2019_IJCAI_Deep Adversarial Social Recommendation
[论文阅读笔记]2019_IJCAI_Deep Adversarial Social Recommendation
论文下载地址: https://www.ijcai.org/Proceedings/2019/0187.pdf
发表期刊:IJCAI
Publish time: 2019
作者及单位:
- Wenqi Fan1, Tyler Derr2, Yao Ma2, Jianping Wang1, Jiliang Tang2and Qing Li3
- 1Department of Computer Science, City University of Hong Kong
- 2Data Science and Engineering Lab, Michigan State University
- 3Department of Computing,The Hong Kong Polytechnic University
- [email protected], {derrtyle, mayao4}@msu.edu, [email protected], [email protected], [email protected]
数据集: 正文中的介绍
- Ciao http://www.cse.msu.edu/∼tangjili/trust.html (文中作者给出的)
- Epinions http://www.cse.msu.edu/∼tangjili/trust.html (文中作者给出的)
代码:
其他:
其他人写的文章
- 对抗性社交推荐 (写的重点)
简要概括创新点: 2018_NACAL_KBGAN: Adversarial Learning for Knowledge Graph Embeddings将GANs与Knowledge graph embeddings(KGE)相结合,提高了KGE的效率,针对的就是negative smaple。本文就把Adversial Learning套在SoRec上,还是针对negative sample
- (1) In this paper, we present a Deep Adversarial SOcial recommendation model (DASO), which learns separated user representations in item domain and social domain. (在本文中,我们提出了一个深度对抗性社会推荐模型(DASO),该模型学习项目域和社会域中分离的用户表示。)
- (2) Particularly, we propose to transfer users’ information from social domain to item domain by using a bidirectional mapping method. (特别地,我们建议使用双向映射方法将用户的信息从社交领域转移到项目领域。)
- (3) In addition, we also introduce the adversarial learning to optimize our entire framework by generating informative negative samples. (此外,我们还引入了对抗式学习,通过生成信息丰富的负样本来优化我们的整个框架。)
- (4) 关于生成器和判别器,与通用的模型的作用是一样的。
Abstract
- Recent years have witnessed rapid developments on social recommendation techniques for improving the performance of recommender systems due to the growing influence of social networks to our daily life. The majority of existing social recommendation methods unify user representation for the user-item interactions (item domain) and user-user connections (social domain). (近年来,由于社交网络对我们日常生活的影响越来越大,为了提高推荐系统的性能,社交推荐技术得到了快速发展。现有的大多数社交推荐方法统一了用户项目交互(项目域)和用户连接(社交域)的用户表示。)
- However, it may restrain user representation learning in each respective domain, since users behave and interact differently in two domains, which makes their representations to be heterogeneous. (然而,由于用户在两个域中的行为和交互不同,这使得他们的表示具有异构性,因此它可能会限制每个域中的用户表示学习)
- In addition, most of traditional recommender systems can not efficiently optimize these objectives, since they utilize negative sampling technique which is unable to provide enough informative guidance towards the training during the optimization process. (此外,大多数传统的推荐系统不能有效地优化这些目标,因为它们使用负采样技术,无法为优化过程中的训练提供足够的信息指导。)
- In this paper, to address the aforementioned challenges, we propose a novel Deep Adversarial SOcial recommendation DASO. (我们提出了一个新的深度对抗性社会推荐DASO。)
- It adopts a bidirectional mapping method to transfer users’ information between social domain and item domain using adversarial learning. (它采用双向映射方法,通过对抗式学习在社交领域和项目领域之间传递用户信息。)
- Comprehensive experiments on two realworld datasets show the effectiveness of the proposed method.
1 Introduction
-
(1) In recent years, we have seen an increasing amount of attention on social recommendation, which harnesses social relations to boost the performance of recommender systems [Tang et al., 2016b; Fan et al., 2019; Wang et al., 2016]. Social recommendation is based on the intuitive ideas that people in the same social group are likely to have similar preferences, and that users will gather information from their experienced friends (e.g., classmates, relatives, and colleagues) when making decisions. Therefore, utilizing users’ social relations has been proven to greatly enhance the performance of many recommender systems [Ma et al., 2008; Fan et al., 2019; Tang et al., 2013b; 2016a]. (近年来,我们看到社会推荐越来越受到关注,它利用社会关系提升推荐系统的性能[Tang等人,2016b;Fan等人,2019;Wang等人,2016]。 社交推荐基于一种直观的想法,即同一社交群体中的人可能有相似的偏好,用户在做出决策时会从经验丰富的朋友(例如同学、亲戚和同事)那里收集信息。 因此,利用用户的社会关系已被证明能极大地提高许多推荐系统的性能[Ma等人,2008年;Fan等人,2019年;Tang等人,2013b;2016a]。)

-
(2) In Figure 1, we observe that in social recommendation we have both the item and social domains, which represent the user-item interactions and user-user connections, respectively. Currently, the most effective way to incorporate the social information for improving recommendations is when learning user representations, which is commonly achieved in ways such as, (在图1中,我们观察到,在社交推荐中,我们同时拥有条目和社交域,它们分别代表用户条目交互和用户-用户连接。目前,整合社交信息以改进推荐的最有效方法是 学习用户表示,这通常通过以下方式实现:)
- using trust propagation [Jamali and Ester, 2010], (使用信任传播)
- incorporating a user’s social neighborhood information [Fan et al., 2018], (合并用户的社交社区信息)
- or sharing a common user representation for the user-item interactions and social relations with a co-factorization method [Ma et al., 2008]. (或者使用协因子分解方法共享用户项交互和社会关系的公共用户表示)
-
However, as shown in Figure 1, although users bridge the gap between these two domains, their representations should be heterogeneous. This is because users behave and interact differently in the two domains. Thus, using a unified user representation may restrain user representation learning in each respective domain and results in an inflexible/limited transferring of knowledge from the social relations to the item domain. Therefore, one challenge is to learn separated user representations in two domains while transferring the information from the social domain to the item domain for recommendation. (然而,如图1所示,尽管用户在这两个域之间架起了桥梁,但他们的表示应该是异构的。 这是因为用户在这两个域中的行为和交互方式不同。因此,使用统一的用户表示可能会限制每个相应领域中的用户表示学习,并导致知识从社会关系到项目领域的不灵活/有限转移。因此,一个挑战是在将信息从社交领域转移到项目领域进行推荐的同时,学习两个领域中分离的用户表示。)
-
(3) In this paper, we adopt a nonlinear mapping operation to transfer user’s information from the social domain to the item domain, while learning separated user representations in the two domains. (在本文中,我们采用非线性映射操作将用户的信息从社交领域转移到项目领域,同时在这两个领域中学习分离的用户表示。)
-
Nevertheless, learning the representations is challenging due to the inherent data sparsity problem in both domains. Thus, to alleviate this problem, we propose to use a bidirectional mapping between the two domains, such that we can cycle information between them to progressively enhance the user’s representations in both domains. (然而,由于这两个领域都存在固有的数据稀疏性问题,因此学习这些表示具有挑战性。因此,为了缓解这个问题,我们建议在两个域之间使用双向映射,这样我们可以在它们之间循环信息,以逐步增强用户在两个域中的表示。)
-
However, for optimizing the user representations and item representations, most existing methods utilize the negative sampling technique, which is quite ineffective [Wang et al., 2018b]. This is due to the fact that during the beginning of the training process, most of the negative user-item samples are still within the margin to the real user-item samples, but later during the optimization process, negative sampling is unable to provide “difficult” and informative samples to further improve the user representations and item representations [Wang et al., 2018b; Cai and Wang, 2018]. Thus, it is desired to have samples dynamically generated throughout the training process to better guide the learning of the user representations and item representations. (然而,为了优化用户表示和项目表示,大多数现有方法都使用负采样技术,这是非常无效的[Wang等人,2018b]。这是因为在培训过程开始时,大多数负面用户项样本仍在与真实用户项样本的差距内,但在优化过程的后期,负抽样无法提供“困难”且信息丰富的样本,以进一步改善用户表征和项目表征[Wang等人,2018b;Cai和Wang,2018]。因此,希望在整个训练过程中 动态生成样本 ,以更好地指导用户表示和项目表示的学习。)
-
(4)Recently, Generative Adversarial Networks (GANs) [Goodfellow et al., 2014], which consists of two models to process adversarial learning, have shown great success across various domains due to their ability to learn an underlying data distribution and generate synthetic samples [Mao et al., 2017; 2018; Brock et al., 2019; Liu et al., 2018; Wang et al., 2017; 2018a; Derr et al., 2019]. (最近,生成性对抗网络(GANs) [Goodfello et al.,2014]由两个模型组成,用于处理对抗学习,由于其能够学习底层数据分布并生成合成样本,在各个领域取得了巨大成功)
- This is performed through the use of a generator and a discriminator. (这是通过使用生成器和鉴别器来实现的)
- The generator tries to generate realistic fake data samples to fool the discriminator, which distinguishes whether a given data sample is produced by the generator or comes from the real data distribution. (生成器试图生成真实的假数据样本来欺骗鉴别器,鉴别器可以区分给定的数据样本是由生成器生成的还是来自真实的数据分布。)
- A minimax game is played between the generator and discriminator, where this adversarial learning can train these two models simultaneously for mutual promotion. (在生成器和鉴别器之间玩一个极大极小博弈,这种对抗性学习可以同时训练这两个模型,以便相互促进。)
- In [Wang et al., 2018b] adversarial learning had been used to address the limitation of typical negative sampling.
- This is performed through the use of a generator and a discriminator. (这是通过使用生成器和鉴别器来实现的)
-
(5)Thus, we propose to harness adversarial learning in social recommendation to generate “difficult” negative samples to guide our framework in learning better user and item representations while further utilizing it to optimize our entire framework. (因此,我们建议在社会推荐中利用对抗性学习来生成“困难的”负面样本,以指导我们的框架学习更好的用户和项目表示,同时进一步利用它优化我们的整个框架。)
-
Our major contributions can be summarized as follows:
- We introduce a principled way to transfer users’ information from social domain to item domain using a bidirectional mapping method where we cycle information between the two domains to progressively enhance the user representations; (我们介绍了一种原则性的方法,使用双向映射方法将用户信息从社交领域转移到项目领域,在这两个领域之间循环信息,以逐步增强用户表示;)
- We propose a Deep Adversarial SOcial recommender system DASO, which can harness the power of adversarial learning to dynamically generate “difficult” negative samples, learn the bidirectional mappings between the two domains, and ultimately optimize better user and item representations; (我们提出了一个深度对抗性社会推荐系统DASO,它可以利用对抗性学习的力量动态生成==“困难”的负面样本==,学习两个领域之间的双向映射,最终优化更好的用户和项目表示;) and
- We conduct comprehensive experiments on two real-world datasets to show the effectiveness of the proposed model. (我们在两个真实数据集上进行了综合实验,以证明该模型的有效性。)
2 The Proposed Framework
- Let U = { u 1 , u 2 , . . . , u N } \mathcal{U} = \{u_1, u_2, ..., u_N\} U={u1,u2,...,uN} and V = { v 1 , v 2 , . . . , v M } \mathcal{V} = \{v_1, v_2, ..., v_M\} V={v1,v2,...,vM} denote the sets of users and items respectively,
- where N ( M ) N (M) N(M) is the number of users (items).
- We define user-item interactions matrix R ∈ R N × M R \in R^{N\times M} R∈RN×M from user’s implicit feedback,
- where the i i i, j j j-th element r i , j r_{i,j} ri,j is 1 if there is an interaction (e.g., clicked/bought) between user u i u_i ui and item v j v_j vj, and 0 other- wise.
- However, r i , j = 1 r_{i,j} = 1 ri,j=1 does not mean user uiactually likes item v j v_j vj.
- Similarly, r i , j = 0 r_{i,j} = 0 ri,j=0 does not mean u i u_i ui does not like item v j v_j vj, since it can be that the user u i u_i ui is not aware of the item v j v_j vj.
- where the i i i, j j j-th element r i , j r_{i,j} ri,j is 1 if there is an interaction (e.g., clicked/bought) between user u i u_i ui and item v j v_j vj, and 0 other- wise.
