word2vec的简单示例
按步骤进行分析:
第一步:下载数据:
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import tensorflow as tf
import collections
import math
import os
import random
import zipfile
import matplotlib.pyplot as plt
import numpy as np
from six.moves import urllib
from six.moves import xrange
#word2vec是将词转化为词向量
#Step1:Download the data
url='http://mattmahoney.net/dc/'
#下载数据集
def maybe_download(filename,expected_bytes):
'''Download a file if not present ,and make sure it's the right size.'''
if not os.path.exists(filename):
filename,_=urllib.request.urlretrieve(url+filename,filename)
#获取文件相关属性
statinfo=os.stat(filename)
#比对文件的大小是否正确
if statinfo.st_size==expected_bytes:
print("Found and verified",filename)
else:
print(statinfo.st_size)
raise Exception(
'Failed to verify '+filename+'. Can you get to it with a browser?'
)
return filename
filename=maybe_download('text8.zip',31344016)
#Read the data into a list of strings
def read_data(filename):
'''Extract the first file enclosed in a zip file as a list of words'''
with zipfile.ZipFile(filename) as f:
data=tf.compat.as_str(f.read(f.namelist()[0])).split()
return data
#单词表
words=read_data(filename)
#Data size
print('Data size',len(words))我们看看我们下载了个什么东西
我们可以看到,一行,100,000,000的长度,果然占用30mb是有原因的。那我们再看 read_data函数就很好理解了,他就是以空格为分割,将这一长段字符串分割在了一个list里,words就是包含所有单词的list。
第二部分处理数据
#Step 2:Build the dictionary and replace rare words with UNK token.
#只留50000个单词,其他的都归为UNK
vocabulary_size=50000
def build_dataset(word,vocabulary_size):
count=[['UNK',-1]]#表示单词UNK出现的次数是-1,UNK就是 Unknow
#extend 追加一个列表
#Counter用来统计每个单词出现的次数
#most_common返回一个TopN列表,只留50000个单词包括UNK
#例如
#c=Counter('abracadabra')
#c.most_common()=[('a',5),('r',2),('b',2),('c',1),('d',1)]
#c.most_common(3)=[('a',5),('r',2),('b',2)]
#列表里已经有一个UNK了,所以,再统计49999个
count.extend(collections.Counter(words).most_common(vocabulary_size-1))
#生成dictionary,词对应编号,word:id(0-49999)
#词频越高,编号越小
dictionary=dict()
for word,_ in count:
dictionary[word]=len(dictionary)
#data把数据集的词都编号
data=list()
unk_count=0
for word in words:
if word in dictionary:
index=dictionary[word]
else:
index=0#dictionary['UNK']
unk_count+=1
data.append(index)
#记录UNK词的数量
count[0][1]=unk_count
#编号对应的字典
reverse_dictionary=dict(zip(dictionary.values(),dictionary.keys()))
#data是数据集的词的编号(是五万的词之一的话,就是该词在dictionary里的编号,否则就是0,表示UNK
#count里面是前五万个出现次数最多的词
#dictionary五万个词对应的编号
#反过来,编号对应词
return data,count,dictionary,reverse_dictionary
data,count,dictionary,reverse_dictionary=build_dataset(words,vocabulary_size)
del words #Hint to reduce memory
print('Most common words (+UNK)', count[:5])
print('Sample data',data[:10],[reverse_dictionary[i] for i in data[:10]])
data_index=0经过处理后返回四个值data,count,dictionary,reverse_dictionary
count形状:[['UNK', -1], ('x1', y1), ('x2', y2),………………]
dictionary形状:{'UNK': 0, 'b': 1, 'a': 2,………………}
data是将words里面所有单词,只要他们是前50000个单词之一,他们就在dictionary中有记录,只要有记录,就有出现次数,data要做的就是按照words里面词的顺序,记录每个词在dictionary中的次数记录,如果不在里面,就记为0
data:[532,0,12,65,0,………………]
reverse_dictionary就是dictionary的反过来形式:{32132155: 'UNK', 50: 'b', 100: 'a',………………}
下面重点来了,第三步生成用于skip-gram模型的一个批次的数据
data_index=0
#Step 3:Function to generate a training batch for the skip-gram model.
