CSAPP perfab
CSAPP perfab
Part A
rotate实验,把nxn的正方形图片逆时针旋转90度,这是一个内存敏感的程序,优化的主要思路是分块(和cachelab很像)。由于图片的边长都是32的倍数,所以我们选择块大小为4,8,16,32去尝试哪一种性能更好,最终选择为16x16的块
Part B
smooth实验,这是一个计算敏感的程序,优化的主要思路是:
1、去掉不必要的过程调用:可以看到,为了处理边缘点,原程序用了很多min和max判断

好处就是代码简洁,坏处就是影响性能CPE。我们分别处理4个角点,4条边缘边和中间部分,并且将2x2,2x3,3x2和3x3的求和小循环展开。
2、中间部分,我们按照外层循环列,内层循环行的循环方式,不求3x3块的和,因为这样每种颜色要9次加法,我们可以利用上一次的sum结果,减去一行,再加上一行的计算方法,如图:

当我们计算完(1,1)处的sum时,我们接着计算(2,1)处的sum,此时,蓝色部分是3x3块重合的部分,我们只需要用(1,1)的结果,减去第0行的红色块,再加上第3行的绿色块,就可以得到(2,1)处的sum,这样的话,计算一个3x3的sum就只需要6次加法,比直接加9次快了1/3
然后为啥要内层按行循环呢,因为考虑到空间局部性,内层按行循环时,3次减法和3次加法操作数是空间相邻的,大概率只有2次cache不命中。
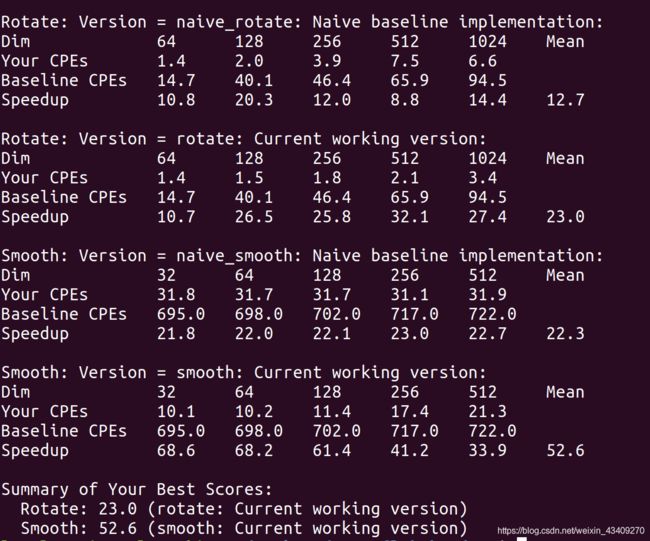
下面图片是我的结果,其中,naive的代码是未优化的,current working是我优化过的,可以发现,即使是未优化的,性能也很不错了,我猜测是机器性能好或者硬件优化好?
下面是我的kernel.c代码
/********************************************************
* Kernels to be optimized for the CS:APP Performance Lab
********************************************************/
#include
#include
#include "defs.h"
/*
* Please fill in the following team struct
*/
team_t team = {
"haha", /* Team name */
"lym", /* First member full name */
"haha@xxxx.edu.cn", /* First member email address */
"", /* Second member full name (leave blank if none) */
"" /* Second member email addr (leave blank if none) */
};
/***************
* ROTATE KERNEL
***************/
/******************************************************
* Your different versions of the rotate kernel go here
******************************************************/
/*
* naive_rotate - The naive baseline version of rotate
*/
char naive_rotate_descr[] = "naive_rotate: Naive baseline implementation";
void naive_rotate(int dim, pixel *src, pixel *dst)
{
int i, j;
for (i = 0; i < dim; i++)
for (j = 0; j < dim; j++)
dst[RIDX(dim-1-j, i, dim)] = src[RIDX(i, j, dim)];
}
/*
* rotate - Your current working version of rotate
* IMPORTANT: This is the version you will be graded on
*/
char rotate_descr[] = "rotate: Current working version";
void rotate(int dim, pixel *src, pixel *dst)
{
//naive_rotate(dim, src, dst);
int block, i, j, ii, jj;
block = 16;
for (i = 0; i < dim; i += block) {
for (j = 0; j < dim; j += block) {
for (ii = i; ii < i+block; ii++) {
for (jj = j; jj < j+block; jj++) {
dst[RIDX(dim-1-jj, ii, dim)] = src[RIDX(ii, jj, dim)];
}
}
}
}
}
/*********************************************************************
* register_rotate_functions - Register all of your different versions
* of the rotate kernel with the driver by calling the
* add_rotate_function() for each test function. When you run the
* driver program, it will test and report the performance of each
* registered test function.
