AI领域 | 改变游戏规则的十个突破性观点
从我的AI之旅开始,我发现了一些具有无穷潜力的想法和概念,它们在辉煌的历史上留下了自己的印记。
今天,我决定整理一些最有趣的想法和概念的清单(根据我自己的经验),这些想法和概念让我这些年来都坚持不懈。希望他们也能像激励我一样激励你。
因此,让我们从AI爱好者的“初恋”开始。
1.神经网络-“来自仿生学的灵感”
每个使用统计模型(例如回归模型和所有模型)的新机器学习(Machin Learning,ML)开发人员,在首次学习人工神经网络(Artificial Neural Networks,ANN)时都经历了肾上腺素激增的过程;这是处在深度学习的门口。
这里,基本思想是通过编程来模仿生物神经元的工作,实现通用函数逼近。
神经科学和计算机科学这两个领域的融合本身就是一个令人兴奋的想法。 我们将在以后进行详细探讨。
数学上,突触和连接如何浓缩为大规模的矩阵乘法; 神经元的放电与激活函数如何类似,如S函数(sigmoid); 大脑中的高级认知抽象和人工神经网络的黑匣子听起来如何既神秘又酷。 所有的这些给新的ML开发人员带来了希望,这是不可思议的。
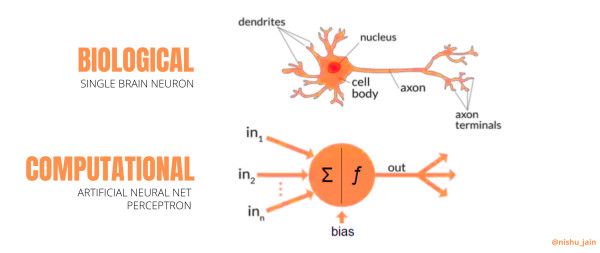
图源:作者提供(Canva制作)
在这一点上,新手认为:“从根本上说,这种受生物启发的技术可以实现一切。 毕竟,大自然选择了执行流程的最佳、最有效的方式,难道不是吗?”
只有在以后的课程中,他们才会学习ANN的部分启发方式,因此仍会有很大的局限性。
从理论上讲,一切听起来都不错,但他们不切实际的雄心勃勃的梦想就消失了,就像在错误配置的神经网络训练课程中的梯度一样(get到这个点了吗?哈哈)。
2.基因算法-“向达尔文问好”
基因算法是另外一类可以应用于计算机科学领域的受自然启发得到的算法。在这里你会找到与达尔文进化论有关所有的术语,有如-突变,繁衍,人口,交叉,适者生存等等。
这些进化算法背后的思想是遵循自然选择,只有最适应环境的个体才有机会繁衍后代。而为了在人口中增加一些多样性,最适应环境的个体所拥有的染色体每过一段时间就会随机地突变一次。
在这里,“个体”指的是给定问题的一个可能的答案
来看一下它的工作流

图源:来自于作者(使用Canva设计出来的)
简洁明了,不是吗?
这个看起来简单的算法在现实世界中可以应用在很多场景,例如-优化,递归神经网络的训练过程,某些问题解决任务的平行化,图像处理之类的。
尽管有这么多的可行方向,基因算法目前还没有任何实际成果。
3.自我编辑程序 -“需要小心的程序员”
作为基因算法应用的延续,这一个当然是最令人兴奋的,而它也值得拥有一个独立的小节。
想象存在一个AI程序可以修改它自身的源代码。它一次又一次地改进着自己,循环多次,直到它最终实现了自己的目标。
很多人相信,
自我改进/编辑代码+AGI=AI超级智慧
显然,要实现这个方法还存在有很多困难,但想一下2013年的这个实验:一个基因算法可以用Brainfuck(一种编程语言)来构造一个可以打印出“hello”的程序。
那个基因算法的源代码中没有写入任何的编程原则,只是一个朴素,古老的自然选择算法。在29分钟之内,它生成了这个-
- +++><>.]]]]
当你在Brainfuck编译器中运行这段代码时,它会打印“hello”。这个实验成功了!
