目标检测主要数据格式的转换
我们经常从网上获取一些目标检测的数据集资源标签的格式都是xml的,而yolov5训练所需要的是txt文件的格式,这里就需要对xml格式的标签文件转换为txt文件。同时训练自己的yolov5检测模型的时候,数据集需要划分为训练集和验证集。这里提供了一份代码将xml格式的标注文件转换为txt格式的标注文件,并按比例划分为训练集和验证集。先上代码再讲解代码的注意事项
本文记录了目标检测任务中,常见的三中数据集标签格式之间的相互转换。
话不多说,先上代码:
DeepLearning/others/label_convert at master · KKKSQJ/DeepLearninggithub.com/KKKSQJ/DeepLearning/tree/master/others/label_convert
数据集格式介绍
voc
VOC数据集由五个部分构成:JPEGImages,Annotations,ImageSets,SegmentationClass以及SegmentationObject.
- JPEGImages:存放的是训练与测试的所有图片。
- Annotations:里面存放的是每张图片打完标签所对应的XML文件。
- ImageSets:ImageSets文件夹下本次讨论的只有Main文件夹,此文件夹中存放的主要又有四个文本文件test.txt、train.txt、trainval.txt、val.txt, 其中分别存放的是测试集图片的文件名、训练集图片的文件名、训练验证集图片的文件名、验证集图片的文件名。
- SegmentationClass与SegmentationObject:存放的都是图片,且都是图像分割结果图,对目标检测任务来说没有用。class segmentation 标注出每一个像素的类别
- object segmentation 标注出每一个像素属于哪一个物体。
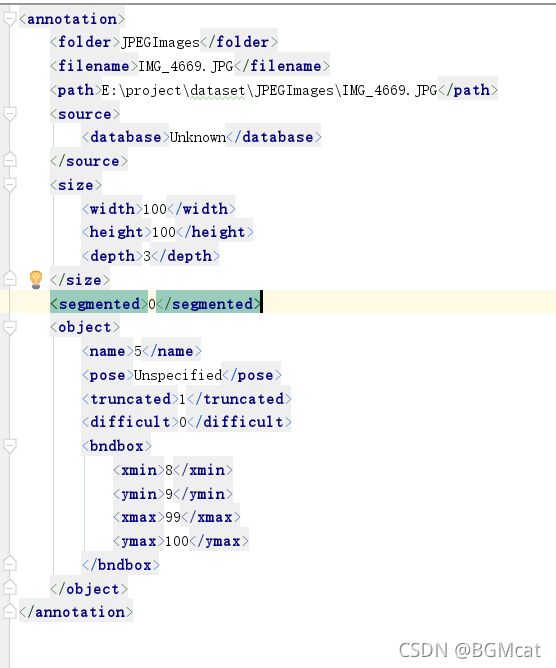
voc数据集的标签主要以xml文件形式进行存放。
xml文件的标注格式如下:
17 # 图片所处文件夹
77258.bmp # 图片名
~/frcnn-image/61/ADAS/image/frcnn-image/17/77258.bmp
#图片来源相关信息
Unknown
#图片尺寸
640
480
3
0 #是否有分割label
coco
COCO数据集现在有3种标注类型,分别是:
- object instances(目标实例)
- object keypoints(目标上的关键点)
- image captions(看图说话)
这3种类型共享这些基本类型:info、image、license,使用JSON文件存储。
json文件的标注格式如下:
以Object Instance为例,这种格式的文件从头至尾按照顺序分为以下段落:
{
"info": info, # dict
"licenses": [license], # list,内部是dict
"images": [image], # list,内部是dict
"annotations": [annotation],# list,内部是dict
"categories": [category] # list,内部是dict
}
info{ # 数据集信息描述
"year": int, # 数据集年份
"version": str, # 数据集版本
"description": str, # 数据集描述
"contributor": str, # 数据集提供者
"url": str, # 数据集下载链接
"date_created": datetime, # 数据集创建日期
}
license{
"id": int,
"name": str,
"url": str,
}
image{ # images是一个list,存放所有图片(dict)信息。image是一个dict,存放单张图片信息
"id": int, # 图片的ID编号(每张图片ID唯一)
"width": int, # 图片宽
"height": int, # 图片高
"file_name": str, # 图片名字
"license": int, # 协议
"flickr_url": str, # flickr链接地址
"coco_url": str, # 网络连接地址
"date_captured": datetime, # 数据集获取日期
}
annotation{ # annotations是一个list,存放所有标注(dict)信息。annotation是一个dict,存放单个目标标注信息。
"id": int, # 目标对象ID(每个对象ID唯一),每张图片可能有多个目标
"image_id": int, # 对应图片ID
"category_id": int, # 对应类别ID,与categories中的ID对应
"segmentation": RLE or [polygon], # 实例分割,对象的边界点坐标[x1,y1,x2,y2,....,xn,yn]
"area": float, # 对象区域面积
"bbox": [xmin,ymin,width,height], # 目标检测,对象定位边框[x,y,w,h]
"iscrowd": 0 or 1, # 表示是否是人群
}
categories{ # 类别描述
"id": int, # 类别对应的ID(0默认为背景)
"name": str, # 子类别名字
"supercategory": str, # 主类别名字
}yolo
yolo数据集标注格式主要是 U版本yolov5项目需要用到。
标签使用txt文本进行保存。
yolo标注格式如下所示:
例如:
0 0.412500 0.318981 0.358333 0.636111:对象的标签索引 - x,y:目标的中心坐标,相对于图片的H和W做归一化。即x/W,y/H。
- width,height:目标(bbox)的宽和高,相对于图像的H和W做归一化。
格式转换
YOLO为txt格式,voc为xml格式,具体结构如下图:


目录结构:
|—py文件(转换的py文件)
|—dataset
||–annotation (存放voc格式的文件夹)
||–YOLOLabels(要存放YOLO格式的文件夹)
||–JPEGImages(照片文件夹)
||–image
|||–train
|||–val
||–label
|||–train
|||–val
YOLOMark2VOC
py文件
YOLOMarkFile
images
labels
VOCFile
Annatations
coco转voc
from pycocotools.coco import COCO
import os
from lxml import etree, objectify
import shutil
from tqdm import tqdm
import sys
import argparse
# 将类别名字和id建立索引
def catid2name(coco):
classes = dict()
for cat in coco.dataset['categories']:
classes[cat['id']] = cat['name']
return classes
# 将标签信息写入xml
def save_anno_to_xml(filename, size, objs, save_path):
E = objectify.ElementMaker(annotate=False)
anno_tree = E.annotation(
E.folder("DATA"),
E.filename(filename),
E.source(
E.database("The VOC Database"),
E.annotation("PASCAL VOC"),
E.image("flickr")
),
E.size(
E.width(size['width']),
E.height(size['height']),
E.depth(size['depth'])
),
E.segmented(0)
)
for obj in objs:
E2 = objectify.ElementMaker(annotate=False)
anno_tree2 = E2.object(
E.name(obj[0]),
E.pose("Unspecified"),
E.truncated(0),
E.difficult(0),
E.bndbox(
E.xmin(obj[1]),
E.ymin(obj[2]),
E.xmax(obj[3]),
E.ymax(obj[4])
)
)
anno_tree.append(anno_tree2)
