有向加权图 最大弱连通分支_Weakly Supervised VAD | 弱监督视频异常检测

一直以来,异常检测都是focus on 无监督(也有说是半监督),所需要挑战的数据集多是监控视频下的行人道上的数据集,所要挑战的异常都是未见物体/异常运动(快速运动为主)。这些数据集和真实情景期望解决的危险有所差别,于是[1]提出了UCF-Crime数据集,并且引入了弱监督的多示例学习的方法进入异常检测。
1. CVPR 2018: Real World Anomaly Detection in Surveillance Video[1]
本文最大贡献在于提出了一个真实场景下的异常(危险)数据集UCF-Crime。数据集总共包含有1900个视频,划分有1610个视频做训练集,其中正常占800个,异常有810个。其中它们的标记是Video-level的。而测试部分包括有290个视频,其中正常包括有150个。视频长短不一,最长的能够有976503帧,最短只有104帧。
另外打破了异常检测常见的无监督设定,选取了弱监督的设定,这能够一定程度打破现有异常检测的小数据集,也符合工业界对非真实异常(危险)检测的需求。
本文细节[CVPR 2018论文笔记] 真实监控场景中的异常事件检测 讲的很仔细,我就不过多复述。

本质上只是pretrained C3D提取特征,输入一个三层FC 网络获得预测分值,另外考虑到异常的标记是含噪的,异常事件的是有事件连续性的,因此给异常部分的预测加上了稀疏约束和时间平滑约束。而基本的loss是用了Hinge Loss.

2. CVPR 2019: Graph Convolutional Label Noise Cleaner: Train a Plug-and-play Action Classififier for Anomaly Detection[2]
在上文中提到的MIL设置中,正常的标记是pure的,但是异常是夹杂着正常的部分。本文引入了noise label cleaner 的做法到此,对于异常部分的标记进行一定的噪音清除,以此训练一个Action Classifier,测试时只需要使用这个classifier就能够做能够产生出一个异常分值。
2.1 Framework

以C3D为例,主要的流程包括:
- 以Sport 1M 预训练C3D
- 替代C3D的最后分类层为1输出的regression,以Video-Level label进行训练 (Direct Loss)
- 利用10 Crop(中心、四角及其镜像) input输入C3D,获取其regression output作为scores,而FC7 output作为features.
- 以10 crops的scores的mean作为该snippet的预测标记,以其variance作为置信度,给定的threshold 获取高置信度的正常和异常,以这些高置信度的标记以训练Label Noise Cleaner
- 训练好的Noise Label Cleaner对于所有的features都做一次预测,得到了Snippet-level Less Noise Labels,再以此label重新训练C3D.
- 重复Step 3-5得到较好的分类器。
训练阶段挺麻烦的,Noise Label Cleaner 和Action Classifier是交替训练的,这就需要反复的取特征/取分值(用两张1080抽特征花了我一天),然后再去训练Noise Label Cleaner。
2.2 GCN Noise Label Cleaner

本文最主要是提出GCN Noise Label Cleaner的模块,主要是两层FC+特征相似图GCN+时序一致性图GCN,两个GCN output经过AVG Pooling 进行混合,从而得到预测分值。
2.2.1 Feature Similarity Graph
给定一个视频V,那么其所有的snippets都是一个节点,邻接矩阵$A_F$,定义如下(这本来就是self-loop,文中再加上$I_n$似乎没必要)。
然后做一个正则化的拉普拉斯矩阵
那么这个这个图卷积结果如下:

2.2.2 Temporal Consistency Graph
给定一个视频有T个snippets,那么构建一个时序一致性图只与$A_T$只是跟时序相关,这里利用了拉普拉斯核函数来计算两个snippet的相似性,

那么对应的时序一致性图可以表示为:

2.3 Loss
这里的loss都是指Graph Label Noise Cleaner的Loss,分为直接损失和简洁损失两个部分。
2.3.1 Directly Loss
直接损失其实就是高置信度的片段的 Cross Entropy Error. 正如之前说的以10crop预测的mean作为预测标记,而其variance作为置信度。这里的就以Action Classifier预测的mean作为准确标记。

2.3.2 Indirectly Loss
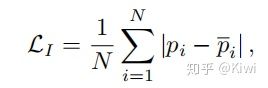
这里的$p_i$ 是指在训练阶段当中对于这一段预测的加权平均,用以平滑网络在不同训练阶段的预测结果,减少大的波动。
2.3 Experiments
文中主要对C3D和TSN的进行了实验。后者包括了TSN-RGB和TSN-Flow两种,而前者总比后者性能要好。
2.3.1 UCF-Crime
在UCF-Crime的数据集上,经过了三次的label noise clean后的得到了最好的表现结果。其中在TSN-RGB上效果最好。

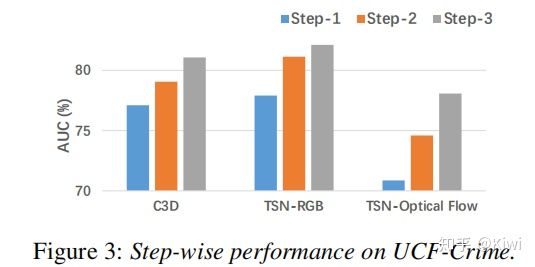
2.3.2 ShanghaiTech
这里,本文对ShanghaiTech数据集重新的安排,训练集既包括正常也有异常,测试集亦然,从而能够做到弱监督训练。

