DSGN: Deep Stereo Geometry Network for 3D Object Detection(2020.4)
文章:https://arxiv.org/pdf/2001.03398.pdf
代码:https://github.com/Jia-Research-Lab/DSGN
摘要
我们的方法:Deep Stereo Geometry Network (DSGN),利用可为的立体表达(3D geometric volume)对3D物体进行检测,有效的在3D刚体空间对3D结构表达,并同时学习深度信息和语义。
1. 介绍
本文提出了基于双目的端到端的3D物体检测方法,如图1,即Deep Stereo Geometry Network (DSGN),其中依赖于从2D特征到3D结构的空间变换,即3D geometric volume (3DGV).
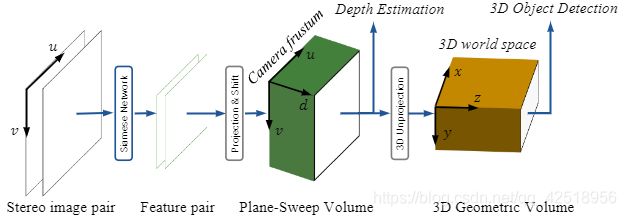
图1:DSGN从双目图像对中同时估计深度并进行3D检测,它在中间生成一个平面扫描体和3D几何体,以表示两个不同3D空间中的3D结构
3DGV的特点在于能够构建包含3D几何信息的3D volume的方法。3D geometric volume(3DGV)定义在3D世界空间,是从相机视锥中构造的Plane-Sweep Volum(PSV)[11,12]转换而来。像素间的相关性约束能够由PSV学习,而真实世界物体的3D特征则由3DGV学习。由于volume的构造是全微分的,因此能够同时对双目匹配和物体检测进行优化。
volume表达有两点好处:(1)能够轻易约束像素相关性的一致性,并将整个深度信息融入3D real-world volume(2)为3D表达提供几何信息,使其能学习真实世界物体的3D几何特征。
贡献:
(1)为了建立2D图像与3D空间之间的关系,在plane-sweep volume建立了立体对应关系,然后将其转化到3D geometric volume,使其包含在3D空间的3D几何及语义线索。(2)设计端到端的方法来提取像素特征用作立体匹配,使用高级特征用作物体识别。提出的网络同时估计深度并检测3D物体,能够实际应用。(3)比其他基于双目的3D物体检测方法在AP衡量上高出10%
3. 方法
3.1 动机
建立有效3D表达的关键取决于将3D几何信息转换到3D空间的能力。双目相机提供明确的像素关系来计算深度,为了设计利用此约束的网络,寻找了能够同时提取双目对应的像素特征和用于语义线索的高阶特征的深层架构
另一方面,假定沿着穿过每个像素的投影线施加像素对应约束,在该像素的深度被确定。 为此,我们从双目图像对创建一个中间的Plane-Sweep Volume,以学习相机的立体约束,然后将其转换为3D空间中的3D volume。 在此3D volume中,从Plane-Sweep Volume中提取了3D几何信息,从而很学习现实对象的3D特征。
3.2 深层双目几何网络:
如图2,输入为双目图像对,使用Siamese network提取特征,并构建plane-sweep volume (PSV)来学习像素关系。通过进行可微变换,将PSV变化到3D geometric volume (3DGV)来估计3D世界的3D几何,然后在3D volume上用3D神经网络学习3D目标检测的必要结构
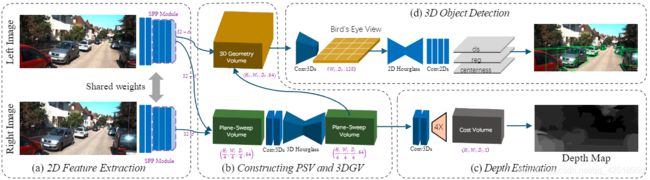
图2:Deep Stereo Geometry Network (DSGN)由四部分组成:(1)2D图像特征提取器来捕获像素特征和高阶特征(2)建立plane-sweep volume 和 3D geometric volume(3)从PSV上估计深度(4)在3DGV上进行3D目标检测
3.2.1 图像特征提取
双目匹配和目标检测的结构不同,为保证匹配精度,采用PSMNet【4】 ,由于检测网络需要在高级语义和大量内容信息上辨别特征,对网络进行改进来捕获更多的高阶信息。
网络结构细节:
这里按照【16】使用conv 1, conv 2, ..., conv 5,对2D特征提取的主要改进:
(1)将更多的计算量从conv 3挪到 conv 4 和 conv 5,将conv 2到conv 5的basic block从{3,16,3,3}更改为{3,6,12,4}
(2)将PSMNet中的SPP模块与输出层conv 4和conv5连接
(3)conv 1输出通道是64而不是32,输出的basic residual block通道数是192而不是128
3.2.2 构建 3D Geometric Volume
为了学习3D空间中的3D卷积特征,先通过将PSV变换到3D空间来建立3DGV。为了一般化,将3D空间的感性区域按大小为![]() 的3D体素(voxel)分割,分别为相机视角的左、下、前方向(X,Y,Z),宽、高、深度。每个voxel大小为
的3D体素(voxel)分割,分别为相机视角的左、下、前方向(X,Y,Z),宽、高、深度。每个voxel大小为![]()
PSV:
在双目视觉中,图像对被用来建立基于视察的损失项来计算匹配损失,指左图中的i像素在对应右图平行变化的视差值d,深度与视差成比例。因此无法区分近似视差值的距离,如39米和40米处几乎没有差别(<0.25像素)。
另一种建立损失的方法是按照典型的plane sweeping方法,通过将左图的特征![]() 与从右图投影的
与从右图投影的![]() 特征以同间距深度(避免从3D空间提取的特征图不平衡)相连接。
特征以同间距深度(避免从3D空间提取的特征图不平衡)相连接。
PSV的坐标由(u,v,d)表示,其中(u,v)为像素坐标,d是深度,并将其所在空间称为grid camera frustum space。深度坐标d按照预定义的3D网格间距vd(体素的深度单位)进行均匀采样,串联的信息能够使网络学习用来目标识别的语义特征
我们对volume采用3D卷积,并在最后对所有深度得到匹配损失量,为减少损失只使用一个3D hourglass模块,PSW中用了3个,由于整个网络可微,下降结果明显。
3D Geometric Volume:
使用已知的相机内参,利用反向3D投影,在计算匹配损失前,将PSV最后的特征图从相机空间(u,v,d)到3D空间(x,y,z):
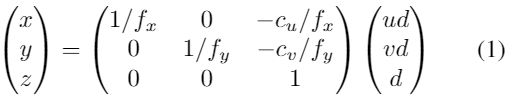
fx,fy为水平和垂直的焦距长度,整个变化完全可微,通过消除预定义的刚性背景背景如天空等来计算,可以由三维差值来进行变换。
图3展示了转换过程,当物体识别在3D空间(欧拉空间)被学习,在相机frustum中施加了像素相关性约束(红虚线),在这两个表达中明显不同
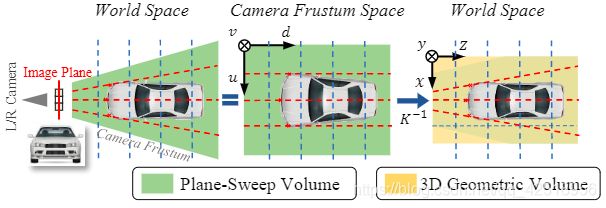
图3:volume变换:图像被成像平面采集(红实线),PSV在左侧camera frustum中将图像以等深度(蓝色虚线)投影,如世界空间(左图)和camera frustum space(中间)。相机空间中,车是失真的,由K的逆矩阵进行转换后,PSV被转换到3DGV,重新储存了车辆。
PSV中最后的特征图,low cost voxel(u,v,d)表示物体存在于光心与像素点(u,v)延长线的深度d的高概率。随着3D空间中的转换,low cost的特征表示这个voxle在场景前面,能够作为3D几何结构的特征为后面的3D网络所学习。
3.2.3 从Plane-Sweep cost回归深度
为了计算plane-sweep的匹配损失,通过使用2个3D卷积得到1D cost来减少PSV的最终特征图,并且使用arg-min计算带![]() 概率的所有深度坐标 :
概率的所有深度坐标 :
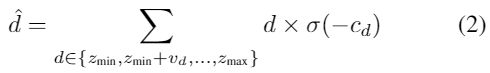
深度坐标用预定义的以vd为单位的[zmin,zmax]范围均匀采样,softmax函数使模型对每个像素选择一个深度层(根据每个层所占概率进行,加权加和)
3.2.4 3D geometric volume上的3D目标检测:
由2D检测FCOS【46】基础上,使用了其中的centerness并设计了基于距离的方法来确定目标。由于同类物体在3D场景中大小相似,因此也保留了anchor
让![]() 作为大小为(W,H,D)的3DGV的特征图。在自动驾驶场景中,对高度信息进行下采样,得到用于鸟撖图大小为(W,H)的特征图F
作为大小为(W,H,D)的3DGV的特征图。在自动驾驶场景中,对高度信息进行下采样,得到用于鸟撖图大小为(W,H)的特征图F
对于F中的每个位置(x,z)(只考虑横向偏移和深度),提供了多种不同大小和方向的anchor,用Anchors A和ground-truth boxes G表示位置、大小和方向。如:![]() and
and![]() 。我们的网络从anchor中回归,并通过
。我们的网络从anchor中回归,并通过![]()
![]() 得到最终结果。其中,
得到最终结果。其中,![]() 表示anchor 方向的数量,
表示anchor 方向的数量, ![]() 表示每个参数的学习出的偏差
表示每个参数的学习出的偏差
基于距离的目标分配:
将目标方向考虑进去,我们提出基于距离的目标分配。距离由anchor和ground-truth box的八个角点距离定义:
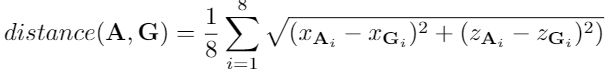
为了平衡正、负例的比率,让与ground-truth相距N个最近距离的anchor作为正例,其中![]() ,k是鸟撖图中ground-truth box中voxels的数量,y是正样本数。我们的中心度由八个角点的负归一化距离的指数值定义:
,k是鸟撖图中ground-truth box中voxels的数量,y是正样本数。我们的中心度由八个角点的负归一化距离的指数值定义:
![]()
其中norm是min-max归一化
3.3 多任务训练
本网络使用立体匹配网络,3D目标检测器以端到端的方法训练。用多任务损失训练整个3D目标检测器:
![]()
对于深度回归损失,采用L1 loss:
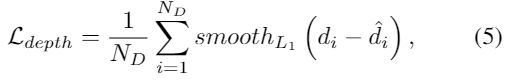
其中Nd是ground-truth 深度的像素点数 。
对于损失分类,采用focal loss处理3D场景中的分类不平衡问题:
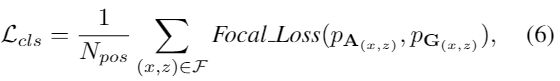
其中Npos,表示正样本数量,对中心度使用Binary cross-entropy (BCE) loss
对于3D bounding box回归,使用L1 loss:

其中Fpos 为所有鸟撖图中正样本
我们使用两种不同回归目标,同时/不同时学习所有参数
(1)分别优化box参数。回归损失直接应用到(x, y, z, h, w, l, θ) 的偏移量
(2)同时优化box 角点。损失由3D anchors估计的box与ground-truth box之间的平均L1距离构成。
4 实验
数据集
在 KITTI 3D object detection dataset上进行评估
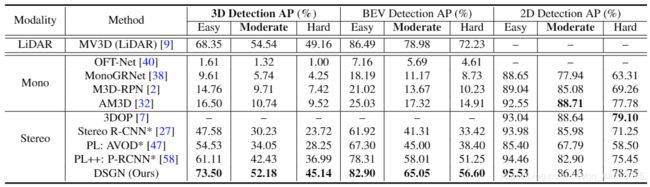
对于 3D 和 BEV(Bird's Eye View)目标检测,DSGN 超越了所有基于图像的 3D 目标检测器;在 2D 检测上,仅仅比 3DOP 要差一点。
DSGN 首次得到了与基于 LiDAR 的目标检测器 MV3D 相当的准确率,该结果证明至少在低速自动驾驶条件下是有应用前景的。这些都验证了 3DGV 的有效性,表明 3DGV 构建了 2D 图像和 3D 空间的桥梁。

表格可以看出:
(1)点云监督是很重要的
(2)基于双目的方法要远远优于基于单目的方法
(3)在3DGV前使用PSCV能充分还原目标本来的3D结构