这证实了基因算法的威力,也展现出了在给予足够的时间和计算资源下它的能力。
4.神经常微分方程 -“螺旋层”
回到几年前,在4854份递交到NeurIPS的研究论文中,这篇名为“神经常微分方程”的论文脱颖而出,成为了最好的4篇论文之一。
它有什么了不起的呢?因为它确切地改变了我们对神经网络的看法。
传统意义上的神经网络拥有的层数是离散的,同时依赖于梯度下降和反向传播来进行优化(寻找全局最小值)。当我们增加层数时,我们的内存消耗也在增加,但我们不再需要那么做,理论上说。
我们可以从离散层模型转换成连续层模型-从而拥有无限层。
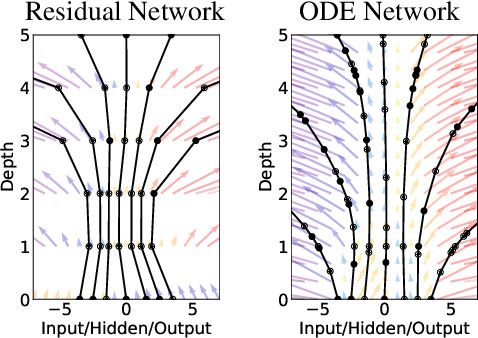
源:上面提到的研究论文
我们不需要事先确定层数。而是输入你想要的精确度然后看着以常数内存为代价的魔术发生。
根据这篇论文,这个方法在时间序列数据中(特别是不规则的时间序列数据)比传统的递归神经网络和残差网络的表现都要更好。
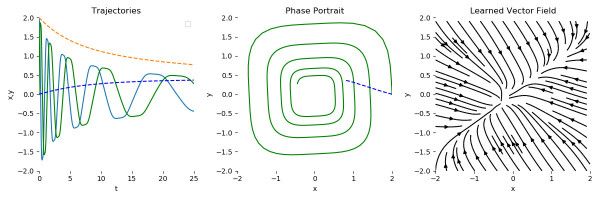
源:上面提到的研究论文
利用这种新的技术,我们可以使用任何常微分方程求解器(OOE Solver),像是欧拉方法来取代梯度上升,使得整个过程更有效率。
而且正如你所知,时间序列数据无所不在-从证券市场的金融数据到医疗保健产业,因此一旦这项技术成熟它的应用将十分广泛。但它目前仍然有待发展。
希望它能往好的方向发展吧!
5.神经进化-“再一次地模仿自然”
神经进化是一个过去的想法,最早可以追溯到二十一世纪初期,由于最近在强化学习的领域中和著名的反向传播算法进行比较而显示出其前景和发展。比如在神经架构搜索,自动机器学习,超参数优化等领域。
用一句话来说,“神经进化是一项利用基因算法改进神经网络的技术”,不仅仅可以改进权重和参数,还能改进网络的(拓扑)结构(最新的研究)。
这是一场梯度下降优化算法和进化优化算法在训练神经网络模型上的战役。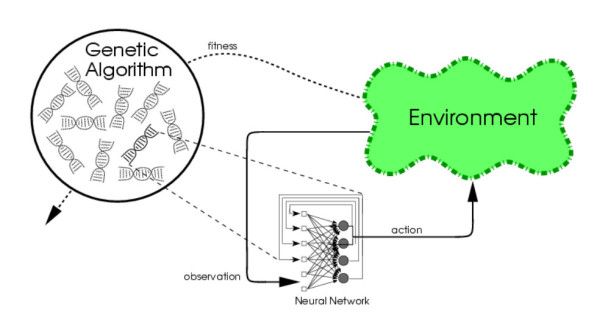
源:https://blog.otoro.net
但我们为什么要使用它呢?
因为,在Uber最近的研究中(深度神经进化),他们发现这项技术比起反向传播可以使模型更快的收敛。在比较低端的PC上几天的计算时间可以缩短为几个小时。
如果你正在用梯度下降训练一个神经网络并卡在了像局部最优点或者梯度弥散的地方,那么神经进化可以帮你得到更好的结果。
你不需为这项替换付出。在每个神经网络被应用到的场所,这项技术都可以被用来优化并训练它们。
“两个脑袋比一个脑袋来的要好,不是因为有某个脑袋不容易出错,而是因为它们不太可能犯同一种错误。"-C.S Lewis
6.谷歌的AI孩子-”AI创造AI“
调整超参数是一项每个数据科学家都深恶痛绝的繁琐而又无聊的任务。由于神经网络实际上是一个黑盒子,我们无法明确地知道我们改变的超参数会如何影响一个网络的学习。
在2018年,谷歌在自动机器学习(AutoML)的世界中作出了一项突破,制作出了一个叫做NASNet的模型。这个物品识别模型拥有82.7%的准确率,比计算机视觉领域内的其他任何模型都要高1.2%,同时效率还要至少高出4%。
最重要的是,它是通过使用强化学习的方法,在另外一个AI的帮助下发展而成的。

图源:谷歌研究院
“神经网络设计神经网络”。。。这确实是一个惊人的想法,你不这么认为吗?