*********************************************************************/
void register_rotate_functions()
{
add_rotate_function(&naive_rotate, naive_rotate_descr);
add_rotate_function(&rotate, rotate_descr);
/* ... Register additional test functions here */
}
/***************
* SMOOTH KERNEL
**************/
/***************************************************************
* Various typedefs and helper functions for the smooth function
* You may modify these any way you like.
**************************************************************/
/* A struct used to compute averaged pixel value */
typedef struct {
int red;
int green;
int blue;
int num;
} pixel_sum;
/* Compute min and max of two integers, respectively */
static int min(int a, int b) { return (a < b ? a : b); }
static int max(int a, int b) { return (a > b ? a : b); }
/*
* initialize_pixel_sum - Initializes all fields of sum to 0
*/
static void initialize_pixel_sum(pixel_sum *sum)
{
sum->red = sum->green = sum->blue = 0;
sum->num = 0;
return;
}
/*
* accumulate_sum - Accumulates field values of p in corresponding
* fields of sum
*/
static void accumulate_sum(pixel_sum *sum, pixel p)
{
sum->red += (int) p.red;
sum->green += (int) p.green;
sum->blue += (int) p.blue;
sum->num++;
return;
}
/*
* assign_sum_to_pixel - Computes averaged pixel value in current_pixel
*/
static void assign_sum_to_pixel(pixel *current_pixel, pixel_sum sum)
{
current_pixel->red = (unsigned short) (sum.red/sum.num);
current_pixel->green = (unsigned short) (sum.green/sum.num);
current_pixel->blue = (unsigned short) (sum.blue/sum.num);
return;
}
/*
* avg - Returns averaged pixel value at (i,j)
*/
static pixel avg(int dim, int i, int j, pixel *src)
{
int ii, jj;
pixel_sum sum;
pixel current_pixel;
initialize_pixel_sum(&sum);
for(ii = max(i-1, 0); ii <= min(i+1, dim-1); ii++)
for(jj = max(j-1, 0); jj <= min(j+1, dim-1); jj++)
accumulate_sum(&sum, src[RIDX(ii, jj, dim)]);
assign_sum_to_pixel(¤t_pixel, sum);
return current_pixel;
}
/******************************************************
* Your different versions of the smooth kernel go here
******************************************************/
/*
* naive_smooth - The naive baseline version of smooth
*/
char naive_smooth_descr[] = "naive_smooth: Naive baseline implementation";
void naive_smooth(int dim, pixel *src, pixel *dst)
{
int i, j;
for (i = 0; i < dim; i++)
for (j = 0; j < dim; j++)
dst[RIDX(i, j, dim)] = avg(dim, i, j, src);
}
/*
* smooth - Your current working version of smooth.
* IMPORTANT: This is the version you will be graded on
*/
typedef struct {
int red;
int green;
int blue;
} pixelSum;
static void initialize_pixelSum(pixelSum *sum)
{
sum->red = sum->green = sum->blue = 0;
return;
}
static void myAvg(int number_of_pixel, pixel *dst, pixelSum *sum)
{
dst->red = (unsigned short) (sum->red / number_of_pixel);
dst->green = (unsigned short) (sum->green / number_of_pixel);
dst->blue = (unsigned short) (sum->blue / number_of_pixel);
return;
}
char smooth_descr[] = "smooth: Current working version";
void smooth(int dim, pixel *src, pixel *dst)
{
pixelSum sum;
int i, j;
//corner (0, 0)
initialize_pixelSum(&sum);
for (i = 0; i < 2; i++) {
for (j = 0; j < 2; j++) {
sum.red += (int) src[RIDX(i, j, dim)].red;
sum.green += (int) src[RIDX(i, j, dim)].green;
sum.blue += (int) src[RIDX(i, j, dim)].blue;
}
}
myAvg(4, &dst[RIDX(0, 0, dim)], &sum);
//corner (0, dim-1)
initialize_pixelSum(&sum);