#batch_size 批次大小
#num_skips是生成多少次label
#skip_window:How many words to consider left and right
#下面会调用这个函数,对应参数分别的是 8,2,1
def generate_batch(batch_size,num_skips,skip_window):
global data_index
#assert检查条件,不符合就终止程序
assert batch_size%num_skips==0
assert num_skips<=2*skip_window
batch=np.ndarray(shape=(batch_size),dtype=np.int32)
labels=np.ndarray(shape=(batch_size,1),dtype=np.int32)
span=2*skip_window+1#[skip_window target skip_window]
#定义一个双向队列
buffer=collections.deque(maxlen=span)#固定了长度为3,满员后进队会使得队首自动出队
#0 1 2 3 4 5 6 7 8 9...
# t i
for _ in range(span):
buffer.append(data[data_index])
data_index=(data_index+1)%len(data)
#获取batch和labels
for i in range(batch_size//num_skips):#所以需要assert batch_size%num_skips==0
#target是锁定上下文的词,skip_window是目标词
target=skip_window#target label at the center of the buffer
targets_to_avoid=[skip_window]
#一个batch会处理四个单词,每一个单词会随机决定先去拿左边还是右边,然后下次拿剩下的那个,每个单词
#生成两个batch数据和两个label数据
#循环两次,一个目标单词对应两个上下文单词
for j in range(num_skips):
while target in targets_to_avoid:
#可能先拿到前面的单词也可能先拿到后面的单词
target=random.randint(0,span-1)
#第一次for循环只要取到0或者2就跳出上面这个while循环
#第二次for循环,必须取到第三种数才能跳出上面这个while循环
targets_to_avoid.append(target)
batch[i*num_skips+j]=buffer[skip_window]
labels[i*num_skips+j,0]=buffer[target]
buffer.append(data[data_index])#队首出队,向后移动一位。
data_index=(data_index+1)%len(data)
#回溯3个词,因为执行完一个batch之后, data_index会多往右移动span个位置
#一个批次(batch)处理四个单词,初始时,目标指向1,data_index=3,即下面的情况
#初始时
#0 1 2 3 4 5 6 7 8 9
# i
#第一次循环
# 0 1 2 3 4 5 6 7 8 9
# t i
#四(batch_size//num_skips)个循环后,
# 0 1 2 3 4 5 6 7 8 9
# t i
#所以,下面是修改回溯三个词,使i和t重合
#下一次再调用这个函数,第一个读入buffer的值就是索引4的单词,而第一个处理的单词是索引5,所以第二个批次就是5 6 7 8 牛逼!
data_index=(data_index+len(data)-span)%len(data)
return batch,labels
#打印sample data
batch,labels=generate_batch(batch_size=8,num_skips=2,skip_window=1)
for i in range(8):#打印一个批次的中间词(即目标词)和上下文的词
print(batch[i],reverse_dictionary[batch[i]],'->',labels[i,0],reverse_dictionary[labels[i,0]])是这样的,一个目标词,上下文包含左右两个部分,左边和右边取同样数量的单词作为上下文,而skip_window值的意义就是决定左右各取多少个数量的单词作为上下文,这里我们传入的参数是1,意思就是[skip_window,target,skip_window],我们的目标词就是target。顺便提一句比较基础的知识,skip_gram模型是根据目标词汇预测上下文哦~。
因为skip_window=1,所以我们设置一个2*skip_window+1长度的定长双向队列,如果满了再加入就会队首元素出队。
for _ in range(span):
buffer.append(data[data_index])
data_index=(data_index+1)%len(data)经过上面for循环代码之后,是下面这种情况
#0 1 2 3 4 5 6 7 8 9...
