基于Weka的典型数据挖掘应用
-
实验目标
理解数据挖掘的基本概念,掌握基于Weka工具的基本数据挖掘(分类、回归、聚类、关联规则分析)过程。
-
实验内容
- 下载并安装Java环境(JDK 7.0 64位)。
- 下载并安装Weka 3.7版。
- 基于Weka的数据分类。
- 基于Weka的数据回归。
- 基于Weka的数据聚类。
- 基于Weka的关联规则分析。
-
实验步骤
-
下载并安装Java环境(JDK 7.0 64位)
1. 搜索JDK 7.0 64位版的下载,下载到本地磁盘并安装。
我的电脑已经预先装过了jdk8,在dos窗口下用java-version命令测试,结果下图所示:

2. 配置系统环境变量PATH,在末尾补充JDK安装目录的bin子目录,以便于在任意位置都能执行Java程序。
先在系统同环境变量里面配置了JAVA_HOME,值为JDK的安装目录,然后在path里面添加了JDK的bin目录,如下图所示:
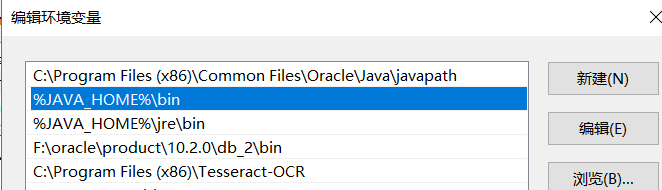
-
下载并安装Weka 3.7版
电脑上安装的是weka3.8,运行初始界面如下图所示:

-
基于Weka的数据分类
1. 读取“电费回收数据.csv”(逗号分隔列),作为原始数据。
操作步骤: 1.主界面点击“explorer” 进入探索者界面。2.点击 open file打开“电费回收数据.csv”文件 。3.打开之后点击“edit”,可查看原始数据 ,原始数据部分内容如下图所示:

实验开始前先去除对于电费回收分析无用的属性列,包括:YMD:(日期),CONS_NO(用户编号),RCVED_DATE(实收日期),CUISHOU_COUNT(催收次数),数据全为0,对于分析无帮助,去除。WZCS(违章次数),数据全为0,对于分析无帮助,去除。
去除无用属性列之后的数据集如下图所示:

2. 数据预处理
(1) 将数值型字段规范化至[0,1]区间。
规范化处理就是把连续型取值(numeric type)转化为离散型取值(nominal type)。
操作步骤:filter->unsupervised->attribute->normalize
normalize的默认参数是[0,1],直接点击apply按钮将数据集的字段规范化到[0,1]区间。规范化之后的数据集如下图所示:

(2)调用特征选择算法(Select attributes),选择关键特征。
特征选择是通过搜索数据中所有可能的属性组合,以找到预测效果最好的属性子集。自动选择属性需要设立两个对象:属性评估器和搜索方法。在进行特征选取时采取了两种方法进行特征选取,方法1注重对特征子集进行评价,方法2侧重对单个属性进行评价。
方法1:
选择CfsSubsetEval作为属性评估方法,这种方法根据属性子集中每一个特征的预测能力以及它们之间的关联性进行评估。
选择GreedyStepwise作为搜索算法,该方法进行向前向后的单步搜索。
然后点击start按钮开始选取关键特征,选取结果如下图所示:
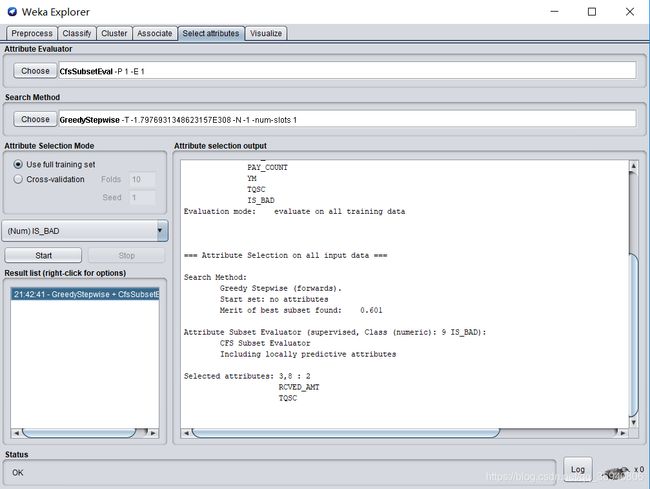
由选取结果可看出,应选取RCVED(实收电费),TQSC(欠费时长)两个属性作为关键属性。
方法2:
选择InfoGainAttributeEval作为属性评估方法,根据与分类有关的每一个属性的信息增益进行评估。
选择Ranker作为搜索算法,对属性值排序。
然后点击start按钮开始选取关键特征,选取结果如下图所示: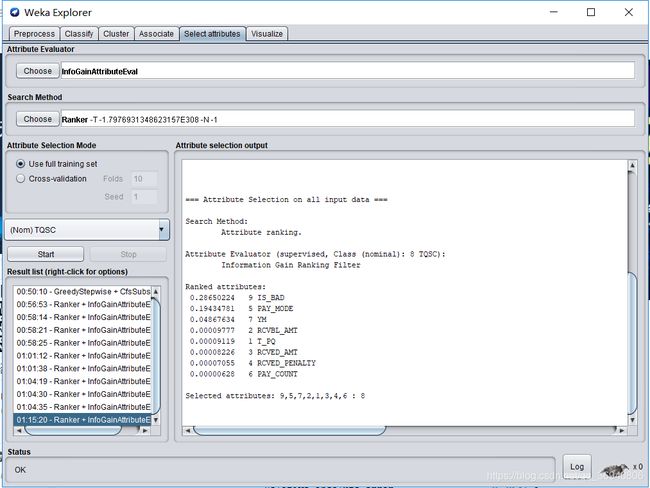
由结果可看出,应选取IS_BAD(是否为欠费用户),PAY_MODEL(支付方式)两个属性作为关键属性。
3. 分别使用决策树(J48)、随机森林(RandomForest)、神经网络(MultilayerPerceptron)、朴素贝叶斯(NaiveBayes)等算法对数据进行分类,取60%作为训练集,记录各算法的查准率(precision)、查全率(recall)、混淆矩阵与运行时间。
进行分类前先进行离散化处理,为什么要进行离散化呢,这里百度了一下:连续特征离散化的基本假设,是默认连续特征不同区间的取值对结果的贡献是不一样的。特征的连续值在不同的区间的重要性是不一样的,所以希望连续特征在不同的区间有不同的权重,实现的方法就是对特征进行划分区间,每个区间为一个新的特征。离散化后的优点有:1.稀疏向量内积乘法运算速度快,计算结果方便存储,容易扩展。2.离散化后的特征对异常数据有很强的鲁棒性,也就是防止异常数据的干扰。3.特征离散化后,模型会更稳定,4.逻辑回归属于广义线性模型,表达能力受限;单变量离散化为N个后,每个变量有单独的权重,相当于为模型引入了非线性,能够提升模型表达能力,加大拟合。
离散化之后的数据集属性如下图所示:
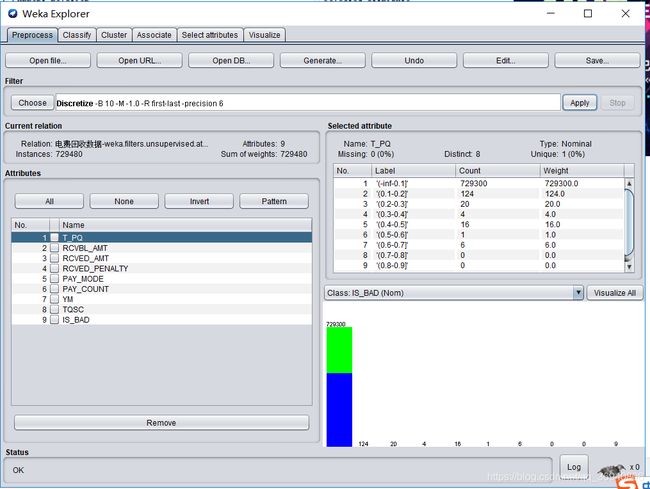
分类之前先了解了一下查准率(precision)和查全率(recall)的意思
网上对于查准率(precision)的定义:查准率是针对我们预测结果而言的,它表示的是预测为正的样例中有多少是真正的正样例。
网上对于查全率(recall)的定义:查全率是针对我们原来的样本而言的,它表示的是样本中的正例有多少被预测正确。
a)使用决策树(J48)进行分类
查准率(precision),查全率(recall)如下图所示:
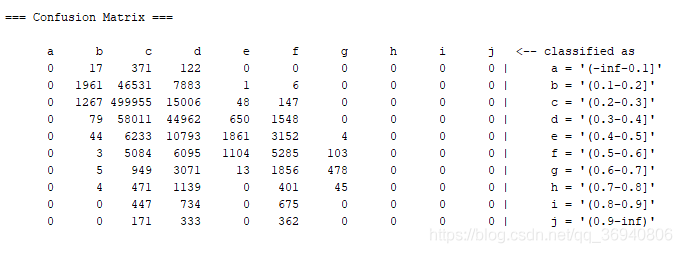
混淆矩阵(Confusion Matrix)如下图所示:
运行时间如下图所示:

b)使用随机森林(RandomForest)进行分类
查准率(precision),查全率(recall)如下图所示:
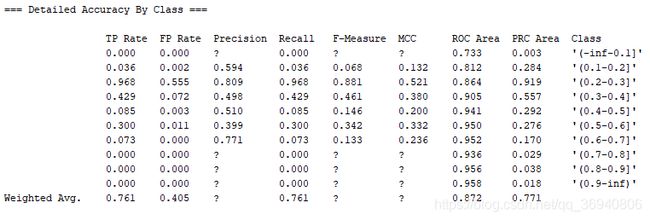
混淆矩阵(Confusion Matrix)如下图所示:
运行时间如下图所示:
c)使用神经网络(MultilayerPerceptron)进行分类
使用此算法进行分类时,没输出想要的东西,运行结果如下图所示:
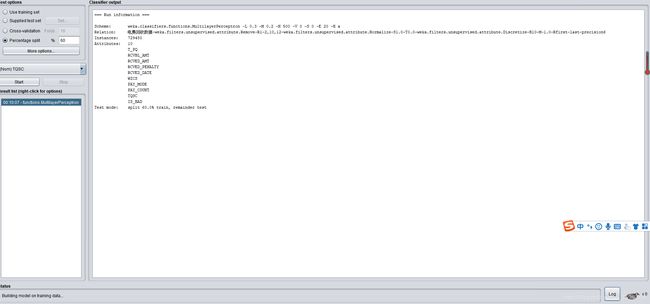
d)使用朴素贝叶斯(NaiveBayes)进行分类
查准率(precision),查全率(recall)如下图所示:

混淆矩阵(Confusion Matrix)如下图所示:
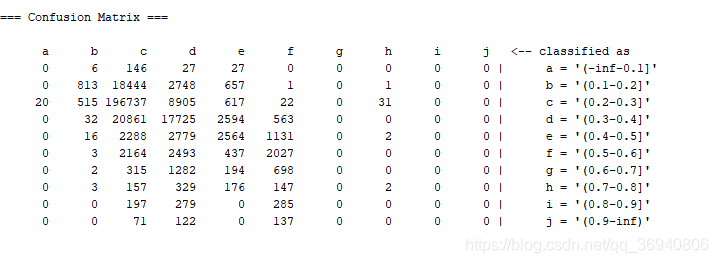
运行时间如下图所示:
![]()
-
基于Weka的回归分析
1. 读取“配网抢修数据.csv”,作为原始数据。
操作步骤: 1.主界面点击“explorer” 进入探索者界面。2.点击 open file打开“配网抢修数据.csv”文件 。3.打开之后点击“edit”,可查看原始数据 ,原始数据部分内容如下图所示:

实验开始前去除对于配网抢修数据分析无用的属性列:YMD:(日期),对于本次实验对于配网抢修分析无关,去除。REGION_ID(地区编号),对于分析无帮助,去除。
去除无用属性列之后的数据集如下图所示:

2.数据预处理:
(1)将数值型字段规范化至[0,1]区间。
操作过程:filter->unsupervised->attribute->normalize
默认参数是[0,1],然后点击apply应用按钮将字段规范化到[0,1]区间
规范化之后的结果如下图所示:

(2)调用特征选择算法(Select attributes),选择关键特征。
在进行特征选取时采取了两种方法进行特征选取,方法1注重对特征子集进行评价,方法2侧重对单个属性进行评价。
方法1:
选择CfsSubsetEval作为属性评估方法,这种方法根据属性子集中每一个特征的预测能力以及它们之间的关联性进行评估。
选择GreedyStepwise作为搜索算法:该方法进行向前向后的单步搜索。
点击start按钮开始选取,运行结果如下图所示:

由结果可看出,应选取HIGH_TEMP(开始气温), MAX_VALUE(负荷最大值), MIN_VALUE(负荷最小值)三个属性作为关键属性。
方法2:
选择InfoGainAttributeEval作为属性评估方法,根据与分类有关的每一个属性的信息增益进行评估。
选择Ranker作为搜索算法:对属性值排序。
点击start按钮开始选取,运行结果如下图所示:
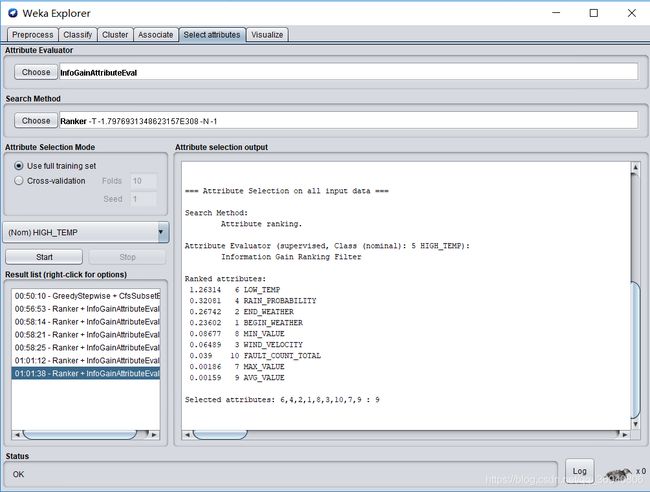
分析结果可知,应选取LOW_TEMP(结束气温),RAIN_PROBABILITY(降雨概率),END_WEATHER(结束天气),BEGIN_WEATHER(开始天气)四个属性作为关键属性。
3. 分别使用随机森林(RandomForest)、神经网络(MultilayerPerceptron)、线性回归(LinearRegression)等算法对数据进行回归分析,取60%作为训练集,记录各算法的均方根误差(RMSE,Root Mean Squared Error)、相对误差(relative absolute error)与运行时间。
a)使用随机森林(RandomForest)进行回归分析
均方根误差(RMSE,Root Mean Squared Error)、相对误差(relative absolute error)如下图所示:
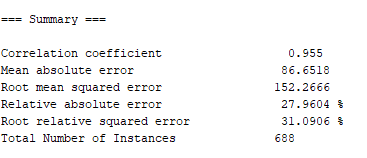
运行时间如下图所示:
![]()
b)使用神经网络(MultilayerPerceptron)进行回归分析
均方根误差(RMSE,Root Mean Squared Error)、相对误差(relative absolute error)如下图所示:

运行时间如下图所示:

c)使用线性回归(LinearRegression)进行回归分析
均方根误差(RMSE,Root Mean Squared Error)、相对误差(relative absolute error)如下图所示:

运行时间如下图所示:
-
基于Weka的数据聚类
1. 读取“移动客户数据.tsv”(TAB符分隔列),作为原始数据。
weka无法读取.tsv格式的数据,先使用excel工具将“ 移动客户数据表.tsv”格式转换成“移动客户数据表.csv”格式 ,然后再使用weka读取文件。
读取的数据集如下图所示:

2. 数据预处理
(1) 将数值型字段规范化至[0,1]区间。
操作过程:filter->unsupervised->attribute->normalize
默认参数是[0,1],然后点击apply应用将字段规范化到[0,1]区间
规范化之后的数据集如下图所示:

(2) 调用特征选择算法(Select attributes),选择关键特征。
方法1:选择CfsSubsetEval作为属性评估方法
选择GreedyStepwise作为搜索算法
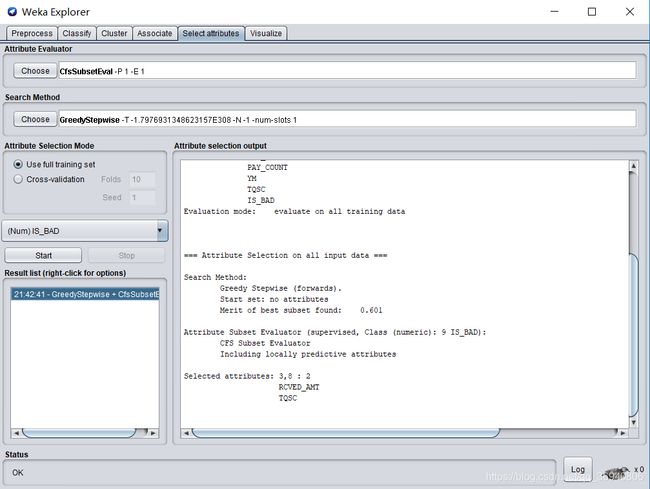
由结果可看出,应选取RCVED(实收电费),TQSC(欠费时长)两个属性作为关键属性。
方法2:选择InfoGainAttributeEval作为属性评估方法,根据与分类有关的每一个属性的信息增益进行评估。
选择Ranker作为搜索算法:对属性值排序。
点击start按钮开始选取

由结果可看出,应选取IS_BAD,PAY_MODEL(支付方式)两个属性作为关键特征。
3. 分别使用K均值(SimpleKMeans)、期望值最大化(EM)、层次聚类(HierarchicalClusterer)等算法对数据进行聚类,记录各算法的聚类质量(sum of squared errors)与运行时间。
(1) 使用K均值(SimpleKMeans)算法进行聚类
聚类质量(sum of squared errors)如下图所示:

运行时间如下图所示:

(2) 使用期望值最大化(EM)算法进行聚类
聚类质量(sum of squared errors)如下图所示:

运行时间如下图所示:

(3) 使用层次聚类(HierarchicalClusterer)算法进行聚类
没做出来!
-
基于Weka的关联规则分析
1. 读取“配网抢修数据.csv”,作为原始数据。

2. 数据预处理:
(1) 将数值型字段规范化至[0,1]区间。
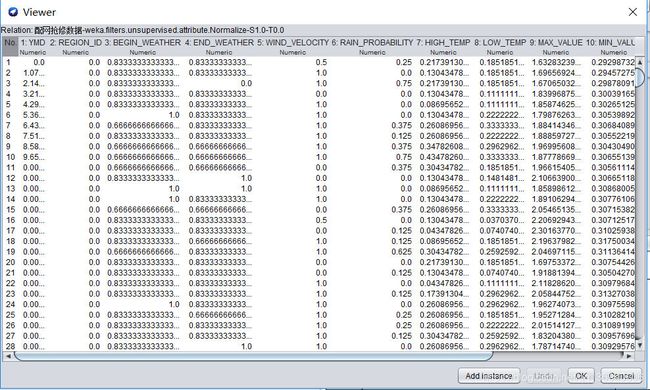
(2) 调用特征选择算法(Select attributes),选择关键特征。
在进行特征选取时,选择CfsSubsetEval作为属性评估方法,GreedyStepwise作为搜索算法,选取结果如下图所示:

由结果可看出,应选取HIGH_TEMP(开始气温),MAX_VALUE(负荷最大值),MIN_VALUE(负荷最小值)两个属性作为关键属性。
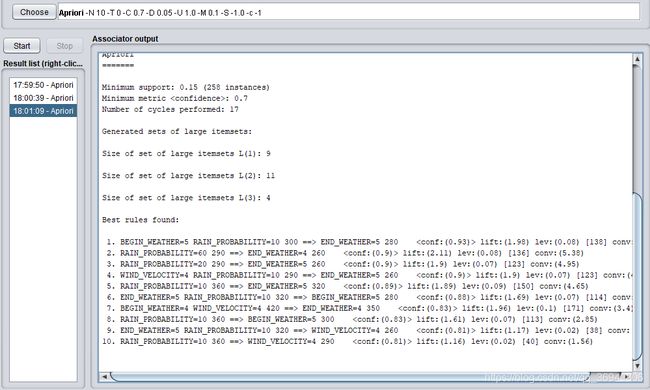
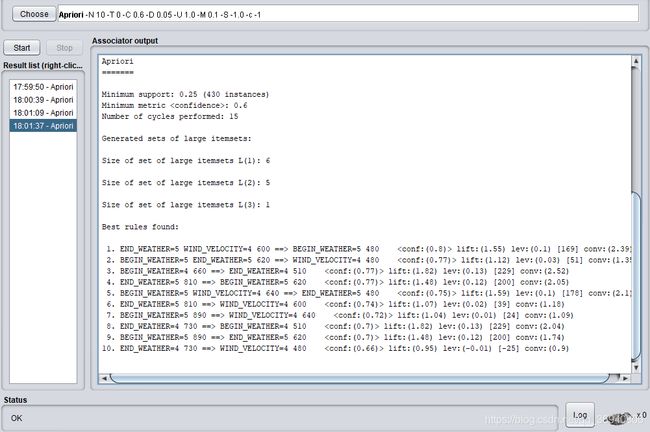
3. 使用Apriori算法对数值型字段进行关联规则分析,记录不同置信度(confidence)下算法生成的规则集。
在使用该算法之前需要使用NumericalToNominal过滤器将数据离散化,离散化操作如下图所示:
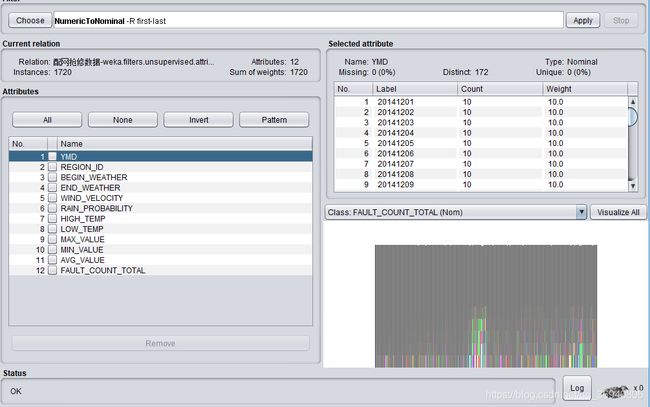
然后使用Apriori算法对数值型字段进行关联规则分析,每次通过改变minMertic的值来设置不同的置信度,下面是0.1, 0.2, 0.3,0.4, 0.5, 0.6, 0.7, 0.8, 0.9九个不同置信度下生成的规则集。
当置信度=0.9时:

当置信度=0.8时:

当置信度=0.7时:
当置信度=0.6时:
当置信度=0.5时:

当置信度=0.4时:
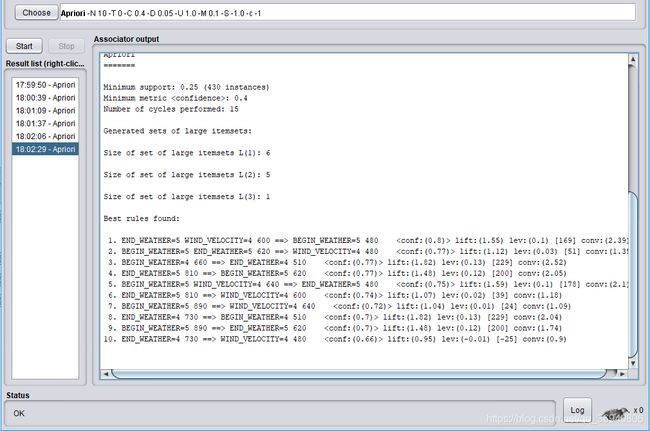
当置信度=0.3时:
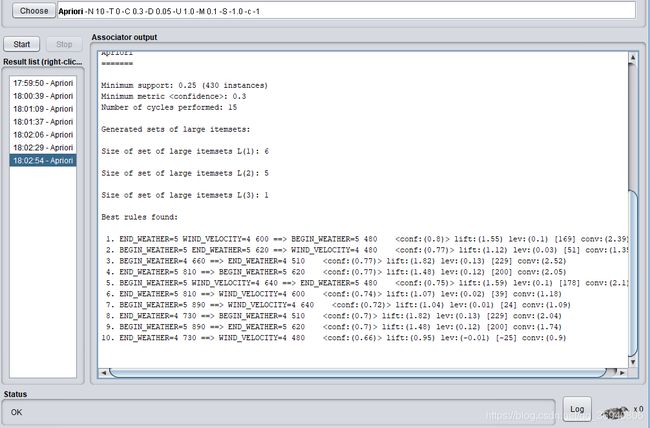
当置信度=0.2时:

当置信度=0.1时:
