目标检测与识别算法综述:从传统算法到深度学习(一)
作 者:XJTU_Ironboy
时 间:2018年11月
联系方式:[email protected]
本文结构:
- 摘要
- 介绍
2.1 大致框架
2.2 测试评价指标
2.3 相关比赛介绍
2.4 相关数据集介绍 - 基于图像处理和机器学习算法
3.1 相关特征介绍
3.1.1 Harr特征
3.1.2 SIFT(尺度不变特征变换匹配算法)
3.1.3 HOG(方向梯度直方图特征)
3.1.4 SURF(加速稳健特征)
3.2 经典的算法
3.2.1 Haar特征+Adaboost算法
3.2.2 Hog特征+Svm算法
3.2.3 DPM算法 - 基于深度学习算法
4.1 基于region proposal的目标检测与识别算法
4.1.1 R-CNN
4.1.2 SPP-Net
4.1.3 Fast R-CNN
4.1.4 Faster R-CNN
4.2 基于regression的目标检测与识别算法
4.2.1 YOLO
4.2.2 SSD
4.2.3 RFCN
4.2.4 Mask-RCNN
4.3 基于search的目标检测与识别算法
4.3.1 基于视觉注意的AttentionNet
4,3.2 基于强化学习的算法 - 总结
- 致未来
1. 摘要
随着计算机技术的发展和计算机视觉原理的广泛应用,利用计算机图像处理技术对目标进行实时跟踪研究越来越热门,对目标进行动态实时跟踪定位在智能化交通系统、智能监控系统、军事目标检测及医学导航手术中手术器械定位等方面具有广泛的应用价值。本文主要系统性地介绍了计算机视觉在目标检测与识别领域相关的基本知识、算法及应用。
2. 介绍
随着人工智能技术,尤其是深度学习算法在计算机视觉领域的广泛应用,目标检测与识别技术在图像和视频中的精度和实时性也越来越高。越来越多的相关研究成果发表在各种人工智能、计算机视觉和模式识别的顶级期刊和会议上,并且也有越来越多的计算机视觉初创公司将该技术应用到真实的场景中。在各种公开数据集上,目标检测与识别算法的水平不断攀升,算法性能也不断地接近人类甚至超越人类。
2.1 大致框架
目标检测(Object detection)通俗的讲就是在一幅图像中精确地找到各种物体所在的位置,并标注出每个物体的类别。然而,这个对于人类来说看似简单的问题,计算机却不是那么容易解决,因为物体的尺寸变化范围很大,摆放物体的角度,姿态不定,可以出现在图片的任何地方,而且物体还可以是多个类别,更何况图像上还可能存在干扰噪声。
所以目标检测与识别任务最终归结为两个问题:目标定位(localization)和图像分类(classification)。
- 目标定位(localization)
输入:图片
输出:方框在图片中的位置(x,y,w,h) - 图像分类(classification)
输入:图片
输出:物体的类别
任务的难点在于待检测区域/候选的提取与识别,所以,任务的大框架为:
- 从场景中提取待识别的候选区域(一般远大于最后成功识别出来的目标个数);
- 提取候选区域的图像特征;
- 输入特征,进行图像分类(classification)和边界回归(regression);
2.2 测试评价指标
对于目标检测和识别有一些基本的测试评价指标需要了解,这些指标用来衡量算法的优劣性,主要是从实时性和准确度两个方面来进行评估。以下表的二分类预测情况为例来讲述:

- Accuracy(准确率)::即判断正确的样本数量占总样本数量的比例,在上表中显然TP(真实类别为1,预测类别也为1)和TN(真实类别为0,预测类别也为0)是被判断正确的,所以计算公式: A c c u r a c y = T P + T N T N + F N + F P + T P Accuracy = \frac{TP+TN}{TN+FN+FP+TP} Accuracy=TN+FN+FP+TPTP+TN
- Precision(精确率):代表真实正样本在划分为正样本中的概率 ,即预测为1的样本(FP+TP)中,真实为1的样本(TP)占的比例,所以计算公式: P r e c i s i o n = T P F P + T P Precision= \frac{TP}{FP+TP} Precision=FP+TPTP
- Recall(召回率):代表将真实正样本划分为正样本的概率,即真实为1的样本(FN+TP)中,被预测对的样本(TP)占的比例,所以计算公式: R e c a l l = T P F N + T P Recall= \frac{TP}{FN+TP} Recall=FN+TPTP
- IOU:物体检测需要定位出物体的bounding box,就像下面的图片一样,我们不仅要定位出车辆的bounding box我们还要识别出bounding box里面的物体就是车辆。对于bounding box的定位精度,有一个很重要的概念,因为我们算法不可能百分百跟人工标注的数据完全匹配,因此就存在一个定位精度评价公式: IOU,IOU定义了两个bounding box的重叠度。