# t i就是已经进队3个,分别是索引0,1,2,目标词汇是索引1,data_index=3
再往下看是一个两层for循环,第一个for循环共batch//num_skips次,然后每次呢都设置target和targets_to_avoid,这两个分别是什么意思呢,往下面看就好了,下面还是一个for循环,循环次数是num_skips次,这个参数的设置要求是<=2*skip_window,也就是说并不一定会左右两边取等量的词,for循环里面还有一个while循环,其实很简单,就是不确定的拿到目标词汇左边或者右边的词,加入到targets_to_avoid里,下一次就不会再循环到这个词了,从而可以生成另一个词,比如说第一次先取到了左边的词,那么下一个有效的取词就是右边的词,如果抽到的还是左边的词那么就会继续while,就是无效的取词。这么做的目的就是达到随机左边或者右边的词,这样就会排除取词顺序对于预测结果的影响。
这样我们就了解了,for循环是取出num_skips个上下文的词,while循环是随即取出一个上下文的词,紧接着跟上对于这个词的操作,batch列表是记录目标词,labels是记录上下文的词,这样的话他们两个的样子就是
batch:['目标词1','目标词1',…………]
label:['目标词1的上下文词1','目标词1的上下文词2',……]
做完一个for+while循环之后(也就是处理完一个目标词和其上下文之后)队首出队,定长队列向后移动一位,同时data_index加1,也就是说,最外层for循环共循环了4(batch//num_skips,下面调用传入的参数分别是8,2)次,
第一次处理的时候t=1,i=3;第二次t=2,i=4;第三次t=3,i=5;第四次t=4,i=6;
第一次处理完之后t=2,i=4;第二次t=3,i=5;第三次t=4,i=6;第四次t=5,i=7;
然后立刻让index减去span,就是减去一个跨度,=7-3=4,然后再次调用这个函数的时候
for _ in range(span):
buffer.append(data[data_index])
data_index=(data_index+1)%len(data)初始化的队列就是456,data_index=7,从5开始处理,重复循环。
我们还需要深入理解一下这个函数的三个参数的意思,batch_size,num_skips,skip_window分别对应批次,上下文选词,目标词上文或下文所选词的最大数量。他们之间有怎样的数学关系呢?批次大小也就是说一个批次实际投入的词的数量,比如这里是8,循环完后,t=5,i=7,i最大,对应八个词。num_skips决定了一个目标词生成多少个上下文词,也就是多少个label。最外层的for循环为什么非要循环batch_size//num_skips次呢?当外层for循环结束后,实际上处理的是索引值为1 2 3 4的目标词,就是说循环一次,处理一个词。我们发现了一个关系,如果你要每个目标词的上下文选词为2的话,一个目标词占用两个索引位置,那么8不就相当于事先订好了每个批次就八个索引位置,8/num_skips意思就是:位置只有8个,你决定生成多少个目标词(batch_size//num_skips),并决定每个目标词占用多少索引(即确定输入参数num_skips的值),所以必须要整除。
这个函数的返回结果是data里面保存的字典中每个单词的编号。
再看第四步:建立并训练模型以及session操作
graph=tf.Graph()
with graph.as_default():
#Input data
train_inputs=tf.placeholder(tf.int32,shape=[batch_size])#一个批次的数据的编号
train_labels=tf.placeholder(tf.int32,shape=[batch_size,1])#[128,1]
#验证集
valid_dataset=tf.constant(valid_examples,dtype=tf.int32)
embeddings=tf.Variable(
tf.random_uniform([vocabulary_size,embedding_size],-1.0,1.0))#50000*128的矩阵,值在-1到1之间均匀分布
#embedding_lookup(params,ids)其实就是按照ids顺序返回params中的第ids行
#比如说,ids=[1,7,4]就是返回params中第1,7,4行,返回结果为params的1,7,4行组成的tensor
#提取要训练的词 并不是五万个词都训练一起 下面就是从所有词中抽取我们要训练的
embed=tf.nn.embedding_lookup(embeddings,train_inputs)#([50000,128],[128])返回一个[128,128]的矩阵
nce_weights=tf.Variable(
tf.truncated_normal([vocabulary_size,embedding_size],#从截断的正态分布中输出随机值。[50000,128],标准差=1.0/math.sqrt(embedding_size)
stddev=1.0/math.sqrt(embedding_size)))
nce_biases=tf.Variable(tf.zeros([vocabulary_size]))#[50000]
#已经封装好了 噪声对比估计
loss=tf.reduce_mean(
tf.nn.nce_loss(weights=nce_weights,#一个Tensor,shape为[num_classes, dim],或者是Tensor对象列表,其沿着维度0的连接具有shape [num_classes,dim].(可能是分区的)类嵌入.
