【YOLOV4】(7) 特征提取网络代码复现(CSPDarknet53+SPP+PANet+Head),附Tensorflow完整代码
各位同学好,今天和大家分享一下如何使用 TensorFlow 构建YOLOV4目标检测算法的特征提取网络。
完整代码在我的Gitee中,有需要的自取:https://gitee.com/dgvv4/yolo-target-detection/tree/master
1. CSPDarkNet53
CSPDarkNet53 骨干特征提取网络在 YOLOV3 的 DarkNet53网络 的基础上引入了 CSP结构。该结构增强了卷积神经网络的学习能力;移除了计算瓶颈;降低了显存的使用;加快了网络的推理速度。
CSP结构图如下。图像输入经过一个3*3卷积的下采样层;然后输出特征图经过1*1卷积分为两路分支,且卷积后的特征图的通道数为输入特征图通道数的一半。主干部分再通过1*1卷积调整通道数,经过若干个残差卷积块之后,再使用1*1卷积整合通道特征。最后将残差边和1*1卷积输出特征图在通道维度上堆叠,再经过1*1卷积融合通道信息。

模型的骨干就是由多个CSP结构组合而成,但是第一个CSP结构和其他的CSP结构不相同。以输入图像的shape为 [416,416,3] 为例。有如下两点不同:第一个CSP结构是先经过一个标准卷积块下采样,然后经过3*3卷积提取特征,不改变通道数64;在主干卷积分支的残差块,先1*1卷积下降通道数32,再3*3卷积上升通道数64。

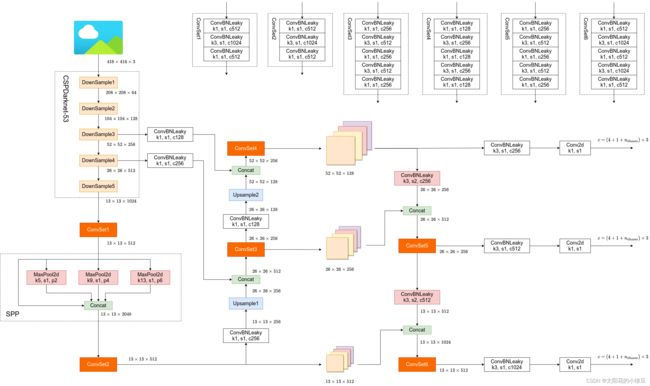
输入图像的shape为[416.416,3],网络不断进行下采样来获得更高的语义信息,输出三个有效特征层,feat1的shape为 [52,52,256] 负责预测小目标,feat2的shape为[26,26,512] 负责预测中等目标,feat3的shape为[13,13,1024] 负责预测大目标

代码展示:
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, regularizers
#(1)Mish激活函数
def mish(x):
# x*tanh(ln(1+ex))
x = x * tf.math.tanh(tf.math.softplus(x))
return x
#(2)标准卷积块
def conv_block(inputs, filters, kernel_size, strides):
# 卷积+BN+Mish
x = layers.Conv2D(filters, kernel_size, strides,
padding='same', use_bias=False, # 有BN不要偏置
kernel_regularizer=regularizers.l2(5e-4))(inputs) # l2正则化
x = layers.BatchNormalization()(x)
x = mish(x)
return x
#(3)残差块
def res_block(inputs, filters):
residual = inputs # 残差边
# 1*1卷积调整通道
x = conv_block(inputs, filters, kernel_size=(1,1), strides=1)
# 3*3卷积提取特征
x = conv_block(x, filters, kernel_size=(3,3), strides=1)
# 残差连接输入和输出
x = layers.Add()([x, residual])
return x
#(4)CSP结构
def csp_bolck(inputs, filters, num):
# 卷积下采样
x = conv_block(inputs, filters, kernel_size=(3,3), strides=2)
# 1*1卷积在通道维度上下降一半
shortcut = conv_block(x, filters//2, (1,1), strides=1) # 残差边
mainconv = conv_block(x, filters//2, (1,1), strides=1) # 主干卷积
# 重复执行残差结构
for _ in range(num):
mainconv = res_block(inputs=mainconv, filters=filters//2)
# 1*1卷积调整通道
mainconv = conv_block(mainconv, filters//2, (1,1), strides=1)
# 输入和输出在通道维度堆叠
x = layers.concatenate([mainconv, shortcut])
# 1*1卷积整合通道
x = conv_block(x, filters, (1,1), strides=1)
return x
#(5)主干网络
def cspdarknet(inputs):
# [416,416,3]==>[416,416,32]
x = conv_block(inputs, filters=32, kernel_size=(3,3), strides=1)
# [416,416,32]==>[208,208,64]
x = csp_bolck(x, filters=64, num=1)
# [208,208,64]==>[104,104,128]
x = csp_bolck(x, filters=128, num=2)
# [104,104,128]==>[52,52,256]
x = csp_bolck(x, filters=256, num=8)
feat1 = x
# [52,52,256]==>[26,26,512]
x = csp_bolck(x, filters=512, num=8)
feat2 = x
# [26,26,512]==>[13,13,1024]
x = csp_bolck(x, filters=1024, num=4)
feat3 = x
return feat1, feat2, feat32. SPP
SPP加强特征提取结构能在一定程度上解决多尺度的问题。如下图
对网络模型输出的 feat3 先经过三个卷积层调整通道数,然后分别使用池化核size为 5*5,9*9,13*13 的最大池化,通过padding='same' 使得池化前后的特征图的shape是完全相同的。然后将原始输入和三种池化的结果特征图在通道维度上堆叠。最后经过三次卷积融合通道信息。

