词频统计报告
时间分配
在做这个项目之前,我预计需要4天的时间,大概是一天用来安装vs2012,两天写程序,一天测试和优化。
实际的完成过程和预计差不多,写程序是不到两天,测试和优化用了近两天的时间。
测试过程
我一共设计了10个测试样例,其中有7个测试样例是扩展模式,3个是普通模式。
里面有5个对正常的输入进行不同模式下词频统计的样例,一个样例针对中文输入统计,两个测试对“单词的判断”,一个测试空文件输入,一个测试单词统计时的大小写不敏感。
在测试的过程中,我改掉了程序中的bug。
在调试的过程中,我了解了map在程序中是如何一步步进行词频统计的。
性能分析
在刚开始进行性能分析时,每次运行就会跳出出错窗口,上面写着:“无法启动wordFreqency.exe,未指定的错误”,然后停止性能分析。感谢@醉歌 的帮助,这个是测试数据太小的缘故,把测试数据加大,就可以正常做性能分析了。
在改需求和优化的过程中,我的程序一共有两个版本,区别主要在最后map的排序上。第一次用了类似冒泡的方法,每次查找最大值输出,第二次改为将map转存到vector中,用sort函数进行排序。
第一版程序的性能分析图:
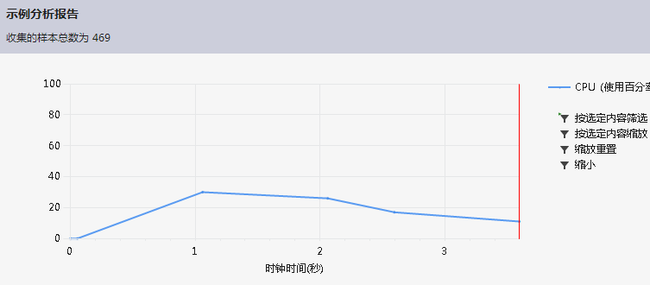
结果显示,运行时间最长的代码为:
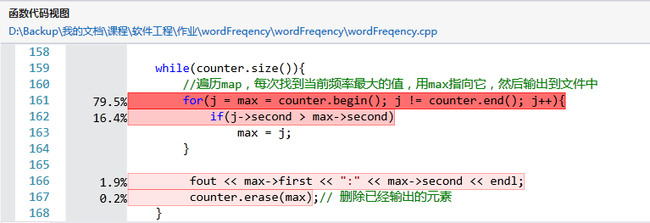
其中,j和max的定义是:
map <string, int> :: iterator j;
map <string, int> :: iterator max;
这段代码的核心功能是对map以value值进行排序。
由于map默认是按照key值排序的,词频统计输出要求按照词频大小输出,所以要对map以value值进行排序。
我在网上查找map以value值排序的方法,大概有两种,第一种是新建一个map,把原来map中的数据的key值和value值互换位置,这样在新的map中就是以原来的value排序的了,但是这个方法在词频统计中并不可行,因为map要求key值是唯一的,而单词频率显然可能重复。另一种方法是把map转存到vector中,再进行排序。在写程序时考虑到这个方法要申请新的空间并且vector的sort方法可能会破坏原来map中按字符串中的字母排好的顺序,所以我选择了手动每次搜索频率最大的元素。不过这个方法的复杂度是O(n2),效率确实比较低。在大数据面前,O(n2)与O(nlogn)的差距十分明显,所以在后来的优化中,我还是选择了第二中把map转存到vector中的方法。
程序优化后的性能分析图:
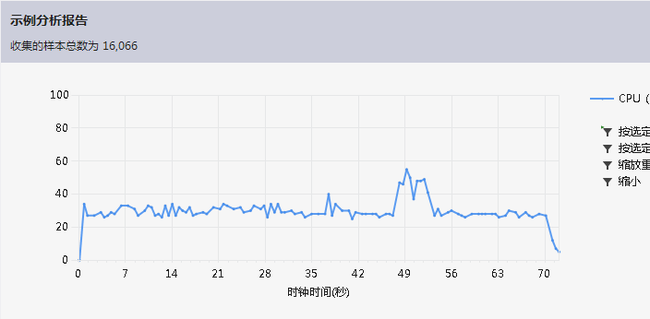
花时间最多的代码部分为:
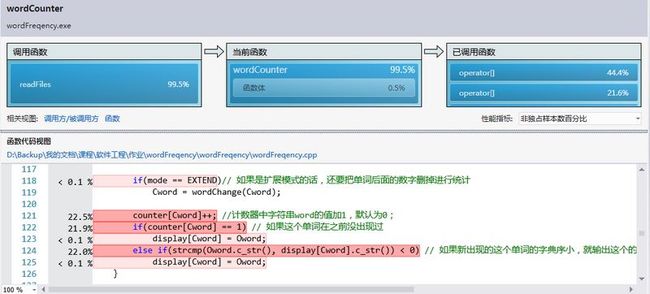
是读入单词时进行统计和处理用的时间最多。这次我真正明白了O(n2)与O(nlogn)的差距,比我最初想象的要大得多。以后在写程序的时候不能为了偷懒儿放弃对程序做优化。
我的收获
通过这个工程,我首先学到了c++中很多STL的用法,map,vector等,尤其是在调试程序的过程中了解了map的工作过程。
此外,用vs2012进行程序性能分析让我很直观的了解到我的程序哪里效率低,哪里需要改进。