在这里,它的家长AI叫做Controller network(控制者网络),它在数千次的迭代中逐步培养出其AI孩子。在每次迭代中,它计算出孩子的性能并使用这个信息来在下一次迭代中建造一个更好的模型。
这种创造性的思考方式推动了”学会学习“的概念(或者元学习),从而不论是从准确性还是效率都可以击败这个星球上任何人类所设计出来的神经网络。
想象一下在计算机视觉的领域之外它还能做什么。难怪这个概念激起了人们对于超级过载人工智慧最深的恐惧。
7. GANs-”神经网络 vs. 神经网络“
GAN是生成式对抗网络的简写,它们可以学会模仿任意的数据分布。
这是什么意思呢?
在GANs之前,机器学习算法专注于寻找输入和输出之间的关联。它们被叫做判别算法。例如,一个图像分类器可以区分苹果和橙子。
当你把一张照片输入到网络中时,它或返回0(我们让它指代苹果)或者返回1(指橙子)。你可以认为它在分配标签。它在内部创建了一个模型,确定了哪些特征对应了苹果,哪些特征对应了橙子,然后吐出一个带有一定概率的标签。。
然而。。。尽管它们在内部可能有办法用某种方式表示苹果和橙子从而对它们进行比较,但它们没有办法生成出苹果和橙子的图片。
这里就是GANs拿手的地方。一个GAN包含了两个网络-一个生成器和一个鉴别器。
沿用之前的例子,如果我们想要生成一张苹果的照片,那么我会使用一个解卷积网络来作为我的生成器以及一个卷积网络来作为我的鉴别器。
这个生成器一开始只会生成一张随机的噪声图像并试着让它看起来像是一个苹果。另一方面,鉴别器会试着鉴别出输入的图片是真实的还是伪造的(由生成器所生成)。
如果鉴别器可以正确地区分出图片,那么生成器就要努力改进自己去生成出更加真实的图片。同时鉴别器也努力提高自己的判别能力。这意味着,不管如何,改进都是不可避免的,问题只是它发生在鉴别器身上还是生成器身上而已。
这看起来有点像一种双重反馈循环。

GANs的复杂性使得它们难以训练,最近在英伟达发布的一篇研究论文中他们描述了一种方法,通过渐进地改进生成器和鉴别器来训练GANs。(有趣的说法!)。
关于GAN的机制我们说的足够多了,那么我们该如何使用它呢?
一些酷炫的GAN的应用:
-
使面孔变老
-
超高分辨率
-
图像混合
-
衣服转换
-
3D物体生成,之类的。
更多信息可以参见这篇文章。
8.迁移学习-”使用预先训练好的网络“
从零开始训练一个神经网络是需要昂贵的计算成本,有时还会变得非常混乱。但试想一下我们可以从另外一个以前在其他数据集上已经训练好的网络中获取知识,并将其重新用在我们新的目标数据集的训练过程中。
这样子,我们可以加速在新的领域上进行学习的过程并且节省大量的计算能耗和资源。可以把它想成是一场起点比其他人要靠前的跑步比赛。
不要把你的时间浪费在重复造轮子上
显然,你不可以把这项技术用在两个毫不相关的领域上,但在一些领域上-自然语言处理和计算机视觉,使用已经训练好的网络是一种新的规范

Source:https://www.topbots.com/
计算机视觉领域中,在物品侦测,物品识别,和图像分类任务中,人们会使用像VGG ConvNet,AlexNet,ResNet-50,InceptionV3,EfficientNet之类的已经预训练好的网络。特别是在任务刚开始的阶段。
即使是在像神经风格转移(NST)这样的任务上,你可以使用VGG19来迅速获取内在表示从而节省时间。
在如情感识别和语言翻译的NLP任务中,各类的不同词向量嵌入方法如斯坦福的GloVe(表示词汇的全局向量)或者谷歌的Word2Vec都是标配。