- The social network between users can be described by a matrix S ∈ R N × N S \in R^{N\times N} S∈RN×N,
- where s i , j = 1 s_{i,j} = 1 si,j=1 if there is a social relation between user u i u_i ui and user u j u_j uj, and 0 otherwise.
- Given interactions matrix R R R and social network S S S, we aim to predict the unobserved entries (i.e., those where r i , j = 0 ri,j= 0 ri,j=0) in R R R. (给定交互矩阵 R R R和社交网络 S S S,我们的目标是预测 R R R中未观察到的条目(即 r i , j = 0 r_{i,j}=0 ri,j=0。)
2.1 An Overview of the Proposed Framework
-
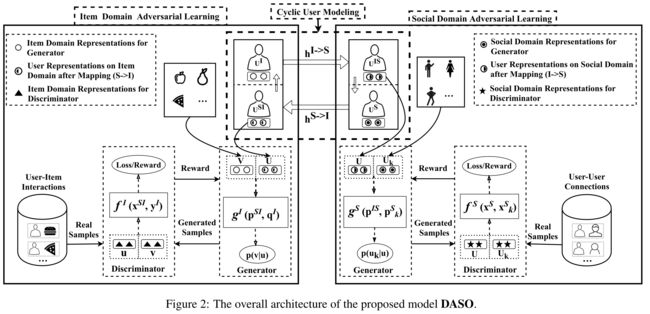
(1)The architecture of the proposed model is shown in Figure 2. The information is from two domains, which are the item domain I I I and the social domain S S S. (提出的模型的架构如图2所示。信息来自两个领域,即项目域I和社交域S)
- The model consists of three components: (该模型由三个部分组成)
- cyclic user modeling, (循环用户建模)
- item domain adversarial learning, (项目域对抗性学习)
- and social domain adversarial learning. (和社交域对抗性学习)
- The cyclic user modeling is to model user representations on two domains. (循环用户建模是在两个域上对用户表示进行建模)
- The item domain adversarial learning is to adopt the adversarial learning for dynamically generating “difficult” and informative negative samples to guide the learning of user and item representations. (项目域 对抗性学习 是采用对抗性学习 动态 生成 “困难” 且 信息丰富 的 负样本,以指导用户和项目表征的学习)
- The generator is utilized to ‘sample’ (recommend) items for each user and output user-item pairs as fake samples; (生成器 用于为每个用户“采样”(推荐)项目,并将用户项目对作为假样本输出)
- the other is the discriminator, which distinguishes the user-item pair samples sampled from the real user-item interactions from the generated user-item pair samples. (另一个是 鉴别器 ,它将从真实用户项交互中采样的用户项对样本与生成的用户项对样本区分开来)
- The social domain adversarial learning also similarly consists of a generator and a discriminator. (社交领域的对抗性学习同样由一个生成器和一个鉴别器组成)
- The model consists of three components: (该模型由三个部分组成)
-
(2)There are four types of representations in the two domains.
- In the item domain I I I, we have two types of representations including
- item domain representations of the generator ( p i I ∈ R d p^I_ i\in R^d piI∈Rd for user u i u_i ui and q j I ∈ R d q^I_j \in R^d qjI∈Rd for item v j v_j vj),
- and the item domain representations of the discriminator ( x i I ∈ R d x^I_i \in R^d xiI∈Rd for user u i u_i ui and y j I ∈ R d y^I_j \in R^d yjI∈Rd for item v j v_j vj).
- Social domains S S S also contains two types of representations including
- the social domain representations of the generator ( p i S ∈ R d p^S_i \in R^d piS∈Rd for user u i u_i ui),
- and the social domain representations of the discriminator ( x i S ∈ R d x^S_i \in R^d xiS∈Rd for user u i u_i ui).
- In the item domain I I I, we have two types of representations including
2.2 Cyclic User Modeling
- Cyclic user modeling aims to learn a relation between the user representations in the item domain I I I and the social domain S S S. As shown in the top part of Figure 2, ((循环用户建模旨在了解项目域I和社交域S中的用户表示之间的关系。如图2顶部所示)
- we first adopt a nonlinear mapping operation, denoted as h S → I h^{S\to I} hS→I, to transfer user’s information from the social domain to the item domain, while learning separated user representations in the two domains. (我们首先采用非线性映射操作,表示为 h S → I h^{S\to I} hS→I将用户信息从社交领域转移到项目领域,同时学习两个领域中的独立用户表示)
- Then, a bidirectional mapping between these two domains (achieved by including another nonlinear mapping h I → S h^{I→S} hI→S) is utilized to help cycle the information between them to progressively enhance the user representations in both domains. (然后,这两个域之间的双向映射(通过包含另一个非线性映射 h I → S h^{I\to S} hI→S实现) 用于帮助循环它们之间的信息,以逐步增强两个域中的用户表示。)
2.2.1 Transferring Social Information to Item Domain
-
(1)In social networks, a person’s preferences can be influenced by their social interactions, suggested by sociologists [Fan et al., 2019; 2018; Wasserman and Faust, 1994]. Therefore, a user’s social relations from the social network should be incorporated into their user representation in the item domain. (社会学家建议,在社交网络中,一个人的偏好可能会受到他们的社交互动的影响[Fan等人,2019年;2018年;瓦瑟曼和浮士德,1994年]。因此,来自社交网络的用户社交关系应该被纳入他们在项目域中的用户表示中。)
-
(2)We propose to adopt nonlinear mapping operation to transfer user’s information from the social domain to the item domain. (我们建议采用非线性映射操作将用户信息从社交领域转移到项目领域。)
- More specifically, the user representation on social domain p i S p^S_i piS is transferred to the item domain via a Multi-Layer Perceptron (MLP) denoted as h S → I h^{S\to I} hS→I.
- The transferred user representation from social domain is denoted as p i S I p^{SI}_i piSI. (从社交领域转移的用户表示被表示为)
- More formally, the nonlinear mapping is as follows: p i S I = h S → I ( p i S ) = W L ⋅ ( ⋅ ⋅ ⋅ a ( W 2 ⋅ a ( W 1 ⋅ p i S + b 1 ) + b 2 ) . . . ) + b L p^{SI}_i = h^{S\to I}(p^S_i) = W_L·(· · ·a(W_2·a(W_1·p^S_i + b_1) + b_2). . .) + b_L piSI=hS→I(piS)=WL⋅(⋅⋅⋅a(W2⋅a(W1⋅piS+b1)+b2)...)+bL,
- where the W s W_s Ws, b s bs bs are the weights and biases for the layers of the neural network having L L L layers,
- and a a a is a nonlinear activation function.
