C语言进阶——字符串函数和内存函数
目录
一. strlen
二. strcpy
三. strcat
四. strcmp
五. strncpy
六. strncat
七. strncmp
八. strstr
九. strtok
一. strlen

字符串以 '\0' 作为结束标志,strlen函数返回的是在字符串中 '\0' 前面出现的字符个数(不包
含 '\0' )。
参数指向的字符串必须要以 '\0' 结束。
注意函数的返回值为size_t,是无符号的
模拟实现
//计数
int my_strlen1(const char* s)
{
int count = 0;
while (*s++ != '\0')
{
count++;
}
return count;
}
//递归
int my_strlen2(const char* s)
{
if (*s != '\0')
return 1 + my_strlen2(s + 1);
return 0;
}
//指针相减
int my_strlen3(const char* s)
{
char* tail = s-1;
while (*++tail!= '\0')
{
;
}
return tail-s;
}而在我们的模拟实现中,返回值使用的是int,而库函数的返回值是无符号型,这两种其实各有利弊,使用int若字符串长度较大会出现负数的情况,而使用无符号型无法实现strlen相减得到字符串长度的差值。
二. strcpy

源字符串必须以 '\0' 结束。
会将源字符串中的 '\0' 拷贝到目标空间。
目标空间必须足够大,以确保能存放源字符串。
目标空间必须可变。
模拟实现
char* my_strcpy(char* s1,const char* s2)
{
assert(s1 && s2);
char* ret=s1;
while (*s2 != '\0')
{
*s1++ = *s2++;
}
return ret;
}三. strcat
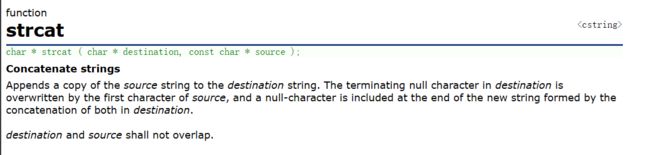
源字符串必须以 '\0' 结束。
目标空间必须有足够的大,能容纳下源字符串的内容。
目标空间必须可修改。
模拟实现
char* my_strcat(char* s1,const char* s2)
{
assert(s1 && s2);
char* ret=s1;
while (*s1++ != '\0')
{
;
}
s1--;
while (*s2 != '\0')
{
*s1++ = *s2++;
}
return ret;
}我们再考虑一个问题,s1和s2能否相同呢
int main()
{
char s[20] = "abc";
my_strcat(s, s);
printf("%s\n", s);
return 0;
}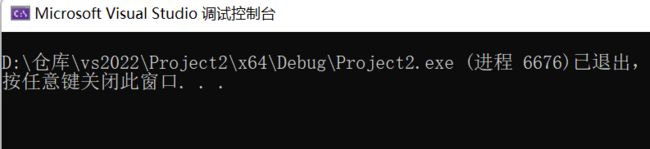
可以看到,程序发生了崩溃
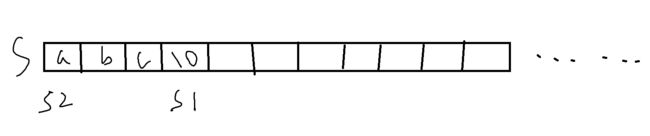
可以看到,若是s1与s2相同,首先s1要加至‘\0’处,在进行赋值时,‘\0’被替换为a,这也就使得s2在向后移动时找不到‘\0’,进而导致死循环。
四. strcmp
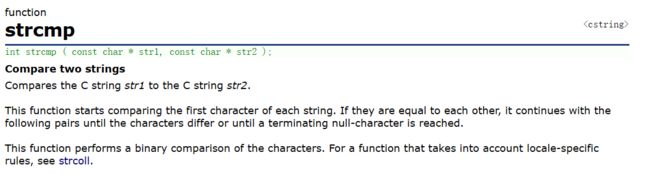
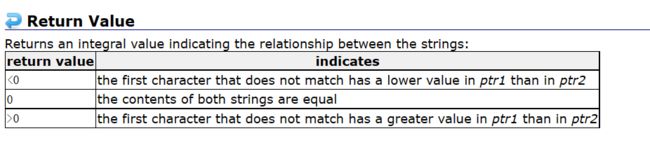
模拟实现
int my_strcmp(const char* s1,const char* s2)
{
int ret = 0;
assert(s1 && s2);
while (*s1 == *s2)
{
s1++;
s2++;
}
if (*s1 > *s2)
ret = 1;
if (*s1 < *s2)
ret = -1;
return ret;
}五. strncpy
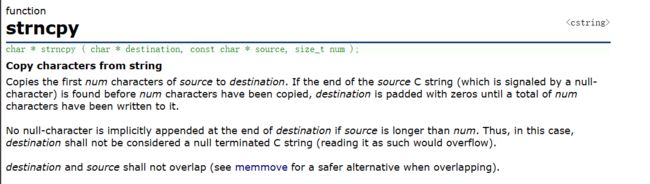
与strcpy的功能类似,只是多了一个参数num,决定拷贝的字符串长度
若拷贝的字符串小于num,则补‘\0’
模拟实现
char* my_strncpy(char* s1, const char* s2, int num)
{
assert(s1 && s2);
char* ret=s1;
while (*s2 != '\0'&&num>0)
{
*s1++ = *s2++;
num--;
}
return ret;
}六. strncat
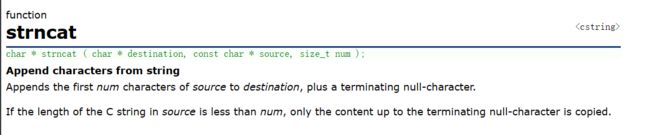
与strcat的功能类似,只是多了一个参数num,决定拼接的字符串长度
模拟实现
char* my_strncat(char* s1, const char* s2, int num)
{
assert(s1 && s2);
char* ret=s1;
while (*s1 != '\0')
{
s1++;
}
while (*s2 != '\0'&&num>0)
{
*s1++ = *s2++;
num--;
}
*s1 = '\0';
return ret;
}七. strncmp

num同上
模拟实现
int my_strncmp(const char* s1, const char* s2, int num)
{
assert(s1 && s2);
int ret = 0;
while (*s1 == *s2&&num>0)
{
num--;
if (num != 0)
{
s1++;
s2++;
}
if (*s1 == '\0' || *s2 == '\0')
break;
}
if (*s1 > *s2)
ret = 1;
if (*s1 < *s2)
ret = -1;
return ret;
}八. strstr

模拟实现
char* my_strstr(const char* s1, const char* s2)
{
assert(s1 && s2);
char* head1 = s1;
char* head2 = s2;
while(*s1!='\0')
{
while (*s1 != '\0' && *s1 != *s2)
s1++;
if (s1 == '\0')
return NULL;
head1 = s1;
while (*s1 == *s2)
{
s1++;
s2++;
if (*s2 == '\0')
return head1;
}
s1 = head1 + 1;
s2 = head2;
}
return NULL;
}九. strtok

sep参数是个字符串,定义了用作分隔符的字符集合
第一个参数指定一个字符串,它包含了0个或者多个由sep字符串中一个或者多个分隔符分割的标记。
strtok函数找到str中的下一个标记,并将其用 \0 结尾,返回一个指向这个标记的指针。(注:strtok函数会改变被操作的字符串,所以在使用strtok函数切分的字符串一般都是临时拷贝的内容并且可修改。)
strtok函数的第一个参数不为 NULL ,函数将找到str中第一个标记,strtok函数将保存它在字符串中的位置。
strtok函数的第一个参数为 NULL ,函数将在同一个字符串中被保存的位置开始,查找下一个标
记。
如果字符串中不存在更多的标记,则返回 NULL 指针。
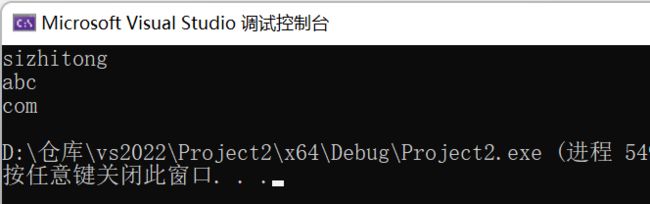
int main()
{
char* p = "[email protected]";
const char* sep = ".@";
char arr[30];
strcpy(arr, p);
char* str;
str = strtok(arr, sep);
printf("%s\n", str);
str = strtok(NULL, sep);
printf("%s\n", str);
str = strtok(NULL, sep);
printf("%s\n", str);
return 0;
}
而若是想要直接打印出去除间隔符后的结果,我们可以利用循环
int main()
{
char *p = "[email protected]";
const char* sep = ".@";
char arr[30];
char *str = NULL;
strcpy(arr, p);
for(str=strtok(arr, sep); str != NULL; str=strtok(NULL, sep))
{
printf("%s\n", str);
}
return 0;
}十. memcpy
函数memcpy从source的位置开始向后复制num个字节的数据到destination的内存位置。
这个函数在遇到 '\0' 的时候并不会停下来。
如果source和destination有任何的重叠,复制的结果都是未定义的。
模拟实现
void* my_memcpy(void* source,void* destination,int num)
{
for(int i=0;i实现起来还是很容易的,但是,我们还是要思考一下source和destination重叠的问题
例如我们给出这样的用例
void* my_memcpy(void* source,void* destination,int num)
{
for(int i=0;i我们想要的结果应该是这样的
1 2 1 2 3 4 5
而实际上却是这样的
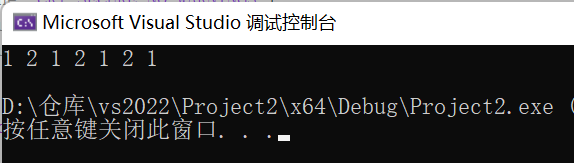
我们来分析一下
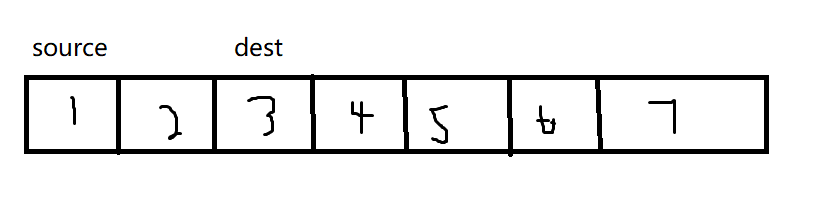 我们可以得知,source和dest都要遍历后面的五个数据,而source的后三个数据与dest部分重叠,这也就导致在source移动到一开始dest的位置时,3已经被改变为1,因此会出现上面的情况,这个问题我们会在下一个函数memmove中解决,而在我们使用vs中的memcpy,并没有出现上述的问题,这个问题我们也在介绍memmove中说明
我们可以得知,source和dest都要遍历后面的五个数据,而source的后三个数据与dest部分重叠,这也就导致在source移动到一开始dest的位置时,3已经被改变为1,因此会出现上面的情况,这个问题我们会在下一个函数memmove中解决,而在我们使用vs中的memcpy,并没有出现上述的问题,这个问题我们也在介绍memmove中说明
十一. memmove