anno_path = os.path.join(save_path, filename[:-3] + "xml")
etree.ElementTree(anno_tree).write(anno_path, pretty_print=True)
# 利用cocoAPI从json中加载信息
def load_coco(anno_file, xml_save_path):
if os.path.exists(xml_save_path):
shutil.rmtree(xml_save_path)
os.makedirs(xml_save_path)
coco = COCO(anno_file)
classes = catid2name(coco)
imgIds = coco.getImgIds()
classesIds = coco.getCatIds()
for imgId in tqdm(imgIds):
size = {}
img = coco.loadImgs(imgId)[0]
filename = img['file_name']
width = img['width']
height = img['height']
size['width'] = width
size['height'] = height
size['depth'] = 3
annIds = coco.getAnnIds(imgIds=img['id'], iscrowd=None)
anns = coco.loadAnns(annIds)
objs = []
for ann in anns:
object_name = classes[ann['category_id']]
# bbox:[x,y,w,h]
bbox = list(map(int, ann['bbox']))
xmin = bbox[0]
ymin = bbox[1]
xmax = bbox[0] + bbox[2]
ymax = bbox[1] + bbox[3]
obj = [object_name, xmin, ymin, xmax, ymax]
objs.append(obj)
save_anno_to_xml(filename, size, objs, xml_save_path)
def parseJsonFile(data_dir, xmls_save_path):
assert os.path.exists(data_dir), "data dir:{} does not exits".format(data_dir)
if os.path.isdir(data_dir):
data_types = ['train2017', 'val2017']
for data_type in data_types:
ann_file = 'instances_{}.json'.format(data_type)
xmls_save_path = os.path.join(xmls_save_path, data_type)
load_coco(ann_file, xmls_save_path)
elif os.path.isfile(data_dir):
anno_file = data_dir
load_coco(anno_file, xmls_save_path)
if __name__ == '__main__':
"""
脚本说明:
该脚本用于将coco格式的json文件转换为voc格式的xml文件
参数说明:
data_dir:json文件的路径
xml_save_path:xml输出路径
"""
parser = argparse.ArgumentParser()
parser.add_argument('-d', '--data-dir', type=str, default='./data/labels/coco/train.json', help='json path')
parser.add_argument('-s', '--save-path', type=str, default='./data/convert/voc', help='xml save path')
opt = parser.parse_args()
print(opt)
if len(sys.argv) > 1:
parseJsonFile(opt.data_dir, opt.save_path)
else:
data_dir = './data/labels/coco/train.json'
xml_save_path = './data/convert/voc'
parseJsonFile(data_dir=data_dir, xmls_save_path=xml_save_path)
coco转yolo
from pycocotools.coco import COCO
import os
import shutil
from tqdm import tqdm
import sys
import argparse
images_nums = 0
category_nums = 0
bbox_nums = 0
# 将类别名字和id建立索引
def catid2name(coco):
classes = dict()
for cat in coco.dataset['categories']:
classes[cat['id']] = cat['name']
return classes
# 将[xmin,ymin,xmax,ymax]转换为yolo格式[x_center, y_center, w, h](做归一化)
def xyxy2xywhn(object, width, height):
cat_id = object[0]
xn = object[1] / width
yn = object[2] / height
wn = object[3] / width
hn = object[4] / height
out = "{} {:.5f} {:.5f} {:.5f} {:.5f}".format(cat_id, xn, yn, wn, hn)
return out
def save_anno_to_txt(images_info, save_path):
filename = images_info['filename']
txt_name = filename[:-3] + "txt"
with open(os.path.join(save_path, txt_name), "w") as f:
for obj in images_info['objects']:
line = xyxy2xywhn(obj, images_info['width'], images_info['height'])
f.write("{}\n".format(line))
# 利用cocoAPI从json中加载信息
def load_coco(anno_file, xml_save_path):
if os.path.exists(xml_save_path):
shutil.rmtree(xml_save_path)
os.makedirs(xml_save_path)
coco = COCO(anno_file)
classes = catid2name(coco)
imgIds = coco.getImgIds()
classesIds = coco.getCatIds()
with open(os.path.join(xml_save_path, "classes.txt"), 'w') as f:
for id in classesIds:
f.write("{}\n".format(classes[id]))
for imgId in tqdm(imgIds):
info = {}
img = coco.loadImgs(imgId)[0]
filename = img['file_name']
width = img['width']
height = img['height']
info['filename'] = filename
info['width'] = width
info['height'] = height
annIds = coco.getAnnIds(imgIds=img['id'], iscrowd=None)
anns = coco.loadAnns(annIds)
objs = []
for ann in anns:
object_name = classes[ann['category_id']]
# bbox:[x,y,w,h]
bbox = list(map(float, ann['bbox']))
xc = bbox[0] + bbox[2] / 2.
yc = bbox[1] + bbox[3] / 2.