2.2.2 Bidirectional Mapping with Cycle Reconstruction
-
(1)As user-item interactions and user-user connections are often very sparse, learning separated user representations is challenging. (由于用户项交互和用户-用户连接通常非常稀疏,因此学习分离的用户表示是一项挑战。)
- Therefore, to partially alleviate this issue, we propose to utilize a bidirectional mapping between the two domains, such that we can cycle information between them to progressively enhance the user representations in both domains. (因此,为了部分缓解这个问题,我们建议利用两个域之间的双向映射,这样我们可以在它们之间循环信息,以逐步增强两个域中的用户表示。)
- To achieve this, another nonlinear apping operation, denoted as h I → S h^{I\to S} hI→S, is adopted to transfer information from the item domain to the social domain: p i I S = h I → S ( p i I ) p^{IS}_i = h^{I\to S}(p^I_i) piIS=hI→S(piI), which has the same network structure as the h S → I h^{S\to I} hS→I.
-
(2)This Bidirectional Mapping allows knowledge to be transferred between item and social domains. To learn these mappings, we further introduce cycle reconstruction. Its intuition is that transferred knowledge in the target domain should be reconstructed to the original knowledge in the source domain. Next we will elaborate cycle reconstruction. (这种双向映射允许知识在项目和社交领域之间转移。为了学习这些映射,我们进一步引入循环重构。它的直觉是,目标领域中转移的知识应该重建为源领域中的原始知识。接下来我们将详细介绍循环重建。)
-
(3)For user u i u_i ui’s item domain representation p i I p^I_i piI, the user representation with cycle reconstruction should be able to map p i I p^I_i piI back to the original domain, as follows, p i I ⟶ h I → S ( p i I ) ⟶ h S → I ( h I → S ( p i I ) ) ≈ p i I p^I_i \longrightarrow h^{I\to S}(p^I_i) \longrightarrow h^{S\to I}(h^{I\to S}(p^I_i)) \approx p^I_i piI⟶hI→S(piI)⟶hS→I(hI→S(piI))≈piI.
- Likewise, for user u i u_i ui’s social domain representation p i S p^S_i piS, the user representation with cycle reconstruction can also bring p i S p^S_i piS back to the original domain: p i S ⟶ h S → I ( p i I ) ⟶ h I → S ( h S → I ( p i S ) ) ≈ p i S . p^S_i \longrightarrow h^{S\to I}(p^I_i) \longrightarrow h^{I\to S}(h^{S\to I}(p^S_i)) ≈ p^S_i. piS⟶hS→I(piI)⟶hI→S(hS→I(piS))≈piS.
-
(4)We can formulate this procedure using a cycle reconstruction loss, which needs to be minimized, as follows,
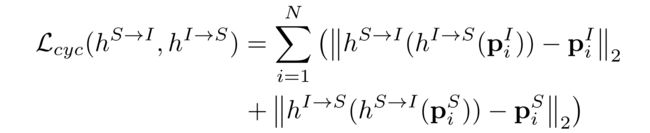
2.3 Item Domain Adversarial Learning
-
(1)To address the limitation of negative sampling for recommendation on the ranking task, we propose to harness adversarial learning to generate “difficult” and informative samples to guide the framework in learning better user and item representations in the item domain. As shown in the bottom left part of Figure 2, the adversarial learning on item domain consists of two components: (为了解决负采样在排名任务中的局限性,我们建议利用对抗性学习生成“困难”且信息丰富的样本,以指导框架更好地学习项目域中的用户和项目表示。如图2左下角所示,项目领域的对抗性学习由两个部分组成:)
- Discriminator D I ( u i , v ; ϕ D I ) D^I(u_i, v; \phi^I_D) DI(ui,v;ϕDI), parameterized by ϕ D I \phi^I_D ϕDI, aims to distinguish the real user-item pairs ( u i , v ) (u_i, v) (ui,v) and the user-item pairs generated by the generator. (旨在区分真正的用户项对 ( u i , v ) (u_i, v) (ui,v)以及生成器生成的用户项对。)
- Generator G I ( v ∣ u i ; θ G I ) G^I(v|u_i; \theta^I_G) GI(v∣ui;θGI), parameterized by θ G I \theta^I_G θGI, tries to fit the underlying real conditional distribution p r e a l I ( v ∣ u i ) p^I_{real}(v|u_i) prealI(v∣ui) as much as possible, and generates (or, to be more precise, selects) the most relevant items to a given user u i u_i ui. (尝试拟合底层实条件分布 p r e a l I ( v ∣ u i ) p^I_{real}(v|u_i) prealI(v∣ui) 并生成(或者更准确地说,选择)与给定用户 u i u_i ui最相关的项 .)
-
(2)Formally, D I D^I DI and G I G^I GI are playing the following two-player minimax game with value function L a d v I ( G I , D I ) L^I_{adv}(G^I, D^I) LadvI(GI,DI), (形式上, D I D^I DI 和 G I G^I GI正在玩下面的两层极小极大值游戏)

2.3.1 Item Domain Discriminator Model
- (1)Discriminator D I D^I DI aims to distinguish real user-item pairs (i.e., real samples) and the generated “fake” samples. (鉴别器 D I D^I DI旨在区分真实用户项目对(即真实样本)和生成的“假”样本。)
- The discriminator D I D^I DI estimates the probability of item v j v_j vj being relevant (bought or clicked) to a given user u i u_i ui using the sigmoid function and a score function f φ D I I f^I_{φ^I_D} fφDII sa follows: (鉴别器 D I D^I DI使用sigmoid函数和score函数估计项目 v j v_j vj的概率与给定用户 u i u_i ui相关(购买或点击)的概率)

- (2)Given real samples and generated fake samples, the objective for the discriminator D I D^I DI is to maximize the log-likelihood of assigning the correct labels to both real and generated samples. The discriminator can be optimized by minimizing the objective in eq. (1) with the generator fixed using stochastic gradient methods. (给定真实样本和生成的假样本,鉴别器 D I D^I DI的目标是最大化为真实样本和生成样本分配正确标签的对数可能性。利用随机梯度法,在生成器固定的情况下,可通过最小化等式(1)中的目标来优化鉴别器。)
2.3.2 Item Domain Generator Model
-
(1) On the other hand, the purpose of the generator G I G^I GI is to approximate the underlying real conditional distribution p r e a l I ( v ∣ u i ) p^I_{real}(v|u_i) prealI(v∣ui), and generate the most relevant items for any given user u i u_i ui. (另一方面,生成器 G I G^I GI的目的是近似底层实条件分布 p r e a l I ( v ∣ u i ) p^I_{real}(v|u_i) prealI(v∣ui), 并为任何给定用户 u i u_i ui生成最相关的项目.)