2.4 Discussion
- TSN的input是5帧,而C3D是16帧。越长的snippet是相对而言越难拿到高置信度的预测,这个长度是不是才是TSN based 模型更优异的原因?
- 提取特征/分数耗时较多,能不能够产生one-stage的模型?
3. IJCAI 2019: Margin Learning Embedded Prediction for Video Anomaly Detection with A Few Anomalies[3]
3.0 Overview
与前面两篇不一样,没有使用UCF-Crime,并且提出了open-set的异常检测的子topic。认为由于异常是无限的,对于open-set,我们常用Metric Learning 例如Triplet Loss等,这里同样也用了Triplet Loss,同时附加上无监督的预测损失,结合Margin Learning和无监督预测来做异常检测。

本文基于Avenue、ShanghaiTech做的open-set:实际上对原来的测试集进行10-fold,取1/10测试集放进训练集,然后进行训练。认为UCF-Crime多背景/角度与现实不符(这个可从ShanghaiTech的表现大概可知,其实原有的无监督方法都倾向于固定的背景和角度。),而没有选择使用这个数据集。对于取1/10的测试集放进训练集训练的做法,然后认为仍在测试集的异常为unseen,这样的分法有些粗略,不过这三个数据集本来就没有标记异常的类别。
3.1 Framework
3.1.1 ConvLSTM
ConvLSTM用在异常检测也不是第一天的事了,当然之前的做法是Conv+Composite LSTM。这里换了个更强的Encoder和Decoder(将CycleGAN 的generator拆成两部分,encoder还带着三个Residual Block,使用前T帧Encoded Feature 输入LSTM,然后预测T+1帧)。相对于17 ICME[4]的模型而言,这更像CVPR 18[5]的预测未来帧。
3.1.2 Loss
文中同时对于Video-Level Annotation和Frame-Level Annotation进行训练。那么在Loss设置也考虑这个问题。由上图我们也可以看到,这包括了Margin Learning Loss 和 Prediction Loss。
3.1.2.1 Prediction Loss
这里只是使用了L1 Loss 来计算预测与实际的差别
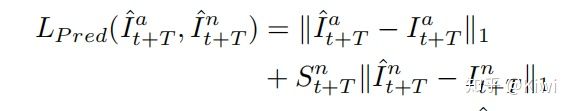
3.1.2.2 Margin Loss
这里的边缘损失,实际上是加权三元组损失,随机选取一个snippet作为anchor,然后选择一个正常的snippet和异常的snippet,从而计算这些的hidden feature的weighted Triplet Loss.

3.1.2.3 Normality Confidence
上面的公式的$S_{t+T}^*$,在Frame-Level的监督下,正常就是1,异常就是0。而在Video-Level的监督下,正常自然就是1。那么对于异常而言,首先用只有正常数据去训练一个ConvLSTM,以其Regular Score作为异常的权重;另外使用0.5作为阈值,划分positive和negative部分。
3.1.2.4 Total Loss
实际使用时$lambda$取1.
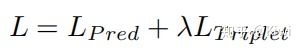
3.2 Experiments
这里沿用了CVPR 2018的计算方法,采用PSNR来计算异常分值。
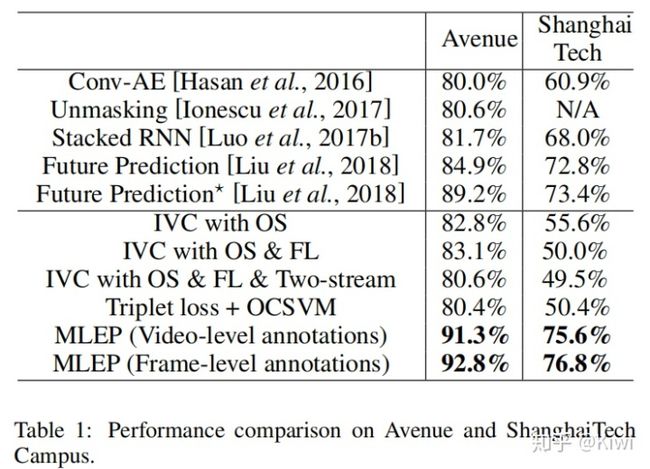
第一列的两个Future Prediction是采用不同的generator的,前者使用的是UNet,后者是ConvLSTM,在无监督设置下,其实就已经能够在Avenue上得到接近90%的表现,而在增加了10%的异常作为弱监督加入到训练后,得到了数个百分点的提升。

对比不同的generator,在与本模型同样的设置下对比其表现,发现ConvLSTM generator更优,能够获得更高的score gap和AUC.
3.3 Disscussions
- open-set是异常检测落地所必须面对的挑战,本文首次提出这个是值得考虑和关注的。
- Imbalance Classification 与异常检测是有一定的关联,本文以此作为baseline,其表现同样告诉我们,需要对此给予更多关注,尤其弱监督设定。
- 传统的无监督做法,以测试集作为调参的标准,实际上模型的表现能力是否在实际应用中得到体现,是否会存在overfit的现象?弱监督相对而言可能会有所帮助,附加上度量学习,能够进一步提高正常和异常的差异。
4. Reference
[1] Real World Anomaly Detection in Surveillance Video, CVPR 2018. paper code
[2] Graph Convolutional Label Noise Cleaner: Train a Plug-and-play Action Classififier for Anomaly Detection paper code
[3] Margin Learning Embedded Prediction for Video Anomaly Detection with A Few Anomalies IJCAI 2019 paper
[4] Remembering history with convolutional LSTM for anomaly detection, ICME 2017 paper
[5] Future Frame Prediction for Anomaly Detection - A New Baseline CVPR 2018 paper my_blog
一家之言,难免疏漏,望不吝斧正~
本文同步于个人专栏
CV上手之路zhuanlan.zhihu.com