import pyspark
from pyspark.sql import SparkSession
import findspark
findspark.init()
spark = SparkSession \
.builder \
.appName("test") \
.master("local[4]") \
.enableHiveSupport() \
.getOrCreate()
导入相关库
import pandas as pd
from pyspark.sql.functions import pandas_udf
from pyspark.sql.types import *
from pyspark.sql import types
创建DataFrame
data = [[1, '1,2,3', 11, 176, '广东-深圳', '[email protected],13617855421'],
[2, '2,3', 12, 180, '湖南-长沙', '13632747086,[email protected]'],
[3, '1,3', 12, 156, '广东-深圳', '[email protected],13645668569'],
[4, '3', 15, 165, '广东-深圳', '13629452472,[email protected]'],
[5, '2', 11, 154, '江西-南昌', '13619886001,[email protected]'],
[6, '2,3', 16, 240, '广东-广州', '13652782065,[email protected]'],
[7, '1,3', 14, 266, '湖北-武汉', '[email protected],13667842501'],
[8, '1,3', 15, 165, '广东-广州', '[email protected],13673339641'],
[9, '1,2,3', 11, 176, '广东-深圳', '13643238869,[email protected]']]
schema = """
order_id integer,
product_id string,
quantity long,
amount long,
address string,
contact string
"""
df = spark.createDataFrame(data=data, schema=schema)
df.show()
'''
+--------+----------+--------+------+---------+---------------------+
|order_id|product_id|quantity|amount| address| contact|
+--------+----------+--------+------+---------+---------------------+
| 1| 1,2,3| 11| 176|广东-深圳|[email protected],136178...|
| 2| 2,3| 12| 180|湖南-长沙|13632747086,365@q...|
| 3| 1,3| 12| 156|广东-深圳|[email protected],136456...|
| 4| 3| 15| 165|广东-深圳|13629452472,147@q...|
| 5| 2| 11| 154|江西-南昌|13619886001,288@q...|
| 6| 2,3| 16| 240|广东-广州|13652782065,377@q...|
| 7| 1,3| 14| 266|湖北-武汉|[email protected],136678...|
| 8| 1,3| 15| 165|广东-广州|[email protected],136733...|
| 9| 1,2,3| 11| 176|广东-深圳|13643238869,442@q...|
+--------+----------+--------+------+---------+---------------------+
'''
自定义函数 pandas_udf
方法一
def func(Series: pd.Series) -> pd.Series:
# 正则表达式:提取手机号码
# pd.Series.str.extract()
# expand=True, 返回DataFrame对象
# expand=False, 返回Series对象
# 提取电子邮箱:(\w+@[\w\.]+)
result = Series.str.extract('(\d{11})', expand=False)
return result
# 申明返回值的数据类型
pandas_func = pandas_udf(func, StringType())
df.select('order_id', pandas_func('contact').alias('phone')).show()
'''
+--------+-----------+
|order_id| phone|
+--------+-----------+
| 1|13617855421|
| 2|13632747086|
| 3|13645668569|
| 4|13629452472|
| 5|13619886001|
| 6|13652782065|
| 7|13667842501|
| 8|13673339641|
| 9|13643238869|
+--------+-----------+
'''
方法二
@pandas_udf(StringType()) # 申明返回值的数据类型
def func(Series: pd.Series) -> pd.Series:
# 正则表达式:提取手机号码
# pd.Series.str.extract()
# expand=True, 返回DataFrame对象
# expand=False, 返回Series对象
# 提取电子邮箱:(\w+@[\w\.]+)
result = Series.str.extract('(\d{11})', expand=False)
return result
df.select('order_id', func('contact').alias('phone')).show()
'''
+--------+-----------+
|order_id| phone|
+--------+-----------+
| 1|13617855421|
| 2|13632747086|
| 3|13645668569|
| 4|13629452472|
| 5|13619886001|
| 6|13652782065|
| 7|13667842501|
| 8|13673339641|
| 9|13643238869|
+--------+-----------+
'''
自定义函数示例
示例1 pandas_udf
@pandas_udf('string') # 申明返回值的数据类型
def func(Series: pd.Series) -> pd.Series:
# 以“-”拆分列并选择第2个元素(城市)
# pd.Series.str.split()
# expand=True, 返回DataFrame对象
# expand=False, 返回Series对象
result = Series.str.split('-', expand=True).loc[:, 1]
return result