-
(2) We define the generator using the softmax function over all the items according to the transferred user representation p i S I p^{SI}_i piSI from social domain to item domain: (我们根据从社交域到项目域传输的用户表示 p i S I p^{SI}_i piSI,在所有项上使用softmax函数定义生成器)

- where g θ G I I g^I_{\theta^I_G} gθGII is a score function reflecting the chance of v j v_j vj being clicked/purchased by u i u_i ui. Given a user u i u_i ui, an item v j v_j vj can be sampled from the distribution G I ( v j ∣ u i ; θ G I ) G^I(v_j | u_i; θ^I_G) GI(vj∣ui;θGI).
-
(3) We note that the process of generating a relevant item for a given user is discrete. Thus, we cannot optimize the generator G I G^I GI via stochastic gradient descent methods [Wang et al., 2017]. Following [Sutton et al., 2000; Schulman et al., 2015], we adopt the policy gradient method usually adopted in reinforcement learning to optimize the generator. (我们注意到,为给定用户生成相关项的过程是离散的。因此,我们无法通过随机梯度下降法优化发生器 G I G^I GI[Wang等人,2017]。继[Sutton等人,2000年;Schulman等人,2015年]之后,我们采用 强化学习 中通常采用的策略梯度法来优化生成器。)
-
(4) To learn the parameters for the generator, we need to perform the following minimization problem: (为了了解生成器的参数,我们需要执行以下最小化问题:)

-
(5) Now, this problem can be viewed in a reinforcement learning setting, where K ( x i I , y j I ) = l o g ( 1 + e x p ( f ϕ D I I ( x i I , y j I ) ) ) K(x^I_i, y^I_j) = log(1 + exp(f^I_{\phi^I_D}(x^I_i, y^I_j))) K(xiI,yjI)=log(1+exp(fϕDII(xiI,yjI))) is the reward given to the action “selecting v i v_i vi given a user u i u_i ui” performed according to the policy probability G I ( v ∣ u i ) G^I(v|u_i) GI(v∣ui). The policy gradient can be written as: (现在,这个问题可以在强化学习环境中查看)

- Specially, the gradient ▽ θ G I L a d v I ( G I , D I ) \bigtriangledown_{\theta^I_G}\mathcal{L}^I_{adv}(G^I, D^I) ▽θGILadvI(GI,DI) is an expected summation over the gradients ▽ θ G I l o g G I ( v j ∣ u i ) \bigtriangledown_{\theta^I_G}logG^I(v_j | u_i) ▽θGIlogGI(vj∣ui) weighted by l o g ( 1 + e x p ( f ϕ D I I ( x i I , y j I ) ) ) log(1 + exp(f^I_{\phi^I_D}(x^I_i, y^I_j))) log(1+exp(fϕDII(xiI,yjI))).
-
(6) The optimal parameters of G I G^I GI and D I D^I DI can be learned by alternately minimizing and maximizing the value function L a d v I ( G I , D I ) L^I_{adv}(G^I, D^I) LadvI(GI,DI). (通过交替最小化和最大化值函数 L a d v I ( G I , D I ) L^I_{adv}(G^I, D^I) LadvI(GI,DI),可以学习 G I G^I GI和 D I D^I DI的最佳参数. )
- In each iteration, discriminator D I D^I DI is trained with real samples from p r e a l I ( ⋅ ∣ u i ) p^I_{real}(\cdot | u_i) prealI(⋅∣ui) and generated samples from generator G I G^I GI; (在每一次迭代中,鉴别器 D I D^I DI都是用来自 p r e a l I ( ⋅ ∣ u i ) p^I_{real}(\cdot | u_i) prealI(⋅∣ui)的真实样本和从生成器 G I G^I GI生成的样本 训练)
- the generator G I G^I GI is updated with policy gradient under the guidance of D I D^I DI. (生成器 G I G^I GI在 D I D^I DI的指导下使用策略梯度进行更新)
-
(7) Note that different from the way of optimizing user and item representations with the typical negative sampling on traditional recommender systems, the adversarial learning technique tries to generate “difficult” and high-quality negative samples to guide the learning of user and item representations. (请注意,与传统推荐系统上典型的负采样优化用户和项目表示不同,对抗学习技术试图生成“困难”和高质量的负采样,以指导用户和项目表示的学习。)
2.4 Social Domain Adversarial Learning
-
(1) In order to learn better user representations from the social perspective, another adversarial learning is harnessed in the social domain. Likewise, the adversarial learning in the social domain consists of two components, as shown in the bottom right part of Figure 2. (为了从社交角度学习更好的用户表示,在社交领域中还利用了另一种对抗性学习。同样,社交领域中的对抗性学习由两部分组成,如图2右下部分所示。)
-
Discriminator D S ( u i , u ; ϕ D S ) D^S(u_i, u; \phi^S_D) DS(ui,u;ϕDS), parameterized by ϕ D S \phi^S_D ϕDS, aims to distinguish the real connected user-user pairs ( u i , u ) (u_i, u) (ui,u) and the fake user-user pairs generated by the generator G S G^S GS. (旨在区分真正的连接用户对 ( u i , u ) (u_i, u) (ui,u)以及生成器 G S G^S GS生成的假用户对。)
-
Generator G S ( u ∣ u i ; θ G S ) G^S(u | u_i; \theta^S_G) GS(u∣ui;θGS), parameterized by θ G S \theta^S_G θGS, tries to fit the underlying real conditional distribution p r e a l S ( u ∣ u i ) p^S_{real}(u|ui) prealS(u∣ui) as much as possible, and generates (or, to be more precise, selects) the most relevant users to the given user u i u_i ui. (尝试拟合底层实条件分布p^S_{real}(u|ui)p real S (u)∣用户界面),并生成(或者更准确地说,选择)与给定用户u_i最相关的用户 .)