w = bbox[2]
h = bbox[3]
obj = [ann['category_id'], xc, yc, w, h]
objs.append(obj)
info['objects'] = objs
save_anno_to_txt(info, xml_save_path)
def parseJsonFile(json_path, txt_save_path):
assert os.path.exists(json_path), "json path:{} does not exists".format(json_path)
if os.path.exists(txt_save_path):
shutil.rmtree(txt_save_path)
os.makedirs(txt_save_path)
assert json_path.endswith('json'), "json file:{} It is not json file!".format(json_path)
load_coco(json_path, txt_save_path)
if __name__ == '__main__':
"""
脚本说明:
该脚本用于将coco格式的json文件转换为yolo格式的txt文件
参数说明:
json_path:json文件的路径
txt_save_path:txt保存的路径
"""
parser = argparse.ArgumentParser()
parser.add_argument('-jp', '--json-path', type=str, default='./data/labels/coco/train.json', help='json path')
parser.add_argument('-s', '--save-path', type=str, default='./data/convert/yolo', help='txt save path')
opt = parser.parse_args()
if len(sys.argv) > 1:
print(opt)
parseJsonFile(opt.json_path, opt.save_path)
# print("image nums: {}".format(images_nums))
# print("category nums: {}".format(category_nums))
# print("bbox nums: {}".format(bbox_nums))
else:
json_path = './data/labels/coco/train.json' # r'D:\practice\compete\goodsDec\data\train\train.json'
txt_save_path = './data/convert/yolo'
parseJsonFile(json_path, txt_save_path)
# print("image nums: {}".format(images_nums))
# print("category nums: {}".format(category_nums))
# print("bbox nums: {}".format(bbox_nums))
voc转coco
import xml.etree.ElementTree as ET
import os
import json
from datetime import datetime
import sys
import argparse
coco = dict()
coco['images'] = []
coco['type'] = 'instances'
coco['annotations'] = []
coco['categories'] = []
category_set = dict()
image_set = set()
category_item_id = -1
image_id = 000000
annotation_id = 0
def addCatItem(name):
global category_item_id
category_item = dict()
category_item['supercategory'] = 'none'
category_item_id += 1
category_item['id'] = category_item_id
category_item['name'] = name
coco['categories'].append(category_item)
category_set[name] = category_item_id
return category_item_id
def addImgItem(file_name, size):
global image_id
if file_name is None:
raise Exception('Could not find filename tag in xml file.')
if size['width'] is None:
raise Exception('Could not find width tag in xml file.')
if size['height'] is None:
raise Exception('Could not find height tag in xml file.')
image_id += 1
image_item = dict()
image_item['id'] = image_id
image_item['file_name'] = file_name
image_item['width'] = size['width']
image_item['height'] = size['height']
image_item['license'] = None
image_item['flickr_url'] = None
image_item['coco_url'] = None
image_item['date_captured'] = str(datetime.today())
coco['images'].append(image_item)
image_set.add(file_name)
return image_id
def addAnnoItem(object_name, image_id, category_id, bbox):
global annotation_id
annotation_item = dict()
annotation_item['segmentation'] = []
seg = []
# bbox[] is x,y,w,h
# left_top
seg.append(bbox[0])
seg.append(bbox[1])
# left_bottom
seg.append(bbox[0])
seg.append(bbox[1] + bbox[3])
# right_bottom
seg.append(bbox[0] + bbox[2])
seg.append(bbox[1] + bbox[3])
# right_top
seg.append(bbox[0] + bbox[2])
seg.append(bbox[1])
annotation_item['segmentation'].append(seg)
annotation_item['area'] = bbox[2] * bbox[3]
annotation_item['iscrowd'] = 0
annotation_item['ignore'] = 0
annotation_item['image_id'] = image_id
annotation_item['bbox'] = bbox
annotation_item['category_id'] = category_id
annotation_id += 1
annotation_item['id'] = annotation_id
coco['annotations'].append(annotation_item)
def read_image_ids(image_sets_file):
ids = []
with open(image_sets_file, 'r') as f:
for line in f.readlines():
ids.append(line.strip())
return ids
def parseXmlFilse(data_dir, json_save_path, split='train'):
assert os.path.exists(data_dir), "data path:{} does not exist".format(data_dir)
labelfile = split + ".txt"
image_sets_file = os.path.join(data_dir, "ImageSets", "Main", labelfile)
xml_files_list = []
if os.path.isfile(image_sets_file):
ids = read_image_ids(image_sets_file)
xml_files_list = [os.path.join(data_dir, "Annotations", f"{i}.xml") for i in ids]
elif os.path.isdir(data_dir):
# 修改此处xml的路径即可
# xml_dir = os.path.join(data_dir,"labels/voc")
xml_dir = data_dir
xml_list = os.listdir(xml_dir)
xml_files_list = [os.path.join(xml_dir, i) for i in xml_list]
for xml_file in xml_files_list:
if not xml_file.endswith('.xml'):
continue
tree = ET.parse(xml_file)
root = tree.getroot()
# 初始化
size = dict()
size['width'] = None
size['height'] = None
if root.tag != 'annotation':
raise Exception('pascal voc xml root element should be annotation, rather than {}'.format(root.tag))
# 提取图片名字
file_name = root.findtext('filename')
assert file_name is not None, "filename is not in the file"
# 提取图片 size {width,height,depth}
size_info = root.findall('size')
assert size_info is not None, "size is not in the file"
for subelem in size_info[0]:
size[subelem.tag] = int(subelem.text)
if file_name is not None and size['width'] is not None and file_name not in image_set:
# 添加coco['image'],返回当前图片ID
current_image_id = addImgItem(file_name, size)
print('add image with name: {}\tand\tsize: {}'.format(file_name, size))
elif file_name in image_set:
raise Exception('file_name duplicated')
else:
raise Exception("file name:{}\t size:{}".format(file_name, size))
# 提取一张图片内所有目标object标注信息
object_info = root.findall('object')
if len(object_info) == 0:
continue
# 遍历每个目标的标注信息
for object in object_info:
# 提取目标名字
object_name = object.findtext('name')
if object_name not in category_set:
# 创建类别索引
current_category_id = addCatItem(object_name)
else:
current_category_id = category_set[object_name]