df.select('order_id', func('address').alias('city')).show()
'''
+--------+----+
|order_id|city|
+--------+----+
| 1|深圳|
| 2|长沙|
| 3|深圳|
| 4|深圳|
| 5|南昌|
| 6|广州|
| 7|武汉|
| 8|广州|
| 9|深圳|
+--------+----+
'''
示例2 pandas_udf + Iterator
from typing import Iterator
@pandas_udf('string') # 申明返回值的数据类型
# 使用yield关键字的函数称为生成器,该函数返回值为迭代器
def func(iterator: Iterator[pd.Series]) -> Iterator[pd.Series]:
for x in iterator:
# 以“-”拆分列并选择第2个元素(城市)
# pd.Series.str.split()
# expand=True, 返回DataFrame对象
# expand=False, 返回Series对象
result = x.str.split('-', expand=True).loc[:, 1]
yield result
df.select('order_id', func('address').alias('city')).show()
'''
+--------+----+
|order_id|city|
+--------+----+
| 1|深圳|
| 2|长沙|
| 3|深圳|
| 4|深圳|
| 5|南昌|
| 6|广州|
| 7|武汉|
| 8|广州|
| 9|深圳|
+--------+----+
'''
示例3 pandas_udf
@pandas_udf('float') # 申明返回值的数据类型
def func(col1: pd.Series, col2: pd.Series) -> pd.Series:
# 均价=金额/数量
result = col2 / col1
return result
df.select('order_id', func('quantity', 'amount').alias('avg_price')).show()
'''
+--------+---------+
|order_id|avg_price|
+--------+---------+
| 1| 16.0|
| 2| 15.0|
| 3| 13.0|
| 4| 11.0|
| 5| 14.0|
| 6| 15.0|
| 7| 19.0|
| 8| 11.0|
| 9| 16.0|
+--------+---------+
'''
示例4 pandas_udf + Iterator
from typing import Iterator, Tuple
@pandas_udf('float') # 申明返回值的数据类型
# 使用yield关键字的函数称为生成器,该函数返回值为迭代器
def func(iterator: Iterator[Tuple[pd.Series, pd.Series]]) -> Iterator[pd.Series]:
for col1, col2 in iterator:
# 均价=金额/数量
result = col2 / col1
yield result
df.select('order_id', func('quantity', 'amount').alias('avg_price')).show()
'''
+--------+---------+
|order_id|avg_price|
+--------+---------+
| 1| 16.0|
| 2| 15.0|
| 3| 13.0|
| 4| 11.0|
| 5| 14.0|
| 6| 15.0|
| 7| 19.0|
| 8| 11.0|
| 9| 16.0|
+--------+---------+
'''
示例5 mapInPandas
# mapInPandas会将df转换为迭代器
# 所以必须通过遍历访问其中的元素
def func(df):
# 以“,”拆分product_id为多行
for row in df:
# row为df对象
# pd.Series.str.split()
# pd.DataFrame.explode()
row['product_id'] = row['product_id'].str.split(',', expand=False)
row = row.explode('product_id')
yield row
df.mapInPandas(func, schema=df.schema).select('order_id', 'product_id').show()
'''
+--------+----------+
|order_id|product_id|
+--------+----------+
| 1| 1|
| 1| 2|
| 1| 3|
| 2| 2|
| 2| 3|
| 3| 1|
| 3| 3|
| 4| 3|
| 5| 2|
| 6| 2|
| 6| 3|
| 7| 1|
| 7| 3|
| 8| 1|
| 8| 3|
| 9| 1|
| 9| 2|
| 9| 3|
+--------+----------+
'''
示例6 groupby + applyInPandas
def func(df):
df['total'] = df['amount'].sum()
return df
schema = 'order_id integer, amount long, address string, total long'
# 以address分组对amount求和,并新增total字段
df.select('order_id', 'amount', 'address') \
.groupby('address') \
.applyInPandas(func, schema=schema).show()
'''
+--------+------+---------+-----+
|order_id|amount| address|total|
+--------+------+---------+-----+
| 7| 266|湖北-武汉| 266|
| 2| 180|湖南-长沙| 180|
| 6| 240|广东-广州| 405|
| 8| 165|广东-广州| 405|
| 5| 154|江西-南昌| 154|
| 1| 176|广东-深圳| 673|
| 3| 156|广东-深圳| 673|
| 4| 165|广东-深圳| 673|
| 9| 176|广东-深圳| 673|
+--------+------+---------+-----+
'''
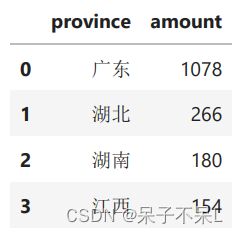
示例7 toPandas
# 将Spark的DataFrame转为Pandas的DataFrame
pd_df = df.toPandas()
pd_df[['province', 'city']] = pd_df['address'].str.split('-', expand=True)
tb = pd_df.groupby('province').agg({'amount': 'sum'}).reset_index()
tb.sort_values(by='amount', ascending=False, ignore_index=True)