数据结构 第四章 串
目录
4.1 串的定义
4.2 案例引入
4.3 串的类型定义、存储结构及其运算
4.3.1 串的抽象类型定义
4.3.2 串的存储结构
1.串的顺序存储结构
2.串的链式存储
4.3.3 串的模式匹配算法
1.BF算法(Brute-Force)
2.KMP算法
3.NEXT数组
计算机上的非数值处理的对象大部分是字符串数据,字符串一般简称为串。串是一种特殊的线性表,其特殊性在于数据元素是一个字符,也就是说,串是一种内容受限的线性表。
4.1 串的定义
串(string)(或字符串)是由零个或多个字符组成的有限序列。例如s="darling"就一个字符串。其中s是串的名,用双引号括起来的是串的值,其值可以是字母、数字或其他字符,而空格也可作为一个元素出现在字符串的中间,但" "不是空字符。一般地,用“ ”来表示空串。拥有零个字符的串称为空串(null string)。
”来表示空串。拥有零个字符的串称为空串(null string)。
串中任意个连续的字符组成的子序列称为该串的子串。包含字串的串相应地称为主串。例如,a="rli"就是上述字符串s="darling"的一个字串。通常称字符在序列中的序号为该字符在串中的位置。字串在主串中的位置则以字串的第一个字符在主串中的位置来表示。例如,a在s中的位置为3(一个串的起始位置为1)。
若两个串中每个对应位置的值都相等,则称这两个串相等。
4.2 案例引入
字符串在实际中有极为广泛的应用,在文字编辑、信息检索、语言编译等软件系统中字符串均是重要的操作对象;在网络入侵、计算机病毒特征码匹配以及DNA序列匹配等应用中,都需要进行串匹配,也称模式匹配。
案例4.1:病毒感染检测
医学研究者最近发现了某些新病毒,通过对这些病毒的分析,得知它们的DNA序列都是环状的。现在研究者已收集了大量的病毒DNA和人的DNA数据,想快速检测出这些人是否感染了相应的病毒。为了方便研究,研究者将人的DNA和病毒DNA均表示成由一些字母组成的字符串序列,然后检测某种病毒DNA序列是否在患者的DNA序列中出现过,如果出现过,则此人感染了该病毒,否则没有感染。例如,假设病毒的DNA序列为baa,患者1的DNA序列为aaabbba,则患者1感染,患者2的DNA序列为babbba,则患者2未感染。(注意,人的DNA序列是线性的,而病毒的DNA序列是环状的)。
如果我们要在程序设计语言中使用串这个结构,那么我们也需像前面的线性表、栈和队列那样对其进行抽象类型定义。
4.3 串的类型定义、存储结构及其运算
4.3.1 串的抽象类型定义
4.3.2 串的存储结构
串有两种存储结构:顺序存储和链式存储。但考虑到存储效率和算法的方便性,串多采用顺序存储结构。在下面两种存储结构的介绍中,我们可以比较两者的差距到底在哪。
1.串的顺序存储结构
类似于线性表的顺序存储结构,用一组地址连续的存储单元存储串值的字符序列。按照预定义的大小,为每个定义的串变量分配一个固定长度的存储区,则可用定长数组作如下描述:
#define MAXLEN 255
typedef struct
{
char ch[MAXLEN+1]; //存储串的一维数组
int length; //串的当前长度
}SString;为了便于说明问题,本章后面算法描述当中所用到的顺序存储的字符串都是从下标1的数组分量开始存储的,下标为0的分量闲置不用。
上面这种定义方式是静态的,在编译时刻就确定了串空间的大小。而多数情况下,串的操作是以串的整体形式参与的,串变量之间的长度相差较大,在操作中串值长度的变化也较大,这样为串变量设定固定大小的空间不尽合理。因此最好是根据实际需要,在程序执行过程中动态地分配和释放字符数组空间。在C语言中, 存在一个称为“堆”(Heap)的自由存储区,可以为每个新产生的串动态分配一块实际串长所需的存储空间,若分配成功,则返回一个指向起始地址的指针,作为串的基址,同时为了以后处理方便,约定串长也作为存储结构的一部分。这种字符串的存储方式也成为串的堆式顺序存储结构。对于此,我们可作如下定义:
typedef struct
{
char *ch;
int length;
}HString; 对于给字符串变量分配空间,我们可以使用malloc函数动态分配,所需头文件为
2.串的链式存储
如果我们用顺序存储结构来存储串的话,当我们需要插入或删除元素时不方便,需要移动大量的字符。对此,我们可采用单链表方式存储串。由于串结构的特殊性——结构中的每个数据元素是一个字符,也可以存放多个字符。例如下图(a)所示为结点大小为4(即每个结点存放4个字符)的链表,下图(b)所示为结点大小为1的链表。当结点大小大于1时,由于串长不一定是结点大小的整倍数,则链表中的最后一个结点不一定全被串值占满,此时通常补上“#”或其它的非串值字符(通常“#”不属于串的字符集,是一个特殊符号)。
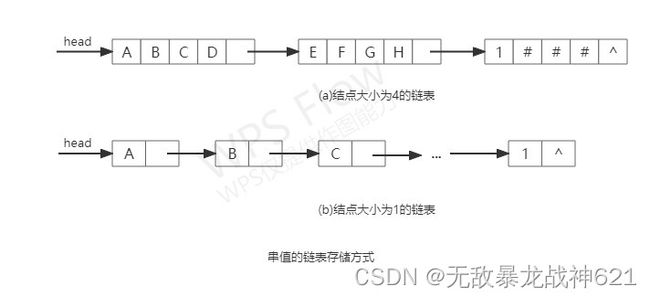
为了便于进行串的操作,当以链表存储串值时,除头指针外,还可附设要给尾指针指示链表中的最后一个结点,并给出当前串的长度。称如此定义的串存储结构为块链结构,说明如下:
#define CHUNKSIZE 80 //定义的块的大小
typedef struct Chunk
{
char ch[CHUNKSIZE];
struct Chunk *next;
}Chunk;
typedef struct
{
Chunk *head,*tail;
int length;
}LString;在链式存储方式中,结点大小的选择直接影响着串的处理效率。在各种串的处理系统中,所处理的串往往很长或很多,如一本书的几百万个字符,情报资料的成千上万个条目,这就要求考虑串值的存储密度(即一个结点存储几个字符)。
显然,存储密度小(如结点大小为1时),运算处理方便,但存储量大。如果在串处理过程中需进行内、外存交换的话,则会因为内、 外存交换操作过多而影响处理的总效率。应该看到,串的字符集的大小也是一个重要因素。一般来说,字符集小,则字符的机内编码就短,这也影响串值存储方式的选取。
串值的链式存储结构对某些串操作,如联接操作等,有一定方便之处,但总的来说,不如顺序存储结构灵活,它占用存储量大且操作复杂。
4.3.3 串的模式匹配算法
字串的定位运算通常称为串的模式匹配或串匹配。此运算的应用非常广泛,比如在搜索引擎、拼写检查、语言翻译、数据压缩等应用中,都需要进行串匹配。
串的模式匹配设有两个字符串S和T,设S为主串,也称正文串;设T为子串,也称模式。在主串S中查找与T相匹配的子串,如果匹配成功,确定相匹配的字串中的第一个字符在主串S中出现的位置。
著名的模式匹配算法有BF算法和KMP算法。
1.BF算法(Brute-Force)
Brute意为野蛮的,Force意为蛮力,也就是说,BF算法是一种比较简单粗暴的算法。
算法4.1 BF算法
【算法分析】
如下图,假设我们在序号表里想要查找某个特定的序列号,但是一般我们是不是在输入时不会将要查的序列号全部输入,通常只输入开头或中间连续的一部分,就有我们想要的查找结果了。这就是串的模式匹配算法的用处。例如:
若要查找子串T在主串S中的位置,则先将T中第一个字符与S中第一个字符进行比较,若相等,则将两个串的下一个字符进行比较;若不相等,则子串中的第一个字符又重新与主串中第二个字符比较,再依次往下比较。需要注意的是,每次匹配不相等,都只能从主串第一次比较的字符的下一个字符开始。(注意:第一次比较不一定要从主串的第一个字符开始,也可以从其他字符开始,但是每一次不匹配都只能从开始字符的下一个字符继续)。