for (i = 0; i < 2; i++) {
for (j = dim-2; j < dim; j++) {
sum.red += (int) src[RIDX(i, j, dim)].red;
sum.green += (int) src[RIDX(i, j, dim)].green;
sum.blue += (int) src[RIDX(i, j, dim)].blue;
}
}
myAvg(4, &dst[RIDX(0, dim-1, dim)], &sum);
//corner (dim-1, 0)
initialize_pixelSum(&sum);
for (i = dim-2; i < dim; i++) {
for (j = 0; j < 2; j++) {
sum.red += (int) src[RIDX(i, j, dim)].red;
sum.green += (int) src[RIDX(i, j, dim)].green;
sum.blue += (int) src[RIDX(i, j, dim)].blue;
}
}
myAvg(4, &dst[RIDX(dim-1, 0, dim)], &sum);
//corner (dim-1, dim-1)
initialize_pixelSum(&sum);
for (i = dim-2; i < dim; i++) {
for (j = dim-2; j < dim; j++) {
sum.red += (int) src[RIDX(i, j, dim)].red;
sum.green += (int) src[RIDX(i, j, dim)].green;
sum.blue += (int) src[RIDX(i, j, dim)].blue;
}
}
myAvg(4, &dst[RIDX(dim-1, dim-1, dim)], &sum);
//last line
for (j = 1; j < dim-1; j++) {
initialize_pixelSum(&sum);
sum.red += (int) src[RIDX(dim-2, j-1, dim)].red
+ (int) src[RIDX(dim-2, j, dim)].red
+ (int) src[RIDX(dim-2, j+1, dim)].red;
sum.blue += (int) src[RIDX(dim-2, j-1, dim)].blue
+ (int) src[RIDX(dim-2, j, dim)].blue
+ (int) src[RIDX(dim-2, j+1, dim)].blue;
sum.green += (int) src[RIDX(dim-2, j-1, dim)].green
+ (int) src[RIDX(dim-2, j, dim)].green
+ (int) src[RIDX(dim-2, j+1, dim)].green;
sum.red += (int) src[RIDX(dim-1, j-1, dim)].red
+ (int) src[RIDX(dim-1, j, dim)].red
+ (int) src[RIDX(dim-1, j+1, dim)].red;
sum.blue += (int) src[RIDX(dim-1, j-1, dim)].blue
+ (int) src[RIDX(dim-1, j, dim)].blue
+ (int) src[RIDX(dim-1, j+1, dim)].blue;
sum.green += (int) src[RIDX(dim-1, j-1, dim)].green
+ (int) src[RIDX(dim-1, j, dim)].green
+ (int) src[RIDX(dim-1, j+1, dim)].green;
myAvg(6, &dst[RIDX(dim-1, j, dim)], &sum);
}
//first row
for (i = 1; i < dim-1; i++) {
initialize_pixelSum(&sum);
sum.red += (int) src[RIDX(i-1, 0, dim)].red
+ (int) src[RIDX(i, 0, dim)].red
+ (int) src[RIDX(i+1, 0, dim)].red;
sum.blue += (int) src[RIDX(i-1, 0, dim)].blue
+ (int) src[RIDX(i, 0, dim)].blue
+ (int) src[RIDX(i+1, 0, dim)].blue;
sum.green += (int) src[RIDX(i-1, 0, dim)].green
+ (int) src[RIDX(i, 0, dim)].green
+ (int) src[RIDX(i+1, 0, dim)].green;
sum.red += (int) src[RIDX(i-1, 1, dim)].red
+ (int) src[RIDX(i, 1, dim)].red
+ (int) src[RIDX(i+1, 1, dim)].red;
sum.blue += (int) src[RIDX(i-1, 1, dim)].blue
+ (int) src[RIDX(i, 1, dim)].blue
+ (int) src[RIDX(i+1, 1, dim)].blue;
sum.green += (int) src[RIDX(i-1, 1, dim)].green
+ (int) src[RIDX(i, 1, dim)].green
+ (int) src[RIDX(i+1, 1, dim)].green;
myAvg(6, &dst[RIDX(i, 0, dim)], &sum);
}
//last row
for (i = 1; i < dim-1; i++) {
initialize_pixelSum(&sum);
sum.red += (int) src[RIDX(i-1, dim-2, dim)].red
+ (int) src[RIDX(i, dim-2, dim)].red
+ (int) src[RIDX(i+1, dim-2, dim)].red;
sum.blue += (int) src[RIDX(i-1, dim-2, dim)].blue
+ (int) src[RIDX(i, dim-2, dim)].blue
+ (int) src[RIDX(i+1, dim-2, dim)].blue;
sum.green += (int) src[RIDX(i-1, dim-2, dim)].green
+ (int) src[RIDX(i, dim-2, dim)].green
+ (int) src[RIDX(i+1, dim-2, dim)].green;
sum.red += (int) src[RIDX(i-1, dim-1, dim)].red
+ (int) src[RIDX(i, dim-1, dim)].red
+ (int) src[RIDX(i+1, dim-1, dim)].red;
sum.blue += (int) src[RIDX(i-1, dim-1, dim)].blue
+ (int) src[RIDX(i, dim-1, dim)].blue
+ (int) src[RIDX(i+1, dim-1, dim)].blue;
sum.green += (int) src[RIDX(i-1, dim-1, dim)].green
+ (int) src[RIDX(i, dim-1, dim)].green
+ (int) src[RIDX(i+1, dim-1, dim)].green;
myAvg(6, &dst[RIDX(i, dim-1, dim)], &sum);