# 初始化标签列表
bndbox = dict()
bndbox['xmin'] = None
bndbox['xmax'] = None
bndbox['ymin'] = None
bndbox['ymax'] = None
# 提取box:[xmin,ymin,xmax,ymax]
bndbox_info = object.findall('bndbox')
for box in bndbox_info[0]:
bndbox[box.tag] = int(box.text)
if bndbox['xmin'] is not None:
if object_name is None:
raise Exception('xml structure broken at bndbox tag')
if current_image_id is None:
raise Exception('xml structure broken at bndbox tag')
if current_category_id is None:
raise Exception('xml structure broken at bndbox tag')
bbox = []
# x
bbox.append(bndbox['xmin'])
# y
bbox.append(bndbox['ymin'])
# w
bbox.append(bndbox['xmax'] - bndbox['xmin'])
# h
bbox.append(bndbox['ymax'] - bndbox['ymin'])
print('add annotation with object_name:{}\timage_id:{}\tcat_id:{}\tbbox:{}'.format(object_name,
current_image_id,
current_category_id,
bbox))
addAnnoItem(object_name, current_image_id, current_category_id, bbox)
json_parent_dir = os.path.dirname(json_save_path)
if not os.path.exists(json_parent_dir):
os.makedirs(json_parent_dir)
json.dump(coco, open(json_save_path, 'w'))
print("class nums:{}".format(len(coco['categories'])))
print("image nums:{}".format(len(coco['images'])))
print("bbox nums:{}".format(len(coco['annotations'])))
if __name__ == '__main__':
"""
脚本说明:
本脚本用于将VOC格式的标注文件.xml转换为coco格式的标注文件.json
参数说明:
voc_data_dir:两种格式
1.voc2012文件夹的路径,会自动找到voc2012/imageSets/Main/xx.txt
2.xml标签文件存放的文件夹
json_save_path:json文件输出的文件夹
split:主要用于voc2012查找xx.txt,如train.txt.如果用格式2,则不会用到该参数
"""
parser = argparse.ArgumentParser()
parser.add_argument('-d', '--voc-dir', type=str, default='data/label/voc', help='voc path')
parser.add_argument('-s', '--save-path', type=str, default='./data/convert/coco/train.json', help='json save path')
parser.add_argument('-t', '--type', type=str, default='train', help='only use in voc2012/2007')
opt = parser.parse_args()
if len(sys.argv) > 1:
print(opt)
parseXmlFilse(opt.voc_dir, opt.save_path, opt.type)
else:
# voc_data_dir = r'D:\dataset\VOC2012\VOCdevkit\VOC2012'
voc_data_dir = './data/labels/voc'
json_save_path = './data/convert/coco/train.json'
split = 'train'
parseXmlFilse(data_dir=voc_data_dir, json_save_path=json_save_path, split=split)
voc转yolo
import os
import json
import argparse
import sys
import shutil
from lxml import etree
from tqdm import tqdm
category_set = set()
image_set = set()
bbox_nums = 0
def parse_xml_to_dict(xml):
"""
将xml文件解析成字典形式,参考tensorflow的recursive_parse_xml_to_dict
Args:
xml: xml tree obtained by parsing XML file contents using lxml.etree
Returns:
Python dictionary holding XML contents.
"""
if len(xml) == 0: # 遍历到底层,直接返回tag对应的信息
return {xml.tag: xml.text}
result = {}
for child in xml:
child_result = parse_xml_to_dict(child) # 递归遍历标签信息
if child.tag != 'object':
result[child.tag] = child_result[child.tag]
else:
if child.tag not in result: # 因为object可能有多个,所以需要放入列表里
result[child.tag] = []
result[child.tag].append(child_result[child.tag])
return {xml.tag: result}
def write_classIndices(category_set):
class_indices = dict((k, v) for v, k in enumerate(category_set))
json_str = json.dumps(dict((val, key) for key, val in class_indices.items()), indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
def xyxy2xywhn(bbox, size):
bbox = list(map(float, bbox))
size = list(map(float, size))
xc = (bbox[0] + (bbox[2] - bbox[0]) / 2.) / size[0]
yc = (bbox[1] + (bbox[3] - bbox[1]) / 2.) / size[1]
wn = (bbox[2] - bbox[0]) / size[0]
hn = (bbox[3] - bbox[1]) / size[1]
return (xc, yc, wn, hn)
def parser_info(info: dict, only_cat=True, class_indices=None):
filename = info['annotation']['filename']
image_set.add(filename)
objects = []
width = int(info['annotation']['size']['width'])
height = int(info['annotation']['size']['height'])
for obj in info['annotation']['object']:
obj_name = obj['name']
category_set.add(obj_name)
if only_cat:
continue
xmin = int(obj['bndbox']['xmin'])
ymin = int(obj['bndbox']['ymin'])
xmax = int(obj['bndbox']['xmax'])
ymax = int(obj['bndbox']['ymax'])
bbox = xyxy2xywhn((xmin, ymin, xmax, ymax), (width, height))
if class_indices is not None:
obj_category = class_indices[obj_name]
object = [obj_category, bbox]
objects.append(object)
return filename, objects
def parseXmlFilse(voc_dir, save_dir):
assert os.path.exists(voc_dir), "ERROR {} does not exists".format(voc_dir)
if os.path.exists(save_dir):
shutil.rmtree(save_dir)
os.makedirs(save_dir)
xml_files = [os.path.join(voc_dir, i) for i in os.listdir(voc_dir) if os.path.splitext(i)[-1] == '.xml']
for xml_file in xml_files:
with open(xml_file) as fid:
xml_str = fid.read()
xml = etree.fromstring(xml_str)
info_dict = parse_xml_to_dict(xml)
parser_info(info_dict, only_cat=True)
with open(save_dir + "/classes.txt", 'w') as classes_file:
for cat in sorted(category_set):
classes_file.write("{}\n".format(cat))
class_indices = dict((v, k) for k, v in enumerate(sorted(category_set)))
xml_files = tqdm(xml_files)
for xml_file in xml_files:
with open(xml_file) as fid:
xml_str = fid.read()
xml = etree.fromstring(xml_str)
info_dict = parse_xml_to_dict(xml)
filename, objects = parser_info(info_dict, only_cat=False, class_indices=class_indices)
if len(objects) != 0:
global bbox_nums
bbox_nums += len(objects)
with open(save_dir + "/" + filename.split(".")[0] + ".txt", 'w') as f:
for obj in objects:
f.write(
"{} {:.5f} {:.5f} {:.5f} {:.5f}\n".format(obj[0], obj[1][0], obj[1][1], obj[1][2], obj[1][3]))
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--voc-dir', type=str, default='./data/labels/voc')
parser.add_argument('--save-dir', type=str, default='./data/convert/yolo')
opt = parser.parse_args()
if len(sys.argv) > 1:
print(opt)