于是,BF算法的时间复杂度就相对来说要高一些,这也就是BF算法的“简单粗暴”之处。
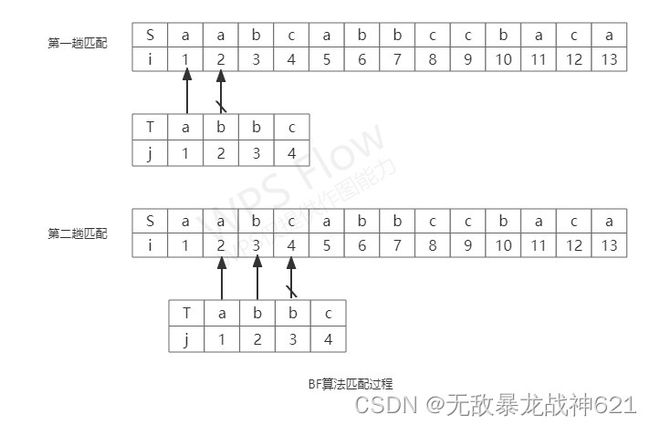
【算法步骤】
1)分别利用计数指针i和j指示主串S和模式T中当前正待比较的字符位置,i初值为pos,j初值为j。
2)如果两个串均为比较到串尾,即i和j均分别小于S和T的长度时,则循环执行以下操作:
 S.ch[i]和T.ch[j]比较,若相等,则i和j分别指示串中下个位置,继续比较后续字符。
S.ch[i]和T.ch[j]比较,若相等,则i和j分别指示串中下个位置,继续比较后续字符。
若不等,指针后退重新开始匹配,从主串的下一个字符起再重新和模式的第一个字符比较。
3)当j>T.length,说明模式T中的每个字符依次和主串S中的一个连续的字符序列相等,则匹配成功,返回模式T在主串S中的位置;否则称匹配不成功,返回0。
【算法描述】
int Index_BF(SString S,SString T,int pos)
{
i=pos;
j=1;
while(i<=S.length&&j<=T.length)
{
if(S.ch[i]=T.ch[j])
{
++i;
++j;
}
else
{
i=i-j+2;
j=1;
}
if(j>T.length)
return i-T.length;
else
return 0;
}2.KMP算法
KMP算法是由Knuth、Morris和Pratt同时设计实现的,因此简称KMP算法。KMP算法是比BF算法时间复杂度更小的一种算法。那么它相较于BF算法更优的地方在哪里,又该如何实现呢?下面我们先举几个例子来简单引入KMP算法。
需要注意的是,KMP算法的问题由模式串决定,不由目标串决定。
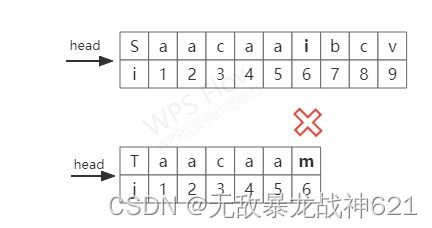
我们先给出KMP算法的第一种情况:
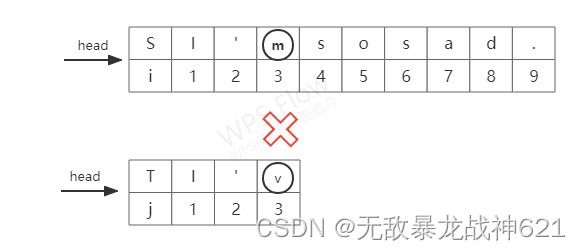
从上图中我们可以得知,在i=3、j=3时失配,按BF算法来讲的话,我们需要从i=2开始回溯。但我们可以通过图中发现,![]() ,那么必然有
,那么必然有![]() ,则我们不必从i=2开始回溯,直接从i=3开始新一轮的匹配。这就是KMP算法相对于BF算法的优点处。下面我们继续给出KMP算法的第二种情况:
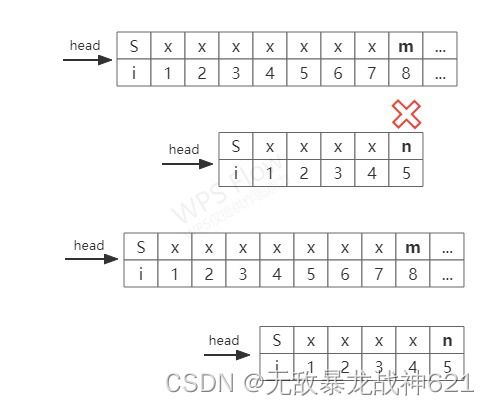
,则我们不必从i=2开始回溯,直接从i=3开始新一轮的匹配。这就是KMP算法相对于BF算法的优点处。下面我们继续给出KMP算法的第二种情况:
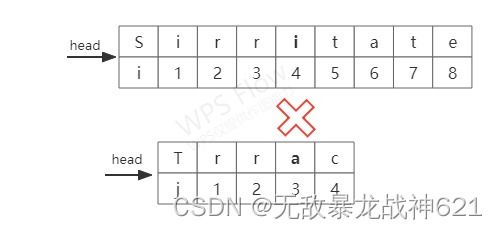
从图中我们可以看到,在i=4、j=3处失配,且![]() ,如果按第一种情况,我们将在i=4处重新开始匹配,但我们发现
,如果按第一种情况,我们将在i=4处重新开始匹配,但我们发现![]() ,于是有可能从i=3处开始能匹配成功,如果按照第一种情况直接跳到i=4,那么我们就有可能错过正确的匹配位置。因此,在遇到模式串中有连续重复字符时,我们又要用另一种方式来选择重新匹配的位置。
,于是有可能从i=3处开始能匹配成功,如果按照第一种情况直接跳到i=4,那么我们就有可能错过正确的匹配位置。因此,在遇到模式串中有连续重复字符时,我们又要用另一种方式来选择重新匹配的位置。
第三种情况:
由图我们可以得知,在i=6、j=6处失配,但我们可以发现![]() ,这时我们就可以从i=4重新开始匹配。
,这时我们就可以从i=4重新开始匹配。
第四种情况:
由图知,在i=8、j=5时失配,这时因为不知道i=9...时的字符是什么,所以将模式串整体向后移。
通过上述KMP算法的四种例子,我们可以知道KMP算法在面对不同模式串时有不同的解决办法。上述四个例子是四种特殊的情况,而在面对一般情况时,我们可以给模式串引入一个k数组,也就是KMP算法中非常著名的NEXT数组。
3.NEXT数组
NEXT的作用:当模式匹配串T失配的时候,NEXT数组对应的元素指导应该用T串的哪个元素进行下一轮的匹配。
对于NEXT数组,我们只需考虑模式匹配串T即可。但我们需要引入前缀(j)和后缀(i)的概念,下面我们将给出一个例子来理解NEXT数组的作用。
前缀:从T串中第一个字符到后缀前某个字符。
后缀:从T串失配处前面的某个字符到T串失配前的一个字符。
| S | a | b | a | b | a | a | a | b | a |
| 下标 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| NEXT[] | 0 | 1 | 1 | 2 | 3 | 4 | 2 | 2 | 3 |
假设我们在下标为4处失配:此时前缀为a,后缀为a,所以我们应在下标为4处的NEXT[]中填入2;若我们在下标为5处失配,此时前缀为ab,后缀为ab,所以我们应在下标为5处的NEXT[]中填入3;若我们在下标为6处失配,此时前缀为aba,后缀为aba,所以我们应在下标为6处的NEXT[]中填入4;若我们在下标为7处失配,此时前缀为a,后缀为a,所以我们应在下标为7处的NEXT[]中填入2;若我们在下标为8处失配,此时前缀为a,后缀为a,所以我们应在下标为8处的NEXT[]中填入2;若我们在下标为9处失配,此时前缀为ab,后缀为ab,所以我们应在下标为9处的NEXT[]中填入3。
我们在返回到下标为1处,对于下标为1的NEXT[],我们一直都是填0;而对于下标为2处的NEXT[],因为其前面没有可匹配的,所以填1;对于下标为3处,此时前缀为a,后缀为b,所以我们在下标为3处的NEXT[]中填2。
由上我们可以发现一个规律:在失配处,NEXT[]的值应等于前缀和后缀相同字符的个数加1。
下面我们将采用上述的第三种情况的例子来说明NEXT[]数组的应用,如下图:
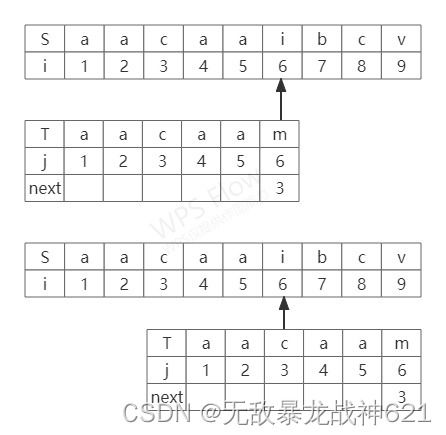
当我们在下标为6处失配时,前缀为aa,后缀为aa,所以我们应在下标为6处的NEXT[]中填入3。当重新开始匹配时,我们就只需要将模式串T下标为3处在S串中失配处开始重新匹配(看到这里需要重新回过头去看一下NEXT数组的作用)。
关于NEXT数组,我们理解起来是一回事,但是用代码写出来又是另一回事。那么,我们该如何利用代码实现NEXT数组呢?下面我们将一步一步设计该代码的实现。
【NEXT数组算法分析】
首先我们通过上述例子可以发现,在给失配处的NEXT[]赋值时,需要判断前缀和后缀是否相等,在这里我们就可以用if条件来判断,若相等,则在if条件的内部进行赋值。需要注意的是,前缀和后缀并不是单独的两个字符,有可能是多个字符。因为前缀总是从下标为1处开始的(特殊情况从下标为0开始),所以前缀是固定的,后缀是相对的。因此,在前缀和后缀第一次相等后,我们需要判断当前缀和后缀的后续字符是否相等,所以在if语句内部就会有i++;j++。
接着就是若不等,我们又该如何操作呢?根据if语句,如果不等,应接着写一个else语句用来应对不相等的情况。若不相等,则有j=next[j]。由于描述比较困难,读者可以自己举例子来理解。
NEXT数组的主体部分已经实现,因为我们需要循环去判断,所以在if语句外层嵌套一个while循环语句。
