win10使用 yolov5 第二弹!如何成功训练自己的数据集!(roboflow、W&B、labelImg)
刚开始学习使用yolov5的朋友,除了完成我上一篇博文cuda\anaconda\pytorch等环境搭建以外,我们的第一步还没有结束。
这篇博文将继续带着大家逐步探索学习yolov5的历程!
参照官方给出的训练数据集的教程:官方教程
(由于是全英文的,还有许多跳转,部分同学可能看起来比较费劲,我自己也看了好久才理清楚的,所以这里出一个中文版教程,帮助理解)
创建环境:
由于我上一篇博客中python安装的版本是3.9,在prompt中,
conda activate yolov5 //激活环境,每次都要激活
你可以去github上下载yolov5项目https://github.com/ultralytics/yolov5,这是经过大数据训练的成熟模型,我们需要完成的项目只需要在这个基础上进行改进就可以了。
安装pycharm,直接去pycharm官网下载,一路默认安装就好了。
============================================================================
接下来,将带着大家一起开始第一个数据集训练!
创建自定义模型来检测您的对象是一个迭代过程,包括收集和组织图像、标记您感兴趣的对象、训练模型、将其部署到野外进行预测,然后使用该部署的模型收集边缘案例的示例以重复和改进。
创建数据集
YOLOv5 模型必须在标记数据上进行训练,才能学习该数据中的对象类别。在开始训练之前创建数据集有两种选择:
1、roboflow: 一种网页版的图形编辑工具,能够以 YOLOv5 的注释格式导出它们。
如果你是第一次用这个网页,会有引导,记住顺序,一步步标记好自己的数据集。
我这里简单写一个教程:
创建新项目—》
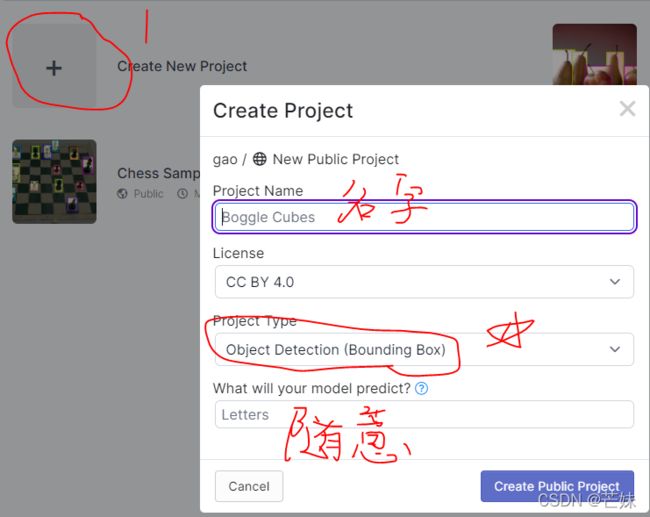
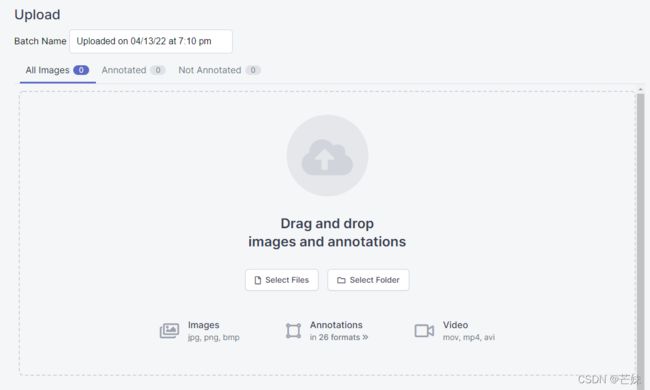
将图片拖到这个框里面,点击右上角上传
点击右边,开始对图片进行标记
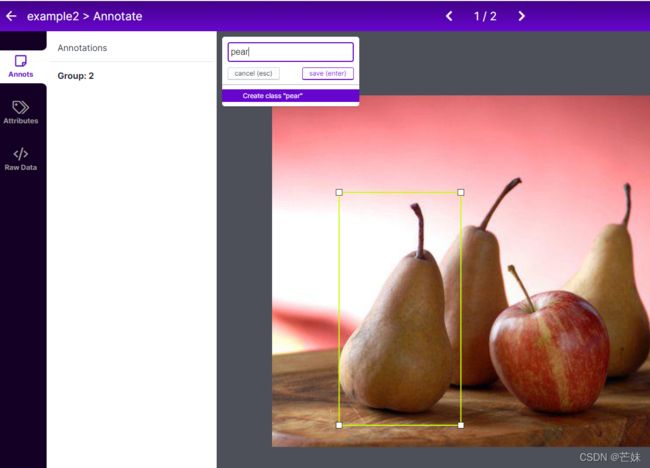
像这样逐个标记好,注意:一张图必须一次性标记好,如果想单独吧梨标记好了再回来标记苹果,你会发现,已经没有勾选框了,你根本就无法再标记了。