代码展示
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from CSPDarknet53 import cspdarknet # 导入网络模型
from CSPDarknet53 import conv_block # 导入标准卷积块
def spp(inputs):
# 获取网络的三个输出特征层
feat1, feat2, feat3 = cspdarknet(inputs)
# 对最后一个输出特征层进行3次卷积
# [13,13,1024]==>[13,13,512]
p5 = conv_block(feat3, filters=512, kernel_size=(1,1), strides=1)
# [13,13,512]==>[13,13,1024]
p5 = conv_block(p5, filters=1024, kernel_size=(3,3), strides=1)
# [13,13,1024]==>[13,13,512]
p5 = conv_block(p5, filters=512, kernel_size=(1,1), strides=1)
# 经过不同尺度的最大池化后相堆叠
maxpool1 = layers.MaxPooling2D(pool_size=(13,13), strides=1, padding='same')(p5)
maxpool2 = layers.MaxPooling2D(pool_size=(9,9), strides=1, padding='same')(p5)
maxpool3 = layers.MaxPooling2D(pool_size=(5,5), strides=1, padding='same')(p5)
# 四种尺度在通道维度上堆叠[13,13,2048]
p5 = layers.concatenate([maxpool1, maxpool2, maxpool3, p5])
# 三次卷积调整通道数
# [13,13,2048]==>[13,13,512]
p5 = conv_block(p5, filters=512, kernel_size=(1,1), strides=1)
# [13,13,512]==>[13,13,1024]
p5 = conv_block(p5, filters=1024, kernel_size=(3,3), strides=1)
# [13,13,1024]==>[13,13,512]
p5 = conv_block(p5, filters=512, kernel_size=(1,1), strides=1)
return feat1, feat2, p53. PANet
PANet 将网络输出的有效特征层和SPP结构的输出进行特征融合,它是由两个特征金字塔组成,一个是将低层的语义信息向高层融合(左),另一个是将高层的语义信息向低层融合(右)。