parseXmlFilse(**vars(opt))
print("image nums: {}".format(len(image_set)))
print("category nums: {}".format(len(category_set)))
print("bbox nums: {}".format(bbox_nums))
else:
voc_dir = './data/labels/voc'
save_dir = './data/convert/yolo'
parseXmlFilse(voc_dir, save_dir)
print("image nums: {}".format(len(image_set)))
print("category nums: {}".format(len(category_set)))
print("bbox nums: {}".format(bbox_nums))
yolo转coco
import argparse
import json
import os
import sys
import shutil
from datetime import datetime
import cv2
coco = dict()
coco['images'] = []
coco['type'] = 'instances'
coco['annotations'] = []
coco['categories'] = []
category_set = dict()
image_set = set()
image_id = 000000
annotation_id = 0
def addCatItem(category_dict):
for k, v in category_dict.items():
category_item = dict()
category_item['supercategory'] = 'none'
category_item['id'] = int(k)
category_item['name'] = v
coco['categories'].append(category_item)
def addImgItem(file_name, size):
global image_id
image_id += 1
image_item = dict()
image_item['id'] = image_id
image_item['file_name'] = file_name
image_item['width'] = size[1]
image_item['height'] = size[0]
image_item['license'] = None
image_item['flickr_url'] = None
image_item['coco_url'] = None
image_item['date_captured'] = str(datetime.today())
coco['images'].append(image_item)
image_set.add(file_name)
return image_id
def addAnnoItem(object_name, image_id, category_id, bbox):
global annotation_id
annotation_item = dict()
annotation_item['segmentation'] = []
seg = []
# bbox[] is x,y,w,h
# left_top
seg.append(bbox[0])
seg.append(bbox[1])
# left_bottom
seg.append(bbox[0])
seg.append(bbox[1] + bbox[3])
# right_bottom
seg.append(bbox[0] + bbox[2])
seg.append(bbox[1] + bbox[3])
# right_top
seg.append(bbox[0] + bbox[2])
seg.append(bbox[1])
annotation_item['segmentation'].append(seg)
annotation_item['area'] = bbox[2] * bbox[3]
annotation_item['iscrowd'] = 0
annotation_item['ignore'] = 0
annotation_item['image_id'] = image_id
annotation_item['bbox'] = bbox
annotation_item['category_id'] = category_id
annotation_id += 1
annotation_item['id'] = annotation_id
coco['annotations'].append(annotation_item)
def xywhn2xywh(bbox, size):
bbox = list(map(float, bbox))
size = list(map(float, size))
xmin = (bbox[0] - bbox[2] / 2.) * size[1]
ymin = (bbox[1] - bbox[3] / 2.) * size[0]
w = bbox[2] * size[1]
h = bbox[3] * size[0]
box = (xmin, ymin, w, h)
return list(map(int, box))
def parseXmlFilse(image_path, anno_path, save_path, json_name='train.json'):
assert os.path.exists(image_path), "ERROR {} dose not exists".format(image_path)
assert os.path.exists(anno_path), "ERROR {} dose not exists".format(anno_path)
if os.path.exists(save_path):
shutil.rmtree(save_path)
os.makedirs(save_path)
json_path = os.path.join(save_path, json_name)
category_set = []
with open(anno_path + '/classes.txt', 'r') as f:
for i in f.readlines():
category_set.append(i.strip())
category_id = dict((k, v) for k, v in enumerate(category_set))
addCatItem(category_id)
images = [os.path.join(image_path, i) for i in os.listdir(image_path)]
files = [os.path.join(anno_path, i) for i in os.listdir(anno_path)]
images_index = dict((v.split(os.sep)[-1][:-4], k) for k, v in enumerate(images))
for file in files:
if os.path.splitext(file)[-1] != '.txt' or 'classes' in file.split(os.sep)[-1]:
continue
if file.split(os.sep)[-1][:-4] in images_index:
index = images_index[file.split(os.sep)[-1][:-4]]
img = cv2.imread(images[index])
shape = img.shape
filename = images[index].split(os.sep)[-1]
current_image_id = addImgItem(filename, shape)
else:
continue
with open(file, 'r') as fid:
for i in fid.readlines():
i = i.strip().split()
category = int(i[0])
category_name = category_id[category]
bbox = xywhn2xywh((i[1], i[2], i[3], i[4]), shape)
addAnnoItem(category_name, current_image_id, category, bbox)
json.dump(coco, open(json_path, 'w'))
print("class nums:{}".format(len(coco['categories'])))
print("image nums:{}".format(len(coco['images'])))
print("bbox nums:{}".format(len(coco['annotations'])))
if __name__ == '__main__':
"""
脚本说明:
本脚本用于将yolo格式的标注文件.txt转换为coco格式的标注文件.json
参数说明:
anno_path:标注文件txt存储路径
save_path:json文件输出的文件夹
image_path:图片路径
json_name:json文件名字
"""
parser = argparse.ArgumentParser()
parser.add_argument('-ap', '--anno-path', type=str, default='./data/labels/yolo', help='yolo txt path')
parser.add_argument('-s', '--save-path', type=str, default='./data/convert/coco', help='json save path')
parser.add_argument('--image-path', default='./data/images')
parser.add_argument('--json-name', default='train.json')
opt = parser.parse_args()
if len(sys.argv) > 1:
print(opt)
parseXmlFilse(**vars(opt))
else:
anno_path = './data/labels/yolo'
save_path = './data/convert/coco'
image_path = './data/images'
json_name = 'train.json'
parseXmlFilse(image_path, anno_path, save_path, json_name)
yolo转voc
import argparse
import os
import sys
import shutil
import cv2
from lxml import etree, objectify
# 将标签信息写入xml
from tqdm import tqdm
images_nums = 0
category_nums = 0
bbox_nums = 0
def save_anno_to_xml(filename, size, objs, save_path):
E = objectify.ElementMaker(annotate=False)
anno_tree = E.annotation(
E.folder("DATA"),
E.filename(filename),
E.source(
E.database("The VOC Database"),
E.annotation("PASCAL VOC"),
E.image("flickr")
),
E.size(
E.width(size[1]),
E.height(size[0]),
E.depth(size[2])
),
E.segmented(0)
)
for obj in objs:
E2 = objectify.ElementMaker(annotate=False)
anno_tree2 = E2.object(
E.name(obj[0]),
E.pose("Unspecified"),
E.truncated(0),
E.difficult(0),
E.bndbox(
E.xmin(obj[1][0]),
E.ymin(obj[1][1]),
E.xmax(obj[1][2]),
E.ymax(obj[1][3])
)
)