-
-
(2) Formally, D S D^S DS and G S G^S GS are playing the following two-player minimax game with value function L a d v S ( G S , D S ) \mathcal{L}^S_{adv}(G^S, D^S) LadvS(GS,DS), (正在进行下面的两层极小极大值游戏)
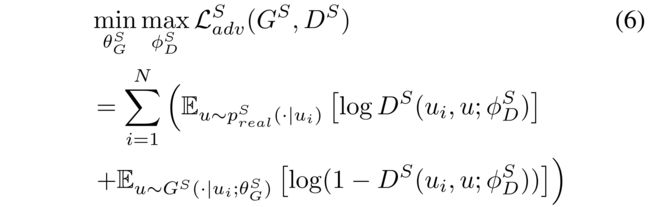
2.4.1 Social Domain Discriminator
- The discriminator D S D^S DS aims to distinguish the real user-user pairs and the generated ones. The discriminators D S D^S DS estimates the probability of user u k u_k uk being connected to user u i u_i ui with a sigmoid function and a score function f ϕ D S S f^S_{\phi^S_D} fϕDSS as follows:

2.4.2 Social Domain Generator
-
(1) The purpose of the generator, G S G^S GS, is to approximate the underlying real conditional distribution p r e a l S ( u ∣ u i ) p^S_{real}(u | u_i) prealS(u∣ui), and generate (or, to be more precise, select) the most relevant users for any given user u i u_i ui. (生成器 G S G^S GS的目的是近似基本的真实条件分布 p r e a l S ( u ∣ u i ) p^S_{real}(u | u_i) prealS(u∣ui),并为任何给定用户 u i u_i ui生成(或者更准确地说,选择)最相关的用户)
-
(2) We model the distribution using a softmax function over all the other users with the transferred user representation p i I S p^{IS}_i piIS (from the item to social domain), (我们使用softmax函数对所有其他用户的分布进行建模,并使用传输的用户表示 p i I S p^{IS}_i piIS(从项目域到社交域))

- where g θ G S S g^S_{\theta^S_G} gθGSSis a score function reflecting the chance of u k u_k uk being related to u i u_i ui. (是一个分数函数,反映了 u k u_k uk被与 u i u_i ui有联系的机会)
-
(3) Likewise, policy gradient is utilized to optimize the generator G S G^S GS, (同样,策略梯度被用来优化生成器 G S G^S GS)

-
where the details are omitted here, since it is defined similar to Eq.(5).
2.5 The Objective Function
-
(1) With all model components, the objective function of the proposed framework is: (对于所有模型组件,提出的框架的目标函数为:)

- where λ \lambda λ is to control the relative importance of cyclereconstruction strategy and further influences the two mapping operation. (其中 λ \lambda λ用于控制施工策略的相对重要性,并进一步影响两个映射操作。)
- h S ⟶ I h^{S\longrightarrow I} hS⟶I and h I ⟶ S h^{I\longrightarrow S} hI⟶S are implemented as MLP with three hidden layers. (实现为具有三个隐藏层的MLP)
- To optimize the objective, the RMSprop [Tieleman and Hinton, 2012] is adopted as the optimizer in our implementation. (为了优化目标,我们的实现采用了RMSprop[Tieleman and Hinton,2012]作为优化器。)
- To train our model, at each training epoch, we iterate over the training set in mini-batch to train each model (e.g., GI) while the parameters of other models (e.g., D I D^I DI, G S G^S GS, D S D^S DS) are fixed. (为了训练我们的模型,在每个训练阶段,我们以小批量迭代训练集来训练每个模型(例如GI),而其他模型(例如 D I D^I DI, G S G^S GS, D S D^S DS)的参数是固定的。)
- When the training is finished, we take the representations learned by the generator G I G^I GI and G S G^S GS as our final representations of item and user for performing recommendation. ( 培训结束后,我们将生成器 G I G^I GI和 G S G^S GS学习到的表示作为项目和用户的最终表示,以执行推荐。)
-
(2) There are six representations in our model, including p i I p^I_i piI, q j I q^I_j qjI, x i I x^I_i xiI, y j I y^I_j yjI, p i S p^S_i piS, x i S x^S_i xiS. They are randomly initialized and jointly learned during the training stage. (在我们的模型中有六个表示,包括 p i I p^I_i piI, q j I q^I_j qjI, x i I x^I_i xiI, y j I y^I_j yjI, p i S p^S_i piS, x i S x^S_i xiS它们在训练阶段被随机初始化并联合学习。)
-
(3) Following the setting of IRGAN [Wang et al., 2017], we adopt the inner product as the score function f φ D I I f^I_{φ^I_D} fφDII and g θ G I I g^I_{\theta^I_G} gθGII in the item domain as follows: f ϕ D I I ( x i I , y j I ) = ( x i I ) T y j I + a j f^I_{\phi^I_D}(x^I_i,y^I_j) = {(x^I_i)}^Ty^I_j+ a_j fϕDII(xiI,yjI)=(xiI)TyjI+aj, g θ G I I ( p i S I , q j I ) = ( p i S I ) T q j I + b j g^I_{\theta^I_G}(p^{SI}_i, q^I_j) = {(p^{SI}_i)}^Tq^I_j+ b_j gθGII(piSI,qjI)=(piSI)TqjI+bj, (按照IRGAN[Wang等人,2017]的设置,我们采用内积作为项目域中的得分函数 f φ D I I f^I_{φ^I_D} fφDII和 g θ G I I g^I_{\theta^I_G} gθGII,如下所示)
- where a j a_j aj and b j b_j bj are the bias term for item j j j.
