python vector变量_用Python实现因子分析
因子分析(factor analysis)因子分析的一般步骤factor_analyzer模块进行因子分析使用Python实现因子分析初始化构建数据将原始数据标准化处理 X计算相关矩阵C计算相关矩阵C的特征值 和特征向量 确定公共因子个数k构造初始因子载荷矩阵A建立因子模型将因子表示成变量的线性组合.计算因子得分.
因子分析(factor analysis)
是指研究从变量群中提取共性因子的统计技术。因子分析是简化、分析高维数据的一种统计方法。
因子分析又存在两个方向,一个是探索性因子分析(exploratory factor analysis)。另一个是验证性因子分析(confirmatory factor analysis)。
探索性因子分析是先不假定一堆自变量背后到底有几个因子以及关系,而是我们通过这个方法去寻找因子及关系。
验证性因子分析是假设一堆自变量背后有几个因子,试图验证这种假设是否正确。
因子分析有两个核心问题,一是如何构造因子变量,二是如何对因子变量进行命名解释。
因子分析的一般步骤
将原始数据标准化处理 X
计算相关矩阵C
计算相关矩阵C的特征值 r 和特征向量 U
确定公共因子个数k
构造初始因子载荷矩阵,其中U为r的特征向量
建立因子模型
对初始因子载荷矩阵A进行旋转变换,旋转变换是使初始因子载荷矩阵结构简化,关系明确,使得因子变量更具有可解释性,如果初始因子不相关,可以用方差极大正交旋转,如果初始因子间相关,可以用斜交旋转,经过旋转后得到比较理想的新的因子载荷矩阵A'.
将因子表示成变量的线性组合,其中的系数可以通过最小二乘法得到.
计算因子得分.
factor_analyzer模块进行因子分析
算法核心:
对若干综合指标进行因子分析并提取公共因子,再以每个因子的方差贡献率作为权数与该因子的得分乘数之和构造得分函数。
import pandas as pd
import numpy as np
from pandas import DataFrame,Series
from factor_analyzer import FactorAnalyzer
import warnings
warnings.filterwarnings("ignore")
使用Python实现因子分析
初始化构建数据
#构建数据集
data=pd.DataFrame(np.random.randint(50,100,size=(5, 10)))
data.columns=["特征1","特征2","特征3","特征4","特征5","特征6","特征7","特征8","特征9","特征10"]
data.index=['对象1','对象2','对象3','对象4','对象5']
#查看数据
data.head(3)

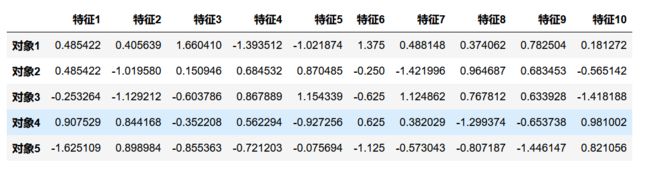
将原始数据标准化处理 X
data=(data-data.mean())/data.std() # 0均值规范化
data
计算相关矩阵C
C=data.corr() #相关系数矩阵
C

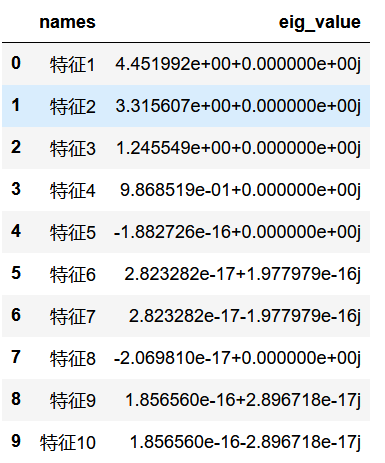
计算相关矩阵C的特征值 和特征向量
import numpy.linalg as nlg #导入nlg函数,linalg=linear+algebra
eig_value,eig_vector=nlg.eig(C) #计算特征值和特征向量
eig=pd.DataFrame() #利用变量名和特征值建立一个数据框
eig['names']=data.columns#列名
eig['eig_value']=eig_value#特征值
eig
确定公共因子个数k
from math import sqrt
for k in range(1,11): #确定公共因子个数
if eig['eig_value'][:k].sum()/eig['eig_value'].sum()>=0.8: #如果解释度达到80%, 结束循环
print(k)
break
3
eig['eig_value'][:3].sum()/eig['eig_value'].sum()
(0.9013148087274826+0j)
构造初始因子载荷矩阵A
col0=list(sqrt(eig_value[0])*eig_vector[:,0]) #因子载荷矩阵第1列
col1=list(sqrt(eig_value[1])*eig_vector[:,1]) #因子载荷矩阵第2列
col2=list(sqrt(eig_value[2])*eig_vector[:,2]) #因子载荷矩阵第3列
A=pd.DataFrame([col0,col1,col2]).T #构造因子载荷矩阵A
A.columns=['factor1','factor2','factor3'] #因子载荷矩阵A的公共因子
A

建立因子模型
h=np.zeros(10) #变量共同度,反映变量对共同因子的依赖程度,越接近1,说明公共因子解释程度越高,因子分析效果越好
D=np.mat(np.eye(10))#特殊因子方差,因子的方差贡献度 ,反映公共因子对变量的贡献,衡量公共因子的相对重要性
A=np.mat(A) #将因子载荷阵A矩阵化
for i in range(10):
a=A[i,:]*A[i,:].T #行平方和
h[i]=a[0,0] #计算变量X共同度,描述全部公共因子F对变量X_i的总方差所做的贡献,及变量X_i方差中能够被全体因子解释的部分
D[i,i]=1-a[0,0] #因为自变量矩阵已经标准化后的方差为1,即Var(X_i)=第i个共同度h_i + 第i个特殊因子方差
将因子表示成变量的线性组合.
from numpy import eye, asarray, dot, sum, diag #导入eye,asarray,dot,sum,diag 函数
from numpy.linalg import svd #导入奇异值分解函数
def varimax(Phi, gamma = 1.0, q =10, tol = 1e-6): #定义方差最大旋转函数
p,k = Phi.shape #给出矩阵Phi的总行数,总列数
R = eye(k) #给定一个k*k的单位矩阵
d=0
for i in range(q):
d_old = d
Lambda = dot(Phi, R)#矩阵乘法
u,s,vh = svd(dot(Phi.T,asarray(Lambda)**3 - (gamma/p) * dot(Lambda, diag(diag(dot(Lambda.T,Lambda)))))) #奇异值分解svd
R = dot(u,vh)#构造正交矩阵R
d = sum(s)#奇异值求和
if d_old!=0 and d/d_old:
return dot(Phi, R)#返回旋转矩阵Phi*R
rotation_mat=varimax(A)#调用方差最大旋转函数
rotation_mat=pd.DataFrame(rotation_mat)#数据框化
rotation_mat

计算因子得分.
data=np.mat(data) #矩阵化处理
factor_score=(data).dot(A) #计算因子得分
factor_score=pd.DataFrame(factor_score)#数据框化
factor_score.columns=['因子A','因子B','因子C'] #对因子变量进行命名
factor_score
#factor_score.to_excel(outputfile)#打印输出因子得分矩阵
 喜欢 分享 or
喜欢 分享 or