
def create_evaluation_metrics(): -
eval_metrics = {} -
for k in [1, 2, 5, 10]: -
eval_metrics[“recall_at_%d” % k] = functools.partial( -
tf.contrib.metrics.streaming_sparse_recall_at_k, -
k=k) -
return eval_metrics
上面代码中,我们使用functools.partial将一个带有3个参数的函数转换为只带有2个参数的函数。 不要让名称streaming_sparse_recall_at_k把你搞糊涂。 streaming只是意味着指标是在多个批次上累积的,而sparse则是指我们标签的格式。
这带来了一个重要的问题:评估过程中我们的预测到底是什么格式? 在训练期间,我们预测样例正确的概率。 但是在评估过程中,我们的目标是对话语和9个干扰项进行评分,并挑选分最高的一个 - 我们不能简单地预测正确还是不正确。 这意味着在评估过程中,每个样例都应该得到一个有10个分值的向量,例如[0.34,0.1,0.22,0.45,0.01,0.02,0.03,0.08,0.33,0.11],每一个分数分别对应于真实的响应和9个干扰项。 每个话语都是独立评分的,所以概率不需要加起来为1.因为真正的响应在数组中总是为0,所以每个例子的标签都是0。上面的例子将被recall@ 1指标视为分类错误,因为第三个干扰项的概率是0.45,而真实的回答只有0.34。 然而,它会被recall@ 2指标视为正确的。

训练代码样板
在编写实际的神经网络代码之前,我喜欢编写用于训练和评估模型的样板代码。 这是因为,只要你坚持正确的接口,很容易换出你使用的是什么样的网络。 假设我们有一个模型函数model_fn,它以批次特征,标签和模式(训练或评估)作为输入,并返回预测结果。 那么我们可以编写如下的通用代码来训练我们的模型:
-
estimator = tf.contrib.learn.Estimator( -
model_fn=model_fn, -
model_dir=MODEL_DIR, -
config=tf.contrib.learn.RunConfig()) -
input_fn_train = udc_inputs.create_input_fn( -
mode=tf.contrib.learn.ModeKeys.TRAIN, -
input_files=[TRAIN_FILE], -
batch_size=hparams.batch_size) -
input_fn_eval = udc_inputs.create_input_fn( -
mode=tf.contrib.learn.ModeKeys.EVAL, -
input_files=[VALIDATION_FILE], -
batch_size=hparams.eval_batch_size, -
num_epochs=1) -
eval_metrics = udc_metrics.create_evaluation_metrics() -
# We need to subclass theis manually for now. The next TF version will -
# have support ValidationMonitors with metrics built-in. -
# It’s already on the master branch. -
class EvaluationMonitor(tf.contrib.learn.monitors.EveryN): -
def every_n_step_end(self, step, outputs): -
self._estimator.evaluate( -
input_fn=input_fn_eval, -
metrics=eval_metrics, -
steps=None) -
eval_monitor = EvaluationMonitor(every_n_steps=FLAGS.eval_every) -
estimator.fit(input_fn=input_fn_train, steps=None, monitors=[eval_monitor])
在这里,我们为model_fn,训练和评估数据的两个输入函数以及评估指标字典创建了一个估计器。 我们还定义了一个监视器,在训练期间每隔FLAGS.eval_every_every指定的步数对模型进行评估。 最后,我们训练模型。 训练过程可以无限期地运行,但Tensorflow可以自动地将检查点文件保存在MODEL_DIR指定的目录中,因此可以随时停止训练。 一个更炫的技巧是使用早期停止,这意味着当验证集指标停止改进时(即开始过拟合),将自动停止训练。 你可以在udc_train.py中看到完整的代码。
我想简要提及的两件事是FLAGS的使用。 这是给程序提供命令行参数的一种方法(类似于Python的argparse)。 hparams是我们在hparams.py中创建的一个自定义对象,它包含用来调整模型的参数、超参数。 我们在实例化模型时将这个hparams对象赋予给模型。
创建模型
现在我们已经建立了关于输入,解析,评估和训练的样板代码,可以为我们的Dual LSTM神经网络编写代码了。 因为我们有不同格式的训练和评估数据,所以我写了一个create_model_fn包装器,它负责为我们提供正确的格式。 它接受一个model_impl参数,应当指向一个实际进行预测的函数。 在我们的例子中就是上面介绍的双编码器LSTM,但是我们可以很容易地把它换成其他的神经网络。 让我们看看是什么样的:
-
def dual_encoder_model( -
hparams, -
mode, -
context, -
context_len, -
utterance, -
utterance_len, -
targets): -
# Initialize embedidngs randomly or with pre-trained vectors if available -
embeddings_W = get_embeddings(hparams) -
# Embed the context and the utterance -
context_embedded = tf.nn.embedding_lookup( -
embeddings_W, context, name=”embed_context”) -
utterance_embedded = tf.nn.embedding_lookup( -
embeddings_W, utterance, name=”embed_utterance”) -
# Build the RNN -
with tf.variable_scope(“rnn”) as vs: -
# We use an LSTM Cell -
cell = tf.nn.rnn_cell.LSTMCell( -
hparams.rnn_dim, -
forget_bias=2.0, -