}
//first line
for (j = 1; j < dim-1; j++) {
initialize_pixelSum(&sum);
sum.red += (int) src[RIDX(0, j-1, dim)].red
+ (int) src[RIDX(0, j, dim)].red
+ (int) src[RIDX(0, j+1, dim)].red;
sum.blue += (int) src[RIDX(0, j-1, dim)].blue
+ (int) src[RIDX(0, j, dim)].blue
+ (int) src[RIDX(0, j+1, dim)].blue;
sum.green += (int) src[RIDX(0, j-1, dim)].green
+ (int) src[RIDX(0, j, dim)].green
+ (int) src[RIDX(0, j+1, dim)].green;
sum.red += (int) src[RIDX(1, j-1, dim)].red
+ (int) src[RIDX(1, j, dim)].red
+ (int) src[RIDX(1, j+1, dim)].red;
sum.blue += (int) src[RIDX(1, j-1, dim)].blue
+ (int) src[RIDX(1, j, dim)].blue
+ (int) src[RIDX(1, j+1, dim)].blue;
sum.green += (int) src[RIDX(1, j-1, dim)].green
+ (int) src[RIDX(1, j, dim)].green
+ (int) src[RIDX(1, j+1, dim)].green;
myAvg(6, &dst[RIDX(0, j, dim)], &sum);
}
//middle
for (j = 1; j < dim-1; j++) {
initialize_pixelSum(&sum);
sum.red += (int) src[RIDX(0, j-1, dim)].red
+ (int) src[RIDX(0, j, dim)].red
+ (int) src[RIDX(0, j+1, dim)].red;
sum.blue += (int) src[RIDX(0, j-1, dim)].blue
+ (int) src[RIDX(0, j, dim)].blue
+ (int) src[RIDX(0, j+1, dim)].blue;
sum.green += (int) src[RIDX(0, j-1, dim)].green
+ (int) src[RIDX(0, j, dim)].green
+ (int) src[RIDX(0, j+1, dim)].green;
sum.red += (int) src[RIDX(1, j-1, dim)].red
+ (int) src[RIDX(1, j, dim)].red
+ (int) src[RIDX(1, j+1, dim)].red;
sum.blue += (int) src[RIDX(1, j-1, dim)].blue
+ (int) src[RIDX(1, j, dim)].blue
+ (int) src[RIDX(1, j+1, dim)].blue;
sum.green += (int) src[RIDX(1, j-1, dim)].green
+ (int) src[RIDX(1, j, dim)].green
+ (int) src[RIDX(1, j+1, dim)].green;
sum.red += (int) src[RIDX(2, j-1, dim)].red
+ (int) src[RIDX(2, j, dim)].red
+ (int) src[RIDX(2, j+1, dim)].red;
sum.blue += (int) src[RIDX(2, j-1, dim)].blue
+ (int) src[RIDX(2, j, dim)].blue
+ (int) src[RIDX(2, j+1, dim)].blue;
sum.green += (int) src[RIDX(2, j-1, dim)].green
+ (int) src[RIDX(2, j, dim)].green
+ (int) src[RIDX(2, j+1, dim)].green;
myAvg(9, &dst[RIDX(1, j, dim)], &sum);
for (i = 2; i < dim-1; i++) {
sum.red -= (int) src[RIDX(i-2, j-1, dim)].red
+ (int) src[RIDX(i-2, j, dim)].red
+ (int) src[RIDX(i-2, j+1, dim)].red;
sum.green -= (int) src[RIDX(i-2, j-1, dim)].green
+ (int) src[RIDX(i-2, j, dim)].green
+ (int) src[RIDX(i-2, j+1, dim)].green;
sum.blue -= (int) src[RIDX(i-2, j-1, dim)].blue
+ (int) src[RIDX(i-2, j, dim)].blue
+ (int) src[RIDX(i-2, j+1, dim)].blue;
sum.red += (int) src[RIDX(i+1, j-1, dim)].red
+ (int) src[RIDX(i+1, j, dim)].red
+ (int) src[RIDX(i+1, j+1, dim)].red;
sum.green += (int) src[RIDX(i+1, j-1, dim)].green
+ (int) src[RIDX(i+1, j, dim)].green
+ (int) src[RIDX(i+1, j+1, dim)].green;
sum.blue += (int) src[RIDX(i+1, j-1, dim)].blue
+ (int) src[RIDX(i+1, j, dim)].blue
+ (int) src[RIDX(i+1, j+1, dim)].blue;
myAvg(9, &dst[RIDX(i, j, dim)], &sum);
}
}
}
/*********************************************************************
* register_smooth_functions - Register all of your different versions
* of the smooth kernel with the driver by calling the
* add_smooth_function() for each test function. When you run the
* driver program, it will test and report the performance of each
* registered test function.
*********************************************************************/
void register_smooth_functions() {
add_smooth_function(&naive_smooth, naive_smooth_descr);
add_smooth_function(&smooth, smooth_descr);
/* ... Register additional test functions here */
}