尽管微服务中的“微”一词表示服务的规模,但它并不是使用微服务的唯一标准。当团队转向基于微服务的架构时,他们旨在提高敏捷性以及自主且频繁地部署功能。很难确定这种架构风格的简单定义。我喜欢Adrian Cockcroft的关于微服务的简短定义: “ 面向服务的体系结构,它由松散耦合的、具有上下文边界的元素组成。”
尽管这定义了高级设计启发式技术,但微服务架构具有一些独特的特性,使其有别于以往的面向服务的架构。以下是其中一些特征。这些以及其他一些文档都有据可查-Martin Fowler的文章和Sam Newman的Building Microservices,仅举几例。
- 服务具有围绕业务上下文而不是任意技术上抽象的明确定义的边界
- 通过意图公开界面隐藏实现细节并公开功能
- 服务不会共享超出其边界的内部结构。例如,不共享数据库。
- 服务可以抵抗故障。
- 团队独立拥有职能,并能够自主发布变更
- 团队拥护自动化文化。例如,自动化测试,持续集成和持续交付
简而言之,我们可以将这种体系结构样式总结如下:
松耦合的面向服务的体系结构,其中每个服务都包含在定义明确的有界上下文中,从而可以快速,频繁且可靠地交付应用程序。
领域驱动设计和有界上下文
微服务的力量来自明确定义其职责并划分它们之间的边界。此处的目的是在边界内建立高凝聚力,并在边界外建立低耦合(banq注:高凝聚低耦合)。也就是说,趋于一起改变的事物应该属于同一事物。就像在许多现实生活中的问题一样,这说起来容易做起来难,业务在不断发展,逻辑的假设前提也会随之改变。因此,重构的能力是设计系统时要考虑的另一关键问题。
领域驱动设计(DDD)是关键,在我们看来,这是设计微服务时必不可少的工具,无论是打破整体还是实施未开发项目。领域驱动的设计(Eric Evans在他的书中提出)是一组思想、原理和模式,可帮助基于业务领域的基础模型设计软件系统。开发人员和领域专家共同合作,以通用的通用语言创建业务模型。然后,他们将这些模型绑定到有意义的系统,并在这些系统与从事这些服务的团队之间建立协作协议。更重要的是,他们设计了系统之间的概念轮廓或边界。
微服务设计从这些概念中汲取了灵感,因为所有这些原理都有助于构建可以相互独立变化和发展的模块化系统。
在继续进行之前,让我们快速了解一下DDD的一些基本术语。域驱动设计的完整概述超出了本博客的范围。我们强烈建议任何尝试构建微服务的人推荐Eric Evans的书籍。
领域:代表组织的工作。例如它是零售或电子商务。
子域:组织或组织内的业务部门。域由多个子域组成。
无所不在的语言:这是用于表达模型的语言。在下面的示例中,Item是一个模型,属于这些子域中每个子域的通用语言。开发人员,产品经理,领域专家和业务涉众都同意使用相同的语言,并在其工件(代码,产品文档等)中使用该语言。
有界上下文:域驱动的设计将有界上下文定义为“单词或语句能确定其含义的设置”。简而言之,这意味着模型是有意义的边界。在上面的示例中,“项目”在每种上下文中的含义不同。在目录上下文中,项目表示可售产品,而在购物车上下文中,则表示客户已将其添加到购物车中的项目。在“运输”上下文中,它表示将要运送给客户的仓库物料。这些模型中的每一个都是不同的,并且每个都有不同的含义,并且可能包含不同的属性。通过将这些模型分离并隔离在它们各自的边界内,我们可以自由地表达模型而没有歧义。
注意:必须了解子域和有界上下文之间的区别。子域属于问题空间,即您的企业如何看待问题,而受限上下文属于解决方案空间,即我们将如何实施问题的解决方案。从理论上讲,每个子域可能具有多个有界上下文,尽管我们努力为每个子域提供一个有界上下文。
微服务与有限上下文如何相关
现在,微服务在哪里适合?可以说每个有界上下文都映射到微服务吗?是的,我们将明白为什么。在某些情况下,有界上下文的边界或轮廓可能很大。
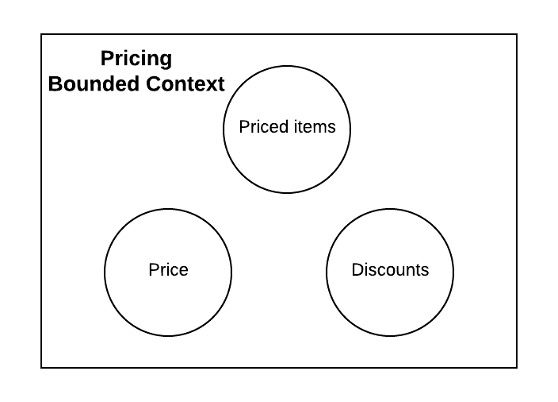
考虑上面的例子。定价绑定上下文具有三个不同的模型-价格,定价项目和折扣,每个模型负责目录项目的价格,计算项目列表的总价格并分别应用折扣。我们可以创建一个包含以上所有模型的系统,但是它可能会成为一个不合理的大型应用程序。如前所述,每个数据模型都有其不变性和业务规则。随着时间的流逝,如果我们不小心的话,系统可能会变成一个泥泞的大球,边界模糊,职责重叠,甚至可能回到我们开始的地方—一个整体。
对系统进行建模的另一种方法是将相关模型分离或分组为单独的微服务。在DDD中,这些模型(价格,定价项目和折扣)被称为聚合Aggregates。聚合是组成相关模型的独立模型。您只能通过已发布的界面更改聚合的状态,并且聚合可确保一致性,并且不变量保持良好状态。
聚合是关联对象的集群,被视为数据更改的单元。外部引用仅限于AGGREGATE的一个成员,称为根。一组一致性规则适用于AGGREGATE的边界。
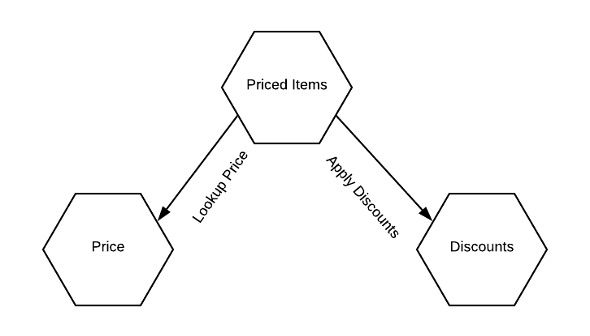
同样,没有必要一定要将每个聚合建模为一个独特的微服务。图中的服务(聚合)是一对一关系,但这不一定是规则。在某些情况下,在单个服务中托管多个聚合可能是有意义的,尤其是当我们不完全了解业务领域时。需要注意的重要一点是,只能在单个聚合中保证一致性,并且只能通过已发布的界面修改聚合。任何违反这些规定的行为都有变成大泥球的风险。
上下文映射—精确划分微服务边界的一种方法
整体结构通常由不同的模型组成,大多数模型是紧密耦合的-模型可能知道彼此的亲密细节,更改一个模型可能会对另一个模型产生副作用,依此类推。分解整体时,确定这些模型(在这种情况下为集合)及其关系至关重要。上下文映射可以帮助我们做到这一点。它们用于标识和定义各种有界上下文和聚合之间的关系。在上面的示例中,有界上下文定义了模型的边界(价格,折扣等),而上下文映射定义了这些模型之间以及不同有界上下文之间的关系。
上下文映射的完整探索不在本博客的讨论范围之内,但我们将通过一个示例进行说明。下图显示了处理电子商务订单付款的各种应用程序。
- 购物车上下文负责订单的在线授权;订单上下文流程过帐付款后的付款流程;联络中心会处理所有例外情况,例如重试付款和更改用于订单的付款方式
- 为了简单起见,让我们假设所有这些上下文都是作为单独的服务实现的
- 所有这些上下文封装了相同的模型。
- 请注意,这些模型在逻辑上是相同的。也就是说,它们都遵循相同的通用域语言-付款方式,授权和结算。只是它们是不同上下文的一部分。
重新定义服务边界—将聚合映射到正确的上下文
错误案例如下图:
电子商务中所有模型都直接与单个支付聚合的网关上下文(payment gateway context)集成,支付需要保证事务性,但是由于与多个服务集成,支付的事务性就不能通过在各种服务之间强制执行不变性和一致性来实现,(banq注:当然有人就提出分布式事务的概念来在这些不同服务之间实现支付过程的事务性,这其实是在错误设计基础上的伪概念)。
请注意,支付网关中的任何更改都将迫使更改多个服务,并可能更改多个团队,因为不同的组可以拥有这些上下文。
进行一些调整并使聚合与正确的上下文对齐,我们可以更好地表示这些子域如下图。发生了很多变化。让我们回顾一下更改:
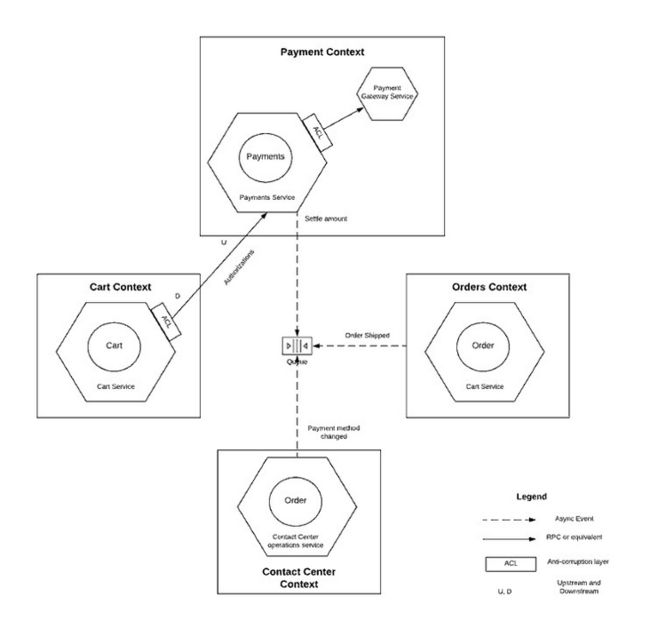
通常,整体(单体)或遗留应用程序具有许多聚合,通常具有重叠的边界。创建这些聚合及其依赖关系的上下文地图有助于我们了解将要从这些整体中摆脱出来的任何新微服务的轮廓。请记住,微服务架构的成功或失败取决于聚合之间的低耦合以及这些聚合之间的高内聚性。
同样重要的是要注意,有界上下文本身就是合适的内聚单元。即使上下文具有多个聚合,整个上下文及其聚合也可以组成一个微服务。我们发现这种启发式方法对于有些晦涩的领域特别有用-考虑组织正在涉足的新业务领域。您可能对分离的正确边界没有足够的了解,并且聚集体的任何过早分解都可能导致昂贵的重构。想象一下,由于数据迁移,不得不将两个数据库合并为一个,因为我们偶然发现两个聚合属于同一类。但是请确保通过接口将这些聚合充分隔离,以使它们不知道彼此的复杂细节。
事件风暴-识别服务边界的另一种技术
事件风暴是识别系统中的聚合(以及微服务)的另一种必不可少的技术。这对于破坏整体结构以及设计复杂的微服务生态系统都是有用的工具。我们已经使用这种技术分解了一个复杂的应用程序,并且打算在单独的博客中介绍Event Storming的经验。对于此博客的范围,我们想给出一个快速的高级概述。如果您有兴趣进一步探索,请观看Alberto Brandelloni的视频。
简而言之,事件风暴是在应用程序团队(在我们的情况下为整体)中进行的头脑风暴,以识别系统中发生的各种领域事件和流程。团队还确定这些事件影响及其后续影响的汇总或模型。在团队进行此练习时,他们会确定不同的重叠概念,模棱两可的领域语言以及相互冲突的业务流程。他们将相关模型分组,重新定义聚合并确定重复的过程。随着这些工作的进行,这些集合所属的有限上下文变得清晰起来。如果所有团队都在同一个房间(物理或虚拟)中,并开始在Scrum风格的白板上绘制事件,命令和过程的映射,那么Event Storming研讨会将非常有用。在本练习结束时,
- 重新定义的聚合列表。这些可能成为新的微服务
- 这些微服务之间需要流动的域事件
- 直接从其他应用程序或用户调用的命令
我们在一场Event Storming研讨会结束时展示了一个示例板。对于团队来说,这是一次很棒的协作活动,以就正确的聚合和有限的上下文达成一致。除了进行出色的团队建设活动外,团队在本次会议中脱颖而出,对领域,通用语言和精确的服务边界有着共同的理解。
微服务之间的通信
一个整体在一个流程边界内托管了多个聚合体。因此,在此边界内可以管理聚合体的事务一致性,例如,如果客户下订单,我们可以减少项目的库存,并向客户发送电子邮件,全部都在一次交易事务中。所有操作都会成功,或者全部都会失败。但是,当我们打破整体并将聚合散布到不同的环境中时,我们将拥有数十甚至数百个微服务。迄今为止,在整体结构的单个边界内存在的流程现在分布在多个分布式系统中。要在所有这些分布式系统上实现事务的完整性和一致性非常困难,而且要付出代价-系统的可用性。
微服务也是分布式系统。因此,CAP定理也适用于它们- “分布式系统只能提供三个所需特征中的两个:一致性,可用性和分区容限(CAP中的“ C”,“ A”和“ P”)。” 在现实世界的系统中,分区容忍度是无法商议的- 网络不可靠,虚拟机可能宕机,区域之间的延迟会变得更糟,等等。
因此,我们可以选择“可用性”或“一致性”。现在,我们知道在任何现代应用程序中,牺牲可用性也不是一个好主意。
围绕最终一致性设计应用程序
如果您尝试跨多个分布式系统构建事务,那么您将再次陷入困境。变成最糟糕的一种分布式整体事务。如果任何一个系统点不可用,则整个流程将不可用,通常会导致令人沮丧的客户体验、失去保障失败的承诺等。
此外,对一项服务的更改通常可能需要对另一项服务进行更改,从而导致复杂而昂贵的部署。因此,我们最好根据自己的用例来设计应用程序,以容忍一点点的不一致性,以提高可用性。对于上面的示例,我们可以使所有进程异步,从而最终保持一致。我们可以异步发送电子邮件,而与其他流程无关。
如果承诺的物品以后在仓库中不可用,该项目可能被延期订购,或者我们可以停止接受超过某个阈值的项目的订单。
有时,您可能会遇到一个场景,该场景可能需要跨越不同流程边界的两个聚合中的强ACID样式事务。这是重新查看这些聚合并将它们合并为一个极好的标志。在我们开始在不同过程边界中分解这些聚合之前,事件风暴和上下文映射将有助于及早识别这些依赖性。将两个微服务合并为一个成本很高,这是我们应该努力避免的事情。
支持事件驱动的架构
微服务可能会在其聚合上发出本质上的变化。这些称为领域事件,并且对这些更改感兴趣的任何服务都可以侦听这些事件并在其域内采取相应的操作。这种方法避免了任何行为上的耦合:一个域不规定其他域应该做什么,以及时间耦合-一个过程的成功完成不依赖于同时可用的所有系统。当然,这将意味着系统最终将保持一致。
在上面的示例中,订单服务发布了一个事件-订单已取消。订阅该事件的其他服务处理其各自的域功能:付款服务退还款项,库存服务调整项目的库存,依此类推。要确保此集成的可靠性和弹性的几点注意事项:
- 生产者应确保至少生产一次事件。如果这样做失败,则应确保存在回退机制以重新触发事件
- 消费者应确保以幂等的方式消费事件。如果再次发生同一事件,那么在用户端不应有任何副作用。事件也可能不按顺序到达。消费者可以使用时间戳记或版本号字段来保证事件的唯一性。
由于某些用例的性质,不一定总是可以使用基于事件的集成。请查看购物车服务和付款服务之间的集成。这是一个同步集成,因此我们需要注意一些事项。这是行为耦合的一个示例-Cart服务可能从Payment服务中调用REST API,并指示其授权订单付款,而时间耦合则需要Payment服务用于Cart服务才能接受订单。这种耦合减少了这些上下文的自治性,并且可能减少了不希望的依赖性。有几种方法可以避免这种耦合,但是使用所有这些选项,我们将失去向客户提供即时反馈的能力。
- 将REST API转换为基于事件的集成。但是,如果支付服务仅公开REST API,则此选项可能不可用
- 购物车服务立即接受订单,并且有一个批处理作业来接管订单并调用支付服务API
- 购物车服务会产生一个本地事件,然后调用付款服务API
在失败和上游依赖项(付款服务)不可用的情况下,将上述内容与重试结合使用可以使设计更具弹性。例如,在发生故障的情况下,可以通过事件或基于批次的重试来备份购物车和付款服务之间的同步集成。这种方法会对客户体验产生额外的影响:客户可能输入了不正确的付款明细,并且当我们离线处理付款时,我们不会将其在线。否则,收回失败的付款可能会增加业务成本。但是,很有可能,购物车服务对于支付服务的不可用性或故障具有弹性,其缺点胜于缺点。例如,如果我们无法离线收款,我们可以通知客户。
避免针对特定消费者数据需求的服务之间的编排
任何面向服务的体系结构中的反模式之一是,这些服务都可以满足消费者的特定访问模式。通常,这发生在消费者团队与服务团队紧密合作时。如果团队正在开发整体应用程序,则他们通常会创建一个跨不同聚合边界的单一API,从而紧密耦合这些聚合。
让我们考虑一个例子。说Web中的“订单详细信息”页面,移动应用程序需要在单个页面上同时显示订单的详细信息和针对该订单处理的退款的详细信息。在整体应用程序中,Order GET API(假设它是REST API)一起查询Orders和Refunds,合并两个聚合,然后将复合响应发送给调用方。由于聚合属于相同的过程边界,因此无需太多开销即可执行此操作。因此,消费者可以在一个调用中获得所有必要的数据。
如果订单和退款是不同上下文的一部分,则数据不再存在于单个微服务或聚合边界内。为消费者保留相同功能的一种选择是使订单服务负责调用退款服务并创建复合响应。此方法引起以下问题:
- 订单服务现在与另一个服务集成在一起,纯粹是为了支持需要退款数据和订单数据的消费者。现在,订单服务的自治性降低了,因为退款总额中的任何更改都将导致订单总额中的更改。
- 订单服务具有另一个集成,因此要考虑另一个故障点-如果退款服务出现故障,订购服务是否仍可以发送部分数据,并且消费者可以正常地故障吗?
- 如果消费者需要更改以从“退款”聚合中获取更多数据,则现在需要两个团队来进行更改
- 如果在整个平台上都遵循这种模式,则可能导致各种域服务之间的依存关系错综复杂,所有这些都是因为这些服务满足了调用者的特定访问模式。
前端的后端BFF
减轻这种风险的一种方法是让消费者团队管理各种域服务之间的编排。毕竟,呼叫者会更好地了解访问模式,并且可以完全控制对这些模式的任何更改。这种方法将域服务与表示层分离开来,使它们专注于核心业务流程。但是,如果Web和移动应用程序开始直接调用不同的服务而不是从整体中调用一个复合API,则可能会导致这些应用程序的性能开销–通过较低带宽网络进行多次调用,处理和合并来自不同API的数据,等等。 。
相反,可以使用另一种称为前端的后端的模式。在这种设计模式下,由消费者(在本例中为Web和移动团队)创建和管理的后端服务负责跨多个域服务的集成,纯粹是为了向客户提供前端体验。Web和移动团队现在可以根据他们的用例设计数据合同。他们甚至可以使用GraphQL而不是REST API来灵活地查询并准确获取所需的信息。
重要的是要注意,此服务是由使用者团队拥有和维护的,而不是由拥有域服务的团队拥有和维护的。前端团队现在可以根据自己的需求进行优化-移动应用程序可以请求更小的有效负载,减少来自移动应用程序的呼叫次数等等。查看下面的业务流程的修订视图。
结论
在此博客中,我们触及了各种概念,策略和设计启发法,以便在我们进入微服务领域时,尤其是在尝试将整体式服务拆分为基于域的微服务时,加以考虑。其中许多主题本身就是广阔的主题,我认为我们没有做出足够的公正性来详细解释它们,但是我们想介绍一些关键主题以及我们采用这些主题的经验。进一步阅读(链接)部分提供了一些参考资料和一些有用的内容,供任何希望采用此方法的人使用。
原文:https://medium.com/walmartglo... \
译文:jdon.com/54558
近期热文推荐:
1.1,000+ 道 Java面试题及答案整理(2022最新版)
4.别再写满屏的爆爆爆炸类了,试试装饰器模式,这才是优雅的方式!!
觉得不错,别忘了随手点赞+转发哦!