anno_tree.append(anno_tree2)
anno_path = os.path.join(save_path, filename[:-3] + "xml")
etree.ElementTree(anno_tree).write(anno_path, pretty_print=True)
def xywhn2xyxy(bbox, size):
bbox = list(map(float, bbox))
size = list(map(float, size))
xmin = (bbox[0] - bbox[2] / 2.) * size[1]
ymin = (bbox[1] - bbox[3] / 2.) * size[0]
xmax = (bbox[0] + bbox[2] / 2.) * size[1]
ymax = (bbox[1] + bbox[3] / 2.) * size[0]
box = [xmin, ymin, xmax, ymax]
return list(map(int, box))
def parseXmlFilse(image_path, anno_path, save_path):
global images_nums, category_nums, bbox_nums
assert os.path.exists(image_path), "ERROR {} dose not exists".format(image_path)
assert os.path.exists(anno_path), "ERROR {} dose not exists".format(anno_path)
if os.path.exists(save_path):
shutil.rmtree(save_path)
os.makedirs(save_path)
category_set = []
with open(anno_path + '/classes.txt', 'r') as f:
for i in f.readlines():
category_set.append(i.strip())
category_nums = len(category_set)
category_id = dict((k, v) for k, v in enumerate(category_set))
images = [os.path.join(image_path, i) for i in os.listdir(image_path)]
files = [os.path.join(anno_path, i) for i in os.listdir(anno_path)]
images_index = dict((v.split(os.sep)[-1][:-4], k) for k, v in enumerate(images))
images_nums = len(images)
for file in tqdm(files):
if os.path.splitext(file)[-1] != '.txt' or 'classes' in file.split(os.sep)[-1]:
continue
if file.split(os.sep)[-1][:-4] in images_index:
index = images_index[file.split(os.sep)[-1][:-4]]
img = cv2.imread(images[index])
shape = img.shape
filename = images[index].split(os.sep)[-1]
else:
continue
objects = []
with open(file, 'r') as fid:
for i in fid.readlines():
i = i.strip().split()
category = int(i[0])
category_name = category_id[category]
bbox = xywhn2xyxy((i[1], i[2], i[3], i[4]), shape)
obj = [category_name, bbox]
objects.append(obj)
bbox_nums += len(objects)
save_anno_to_xml(filename, shape, objects, save_path)
if __name__ == '__main__':
"""
脚本说明:
本脚本用于将yolo格式的标注文件.txt转换为voc格式的标注文件.xml
参数说明:
anno_path:标注文件txt存储路径
save_path:json文件输出的文件夹
image_path:图片路径
"""
parser = argparse.ArgumentParser()
parser.add_argument('-ap', '--anno-path', type=str, default='./data/labels/yolo', help='yolo txt path')
parser.add_argument('-s', '--save-path', type=str, default='./data/convert/voc', help='xml save path')
parser.add_argument('--image-path', default='./data/images')
opt = parser.parse_args()
if len(sys.argv) > 1:
print(opt)
parseXmlFilse(**vars(opt))
print("image nums: {}".format(images_nums))
print("category nums: {}".format(category_nums))
print("bbox nums: {}".format(bbox_nums))
else:
anno_path = './data/labels/yolo'
save_path = './data/convert/voc1'
image_path = './data/images'
parseXmlFilse(image_path, anno_path, save_path)
print("image nums: {}".format(images_nums))
print("category nums: {}".format(category_nums))
print("bbox nums: {}".format(bbox_nums))
图片可视化
coco格式,图片可视化
import argparse
import os
import sys
from collections import defaultdict
from xml import etree
from pycocotools.coco import COCO
import cv2
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
from tqdm import tqdm
category_set = dict()
image_set = set()
every_class_num = defaultdict(int)
category_item_id = -1
def addCatItem(name):
global category_item_id
category_item = dict()
category_item_id += 1
category_item['id'] = category_item_id
category_item['name'] = name
category_set[name] = category_item_id
return category_item_id
def draw_box(img, objects, draw=True):
for object in objects:
category_name = object[0]
every_class_num[category_name] += 1
if category_name not in category_set:
category_id = addCatItem(category_name)
else:
category_id = category_set[category_name]
xmin = int(object[1])
ymin = int(object[2])
xmax = int(object[3])
ymax = int(object[4])
if draw:
def hex2rgb(h): # rgb order (PIL)
return tuple(int(h[1 + i:1 + i + 2], 16) for i in (0, 2, 4))
hex = ('FF3838', 'FF9D97', 'FF701F', 'FFB21D', 'CFD231', '48F90A', '92CC17', '3DDB86', '1A9334', '00D4BB',
'2C99A8', '00C2FF', '344593', '6473FF', '0018EC', '8438FF', '520085', 'CB38FF', 'FF95C8', 'FF37C7')
palette = [hex2rgb('#' + c) for c in hex]
n = len(palette)
c = palette[int(category_id) % n]
bgr = False
color = (c[2], c[1], c[0]) if bgr else c
cv2.rectangle(img, (xmin, ymin), (xmax, ymax), color)
cv2.putText(img, category_name, (xmin, ymin), cv2.FONT_HERSHEY_SIMPLEX, 1, color)
return img
# 将类别名字和id建立索引
def catid2name(coco):
classes = dict()
for cat in coco.dataset['categories']:
classes[cat['id']] = cat['name']
return classes
def show_image(image_path, anno_path, show=False, plot_image=False):
assert os.path.exists(image_path), "image path:{} dose not exists".format(image_path)
assert os.path.exists(anno_path), "annotation path:{} does not exists".format(anno_path)
if not anno_path.endswith(".json"):
raise RuntimeError("ERROR {} dose not a json file".format(anno_path))
coco = COCO(anno_path)
classes = catid2name(coco)
imgIds = coco.getImgIds()
classesIds = coco.getCatIds()
for imgId in tqdm(imgIds):
size = {}
img = coco.loadImgs(imgId)[0]
filename = img['file_name']
image_set.add(filename)
width = img['width']
height = img['height']
size['width'] = width
size['height'] = height
size['depth'] = 3
annIds = coco.getAnnIds(imgIds=img['id'], iscrowd=None)
anns = coco.loadAnns(annIds)
objs = []
for ann in anns:
object_name = classes[ann['category_id']]
# bbox:[x,y,w,h]
bbox = list(map(int, ann['bbox']))
xmin = bbox[0]
ymin = bbox[1]
xmax = bbox[0] + bbox[2]
ymax = bbox[1] + bbox[3]
obj = [object_name, xmin, ymin, xmax, ymax]
objs.append(obj)
file_path = os.path.join(image_path, filename)
img = cv2.imread(file_path)