use_peepholes=True, -
state_is_tuple=True) -
# Run the utterance and context through the RNN -
rnn_outputs, rnn_states = tf.nn.dynamic_rnn( -
cell, -
tf.concat(0, [context_embedded, utterance_embedded]), -
sequence_length=tf.concat(0, [context_len, utterance_len]), -
dtype=tf.float32) -
encoding_context, encoding_utterance = tf.split(0, 2, rnn_states.h) -
with tf.variable_scope(“prediction”) as vs: -
M = tf.get_variable(“M”, -
shape=[hparams.rnn_dim, hparams.rnn_dim], -
initializer=tf.truncated_normal_initializer()) -
# “Predict” a response: c * M -
generated_response = tf.matmul(encoding_context, M) -
generated_response = tf.expand_dims(generated_response, 2) -
encoding_utterance = tf.expand_dims(encoding_utterance, 2) -
# Dot product between generated response and actual response -
# (c * M) * r -
logits = tf.batch_matmul(generated_response, encoding_utterance, True) -
logits = tf.squeeze(logits, [2]) -
# Apply sigmoid to convert logits to probabilities -
probs = tf.sigmoid(logits) -
# Calculate the binary cross-entropy loss -
losses = tf.nn.sigmoid_cross_entropy_with_logits(logits, tf.to_float(targets)) -
# Mean loss across the batch of examples -
mean_loss = tf.reduce_mean(losses, name=”mean_loss”) -
return probs, mean_loss
完整的代码在dual_encoder.py中 。 鉴于此,我们现在可以在我们之前定义的udc_train.py的主例程中实例化我们的模型函数。
-
model_fn = udc_model.create_model_fn( -
hparams=hparams, -
model_impl=dual_encoder_model)
好了! 我们现在可以运行python udc_train.py,它将开始训练我们的网络,间或评估验证数据的召回情况(你可以选择使用-eval_every开关来选择评估的频率)。 要获得我们使用tf.flags和hparams定义的所有可用的命令行标志的完整列表,你可以运行python udc_train.py --help。
-
INFO:tensorflow:training step 20200, loss = 0.36895 (0.330 sec/batch). -
INFO:tensorflow:Step 20201: mean_loss:0 = 0.385877 -
INFO:tensorflow:training step 20300, loss = 0.25251 (0.338 sec/batch). -
INFO:tensorflow:Step 20301: mean_loss:0 = 0.405653 -
… -
INFO:tensorflow:Results after 270 steps (0.248 sec/batch): recall_at_1 = 0.507581018519, recall_at_2 = 0.689699074074, recall_at_5 = 0.913020833333, recall_at_10 = 1.0, loss = 0.5383 -
…
评估模型
在你训练完模型之后,你可以在测试集上使用python udc_test.py - model_dir = $ MODEL_DIR_FROM_TRAINING来评估它,例如python udc_test.py - model_dir =〜/ github / chatbot-retrieval / runs / 1467389151。 这将在测试集而不是验证集上运行recall@ k评估指标。 请注意,你必须使用在训练期间使用的相同参数调用udc_test.py。 所以,如果你用 - embedding_size = 128进行训练,就需要用相同的方法调用测试脚本。
经过约20,000步的训练(在快速GPU上一个小时左右),我们的模型在测试集上得到以下结果:
-
recall_at_1 = 0.507581018519 -
recall_at_2 = 0.689699074074 -
recall_at_5 = 0.913020833333
虽然recall@ 1接近我们的TFIDF模型,recall@ 2和recall@ 5显着更好,这表明我们的神经网络为正确的答案分配了更高的分数。 原始论文中recall@1、recall@2和recall@5的值分别是0.55,0.72和0.92,但是我还没能重现。 也许额外的数据预处理或超参数优化可能会使分数上升一点。
预测
你可以修改并运行udc_predict.py,以获取不可见数据的概率得分。 例如python udc_predict.py — model_dir=./runs/1467576365/,将得到输出:
-
Context: Example context -
Response 1: 0.44806 -
Response 2: 0.481638
.
你可以想象为,在一个上下文中输入100个潜在的响应,然后选择一个最高分的。
结论
在这篇文章中,我们已经实现了一个基于检索的神经网络模型,可以根据对话上下文对潜在的响应打分。 然而,还有很多改进的余地。 可以想象,与双LSTM编码器相比,其他神经网络在这个任务上做得更好。 超参数优化还有很多空间,或者预处理步骤的改进。 本教程的代码和数据在Github上,请查看。
原文:Ultimate Guide to Leveraging NLP & Machine Learning for your Chatbot
https://blog.csdn.net/qfire/article/details/78809289