- We define the score function f ϕ D S S f^S_{\phi^S_D} fϕDSS and g θ G S S g^S_{\theta^S_G} gθGSS in the social domain in a similar way. (在社交领域,以类似的方式定义了分数函数 f ϕ D S S f^S_{\phi^S_D} fϕDSS and g θ G S S g^S_{\theta^S_G} gθGSS)
- Note that the above score functions can be also implemented using deep neural networks, but leave this investigation as one future work. (请注意,上述评分函数也可以使用深度神经网络实现,但将此研究留作未来工作。)
3 Experiments
3.1 Experimental Settings
- (1) We conduct our experiments on two representative datesets Ciao and Epinions1 for the Top-K recommendation. (我们在两个具有代表性的数据集Ciao和Epinions1上进行实验,以获得Top-K推荐。)
- As these two datasets provide users’ explicit ratings on items, we convert them into 1(Both Ciao and Epinions datasets are available at: http://www.cse.msu.edu/∼tangjili/trust.html) as the implicit feedback. This processing method is widely used in previous works on recommendation with implicit feedback [Rendle et al., 2009]. (由于这两个数据集提供了用户对项目的显式评分,我们将其转换为1作为隐式反馈。这种处理方法被广泛应用于之前关于隐性反馈推荐的工作中[Rendle等人,2009]。)

- We randomly split the user-item interactions of each dataset into training set (80%) to learn the parameters, validation set (10%) to tune hyper-parameters, and testing set (10%) for the final performance comparison. We implemented our method with tensorflow and tuned all the hyper-parameters with grid-search [Fan et al., 2019]. The statistics of these two datasets are presented in Table 1. (我们将每个数据集的用户项交互随机分为训练集(80%)学习参数,验证集(10%)调整超参数,测试集(10%)进行最终性能比较。我们使用tensorflow实现了我们的方法,并使用网格搜索调整了所有超参数[Fan等人,2019]。这两个数据集的统计数据如表1所示。)
- We use two popular performance metrics for Top-K recommendation [Wang et al., 2017]: (我们在Top-K推荐中使用了两种流行的性能指标[Wang等人,2017]:Precision@K以及归一化贴现累积收益(NDCG@K))
- Precision@K
- and Normalized Discounted Cumulative Gain (NDCG@K).
- We set K as 3, 5, and 10. Higher values of the Precision@K and NDCG@K indicate better predictive performance. (.我们将K设为3、5和10。更高的Precision@K和NDCG@K显示更好的预测性能。)
Baselines
- (2) To evaluate the performance, we compared our proposed model DASO with four groups of representative baselines, including (为了评估性能,我们将我们提出的DASO模型与四组具有代表性的基线进行了比较,包括)
- traditional recommender system without social network information (BPR [Rendle et al., 2009]),
- tradition social recommender systems (SBPR [Zhao et al., 2014] and SocialMF [Jamali and Ester, 2010]),
- deep neural networks based social recommender systems (DeepSoR [Fan et al., 2018] and GraphRec [Fan et al., 2019]),
- and adversarial learning based recommender system (IRGAN [Wang et al., 2017]).
- Some of the original baseline implementations (SocialMF, DeepSoR, and GraphRec) are for rating prediction on recommendations. Therefore we adjust their objectives to point-wise prediction with sigmoid cross entropy loss using negative sampling. (一些原始的基线实现(SocialMF、DeepSoR和GraphRec)用于对建议进行评级预测。因此,我们调整了他们的目标,采用==负采样的sigmoid交叉熵损失==进行逐点预测。)
3.2 Performance Comparison of Recommender Systems
Table 2 presents the performance of all recommendation methods. We have the following findings: (表2给出了所有推荐方法的性能。我们有以下发现:)
- SBPR and SocialMF outperform BPR. SBPR and SocialMF utilize both user-item interactions and social relations; while BPR only uses the user-item interactions. These improvements show the effectiveness of incorporating social relations for recommender systems. (SBPR和Socialf的表现优于BPR。SBPR和SocialMF同时利用用户项交互和社会关系;而BPR只使用用户项交互。这些改进显示了将社会关系纳入推荐系统的有效性。)
- In most cases, the two deep models, DeepSoR and GraphRec, obtain better performance than SBPR and SocialMF, which are odeled with shallow architectures. These improvements reflect the power of deep architectures on the task of recommendations. (在大多数情况下,DeepSoR和GraphRec这两个深层模型比SBPR和SocialMF(它们是用浅层架构建模的)获得更好的性能。这些改进反映了深层架构对建议任务的强大作用。)
- IRGAN achieves much better performance than BPR, while both of them utilize the user-item interactions only. IRGAN adopts the adversarial learning to optimize user and item representations; while BPR is a pair-wise ranking framework for Top-K traditional recommender systems. This suggests that adopting adversarial learning can provide more informative negative samples and thus improve the performance of the model. (IRGAN实现了比BPR更好的性能,而两者都只利用用户项交互。IRGAN采用对抗式学习来优化用户和项目表示;而BPR是Top-K传统推荐系统的成对排序框架。这表明采用对抗性学习可以提供更多信息量的负面样本,从而提高模型的性能。)
- Our model DASO consistently outperforms all the baselines. Compared with DeepSoR and GraphRec, our model proposes advanced model components to model user representations in both item domain and social domain. (我们的DASO模型始终优于所有基线。与DeepSoR和GraphRec相比,我们的模型提出了高级模型组件来对项目域和社交域中的用户表示进行建模。)
- In addition, our model harnesses the power of adversarial learning to generate more informative negative samples, which can help learn better user and item representations. (此外,我们的模型利用对抗性学习的力量生成更多信息量的负面样本,这有助于学习更好的用户和项目表示。)