if img is None:
continue
img = draw_box(img, objs, show)
if show:
cv2.imshow(filename, img)
cv2.waitKey()
cv2.destroyAllWindows()
if plot_image:
# 绘制每种类别个数柱状图
plt.bar(range(len(every_class_num)), every_class_num.values(), align='center')
# 将横坐标0,1,2,3,4替换为相应的类别名称
plt.xticks(range(len(every_class_num)), every_class_num.keys(), rotation=90)
# 在柱状图上添加数值标签
for index, (i, v) in enumerate(every_class_num.items()):
plt.text(x=index, y=v, s=str(v), ha='center')
# 设置x坐标
plt.xlabel('image class')
# 设置y坐标
plt.ylabel('number of images')
# 设置柱状图的标题
plt.title('class distribution')
plt.savefig("class_distribution.png")
plt.show()
if __name__ == '__main__':
"""
脚本说明:
该脚本用于coco标注格式(.json)的标注框可视化
参数明说:
image_path:图片数据路径
anno_path:json标注文件路径
show:是否展示标注后的图片
plot_image:是否对每一类进行统计,并且保存图片
"""
parser = argparse.ArgumentParser()
parser.add_argument('-ip', '--image-path', type=str, default='./data/images', help='image path')
parser.add_argument('-ap', '--anno-path', type=str, default='./data/labels/coco/train.json', help='annotation path')
parser.add_argument('-s', '--show', action='store_true', help='weather show img')
parser.add_argument('-p', '--plot-image', action='store_true')
opt = parser.parse_args()
if len(sys.argv) > 1:
print(opt)
show_image(opt.image_path, opt.anno_path, opt.show, opt.plot_image)
print(every_class_num)
print("category nums: {}".format(len(category_set)))
print("image nums: {}".format(len(image_set)))
print("bbox nums: {}".format(sum(every_class_num.values())))
else:
image_path = './data/images'
anno_path = './data/labels/coco/train.json'
show_image(image_path, anno_path, show=True, plot_image=True)
print(every_class_num)
print("category nums: {}".format(len(category_set)))
print("image nums: {}".format(len(image_set)))
print("bbox nums: {}".format(sum(every_class_num.values())))
voc格式,图片可视化
import os
import cv2
import matplotlib.pyplot as plt
from tqdm import tqdm
from lxml import etree
from collections import defaultdict
import argparse
import sys
category_set = dict()
image_set = set()
every_class_num = defaultdict(int)
category_item_id = -1
def draw_box(img, objects, draw=True):
for object in objects:
category_name = object['name']
every_class_num[category_name] += 1
if category_name not in category_set:
category_id = addCatItem(category_name)
else:
category_id = category_set[category_name]
xmin = int(object['bndbox']['xmin'])
ymin = int(object['bndbox']['ymin'])
xmax = int(object['bndbox']['xmax'])
ymax = int(object['bndbox']['ymax'])
if draw:
def hex2rgb(h): # rgb order (PIL)
return tuple(int(h[1 + i:1 + i + 2], 16) for i in (0, 2, 4))
hex = ('FF3838', 'FF9D97', 'FF701F', 'FFB21D', 'CFD231', '48F90A', '92CC17', '3DDB86', '1A9334', '00D4BB',
'2C99A8', '00C2FF', '344593', '6473FF', '0018EC', '8438FF', '520085', 'CB38FF', 'FF95C8', 'FF37C7')
palette = [hex2rgb('#' + c) for c in hex]
n = len(palette)
c = palette[int(category_id) % n]
bgr = False
color = (c[2], c[1], c[0]) if bgr else c
cv2.rectangle(img, (xmin, ymin), (xmax, ymax), color)
cv2.putText(img, category_name, (xmin, ymin), cv2.FONT_HERSHEY_SIMPLEX, 1, color)
return img
def addCatItem(name):
global category_item_id
category_item = dict()
category_item_id += 1
category_item['id'] = category_item_id
category_item['name'] = name
category_set[name] = category_item_id
return category_item_id
def parse_xml_to_dict(xml):
"""
将xml文件解析成字典形式,参考tensorflow的recursive_parse_xml_to_dict
Args:
xml: xml tree obtained by parsing XML file contents using lxml.etree
Returns:
Python dictionary holding XML contents.
"""
if len(xml) == 0: # 遍历到底层,直接返回tag对应的信息
return {xml.tag: xml.text}
result = {}
for child in xml:
child_result = parse_xml_to_dict(child) # 递归遍历标签信息
if child.tag != 'object':
result[child.tag] = child_result[child.tag]
else:
if child.tag not in result: # 因为object可能有多个,所以需要放入列表里
result[child.tag] = []
result[child.tag].append(child_result[child.tag])
return {xml.tag: result}
def show_image(image_path, anno_path, show=False, plot_image=False):
assert os.path.exists(image_path), "image path:{} dose not exists".format(image_path)
assert os.path.exists(anno_path), "annotation path:{} does not exists".format(anno_path)
anno_file_list = [os.path.join(anno_path, file) for file in os.listdir(anno_path) if file.endswith(".xml")]
for xml_file in tqdm(anno_file_list):
if not xml_file.endswith('.xml'):
continue
with open(xml_file) as fid:
xml_str = fid.read()
xml = etree.fromstring(xml_str)
xml_info_dict = parse_xml_to_dict(xml)
filename = xml_info_dict['annotation']['filename']
image_set.add(filename)
file_path = os.path.join(image_path, filename)
if not os.path.exists(file_path):
continue
img = cv2.imread(file_path)
if img is None:
continue
img = draw_box(img, xml_info_dict['annotation']['object'], show)
if show:
cv2.imshow(filename, img)
cv2.waitKey()
cv2.destroyAllWindows()
if plot_image:
# 绘制每种类别个数柱状图
plt.bar(range(len(every_class_num)), every_class_num.values(), align='center')
# 将横坐标0,1,2,3,4替换为相应的类别名称
plt.xticks(range(len(every_class_num)), every_class_num.keys(), rotation=90)
# 在柱状图上添加数值标签
for index, (i, v) in enumerate(every_class_num.items()):
plt.text(x=index, y=v, s=str(v), ha='center')
# 设置x坐标
plt.xlabel('image class')
# 设置y坐标
plt.ylabel('number of images')
# 设置柱状图的标题
plt.title('class distribution')
plt.savefig("class_distribution.png")
plt.show()
if __name__ == '__main__':
"""
脚本说明:
该脚本用于voc标注格式(.xml)的标注框可视化
参数明说:
image_path:图片数据路径
anno_path:xml标注文件路径
show:是否展示标注后的图片
plot_image:是否对每一类进行统计,并且保存图片
"""
parser = argparse.ArgumentParser()
parser.add_argument('-ip', '--image-path', type=str, default='./data/images', help='image path')
