用于强化学习的自动驾驶仿真场景highway-env(1)
在强化学习过程中,一个可交互,可定制,直观的交互场景必不可少。
最近发现一个自动驾驶的虚拟环境,本文主要来说明下如何使用该environment
具体项目的github地址
一、 定制环境
quickly experience
如下代码可以快速创建一个env
import gym
import highway_env
from matplotlib import pyplot as plt
env = gym.make('highway-v0')
env.reset()
for _ in range(10):
action = env.action_type.actions_indexes["IDLE"]
obs, reward, down, info = env.step(action)
env.render()
plt.imshow(env.render(mode="rgb_array"))
plt.show()
运行结果如下所示:
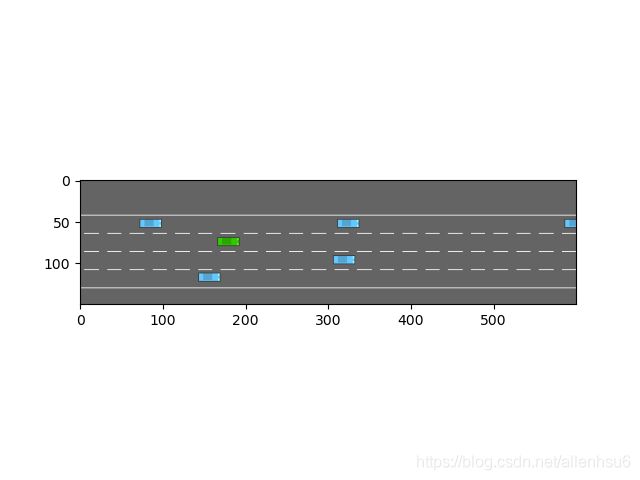
所有的场景包括五种,上文只是说明其中的highway高速路场景。
接下来,我们详细说明五种场景。
1. highway
特点
- 速度越快,奖励越高
- 靠右行驶,奖励高
- 与其他car交互实现避障
使用
env = gym.make("highway-v0")
默认参数
{
"observation": {
"type": "Kinematics"
},
"action": {
"type": "DiscreteMetaAction",
},
"lanes_count": 4,
"vehicles_count": 50,
"duration": 40, # [s]
"initial_spacing": 2,
"collision_reward": -1, # 与其他车发生碰撞的reword
"reward_speed_range": [20, 30], # [m/s] -> [0, HighwayEnv.HIGH_SPEED_REWARD]线性映射.
"simulation_frequency": 15, # [Hz]
"policy_frequency": 1, # [Hz]
"other_vehicles_type": "highway_env.vehicle.behavior.IDMVehicle",
"screen_width": 600, # [px]
"screen_height": 150, # [px]
"centering_position": [0.3, 0.5],
"scaling": 5.5,
"show_trajectories": False,
"render_agent": True,
"offscreen_rendering": False
}
2. merge
特点
- 首先在主路,然后前方遇到并道
- 并道上有car
- 要求实现安全并道
使用
env = gym.make("merge-v0")
默认参数
{
"observation": {
"type": "TimeToCollision"
},
"action": {
"type": "DiscreteMetaAction"
},
"simulation_frequency": 15, # [Hz]
"policy_frequency": 1, # [Hz]
"other_vehicles_type": "highway_env.vehicle.behavior.IDMVehicle",
"screen_width": 600, # [px]
"screen_height": 150, # [px]
"centering_position": [0.3, 0.5],
"scaling": 5.5,
"show_trajectories": False,
"render_agent": True,
"offscreen_rendering": False
}
3. roundabout
特点
- 环形公路
- longitudinal control
使用
env = gym.make("roundabout-v0")
默认参数
{
"observation": {
"type": "TimeToCollision"
},
"action": {
"type": "DiscreteMetaAction"
},
"incoming_vehicle_destination": None,
"duration": 11,
"simulation_frequency": 15, # [Hz]
"policy_frequency": 1, # [Hz]
"other_vehicles_type": "highway_env.vehicle.behavior.IDMVehicle",
"screen_width": 600, # [px]
"screen_height": 600, # [px]
"centering_position": [0.5, 0.6],
"scaling": 5.5,
"show_trajectories": False,
"render_agent": True,
"offscreen_rendering": False
}
4. parking
特点
- 停车场
- 合适的朝向停到合适的车位
使用
env = gym.make("parking-v0")