最后我们就需要设定i和j的初值,但它们的初值不可能一开始就相同吧,那样的话它们所指字符就会一直相等。所以j的初值为0,i的初值为1。但这样处理又有一个问题,在字符串中我们通常从下标为1开始,而下标为0处用来存放字符串的长度。所以我们又需要在if条件中增加一个判断:若j=0...。至此,NEXT数组大致结构已经描述完成,下面给出其代码实现。
【NEXT数组代码实现】
void get_next(SString T,int next[])
{
j=0;
i=1;
next[1]=0;
while(i因为NEXT数组只于模式匹配串T有关,不需考虑主串S,所以我们在用KMP算法时应调用get_next函数给模式匹配串一个NEXT数组。当模式匹配串有对应NEXT数组时,我们就可以实现KMP算法了。
【KMP算法分析】
首先我们要明确该算法的目的:我们是为了查找模式串T在主串S中的位置。所以必须在主串中找到与模式串一样的连续字符序列。所以我们就要将模式串的每一个字符与主串的一段连续字符序列进行比较,第一个字符相等后两串就要向后移。所以主体结构是一个while循环语句,在循环语句内用if条件语句判断字符是否相等,若相等,则后移;若不等,则利用NEXT数组指导T串该用哪一个元素进行下一轮的匹配。且while循环的前提是两串均为比较到串尾。因为j是T串的下标,若while循环结束后j大于T串的长度,则匹配成功,否则匹配失败。下面我们给出KMP算法的代码实现。
【KMP算法代码实现】
int Index_KMP(SString S,SString T,int pos)
{
i=pos; //1<=i<=S.length
j=1;
while(i<=S.length && j<=T.length)
{
if(T[j] == S[i])
{
i++;
j++;
}
else
j=next[j];
}
if(j>T.length)
return i-T.length;
else
return 0;
}
} 但是呢,都说人无完人,金无赤足嘛,一个再好的算法也总会有那么一些确定,一个好的算法就是不断改进中提升的。就比如说上面这个KMP算法,若其主串和模式串是如下图所示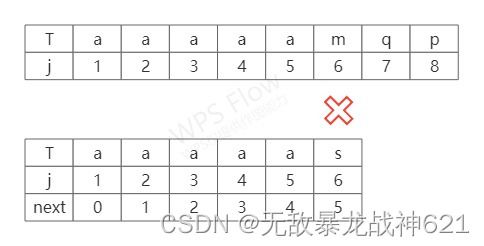
由图可知,如用上述KMP算法,我们在i=6、j=6处失配,随后根据NEXT数组的值进行重新匹配。但我们发现j=6前面的字符都相等,就算根据NEXT数组进行重新匹配,也会大大地浪费时间,对于此种情况我们可以做相应的改进。
改进后的KMP算法当遇见连续相同字符序列的情况时就不会做多做无意义的比较,时间复杂度更小。
void get_next(SString T,int next[])
{
j=0;
i=1;
next[1]=0;
while( i总结:我们先来谈谈BF算法和KMP算法的区别。若从主串S的同一处开始匹配,BF相当于是按“顺序”将所有可能的匹配都遍历一次,直到匹配成功;而KMP中多了一个NEXT数组,相当于在失配的时候我们可以利用NEXT数组跳过那些没有意义的匹配。对于存储性能来说,KMP算法相较于BF算法多了一个数组的存储空间,但是对于较长的串的匹配的时候,KMP算法的时间复杂度相较于BF算法是大大减小了的。因此,只有在面对串非常小的匹配情况时,用BF算法可能较优,具体情况还需判断。
下面我们再来谈一谈串的模式匹配算法到底有什么用?在开头我们提出了可以在医学方面利用串的模式匹配来检测一个人的DNA里是否含有病毒的基因序列进而判断该人是否患病。
串的模式匹配就相当于是一个检索的过程,但这个检索是用“部分”在“整体”里检索。例如,在大学的一个网上活动中,我们需要知道参与者是哪一届的学生,这时我们就用4个字符的T串(代表年份)在所有参与者的学号里去匹配,进而得出我们想要的结果。