biases=nce_biases,#一个Tensor,shape为[num_classes].类偏差.
labels=train_labels,#一个Tensor,类型为int64和shape [batch_size, num_true].目标类.
inputs=embed,#一个Tensor,shape [batch_size, dim].输入网络的正向激活.
num_sampled=num_sampled,#采样出多少个负样本
num_classes=vocabulary_size)#可能的类数
)
#随机梯度下降法
optimizer=tf.train.GradientDescentOptimizer(1).minimize(loss)
#正则化
norm=tf.sqrt(tf.reduce_sum(tf.square(embeddings),1,keep_dims=True))
# 调用reduce_sum(arg1, arg2)
# 时,参数arg1即为要求和的数据,arg2有两个取值分别为0和1,通常用reduction_indices = [0]
# 或reduction_indices = [1]
# 来传递参数。从上图可以看出,当arg2 = 0
# 时,是纵向对矩阵求和,原来矩阵有几列就得到几个值;相似地,当arg2 = 1
# 时,是横向对矩阵求和;当省略arg2参数时,默认对矩阵所有元素进行求和。
# ————————————————
# 版权声明:本文为CSDN博主「Maples丶丶」的原创文章,遵循CC
# 4.0
# by - sa版权协议,转载请附上原文出处链接及本声明。
# 原文链接:https: // blog.csdn.net / qq_16137569 / article / details / 72568793
# 计算输入tensor元素的和,或者安照reduction_indices指定的轴进行求和
# # ‘x’ is [[1, 1, 1]
# # [1, 1, 1]]
# tf.reduce_sum(x, 1) == > [3, 3]
# tf.reduce_sum(x, 1, keep_dims=True) == > [[3], [3]]
# ————————————————
# 版权声明:本文为CSDN博主「林海山波」的原创文章,遵循CC
# 4.0
# by - sa版权协议,转载请附上原文出处链接及本声明。
# 原文链接:https: // blog.csdn.net / lenbow / article / details / 52152766
#正则化之后的矩阵
normalized_embeddings=embeddings/norm
#抽取一些常用词来测试余弦相似度
valid_embeddings=tf.nn.embedding_lookup(
normalized_embeddings,valid_dataset)#[16,128]从5w行中随机抽16行,行标在100以内
#余弦相似度
similarity=tf.matmul(
valid_embeddings,normalized_embeddings,transpose_b=True)#transpose_b=True对第二个矩阵进行转置,变为[16,128]*[128,50000]
init=tf.global_variables_initializer()
#Step5
num_steps=100001
final_embeddings=[]
with tf.Session(graph=graph) as session:
init.run()
print("Initialized")
average_loss=0
for step in xrange(num_steps):
#获取一个批次的target,以及对应的labels,都是编号形式
batch_inputs,batch_labels=generate_batch(
batch_size,num_skips,skip_window)#128,2,1
feed_dict={train_inputs:batch_inputs,train_labels:batch_labels}
_,loss_val=session.run([optimizer,loss],feed_dict=feed_dict)
average_loss+=loss_val
#计算训练2000次的平均loss
if step%2000==0:
if step>0:
average_loss /=2000
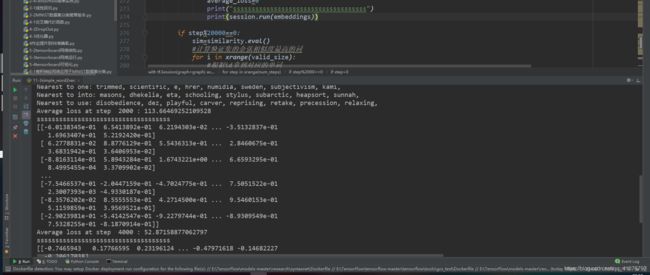
print("Average loss at step ",step,":",average_loss)
average_loss=0