默认参数
{
"observation": {
"type": "KinematicsGoal",
"features": ['x', 'y', 'vx', 'vy', 'cos_h', 'sin_h'],
"scales": [100, 100, 5, 5, 1, 1],
"normalize": False
},
"action": {
"type": "ContinuousAction"
},
"simulation_frequency": 15,
"policy_frequency": 5,
"screen_width": 600,
"screen_height": 300,
"centering_position": [0.5, 0.5],
"scaling": 7
"show_trajectories": False,
"render_agent": True,
"offscreen_rendering": False
5. intersection
特点
- 十字路口
- 左转
使用
env = gym.make("intersection-v0")
默认参数
{
"observation": {
"type": "Kinematics",
"vehicles_count": 15,
"features": ["presence", "x", "y", "vx", "vy", "cos_h", "sin_h"],
"features_range": {
"x": [-100, 100],
"y": [-100, 100],
"vx": [-20, 20],
"vy": [-20, 20],
},
"absolute": True,
"flatten": False,
"observe_intentions": False
},
"action": {
"type": "DiscreteMetaAction",
"longitudinal": False,
"lateral": True
},
"duration": 13, # [s]
"destination": "o1",
"initial_vehicle_count": 10,
"spawn_probability": 0.6,
"screen_width": 600,
"screen_height": 600,
"centering_position": [0.5, 0.6],
"scaling": 5.5 * 1.3,
"collision_reward": IntersectionEnv.COLLISION_REWARD,
"normalize_reward": False
}
二、关于参数
打印当前参数
import gym
import highway_env
import pprint
env = gym.make('highway-v0')
env.reset()
pprint.pprint(env.config)
output:
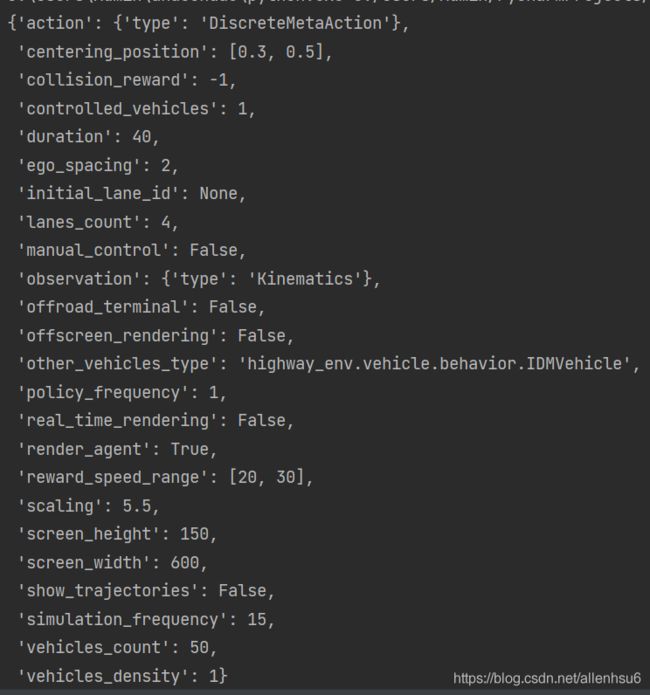
配置参数
env.config["lanes_count"] = 2
env.reset()
output:
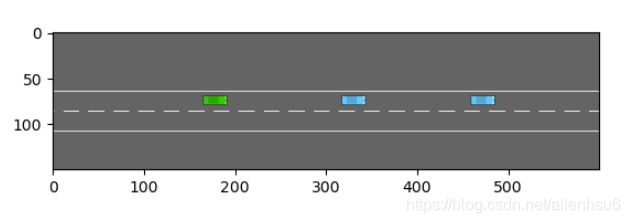
三、训练agent
场景与很多对应的算法平台可以直接对接。比如:
- rl-agents
- baselines
- stable-baselines
example
使用stable-baselines的一个demo:
import gym
import highway_env
import numpy as np
from stable_baselines import HER, SAC, DDPG, TD3
from stable_baselines.ddpg import NormalActionNoise
env = gym.make("parking-v0")
n_sampled_goal = 4
model = HER('MlpPolicy', env, SAC, n_sampled_goal=n_sampled_goal,
goal_selection_strategy='future', verbose=1,
buffer_size=int(1e6),
learning_rate=1e-3,
gamma=0.95, batch_size=256,
policy_kwargs=dict(layer=[256, 256, 256]))
model.learn(int(2e5))
model.save('her_sac_highway')
obs = env.reset()
# 100次的reward作为评价指标
episode_reward = 0
for _ in range(100):
action, _ = model.predict(obs)
obs, reward, done, info = env.step(action)
env.render()
episode_reward += reward
if done or info.get('is_success', False):
print("Reward:", episode_reward, "Success?", info.get('is_success', False))
episode_reward = 0.0
obs = env.reset()