所以计算公式: I O U = A ∩ B A ∪ B IOU= \frac{A∩B}{A∪B} IOU=A∪BA∩B
- FPS:Frames Per second,指画面每秒传输帧数,通俗来讲就是指动画或视频的画面数。FPS是测量用于保存、显示动态视频的信息数量。每秒钟帧数愈多,所显示的动作就会越流畅。
- PR曲线: PR曲线的横轴是Recall,纵轴是PrecisionPrecision-recall曲线反映了分类器对正例的识别准确程度和对正例的覆盖能力之间的权衡
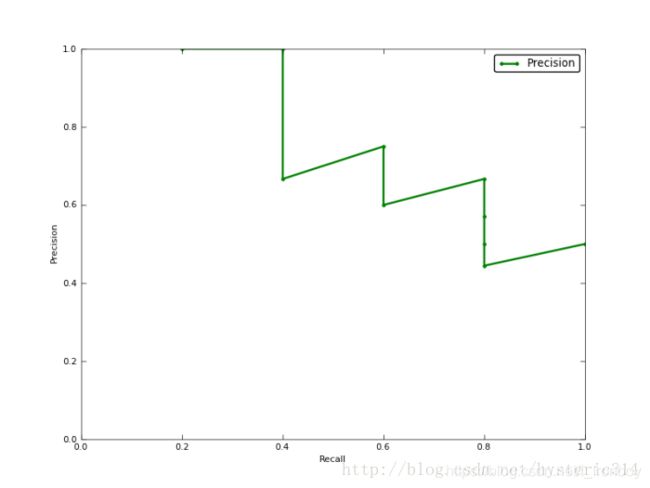
怎么画一个PR曲线呢?按照1、2、3、4…M的数量截取Bounding Box,计算每次截取后的recall和precision,这样得到M个recall和precision点,便画出PR曲线了。
- AP:即Average Precision,AP就是PR曲线与X轴围成的图形面积,对于连续的PR曲线有 A P = ∫ 0 1 P R d r AP=\int_{0}^{1}PRdr AP=∫01PRdr,对于离散的PR曲线,有 A P = ∑ k = 1 M P ( k ) △ r ( k ) AP=\sum_{k=1}^{M}P(k)\triangle r(k) AP=∑k=1MP(k)△r(k)
- mAP:即Mean Average Precision,AP衡量的是学出来的模型在每个类别上的好坏,mAP衡量的是学出的模型在所有类别上的好坏,得到AP后mAP的计算就变得很简单了,就是取所有AP的平均值,有 m A P = ∑ i = 1 Q A P ( i ) Q mAP=\frac{\sum_{i=1}^{Q}AP(i)}{Q} mAP=Q∑i=1QAP(i)
2.3 相关比赛介绍
1. ILSVRC
ILSVRC全称是ImageNet Large Scale Visual Recognition Challenge ,这是ImageNet的图像识别竞赛。竞赛的一个主要目的是通过利用大量的人工标记训练数据,刺激研究者们来比较他们的算法在多种多样的物体检测上的效果。另一个主要目的是检验计算机视觉技术在大尺度图像的检索和标注方面的进步。参赛流程就是先设计模型,然后在标注好的训练集上训练模型参数,然后拿到测试集上去测试,看谁的分类错误率的低的比赛。众多知名的经典网络结构都在该竞赛中崭露头角。比如AlexNet,VGG,GoogleNet,Deep Residual Network等等。该竞赛自2010年举办以来,由于深度学习技术的日益发展,使得机器视觉在ILSVRC的比赛成绩屡创佳绩,其错误率已经低于人类视觉,若再继续举办类似比赛已无意义,2017年已是最后一届举办。

2. PASCAL VOC
PASCAL VOC(Pattern,Analysis,Statistical modelling and Computational learning Visual Object Classes)主要包含两个主要部分:(1)一个公开可用的数据集,包含ground truth annotaion和标准化的评估软件;(2)每年一届的比赛和研讨会。PASCAL VOC挑战赛是计算机视觉目标检测的经典权威赛事,其数据集标注质量高、场景复杂、目标多样、检测难度大,是快速检验算法有效性的首选。在计算视觉领域,Pascal VOC挑战赛与ImageNet同为世界顶级的比赛,是国内外AI公司竞相展开激烈竞争的主赛场。
PASCAL VOC的数据集包括20个类别:人类,动物(鸟、猫、牛、狗、马、羊),交通工具(飞机、自行车、船、公共汽车、小轿车、摩托车、火车),室内物体(瓶子、椅子、餐桌、盆栽植物、沙发、电视)。该竞赛的持续时间是2005-2012,至于目前还有某某机构或单位在国际PASCAL VOC竞赛中获得佳绩的新闻流出尚不明确是怎么个具体情况,但是PASCAL VOC的数据集仍然在被很多研究机构用来训练和测试却是事实。

3. The KITTI Vision Benchmark
KITTI由德国卡尔斯鲁厄理工学院和丰田美国技术研究院联合创办,是目前国际上最大的自动驾驶场景下的计算机视觉算法评测数据集。用于评测目标(机动车、非机动车、行人等)检测、目标跟踪、路面分割等计算机视觉技术在车载环境下的性能。KITTI包含市区、乡村和高速公路等场景采集的真实图像数据,每张图像中多达15辆车和30个行人,还有各种程度的遮挡。
KITTI数据集中,目标检测包括了车辆检测、行人检测、自行车等三个单项,目标追踪包括车辆追踪、行人追踪等两个单项,道路分割包括urban unmarked、urban marked、urban multiple marked三个场景及前三个场景的平均值urban road等四个单项。
严格的说The KITTI Vision Benchmark并不是一项国际竞赛,但是由于它会实时刷新最新的测评成绩,所以很多研究机构,尤其是自动驾驶方面的AI公司会在这个榜单上一争高下,由此也推动了计算机视觉在自动驾驶领域的发展。

4. COCO
MS COCO 的全称是常见物体图像识别(Microsoft Common Objects in Context),起源是微软于2014年出资标注的Microsoft COCO数据集(http://cocodataset.org/ ) 在这个数据集上,共有物体检测 (Detection)、人体关键点检测 (Keypoints)、图像分割 (Stuff)、图像描述生成 (Captions) 四个类别的比赛任务。由于这些视觉任务是计算机视觉领域当前最受关注和最有代表性的,所以该竞赛与此前著名的 ImageNet 竞赛一样,被视为是计算机视觉领域最受关注和最权威的比赛之一。而在ImageNet竞赛停办后,COCO竞赛就成为是当前物体识别、检测等领域的一个最权威、最重要的标杆,也是目前该领域在国际上唯一能汇集Google、微软、Facebook 以及国内外众多顶尖院校和优秀创新企业共同参与的大赛。

5. Google AI Open Images-Object Detection Track
不久之前,Google AI在Kaggle上推出了一项名为Open Images Challenge的大规模目标检测竞赛。到目前为止,COCO检测挑战一直是目标检测的重要挑战之一。但是,与ImageNet相比,它规模较小。COCO只有80个类别和330K图像。它并不能达到人们在现实世界中那么复杂的场景想要实现的目标。从业者往往也会发现在自然环境下目标检测会变得极具挑战性。相比而言,ImageNet至少有着足够大的数据集和足够多的类,它对于预训练和使用网络进行迁移学习都非常有用。也许在足够大的数据集上,训练得到的目标检测器在迁移学习时会同样有着足够好表现。Google AI已公开发布了Open Images数据集v4版本。kaggle上由Google AI发起的比赛的数据集就是基于这个数据集,但又不是完全相同的。另外,Open Images同样遵循着PASCAL VOC,ImageNet和COCO的传统,而且规模空前。
2.4 相关数据集介绍
1. ImageNet
ImageNet项目是一个用于视觉对象识别软件研究的大型可视化数据库。超过1400万的图像URL被ImageNet手动注释,以指示图片中的对象;在至少一百万个图像中,还提供了边界框。ImageNet包含2万多个类别; 一个典型的类别,如“气球”或“草莓”,包含数百个图像。第三方图像URL的注释数据库可以直接从ImageNet免费获得;但是,实际的图像不属于ImageNet。2012年在解决ImageNet挑战方面取得了巨大的突破,被广泛认为是2010年的深度学习革命的开始。
Imagenet数据集有1400多万幅图片,涵盖2万多个类别;其中有超过百万的图片有明确的类别标注和图像中物体位置的标注,具体信息如下:
- Total number of non-empty synsets: 21841
- Total number of images: 14,197,122
- Number of images with bounding box annotations: 1,034,908
- Number of synsets with SIFT features: 1000
- Number of images with SIFT features: 1.2 million
Imagenet数据集是目前深度学习图像领域应用得非常多的一个领域,关于图像分类、定位、检测等研究工作大多基于此数据集展开。Imagenet数据集文档详细,有专门的团队维护,使用非常方便,在计算机视觉领域研究论文中应用非常广,几乎成为了目前深度学习图像领域算法性能检验的“标准”数据集。
数据集大小:~1TB(ILSVRC2016比赛全部数据)
下载地址:http://www.image-net.org/about-stats
2. PASCAL VOC
PASCAL VOC为图像识别和分类提供了一整套标准化的优秀的数据集,从2005年到2012年每年都会举行一场图像识别challenge。该挑战的主要目的是识别真实场景中一些类别的物体。在该挑战中,这是一个监督学习的问题,训练集以带标签的图片的形式给出。这些物体包括20类:
- Person: person;
- Animal: bird, cat, cow, dog, horse, sheep;
- Vehicle: aeroplane, bicycle, boat, bus,car, motorbike, train;
- Indoor: bottle, chair, dining table, pottedplant, sofa, tv/monitor;

下载地址:http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
3. KITTI
KITTI包含市区、乡村和高速公路等场景采集的真实图像数据,每张图像中最多达15辆车和30个行人,还有各种程度的遮挡与截断。整个数据集由389对立体图像和光流图,39.2 km视觉测距序列以及超过200k 3D标注物体的图像组成,以10Hz的频率采样及同步。总体上看,原始数据集被分类为’Road’, ’City’, ’Residential’, ’Campus’ 和 ’Person’。对于3D物体检测,label细分为car, van, truck, pedestrian, pedestrian(sitting), cyclist, tram以及misc组成。KITTI数据采集平台包括2个灰度摄像机,2个彩色摄像机,一个Velodyne 3D激光雷达,4个光学镜头,以及1个GPS导航系统。

下载地址:http://www.cvlibs.net/datasets/kitti/eval_object.php
4. COCO
COCO数据集是微软团队获取的一个可以用来图像recognition+segmentation+captioning 数据集,该数据集主要有的特点如下:
(1) Object segmentation;
(2) Recognition in Context;
(3) Multiple objects per image;
(4) More than 300,000 images;
(5) More than 2 Million instances;
(6) 80 object categories;
(7) 5 captions per image;
(8) Keypoints on 100,000 people
为了更好的介绍这个数据集,微软在ECCV Workshops里发表这篇文章:Microsoft COCO: Common Objects in Context。从这篇文章中,我们了解了这个数据集以scene understanding为目标,主要从复杂的日常场景中截取,图像中的目标通过精确的segmentation进行位置的标定。图像包括91类目标,328,000影像和2,500,000个label。

下载地址:http://cocodataset.org/#download
由于该综述较长,所以分几篇博客连载:
【下一篇】目标检测与识别算法综述:从传统算法到深度学习(二)
该篇的参考文献
【1】 HOU_JUN, 1_目标检测与识别的发展与现状
【2】 zhihua_oba, 机器学习常见评价指标
【3】 Amor_tila, 【RCNN系列】【超详细解析】
【4】蓝鲸王子, Precision/Recall、ROC/AUC、AP/MAP等概念区分
【5】Tensorflowai, Google AI推出新的大规模目标检测挑战赛
【6】ImageNet百度百科
【7】girafffeee, PASCAL VOC数据集分析