parser.add_argument('-ap', '--anno-path', type=str, default='./data/labels/voc', help='annotation path')
parser.add_argument('-s', '--show', action='store_true', help='weather show img')
parser.add_argument('-p', '--plot-image', action='store_true')
opt = parser.parse_args()
if len(sys.argv) > 1:
print(opt)
show_image(opt.image_path, opt.anno_path, opt.show, opt.plot_image)
print(every_class_num)
print("category nums: {}".format(len(category_set)))
print("image nums: {}".format(len(image_set)))
print("bbox nums: {}".format(sum(every_class_num.values())))
else:
image_path = './data/images'
anno_path = './data/convert/voc'
show_image(image_path, anno_path, show=True, plot_image=True)
print(every_class_num)
print("category nums: {}".format(len(category_set)))
print("image nums: {}".format(len(image_set)))
print("bbox nums: {}".format(sum(every_class_num.values())))
yolo格式,图片可视化
import argparse
import os
import sys
from collections import defaultdict
import cv2
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
from tqdm import tqdm
category_set = dict()
image_set = set()
every_class_num = defaultdict(int)
category_item_id = -1
def xywhn2xyxy(box, size):
box = list(map(float, box))
size = list(map(float, size))
xmin = (box[0] - box[2] / 2.) * size[0]
ymin = (box[1] - box[3] / 2.) * size[1]
xmax = (box[0] + box[2] / 2.) * size[0]
ymax = (box[1] + box[3] / 2.) * size[1]
return (xmin, ymin, xmax, ymax)
def addCatItem(name):
global category_item_id
category_item = dict()
category_item_id += 1
category_item['id'] = category_item_id
category_item['name'] = name
category_set[name] = category_item_id
return category_item_id
def draw_box(img, objects, draw=True):
for object in objects:
category_name = object[0]
every_class_num[category_name] += 1
if category_name not in category_set:
category_id = addCatItem(category_name)
else:
category_id = category_set[category_name]
xmin = int(object[1][0])
ymin = int(object[1][1])
xmax = int(object[1][2])
ymax = int(object[1][3])
if draw:
def hex2rgb(h): # rgb order (PIL)
return tuple(int(h[1 + i:1 + i + 2], 16) for i in (0, 2, 4))
hex = ('FF3838', 'FF9D97', 'FF701F', 'FFB21D', 'CFD231', '48F90A', '92CC17', '3DDB86', '1A9334', '00D4BB',
'2C99A8', '00C2FF', '344593', '6473FF', '0018EC', '8438FF', '520085', 'CB38FF', 'FF95C8', 'FF37C7')
palette = [hex2rgb('#' + c) for c in hex]
n = len(palette)
c = palette[int(category_id) % n]
bgr = False
color = (c[2], c[1], c[0]) if bgr else c
cv2.rectangle(img, (xmin, ymin), (xmax, ymax), color)
cv2.putText(img, category_name, (xmin, ymin), cv2.FONT_HERSHEY_SIMPLEX, 1, color)
return img
def show_image(image_path, anno_path, show=False, plot_image=False):
assert os.path.exists(image_path), "image path:{} dose not exists".format(image_path)
assert os.path.exists(anno_path), "annotation path:{} does not exists".format(anno_path)
anno_file_list = [os.path.join(anno_path, file) for file in os.listdir(anno_path) if file.endswith(".txt")]
with open(anno_path + "/classes.txt", 'r') as f:
classes = f.readlines()
category_id = dict((k, v.strip()) for k, v in enumerate(classes))
for txt_file in tqdm(anno_file_list):
if not txt_file.endswith('.txt') or 'classes' in txt_file:
continue
filename = txt_file.split(os.sep)[-1][:-3] + "jpg"
image_set.add(filename)
file_path = os.path.join(image_path, filename)
if not os.path.exists(file_path):
continue
img = cv2.imread(file_path)
if img is None:
continue
width = img.shape[1]
height = img.shape[0]
objects = []
with open(txt_file, 'r') as fid:
for line in fid.readlines():
line = line.strip().split()
category_name = category_id[int(line[0])]
bbox = xywhn2xyxy((line[1], line[2], line[3], line[4]), (width, height))
obj = [category_name, bbox]
objects.append(obj)
img = draw_box(img, objects, show)
if show:
cv2.imshow(filename, img)
cv2.waitKey()
cv2.destroyAllWindows()
if plot_image:
# 绘制每种类别个数柱状图
plt.bar(range(len(every_class_num)), every_class_num.values(), align='center')
# 将横坐标0,1,2,3,4替换为相应的类别名称
plt.xticks(range(len(every_class_num)), every_class_num.keys(), rotation=90)
# 在柱状图上添加数值标签
for index, (i, v) in enumerate(every_class_num.items()):
plt.text(x=index, y=v, s=str(v), ha='center')
# 设置x坐标
plt.xlabel('image class')
# 设置y坐标
plt.ylabel('number of images')
# 设置柱状图的标题
plt.title('class distribution')
plt.savefig("class_distribution.png")
plt.show()
if __name__ == '__main__':
"""
脚本说明:
该脚本用于yolo标注格式(.txt)的标注框可视化
参数明说:
image_path:图片数据路径
anno_path:txt标注文件路径
show:是否展示标注后的图片
plot_image:是否对每一类进行统计,并且保存图片
"""
parser = argparse.ArgumentParser()
parser.add_argument('-ip', '--image-path', type=str, default='./data/images', help='image path')
parser.add_argument('-ap', '--anno-path', type=str, default='./data/labels/yolo', help='annotation path')
parser.add_argument('-s', '--show', action='store_true', help='weather show img')
parser.add_argument('-p', '--plot-image', action='store_true')
opt = parser.parse_args()
if len(sys.argv) > 1:
print(opt)
show_image(opt.image_path, opt.anno_path, opt.show, opt.plot_image)
else:
image_path = './data/images'
anno_path = './data/labels/yolo'
show_image(image_path, anno_path, show=True, plot_image=True)
print(every_class_num)
print("category nums: {}".format(len(category_set)))
print("image nums: {}".format(len(image_set)))
print("bbox nums: {}".format(sum(every_class_num.values())))Refference:
用labelme标注后先制作voc数据集,再导成YOLO格式:VOC与YOLO数据格式的相互转换 - 知乎 (zhihu.com)
YOLOv5的数据集格式转化以及训练集和验证集划分:
目标检测---数据集格式转化及训练集和验证集划分_深度学习-DevPress官方社区 (csdn.net)
yolo和voc格式数据集的标注和划分:
yolo和voc格式之数据集标注和划分_CSDN博客_yolo标注要求
yolo数据标注工具:Yolo_mark
YOLO系列网络训练数据准备工具—Yolo_mark - 腾讯云开发者社区-腾讯云 (tencent.com)
YOLOMark格式转换为VOC格式_CSDN博客_yolomark