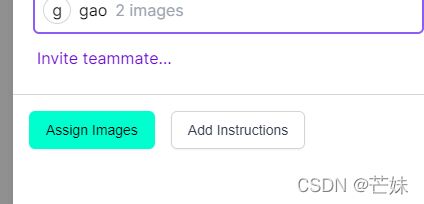
点击右上角,add XX picture to dataset,出现选择框,要选择将其中多少作为训练集,那些作为测试集,那些作为验证集。这个按照自己的需要选择。弄好之后,点击add picture
双击进入刚才标记的图片集,把这几个都选好,generate


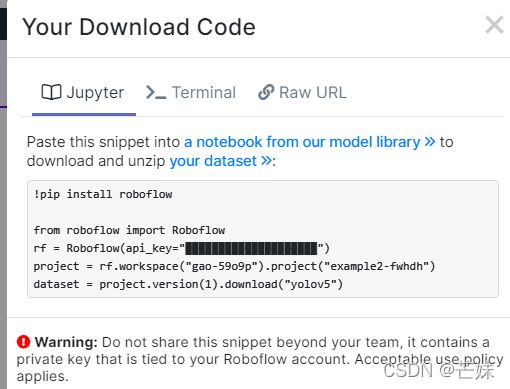
将这一串代码复制下来,便于到时候调出刚才标记的数据集。
到这里数据集的标记工作就已经完成了,但我们经常需要用到的数据集可能是成千上万张图片,所以这个过程是极其费时间的。网上有许多别人已经标记好的数据集。在这里列举几个,有需要的可以去看看。
用于图像识别的数以百万计的图像:
ImageNet:“http://www.image-net.org”; Place: " http://places.csail.mit.edu/downloadData.html"
用于语音识别的上千小时的数据集:
http://www.openslr.org/resources.php
2、安装labelimg图形处理软件

每次在下面这个路径下输入python labelImg.py就能打开了(记住路径)
![]()
操作起来也不困难。
可视化的界面最终直接把图片存在文件夹里,比roboflow可视化强很多。
这个软件也是用来标记数据集的,和roboflow二选一即可.
必须要做的!
到weight&biases官网上注册自己的账号,因为后面在ptycharm中运行代码时,会自动从这个网站上下载.pt模型的权重文件,到时候会需要 API 码。
训练自己的数据集
其实,我们从github上下载的代码就是直接可以运行的,里面有两张命名如下的图片,打开detect.py程序,右键,run ,就能看到结果。结果保存在runs–>detect–>exp中
![]()
如果要训练自己的数据集该怎么做呢?
首先将划分好的数据集分为训练集+验证集合+测试集合.;利用labelimg工具完成数据集的划分,记住yolov5数据集需要.txt文件,里面包含目标框中心点 长宽信息。(有的目标检测算法包含图片本身大小这些辅助信息),如果不是,可用python代码进行格式转换。
直接将划分好的数据集,替换yolo_master中的coco2018数据集就行。