3.2.1 Parameter Analysis
Next, we investigate how the value of λ \lambda λ affects the performance of the proposed framework. (接下来,我们研究 λ \lambda λ的值如何影响所提出框架的性能。)
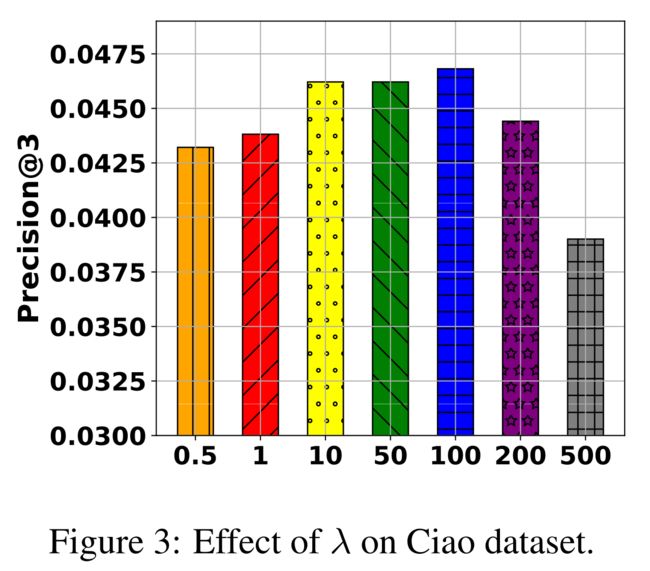
- The value of λ \lambda λ is to control the importance of cycle reconstruction. Figure 3 shows the performance with varied values of λ \lambda λ using Precision@3 as the measurement. The performance first increases as the value of λ \lambda λ gets larger and then starts to decrease once λ goes beyond 100. ( λ \lambda λ的值用于控制循环重建的重要性。图3显示了使用不同的 λ \lambda λ值时的性能Precision@3作为衡量标准。性能首先随着 λ \lambda λ的值变大而增加,然后在 λ \lambda λ超过100时开始降低。)
- The performance weakly depends on the parameter controlling the bidirectional influence, which suggests that transferring user’s information from the social domain to the item domain already significantly boosts the performance. (性能弱地依赖于控制双向影响的参数,这表明将用户信息从社交域转移到项目域已经显著提高了性能。)
- However, the user-item interactions and user-user connections are often very sparse, so the bidirectional mapping (Cycle Reconstruction) is proposed to help alleviate this data sparsity problem. Although the performance weakly depends on the bidirectional influence, we still observe that we can learn better user’s representation in both domains. (然而,用户项交互和用户连接通常非常稀疏,因此提出了双向映射(循环重构)来帮助缓解这种数据稀疏问题。虽然性能弱地依赖于双向影响,但我们仍然观察到,我们可以在这两个域中学习更好的用户表示。)
4 Related Work
-
(1) As suggested by the social theories [Marsden and Friedkin, 1993], people’s behaviours tend to be influenced by their social connections and interactions. Many existing social recommendation methods [Fan et al., 2018; Tang et al., 2013a; 2016b; Du et al., 2017; Ma et al., 2008] have shown that incorporating social relations can enhance the performance of the recommendations. (正如社会理论[Marsden and Friedkin,1993]所指出的那样,人们的行为往往会受到社会关系和互动的影响。许多现有的社会推荐方法[Fan et al.,2018;Tang et al.,2013a;2016b;Du et al.,2017;Ma et al.,2008]表明,融入社会关系可以提高推荐的绩效。)
-
In addition, deep neural networks have been adopted to enhance social recommender systems. (此外,深度神经网络已被用于增强社会推荐系统)
- DLMF [Deng et al., 2017] utilizes deep auto-encoder to initialize vectors for matrix factorization. (DLMF[Deng等人,2017]利用深度自动编码器初始化矩阵分解的向量。)
- DeepSoR [Fan et al., 2018] utilizes deep neural networks to capture nonlinear user representations in social relations and integrate them into ((probabilistic matrix factorization** for prediction. (DeepSoR[Fan et al.,2018]利用深度神经网络捕捉社会关系中的非线性用户表示,并将其集成到概率矩阵分解中进行预测。)
- GraphRec [Fan et al., 2019] proposes a graph neural net-works framework for social recommendation, which aggregates both user-item interactions information and social interaction information when performing prediction. (GraphRec[Fan et al.,2019]提出了一个用于社会推荐的图神经网络框架,该框架在进行预测时聚合了用户项交互信息和社会交互信息。)
-
(2) Some recent works have investigated adversarial learning for recommendation.
- IRGAN [Wang et al., 2017] proposes to unify the discriminative model and generative model with adversarial learning strategy for item recommendation. (IRGAN[Wang等人,2017]提出将判别模型和生成模型与项目推荐的对抗性学习策略相统一。)
- NMRN-GAN [Wang et al., 2018b] introduces the adversarial learning with negative sampling for streaming recommendation. (NMRN-GAN[Wang等人,2018b]为流媒体推荐引入了带有负采样的对抗式学习。)
-
Despite the compelling success achieved by many works, little attention has been paid to social recommendation with adversarial learning. Therefore, we propose a deep adversarial social recommender system to fill this gap. (尽管许多作品取得了令人信服的成功,但很少有人关注具有对抗性学习的社会推荐。因此,我们提出了一个深度对抗的社会推荐系统来填补这一空白。)
5 Conclusion and Future Work
- (1) In this paper, we present a Deep Adversarial SOcial recommendation model (DASO), which learns separated user representations in item domain and social domain. (在本文中,我们提出了一个深度对抗性社会推荐模型(DASO),该模型学习项目域和社会域中分离的用户表示。)
- (2) Particularly, we propose to transfer users’ information from social domain to item domain by using a bidirectional mapping method. (特别地,我们建议使用双向映射方法将用户的信息从社交领域转移到项目领域。)
- (3) In addition, we also introduce the adversarial learning to optimize our entire framework by generating informative negative samples. (此外,我们还引入了对抗式学习,通过生成信息丰富的负样本来优化我们的整个框架。)
- Comprehensive experiments on two real-world datasets show the effectiveness of our model. The calculation of softmax function in item/social domain generator involves all items/users, which is time-consuming and computationally inefficient. (在两个真实数据集上的综合实验表明了该模型的有效性。在item/social domain generator中,softmax函数的计算涉及所有item/users,这既耗时又计算效率低下。)
- Therefore, hierarchical softmax [Morin and Bengio, 2005; Mikolov et al., 2013; Wang et al., 2018a], which is a replacement for softmax, would be considered to speed up the calculation in both generators in the future direction. (因此,替代softmax的分层softmax[Morin and Bengio,2005;Mikolov et al.,2013;Wang et al.,2018a]将被认为在未来的方向上加快两台生成器的计算速度。)