【Python】数据分析和机器学习高频使用代码集锦!
作者:Peter 编辑:Peter
本文记录的是个人高频使用的数据分析和机器学习代码片段,包含的主要内容:
pandas设置
可视化
jieba分词
缺失值处理
特征分布
数据归一化
上下采样
回归与分类模型
模型评价等

常用库
import numpy as np
import pandas as pd
pd.set_option( 'display.precision',6) # 小数精度6位
pd.set_option("display.max_rows",999) # 最多显示行数
pd.reset_option("display.max_rows") # 重置
pd.set_option('display.max_columns',100) # 最多显示列100
pd.set_option('display.max_columns',None) # 显示全部列
pd.set_option ('display.max_colwidth', 100) # 列宽
pd.reset_option('display.max_columns') # 重置
pd.set_option("expand_frame_repr", True) # 折叠
pd.set_option('display.float_format', '{:,.2f}'.format) # 千分位
pd.set_option('display.float_format', '{:.2f}%'.format) # 百分比形式
pd.set_option('display.float_format', '{:.2f}¥'.format) # 特殊符号
pd.options.plotting.backend = "plotly" # 修改绘图
pd.set_option("colheader_justify","left") # 列字段对齐方式
pd.reset_option('all') # 全部功能重置
# 忽略notebook中的警告
import warnings
warnings.filterwarnings("ignore")可视化
# 1、基于plotly
import plotly as py
import plotly.express as px
import plotly.graph_objects as go
py.offline.init_notebook_mode(connected = True)
from plotly.subplots import make_subplots # 多子图
# 2、基于matplotlib
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
%matplotlib inline
# 中文显示问题
plt.rcParams["font.sans-serif"]=["SimHei"] #设置字体
plt.rcParams["axes.unicode_minus"]=False #正常显示负号
# 3、基于seaborn
import seaborn as sns
# plt.style.use("fivethirtyeight")
plt.style.use('ggplot')
# 4、基于Pyecharts
from pyecharts.globals import CurrentConfig, OnlineHostType
from pyecharts import options as opts # 配置项
from pyecharts.charts import Bar, Pie, Line, HeatMap, Funnel, WordCloud, Grid, Page # 各个图形的类
from pyecharts.commons.utils import JsCode
from pyecharts.globals import ThemeType,SymbolType1、柱状图带显示数值:
fig = px.bar(df4, x="name",y="成绩",text="成绩")
fig.update_traces(textposition="outside")
fig.update_layout(xaxis_tickangle=45) # 倾斜角度设置
fig.show()2、饼图带显示类型名称:
fig = px.pie(df, # 以城市和数量为字段
names="城市",
values="数量"
)
fig.update_traces(
textposition='inside',
textinfo='percent+label'
)
fig.update_layout(
title={
"text":"城市占比",
"y":0.96, # y轴数值
"x":0.5, # x轴数值
"xanchor":"center", # x、y轴相对位置
"yanchor":"top"
}
)
fig.show()3、seaborn箱型图
# 方式1
ax = sns.boxplot(y=df["total_bill"])
# 方式2:传入y和data参数
ax = sns.boxplot(y="total_bill", data=df)4、plotly子图绘制,假设是28个图,生成7*4的子图:

jieba分词与词云图
import jieba
title_list = df["title"].tolist()
# 分词过程
title_jieba_list = []
for i in range(len(title_list)):
# jieba分词
seg_list = jieba.cut(str(title_list[i]).strip(), cut_all=False)
for each in list(seg_list):
title_jieba_list.append(each)
# 创建停用词list
def StopWords(filepath):
stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()]
return stopwords
# 传入停用词表的路径:路径需要修改
stopwords = StopWords("/Users/Desktop/spider/nlp_stopwords.txt")
# 收集有用词语
useful_result = []
for col in title_jieba_list:
if col not in stopwords:
useful_result.append(col)
information = pd.value_counts(useful_result).reset_index()
information.columns=["word","number"]
# 词云图
information_zip = [tuple(z) for z in zip(information_new["word"].tolist(), information_new["number"].tolist())]
# 绘图
c = (
WordCloud()
.add("", information_zip word_size_range=[20, 80], shape=SymbolType.DIAMOND)
.set_global_opts(title_opts=opts.TitleOpts(title="词云图"))
)
c.render_notebook()数据探索
import pandas as pd
df = pd.read_csv("data.csv")
df.shape # 数据形状
df.isnull().sum() # 缺失值
df.dtypes # 字段类型
df.describe # 描述统计信息缺失字段可视化
import missingno as mso
mso.bar(df,color="blue")
plt.show()删除字段
# 删除某个非必须属性
df.drop('Name', axis=1, inplace=True)缺失值填充
以字段的现有数据中位数进行填充为例:
# transform之前要指定操作的列(Age),它只能对某个列进行操作
df['Age'].fillna(train.groupby('Title')['Age'].transform("median"), inplace=True)字段位置重置
# 1、单独提出来
scaled_amount = df['amount']
# 2、删除原字段信息
df.drop(['amount'], axis=1, inplace=True)
# 3、插入
df.insert(0, 'amount', scaled_amount)数据集划分
from sklearn.model_selection import train_test_split
from sklearn.model_selection import StratifiedShuffleSplit
X = df.drop("Class", axis=1) # 特征
y = df["Class"] # 标签
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.2,random_state=44)
# 3、将数据转成数组,然后传给模型
X_train = X_train.values
X_test = X_test.values
y_train = y_train.values
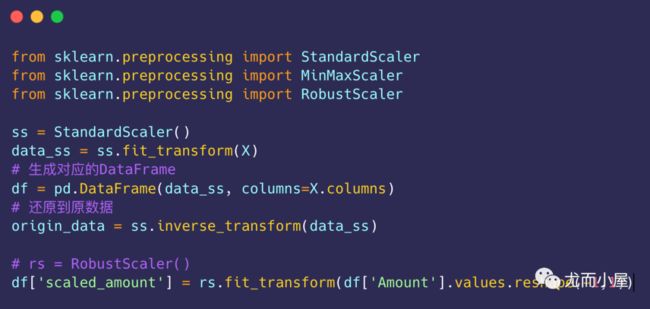
y_test = y_test.values数据标准化/归一化
基于numpy来实现
# 基于numpy实现
mean = X_train.mean(axis=0)
X_train -= mean
std = X_train.std(axis=0)
X_train /= std
# 测试集:使用训练集的均值和标准差来归一化
X_test -= mean
X_test /= std基于sklearn实现
相关性热力图
f, ax1 = plt.subplots(1,1,figsize=(24, 20))
corr = df.corr()
sns.heatmap(corr, cmap="coolwarm_r",annot_kws={"size":20})
ax.set_title("Correlation Matrix", fontsize=14)属性间相关性
cols = ["col1", "col2", "col3"]
plt.figure(1,figsize=(15,6))
n = 0
for x in cols:
for y in cols:
n += 1 # 每循环一次n增加,子图移动一次
plt.subplot(3,3,n) # 3*3的矩阵,第n个图形
plt.subplots_adjust(hspace=0.5, wspace=0.5) # 子图间的宽、高参数
sns.regplot(x=x,y=y,data=df,color="#AE213D") # 绘图的数据和颜色
plt.ylabel(y.split()[0] + " " + y.split()[1] if len(y.split()) > 1 else y)
plt.show()删除离群点
删除基于上下四分位的离群点:
# 数组
v12 = df["V12"].loc[df["Class"] == 1]
# 25%和75%分位数
q1, q3 = v12.quantile(0.25), v12.quantile(0.75)
iqr = q3 - q1
# 确定上下限
v12_cut_off = iqr * 1.5
v12_lower = q1 - v12_cut_off
v12_upper = q3 + v12_cut_off
# 确定离群点
outliers = [x for x in v12 if x < v12_lower or x > v12_upper]
# 技巧:如何删除异常值
new_df = df.drop(df[(df["V12"] > v12_upper) | (df["V12"] < v12_lower)].index)离群点填充均值
df['Price']=np.where(df['Price']>=40000, # 大于等于40000看成异常值
df['Price'].median(), # 替换均值
df['Price']) # 替换字段特征分布
1、特征取值数量统计
df["Class"].value_counts(normalize=True)plt.figure(1, figsize=(12,5))
sns.countplot(y="sex", data=df)
plt.show()2、基于seaborn绘图
# 绘图
colors = ["red", "blue"]
sns.countplot("Class", data=df, palette=colors)
plt.title("0-No Fraud & 1-Fraud)")
plt.show()3、特征直方图分布

效果:

另一种方法:
# 绘图
plt.figure(1,figsize=(15,6))
n = 0
for col in cols:
n += 1 # 子图位置
plt.subplot(1,3,n)
plt.subplots_adjust(hspace=0.5,wspace=0.5) # 调整宽高
sns.distplot(df[col],bins=20) # 绘制直方图
plt.title(f'Distplot of {col}')
plt.show() # 显示图形特征重要性
from sklearn.feature_selection import mutual_info_classif
imp = pd.DataFrame(mutual_info_classif(X,y),
index=X.columns)
imp.columns=['importance']
imp.sort_values(by='importance',ascending=False)2种编码
Nominal data -- Data that are not in any order -->one hot encoding
ordinal data -- Data are in order --> labelEncoder标称数据:没有任何顺序,使用独热编码oneot encoding
有序数据:存在一定的顺序,使用类型编码labelEncoder
独热码的实现:
df["sex"] = pd.get_dummies(df["sex"])基于有序数据的类型编码自定义:
dic = {"v1":1, "v2":2, "v3":3, "v4":4}
df["class"] = df["class"].map(dic)sklearn实现类型编码:
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
for i in ['Route1', 'Route2', 'Route3', 'Route4', 'Route5']:
categorical[i]=le.fit_transform(categorical[i])上、下采样
上采样
# 使用imlbearn库中上采样方法中的SMOTE接口
from imblearn.over_sampling import SMOTE
# 设置随机数种子
smo = SMOTE(random_state=42)
X_smo, y_smo = smo.fit_resample(X, y)下采样
# 欺诈的数据
fraud_df = df[df["Class"] == 1] # 少量数据
# 从非欺诈的数据中取出相同的长度len(fraud_df)
no_fraud_df = df[df["Class"] == 0][:len(fraud_df)]
# 组合
normal_distributed_df = pd.concat([fraud_df, no_fraud_df])
# 随机打乱数据
new_df = normal_distributed_df.sample(frac=1, random_state=123)PCA降维
from sklearn.manifold import TSNE
from sklearn.decomposition import PCA, TruncatedSVD
# PCA降维
X_reduced_pca = PCA(n_components=2,
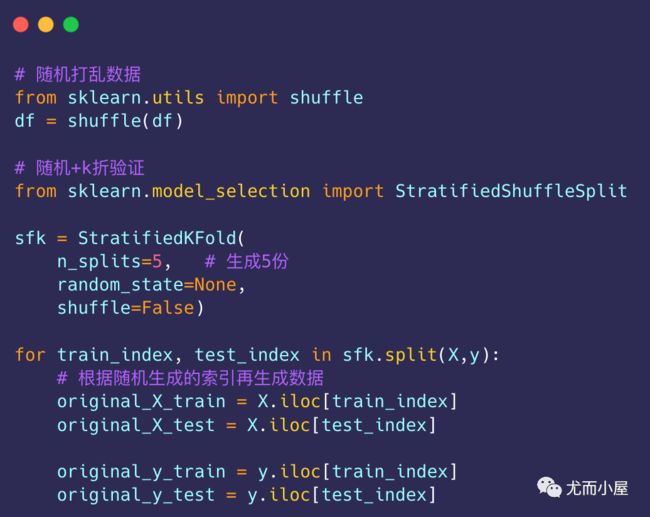
random_state=42).fit_transform(X.values)sklearn使用k折交叉验证
随机打乱数据并生成索引:
Keras使用交叉验证
Keras中的k折交叉验证:

回归模型

回归模型评分
from sklearn.metrics import r2_score,mean_absolute_error,mean_squared_error
def predict(ml_model):
print("Model is: ", ml_model)
model = ml_model.fit(X_train, y_train)
print("Training score: ", model.score(X_train,y_train))
predictions = model.predict(X_test)
print("Predictions: ", predictions)
print('-----------------')
r2score = r2_score(y_test, predictions)
print("r2 score is: ", r2score)
print('MAE:{}', mean_absolute_error(y_test,predictions))
print('MSE:{}', mean_squared_error(y_test,predictions))
print('RMSE:{}', np.sqrt(mean_squared_error(y_test,predictions)))
# 真实值和预测值的差值
sns.distplot(y_test - predictions)分类模型

混淆矩阵
分类任务的混淆矩阵
from sklearn import metrics # 模型评价
confusion_matrix = metrics.confusion_matrix(y_test, y_pred)auc值
auc = metrics.roc_auc_score(y_test, y_pred) # 测试值和预测值ROC曲线
from sklearn.metrics import roc_curve, auc
false_positive_rate, true_positive_rate, thresholds = roc_curve(y_test, y_prob) # y的真实值和预测值
# roc值
roc = auc(false_positive_rate, true_positive_rate)
import matplotlib.pyplot as plt
plt.figure(figsize=(10,10))
plt.title('ROC')
plt.plot(false_positive_rate,true_positive_rate, color='red',label = 'AUC = %0.2f' % roc_auc)
plt.legend(loc = 'lower right')
plt.plot([0, 1], [0, 1],linestyle='--')
plt.axis('tight')
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show()网络搜索
以逻辑回归为例:
from sklearn.model_selection import GridSearchCV
# 逻辑回归
lr_params = {"penalty":["l1", "l2"],
"C": [0.001, 0.01, 0.1, 1, 10, 100, 1000]
}
grid_lr = GridSearchCV(LogisticRegression(), lr_params)
grid_lr.fit(X_train, y_train)
# 最好的参数组合
best_para_lr = grid_lr.best_estimator_随机搜索
以随机森林模型为例为例:
# 采用随机搜索调优
from sklearn.model_selection import RandomizedSearchCV
# 待调优的参数
random_grid = {
'n_estimators' : [100, 120, 150, 180, 200,220],
'max_features':['auto','sqrt'],
'max_depth':[5,10,15,20],
}
# 建模拟合
rf=RandomForestRegressor()
rf_random=RandomizedSearchCV(
estimator=rf,
param_distributions=random_grid,
cv=3,
verbose=2,
n_jobs=-1)
rf_random.fit(X_train,y_train)![]()
推荐阅读
往期精彩回顾
适合初学者入门人工智能的路线及资料下载(图文+视频)机器学习入门系列下载中国大学慕课《机器学习》(黄海广主讲)机器学习及深度学习笔记等资料打印《统计学习方法》的代码复现专辑机器学习交流qq群955171419,加入微信群请扫码: