【论文简述】Vis-MVSNet: Visibility-Aware Multi-view Stereo Network(IJCV 2022)
一、论文简述
1. 第一作者:Jingyang Zhang
2. 发表年份:2022
3. 发表期刊:IJCV、BMVC
4. 关键词:MVS、可见性、MVSNet
5. 探索动机:MVS的可见性
- One critical factor in MVS is the pixel-wise visibility: whether a 3D point is visible in given images. However, such visibility information is unknown before the 3D model is densely recovered, which implies a chicken-and-egg problem.
- However, very few of the current learning-based MVS methods have acknowledged this problem and have explicitly handled the visibility issue.
- While it is possible that the network could implicitly learn how to discard the invisible views for each pixel, the unsolved visibility problem may inevitably deteriorate the final reconstruction.
6. 工作目标:解决可见性问题
In this paper, we explicitly infer and integrate the pixel-wise occlusion information in the MVS network via the matching uncertainty estimation. The pair-wise uncertainty map is jointly inferred with the pair-wise depth map, which is further used as weighting guidance during the multi-view cost volume fusion. As such, the adverse influence of occluded pixels is suppressed in the cost fusion.
7. 核心思想:提出了一个端到端网络的结构,考虑了像素可见性信息。深度图由多视图图像分两步估计。
- 首先,匹配参考图像和源图像对,得到代表对匹配质量的潜在体体进一步回归得到深度图和不确定性图的中间估计,其中不确定性由概率体的深度熵转换而来。
- 其次,利用对匹配的不确定性作为加权引导,将所有成对潜在体融合到一个多视图代价体中,以减弱不匹配像素。融合体正则化并回归到最终深度估计。
- 集成了组相关和从粗到细的策略,以进一步提高整体重建质量。
- 网络是端到端可训练的,不确定性部分以无监督的方式训练。因此,可以直接利用现有的具有真实深度图的MVS数据集来训练具有可见性的MVS网络。
8. 实验结果:Vis-MVSNet在DTU、BlendedMVS 数据集上进行了评估,并在Tanks and Temples 和ETH3D数据集上进行了基准测试。在Tanks and Temples在线基准测试(截止2020年5月1日)中该方法排名中第一名,是Tanks and Temples高级数据集和ETH3D高分辨率集中最好的基于学习的方法。
9. 论文和代码下载:
https://link.springer.com/content/pdf/10.1007/s11263-022-01697-3.pdf?pdf=button
https://github.com/jzhangbs/Vis-MVSNet
二、实现过程
1. Vis-MVSNet概述
基线结构类似于CasMVSNet ,应用了从粗到细的策略来进行多视图深度图估计。首先,将参考图像I0和一组相邻的源图像{Ii}i输入2D UNet用于多尺度图像特征的提取,用于从低分辨率到高分辨率的三个阶段的深度估计和不确定性图。对于第k阶段的重建,根据不确定性对潜体进行融合,构造代价体,正则化并用于估计与输入特征图分辨率相同的深度图Dk,0。前一阶段的中间深度图将用于下一阶段的代价体构建。最后,D3,0作为系统的最终输出D0。

2. 特征提取
使用沙漏形编码器-解码器UNet,输出分辨率分别为1/8、1/4、1/2的32通道的特征图。
3. 代价体和正则化
与先前工作构建所有视图统一的代价体不同,本文是构建每一对参考视图和源视图的代价体,并通过组相关的方式,将32通道的特征图,分为8组,最终得到8通道的组相关体Ck,i,第i个第k阶段的大小为Nd,k×H×W×Nc,其中Nd,k为第k阶段的深度假设数,Nc=8为按组相关组数。
延续Cas-MVSNet的思想,从粗到细的结构共分三个阶段,对于第一阶段,深度范围为[dmin, dmin + 2∆d),深度数为Nd,1,其中dmin,∆d和Nd,1是预先确定的。对于第k阶段(k∈{2,3}),减小深度范围、样本数量和间隔。范围以上一阶段的深度估计为中心,像素x的深度范围为[Dk−1,0−wk∆d, Dk−1,0 + wk∆d),深度数为pkNd,k,其中wk < 1和pk < 1为预定义的缩放因子,Dk−1,0为上一阶段k−1像素x的最终深度估计。
代价体正则化分两步。首先,每个对代价体分别正则化为一个潜在体Vk,i。然后,将所有潜在体融合为Vk, Vk进一步正则化为概率体Pk,并通过soft-argmax运算回归得到到当前阶段的最终深度图Dk,0。潜在体的融合是可见的。具体来说,首先通过联合推断深度和不确定性来测量可见性。每个潜在体通过附加的3D CNNs和softmax运算转换为概率体Pk,i。然后通过soft-argmax和熵运算联合推断深度图Dk,i和相应的不确定性图Uk,i。不确定度图将被用作潜在体融合期间的加权指导。
4. 逐对联合的深度和不确定性估计
如前一节所述,获得了联合深度和不确定性估计的对概率体,通过soft-argmax回归深度图。为简单起见,将所有深度假设的概率分布表示为{Pi,j},省略了阶段编号k。soft-argmax运算等价于计算该分布的期望,Di计算为:

为了联合回归深度估计及其不确定性,我们假设深度估计遵循拉普拉斯分布。在这种情况下,估计深度和不确定性使观测到的真值的可能性最大化为:
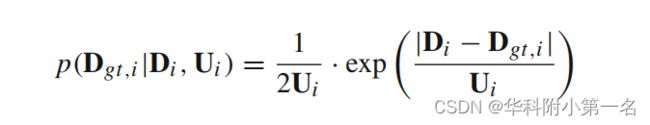
其中Ui是像素的深度估计的不确定性。注意,概率分布{Pi, j}也反映了匹配质量。因此,我们应用{Pi, j}Nj= d1的熵图Hi来衡量深度估计质量。通过函数fu将Hi转换为不确定性图Ui,fu为一个浅层的2D CNN:

采用熵的原因是分布的随机性与单峰分布呈负相关。单模态是深度估计可信度较高的一个指标。
为了联合学习深度图估计Di及其不确定性Ui,我们最小化上面描述的负对数似然:

公式中省略了常数。为了数值的稳定性,在实践中我们推断Si = log Ui而不是直接用Ui。log不确定性图Si也通过一个浅层的2D CNN从熵图Hi转换而来。
损失(公式4)也可以解释为带有正则化项的估计和真值之间L1损失的衰减。直觉是,在训练过程中应该减少错误样本的干扰。
5. 体融合
给定对潜在代价体{Vi},通过加权和融合得到体V,其中权重与估计的对不确定性呈负相关。

从观察来看,不确定性大的像素点更有可能位于遮挡区域。因此,潜在体中的这些值可以被衰减。加权和的替代方案是将Si设置为阈值,并对每个像素执行硬可见性选择。然而,没有Si值的解释,我们只能做经验阈值,这可能不通用。相反,加权和自然地融合了所有视图,并以相关的方式考虑了log不确定性Si。
6. 训练损失
对于每个阶段,计算最终深度图的对L1损失、对联合损失和L1损失,总损失是所有三个阶段损失的加权和。为了将不同训练场景中的尺度归一化,所有的深度差异都除以最后阶段预先定义的深度间隔。

由于不确定性损失倾向于过度放松对深度和不确定性估计,因此包含了对L1损失。这里的对L1损失可以保证合格的对深度图估计。
7. 点云生成(写的比较详细)
在生成所有视图的深度图后,深度图通过光度和几何一致性过滤,融合成统一的点云。
概率图(光度一致性)。额外生成概率图过滤不可靠的像素。围绕最终深度估计的[D−2,D + 2]范围内深度概率计算总概率得到最终的概率图。此外,在从粗到细架构中有不同阶段的概率图,因此过滤准则是当且仅当三个阶段的所有概率图都高于相应的阈值pt,1, pt,2, pt,3时,参考视图中的像素将被保留。
几何一致性。和之前的方式一样。
几何可见性融合。所有源深度图都被投影到参考视图,其中参考深度图中的每个像素可以接收不同数量的深度值。对于每个像素,计算每个深度的以下度量:(1)遮挡,这是遮挡这个像素的深度的数量(深度值小于这个深度值);(2)违例,即投影后该深度在自由空间中的视图数(投影深度小于源视图中相应位置的值);(3)稳定性,即遮挡减去违例。最后选取非负稳定性的最小深度值作为该像素的新深度值。更多关于遮挡、违例和稳定性的细节可以在原文中找到(Merrell et al., 2007)。与单纯选取深度候选值的中位数相比,基于可见性的融合方法略微提高了点云质量。
几何平均融合。通过对源视图重投影深度进行平均,可以降低估计深度值的噪声。对参考深度图中于深度为d0的像素p0,我们从所有一致的源视图Ic中收集重投影的深度{di}i∈Ic。平均融合所有深度得到最后结果。
小段滤波。加入了小段滤波,观察到小簇的飞行点通常是空间中的噪声,可以根据它们的簇大小轻松地删除它们,这可以在深度图级别完成。给定一个深度图,如果两个相邻像素之间都有效且深度差不大,则可以在两个相邻像素之间存在一条边的情况下构建一个图。然后去除连接的少量像素的部分。在实际应用中,使用深度差百分比阈值为0.05 %,簇大小为10。
整个滤波和融合机制如下所示:
- 概率图滤波;
- 几何一致性滤波;
- 几何可见性融合;
- 几何一致性滤波;
- 几何平均融合;
- 几何一致性滤波;
- 小段滤波。
- 如果一个像素在某个环节被过滤掉,后续步骤将不涉及。

8. 实验
8.1. 实现
源图像的预选:所考虑的源视图应该是条件良好的,即参考图像和源图像对的重叠区域的并集可以覆盖参考图的像大部分。因此,在稀疏重建中,所有的源视图都是根据考虑到所有公共轨迹的基线角度的得分来排序的。通常,与参考视图接近的源视图是首选视图。
训练:网络在BlendedMVS的训练集上训练,用于Tanks and Temples和消融实验,并在DTU训练集上训练,进行DTU基准测试。对于这两个训练集,输入图像大小为640 × 512,输出深度图大小为320 × 256。训练时源视图的数量设置为Nv=3。对于不同阶段的深度样本,我们设深度假设数为Nd,1, Nd,2, Nd,3 =32, 16, 8,深度范围缩放因子分别为w2, w3 = 1/4, 1/16 。各阶段损失权重λ1、λ2、λ3 =0.5,1,2。该网络被Adam优化器训练为16万次迭代,批大小为2。所有实验均使用一台NVidia V100显卡。
8.2. 结果
DTU数据集基准:输入原始大小的图像(1600×1200),设置视图数N为5,效果很好。

Tanks & Temples:SOTA
Intermediate Set

Advanced Set
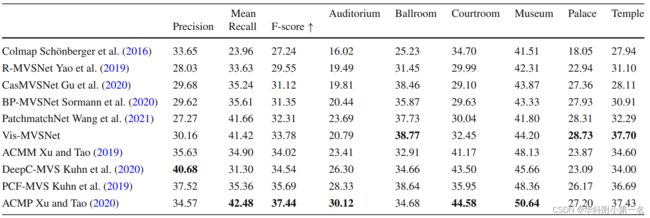
ETH3D。第二好
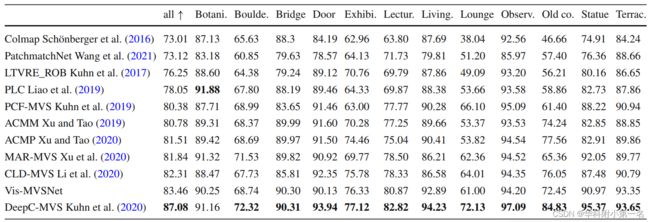
7.5. 消融实验
讨论具有隐式或显式可见性意识的体融合的可选方法。
Baseline:方差
Averaging:直接平均
Max Pooling:取最大
Weighted Averaging:vis without the coarse-to-fine architecture.