if step%20000==0:
sim=similarity.eval()
#计算验证集的余弦相似度最高的词
for i in xrange(valid_size):
#根据id拿到对应的单词
valid_word=reverse_dictionary[valid_examples[i]]
top_k=8
#从大到小排序,排除自己本身,取前top_k个值
nearest=(-sim[i,:]).argsort()[1:top_k+1]
log_str="Nearest to %s:"%valid_word
for k in xrange(top_k):
close_word=reverse_dictionary[nearest[k]]
log_str="%s %s,"%(log_str,close_word)
print(log_str)
#训练结束得到的词向量
final_embeddings=normalized_embeddings.eval()
#step 6 Visualize the embeddings.
#将词向量降维然后画出来
def plot_with_labels(low_dim_embs,labels,filename='tsne.png'):
assert low_dim_embs.shape[0]>=len(labels),"More labels than embeddings"
#设置图片大小
plt.figure(figsize=(15,15))
for i,label in enumerate(labels):
x,y=low_dim_embs[i,:]
plt.scatter(x,y)
plt.annotate(label,
xy=(x,y),
xytext=(5,2),
textcoords='offset points',
ha='right',
va='bottom')
plt.savefig(filename)
try:
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
tsne=TSNE(perplexity=30,n_components=2,init='pca',n_iter=5000,method='exact')
plot_only=500
low_dim_embs=tsne.fit_transform(final_embeddings[:plot_only,:])
labels=[reverse_dictionary[i] for i in xrange(plot_only)]
plot_with_labels(low_dim_embs,labels)
except ImportError:
print("Please install sklearn,matplotlib,and scipy to visualize embeddings.")我们从session开始看起,num_steps是迭代周期,十万次,每次获取一个批次的target和label,就是第三步的返回结果,即返回目标词的编号以及其上下文的编号。这两个作为传入的train_inputs和train_labels参数。然后我们看看做了什么。
tf.nn.nce_loss是用来计算并返回噪声对比估计(NCE, Noise Contrastive Estimation)训练损失.这个函数需要很多参数,其中weights,和biases分别采用了截断正态分布和零值进行初始化的。labels将第三阶段返回的labels传入,inputs则是通过将一个均匀分布的[50000,128]的矩阵提取了小于128行(因为train_inputs也就是第三步分会的target中可能会有重复的数字,因为他们可能都是0,就是在data生成的时候,data判定如果这个单词不是属于50000个最频繁的单词之一,则标记为0),返回了一个[128,128]的矩阵(行之间可能重复,因为0的存在)。
然后用随机梯度下降法最小化这个损失值,然后正则化(方便后面计算余弦相似度,直接使用矩阵乘积即可,因为除数已经被归一化了),计算余弦相似度,后面的都很简单了。最终我们可以得到50000个词中任意一个词的与之余弦相似度接近的其他词。
我其实一直有一个疑问,
embeddings=tf.Variable(
tf.random_uniform([vocabulary_size,embedding_size],-1.0,1.0))#50000*128的矩阵,值在-1到1之间均匀分布最终的词向量与embeddings有关,可是他只是一个均匀分布初始化的矩阵,为什么会与词向量有关,不应该是embed更靠谱嘛,后来自我思考感觉应该是在训练的过程中这个包含5w词向量的值会不断的变化来使得loss降低吧。
于是我检验了一下,确实是这样的