我不想提及那些最新的语言模型(那些大家伙)如谷歌的BERT,OpenAI的GPT-2(生成式预训练Transformer),和全能的GPT-3。他们都是在我们这些平民难以想象的海量的信息中训练出来的。他们几乎把整个网络作为他们的输入数据集并花费了数百万美元来进行训练。
从这一点而言,它看起来像是未来我们使用的预训练网络。
9.神经形态架构 -”次世代材料“
在看了那么多软件世界的进展之后,我们来关注一下硬件部分。
但在那之前,先来看一下这个荒谬的对比。。。
人类的脑子里平均有860亿个神经元和大约1千万亿突触。直观地说,你实际上可以通过解开你的脑子来到达月球(用400000千米长的神经纤维)。
如果你想要模拟你的脑子,你需要消耗大量的计算能源(1百亿亿次运算),这是在现有的技术水平上无法实现的。
即使是最强大的超级计算机也无法实现这么大的运算量,更别提我们的大脑仅仅需要20瓦的电力(比点燃一个灯泡还少)就可以做到这种程度。
为什么?因为”架构“
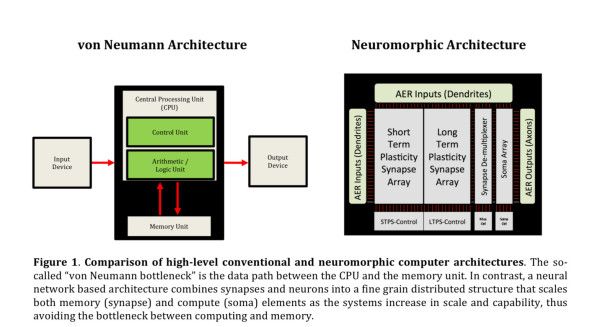
图源:https://randommathgenerator.com/
你知道吗,今天我们用到的每一台计算机都是基于一个有75年历史的架构,即冯诺依曼架构。在这个架构中,内存和处理器是相互分离的,这使得我们在执行大运算量的任务,如大型矩阵乘法,时存在着性能瓶颈。
这个冯诺依曼瓶颈的产生是因为我们执行一系列指令的时候传入输入和得到输出的过程是有顺序的。但在我们的脑子中,进行记忆和处理的单元本质上是同一个,这使得它可以用闪电般的速度处理巨量的数据同时只需要消耗极小量的能量。在这里,连接记忆和处理单元的就是记忆本身。
有一些公司例如IBM和Intel正尝试模拟一个像我们生物的脑子一样的架构。它最终会催生出一种新的计算方式,神经形态计算。
使用多块GPU和TPU的日子就要到头了。我真的迫不及待那一天的到来!
进展:IBM的真北芯片和Intel的神经形态芯片。
10.通用人工智能(AGI)-“我们的终极目标”
当你听到有人嘶喊到“总有一天,AI会把我们都杀光。”那么通用人工智能最有可能做出这样的事情。
为什么?
因为现在我们正在处理的是“弱人工智能”意思是我们现在的模型在它们的特定领域之外一无是处。但是,全球的科学家和研究人员都在致力于产生一种可以完成各类任务,或者能学会完成几乎任何给定任务的人工智能。
如果他们成功了,可以预测到的是,这会导致智慧爆炸,远超人类的智慧并最终催生出超级智能。
当这件事发生的时候,那个超级智能会变成一个拥有知觉,自我意识,以及更高的认知能力的存在。

源:https://www.theverge.com(实在忍不住放上这张照片)
之后会发生什么?只有天知道。
有一个专门的词来形容这种情况。Singularity是一个假设的时间点,到那个时候技术发展会变得不可控且不可逆,最终对人类文明产生不可预见的改变。-维基百科
我们不能简单地停止它的发展吗?不。
人工智能就像是今天的电能一样。我们对它拥有着重度依赖,停止它的发展就像是回到黑暗时代。此外,没有国家会停止它的发展因为有一种共同的心态-”即使我们不发展,他们也会“-就像我们制造具有大规模杀伤力的核武器时的心态。
埃隆马斯克的担心并非空穴来风。他是认真的。
总结
我觉得已经说出了一些制造一个完美AI的方法的要点。但谁在乎呢?除非我们有办法和他们共存。
我希望在Neuralink工作的人们能够在世界末日之前完成他们的人脑-机器接口。且埃隆马斯克设法在不把我们的脑子暴露给新世代黑客的情况下使用它。
为了一个乌托邦式的未来,我们可以暂时停止争论。最后我想说,我非常享受写这一篇文章,我希望你也能乐在其中。