和memcpy的差别就是memmove函数处理的源内存块和目标内存块是可以重叠的。
如果源空间和目标空间出现重叠,就得使用memmove函数处理。
在一些编译器中,将库中的memcpy修改得与memmove类似,使得在这些编译器中memcpy也可以处理重叠的数组。
模拟实现
首先memmove的模拟实现与memcpy类似,只需要再考虑重叠的问题即可
首先便是memcpy中出问题的数据
void* my_memmove(void* source, void* destination, int num)
{
for (int i = 0; i < num; i++)
{
*((char*)source + i) = *((char*)destination + i);
}
return source;
}
int main()
{
int nums[10] = { 1,2,3,4,5,6,7 };
my_memmove(nums+2, nums, 5 * sizeof(int));
for (int i = 0; i < 7; i++)
{
printf("%d ", nums[i]);
}
printf("\n");
return 0;
}可以看到,这组数据中,source与destination之间有重叠部分并且source地址高于destination的地址。
那么我们有什么解决方法呢?
从前向后赋值,source的值会被dest改变,那么我们可以选择从后向前赋值
void* my_memmove(void* source, void* destination, int num)
{
while(num--)
{
*((char*)source + num) = *((char*)destination + num);
}
return source;
}
int main()
{
int nums[10] = { 1,2,3,4,5,6,7 };
my_memmove(nums+2, nums, 5 * sizeof(int));
for (int i = 0; i < 7; i++)
{
printf("%d ", nums[i]);
}
printf("\n");
return 0;
}的确,这样会解决以上的问题,但若是重叠且source的地址低于dest
int nums[10] = { 1,2,3,4,5,6,7 };
my_memmove(nums, nums+2, 5 * sizeof(int));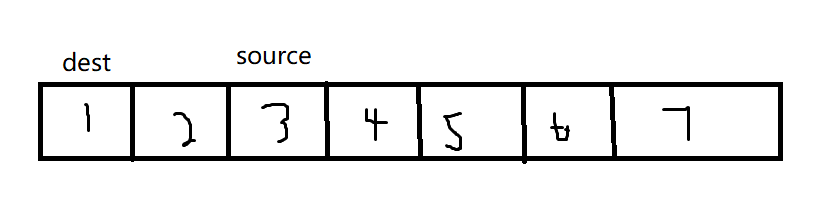
逆序会出现问题,而正序反而不会出现问题。
因此,我们需要进行条件判断,当dest的地址大于source的地址选择正序,小于则选择逆序,而且并不需要考虑是否重叠,因为若是不重叠,采用这两种方法都是可以的
void* my_memmove(void* source, void* destination, int num)
{
while (source > destination && num--)
{
*((char*)source + num) = *((char*)destination + num);
}
if(source <= destination)
{
for (int i = 0; i < num; i++)
{
*((char*)source + i) = *((char*)destination + i);
}
}
return source;
}
十二. memcmp
比较从ptr1和ptr2指针开始的num个字节

实际上,memcmp与strncpy是非常类似的,只是相较来说,memcmp可以比较任何类型的数据,但若是num大于字符数组的字节数,即使遇到‘\0’,也不会停止,大多数情况下是没什么问题的,而当两个字符数组长度相同时,同时遇到'\0'后依旧会向后进行比较,导致越界。
模拟实现
int my_memcmp(const void* s1, const void* s2, int num)
{
assert(s1 && s2);
for(int i=0;i*((char*)s2+i))
return 1;
}
return 0;
}