首先,对SPP结构的输出p5进行卷积和上采样,对网络输出的26*26*512的特征图卷积,将两个结果在通道维度上堆叠,再经过5次卷积,输出特征图shape为26*26*256。然后将结果再进行卷积和上采样,网络输出的52*52*256的特征图经过1*1卷积,两个特征图在通道维度上堆叠。完成左侧特征金字塔的信息融合。同理右侧的特征金字塔。
代码展示
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from CSPDarknet53 import conv_block # 网络模型和标准卷积块
from SPP import spp # 导入spp加强特征提取模块
# 5次卷积操作提取特征减少参数量
def five_conv(x, filters):
x = conv_block(x, filters, (1,1), strides=1)
x = conv_block(x, filters*2, (3,3), strides=1)
x = conv_block(x, filters, (1,1), strides=1)
x = conv_block(x, filters*2, (3,3), strides=1)
x = conv_block(x, filters, (1,1), strides=1)
return x
def panet(inputs):
# 获得网络的三个有效输出特征层
feat1, feat2, p5 = spp(inputs)
#(1)
# 对spp结构的输出进行卷积和上采样
# [13,13,512]==>[13,13,256]==>[26,26,256]
p5_upsample = conv_block(p5, filters=256, kernel_size=(1,1), strides=1)
p5_upsample = layers.UpSampling2D(size=(2,2))(p5_upsample)
# 对feat2特征层卷积后再与p5_upsample堆叠
# [26,26,512]==>[26,26,256]==>[26,26,512]
p4 = conv_block(feat2, filters=256, kernel_size=(1,1), strides=1)
p4 = layers.concatenate([p4, p5_upsample])
# 堆叠后进行5次卷积[26,26,512]==>[26,26,256]
p4 = five_conv(p4, filters=256)
#(2)
# 对p4卷积上采样
# [26,26,256]==>[26,26,512]==>[52,52,512]
p4_upsample = conv_block(p4, filters=128, kernel_size=(1,1), strides=1)
p4_upsample = layers.UpSampling2D(size=(2,2))(p4_upsample)
# feat1层卷积后与p4_upsample堆叠
# [52,52,256]==>[52,52,128]==>[52,52,256]
p3 = conv_block(feat1, filters=128, kernel_size=(1,1), strides=1)
p3 = layers.concatenate([p3, p4_upsample])
# 堆叠后进行5次卷积[52,52,256]==>[52,52,128]
p3 = five_conv(p3, filters=128)
# 存放第一个特征层的输出
p3_output = p3
#(3)
# p3卷积下采样和p4堆叠
# [52,52,128]==>[26,26,256]==>[26,26,512]
p3_downsample = conv_block(p3, filters=256, kernel_size=(3,3), strides=2)
p4 = layers.concatenate([p3_downsample, p4])
# 堆叠后的结果进行5次卷积[26,26,512]==>[26,26,256]
p4 = five_conv(p4, filters=256)
# 存放第二个有效特征层的输出
p4_output = p4
#(4)
# p4卷积下采样和p5堆叠
# [26,26,256]==>[13,13,512]==>[13,13,1024]
p4_downsample = conv_block(p4, filters=512, kernel_size=(3,3), strides=2)
p5 = layers.concatenate([p4_downsample, p5])
# 堆叠后进行5次卷积[13,13,1024]==>[13,13,512]
p5 = five_conv(p5, filters=512)
# 存放第三个有效特征层的输出
p5_output = p5
# 返回输出层结果
return p3_output, p4_output, p5_output
# 验证
if __name__ == '__main__':
inputs = keras.Input(shape=[416,416,3])
p3_output, p4_output, p5_output = panet(inputs)
print('p3.shape:', p3_output.shape, # (None, 52, 52, 128)
'p4.shape:', p4_output.shape, # (None, 26, 26, 256)
'p5.shape:', p5_output.shape) # (None, 13, 13, 512)4. Head
YOLOHead 由一个3*3卷积层和一个1*1卷积层构成,3*3卷积整合之前获得的所有特征信息,1*1卷积获得三个有效特征层的输出结果。
代码如下,其中1*1卷积的通道数为 num_anchors(5+num_classes)。以 输出结果p3_output 为例,shape为 [512,512,num_anchors(5+num_classes)],可理解为,将一张图片划分成 512*512 个网格,当某一个目标物体的中心点落在某网格中,该物体就需要该网格生成的预测框去预测。
每个网格预先设置了 num_anchors=3 个先验框,网络会对这3个先验框的位置进行调整,使其变成最终的预测框。此外,5+num_classes可以理解为4+1+num_classes。其中 4 代表先验框的调整参数(x, y, w, h),调整已经设定好了的框的位置,调整后的结果是最后的预测框;1 代表先验框中是否包含目标物体,值越接近0代表不包含目标物体,越接近1代表包含目标物体;num_classes 代表目标物体的种类,VOC数据集中num_classes=20,它的值是目标物体属于某个类别的条件概率。
# 通过yolohead获得预测结果
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, Model
from PANet import panet # 导入panet加强特征提取方法
from CSPDarknet53 import conv_block # 导入标准卷积快
# 对PANet的特征输出层处理获得最终的预测结果
def yoloHead(inputs, num_anchors, num_classes):
'''
num_anchors每个网格包含先验框的数量, num_classes分类数
num_anchors(5+num_classes)代表: 每个先验框有5+num_classes个参数, 即(x,y,w,h,c)和20个类别的条件概率
每一个特征层的输出代表: 每一个网格上每一个先验框内部是否包含物体, 以及包含物体的种类, 和先验框的调整参数
'''
# 获得三个有效特征层
p3_output, p4_output, p5_output = panet(inputs)
# 3*3卷积[52,52,128]==>[52,52,256]
p3_output = conv_block(p3_output, filters=256, kernel_size=(3,3), strides=1)
# [52,52,256]==>[52,52,num_anchors(5+num_classes)]
p3_output = conv_block(p3_output, filters=num_anchors*(5+num_classes),
kernel_size=(1,1), strides=1)
# [26,26,256]==>[26,26,516]
p4_output = conv_block(p4_output, filters=512, kernel_size=(3,3), strides=1)
# [26,26,512]==>[26,26,num_anchors(5+num_classes)]
p4_output = conv_block(p4_output, filters=num_anchors*(5+num_classes),
kernel_size=(1,1), strides=1)
# [13,13,512]==>[13,13,1024]
p5_output = conv_block(p5_output, filters=1024, kernel_size=(3,3), strides=1)
# [13,13,1024]==>[13,13,num_anchors(5+num_classes)]
p5_output = conv_block(p5_output, filters=num_anchors*(5+num_classes),
kernel_size=(1,1), strides=1)
# 构建模型
model = Model(inputs, [p5_output, p4_output, p3_output])
return model
# 查看模型结构
if __name__ == '__main__':
inputs = keras.Input(shape=[416,416,3]) # 构造输入
# 接收模型,传入先验框数量3,分类数20
model = yoloHead(inputs, num_anchors=3, num_classes=20)
# 网络架构
model.summary()感谢 太阳花的小绿豆 博主的网络结构图