Deep Learning × ECG (5) :利用循环神经网络RNN对心律失常ECG数据进行分类
文章目录
- 1. RNN 介绍
- 2. 搭建RNN模型进行训练
1. RNN 介绍
循环神经网络RNN的提出主要针对于时间序列数据。
类似于股票、心律失常 ECG 和 电力数据 等数据都是属于时间序列数据。
RNN模型具有记忆功能。时间序列数据前一时刻的数据可能会影响后一时刻的数据;因此,循环神经网络在时间序列数据上有着较好的性能。
简单地说,循环神经网络目的在于探索序列之间的关系!!!它是根据"人的认知是基于过往的经验和记忆"这一观点提出的。
需要注意的是,该类模型主要处理一维数据。鉴于其记忆功能,能够将前后数据进行关联,因此循环神经网络模型在一维数据的处理上获得了较好的表现。
目前,主流的循环神经网络模型有RNN、LSTM、GRU以及基于它们的改进模型。
本篇文章主要以介绍 RNN 处理心律失常ECG数据为主。

参数解释:
- x t − 1 , x t , x t + 1 x_{t-1}, x_{t}, x_{t+1} xt−1,xt,xt+1 分别表示 t-1, t 和 t+1 时刻的输入
- o t − 1 , o t , o t + 1 o_{t-1}, o_{t}, o_{t+1} ot−1,ot,ot+1 分别表示 t-1, t 和 t+1 时刻的结果
- s t − 1 , s t , s t + 1 s_{t-1}, s_{t}, s_{t+1} st−1,st,st+1 分别表示 t-1, t 和 t+1 时刻的记忆或叫隐藏层
- W W W 表示前一时刻输入的权重, U U U 表示此刻输入的样本的权重, V V V 表示输出的样本权重.
- 在整个网络中, W W W, U U U 和 V V V 是共享的。需要注意的是: V V V 是需要看情况使用的;若搭建网络时需要每一个隐藏层的输出,这种情况下是需要用到 V V V 的;若不需要每一个隐藏层的输出,可以不使用 V V V 。(本篇文章只取最后一个隐藏层的输出,因此用不到 V V V。 )
在实现代码的过程中,可能有部分同学有疑问:整个训练过程只有一个参数矩阵A啊,不是应该有2个参数 W W W, U U U?
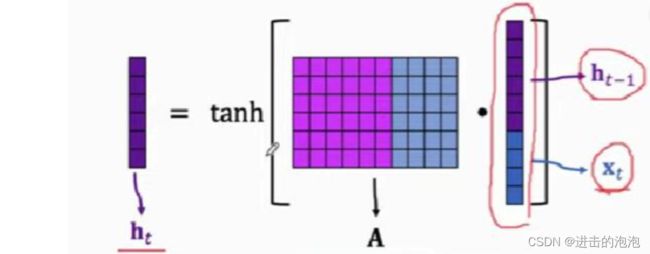
其实很简单,在实现过程中RNN会将上一个状态 s t − 1 s_{t-1} st−1和当前状态的输入 x t x_t xt 进行 connect 操作,如上图;那么 W 和 U便是上图左边矩阵A中的参数;W是A中紫色部分,U是A中蓝色部分。也就是说,在实际操作过程中,将这两个参数合并在一起了。
在本实验中,我们举得例子中 x 大小(每个心拍)为300,隐藏层h的大小是 50;那么根据矩阵的乘法运算,我们可以轻易地得到A的大小是 50 * 350
2. 搭建RNN模型进行训练
关于心律失常ECG数据的相关处理之前都已经介绍过了,这里就不展开介绍了。
实验所用数据集:MIT-BIH Arrhythmia Database
主要有几点区别:
- 本次代码是用 Pytorch 实现的。
- 鉴于目前大多数心律失常分类都是在对N、S、V、F 和 Q 五类进行分类,之前我们是分类N、A、V、L和R五类。本次实验主要是针对 N、S、V、F 和 Q 五类。
直接看代码,相关代码均已在代码中注释。
'''
导入相关包
'''
import wfdb
import pywt
import seaborn
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
import torch
import torch.utils.data as Data
from torch import nn
'''
加载数据集
'''
# 测试集在数据集中所占的比例
RATIO = 0.2
# 小波去噪预处理
def denoise(data):
# 小波变换
coeffs = pywt.wavedec(data=data, wavelet='db5', level=9)
cA9, cD9, cD8, cD7, cD6, cD5, cD4, cD3, cD2, cD1 = coeffs
# 阈值去噪
threshold = (np.median(np.abs(cD1)) / 0.6745) * (np.sqrt(2 * np.log(len(cD1))))
cD1.fill(0)
cD2.fill(0)
for i in range(1, len(coeffs) - 2):
coeffs[i] = pywt.threshold(coeffs[i], threshold)
# 小波反变换,获取去噪后的信号
rdata = pywt.waverec(coeffs=coeffs, wavelet='db5')
return rdata
# 读取心电数据和对应标签,并对数据进行小波去噪
def getDataSet(number, X_data, Y_data):
ecgClassSet = ['N', 'A', 'V', 'L', 'R']
# 读取心电数据记录
# print("正在读取 " + number + " 号心电数据...")
# 读取MLII导联的数据
record = wfdb.rdrecord('./data/MIT-BIH-360/' + number, channel_names=['MLII'])
data = record.p_signal.flatten()
rdata = denoise(data=data)
# 获取心电数据记录中R波的位置和对应的标签
annotation = wfdb.rdann('./data/MIT-BIH-360/' + number, 'atr')
Rlocation = annotation.sample
Rclass = annotation.symbol
# 去掉前后的不稳定数据
start = 10
end = 5
i = start
j = len(annotation.symbol) - end
# 因为只选择NAVLR五种心电类型,所以要选出该条记录中所需要的那些带有特定标签的数据,舍弃其余标签的点
# X_data在R波前后截取长度为300的数据点
# Y_data将NAVLR按顺序转换为01234
while i < j:
try:
# Rclass[i] 是标签
lable = ecgClassSet.index(Rclass[i])
# 基于经验值,基于R峰向前取100个点,向后取200个点
x_train = rdata[Rlocation[i] - 100:Rlocation[i] + 200]
X_data.append(x_train)
Y_data.append(lable)
i += 1
except ValueError:
i += 1
return
# 加载数据集并进行预处理
def loadData():
numberSet = ['100', '101', '103', '105', '106', '107', '108', '109', '111', '112', '113', '114', '115',
'116', '117', '119', '121', '122', '123', '124', '200', '201', '202', '203', '205', '208',
'210', '212', '213', '214', '215', '217', '219', '220', '221', '222', '223', '228', '230',
'231', '232', '233', '234']
dataSet = []
lableSet = []
for n in numberSet:
getDataSet(n, dataSet, lableSet)
# 转numpy数组,打乱顺序
dataSet = np.array(dataSet).reshape(-1, 300)
lableSet = np.array(lableSet).reshape(-1, 1)
train_ds = np.hstack((dataSet, lableSet))
np.random.shuffle(train_ds)
# 数据集及其标签集
X = train_ds[:, :300].reshape(-1, 1,300)
Y = train_ds[:, 300]
# 测试集及其标签集
shuffle_index = np.random.permutation(len(X))
# 设定测试集的大小 RATIO是测试集在数据集中所占的比例
test_length = int(RATIO * len(shuffle_index))
# 测试集的长度
test_index = shuffle_index[:test_length]
# 训练集的长度
train_index = shuffle_index[test_length:]
X_test, Y_test = X[test_index], Y[test_index]
X_train, Y_train = X[train_index], Y[train_index]
return X_train, Y_train, X_test, Y_test
X_train, Y_train, X_test, Y_test = loadData()
'''
数据处理
'''
train_Data = Data.TensorDataset(torch.Tensor(X_train), torch.Tensor(Y_train)) # 返回结果为一个个元组,每一个元组存放数据和标签
train_loader = Data.DataLoader(dataset=train_Data, batch_size=128)
test_Data = Data.TensorDataset(torch.Tensor(X_test), torch.Tensor(Y_test)) # 返回结果为一个个元组,每一个元组存放数据和标签
test_loader = Data.DataLoader(dataset=test_Data, batch_size=128)
'''
模型搭建
'''
class RnnModel(nn.Module):
def __init__(self):
super(RnnModel, self).__init__()
'''
参数解释:(输入维度,隐藏层维度,网络层数)
输入维度:每个x的输入大小,也就是每个x的特征数
隐藏层:隐藏层的层数,若层数为1,隐层只有1层
网络层数:网络层的大小
'''
self.rnn = nn.RNN(300, 50, 3, nonlinearity='tanh')
self.linear = nn.Linear(50, 5)
def forward(self, x):
r_out, h_state = self.rnn(x)
output = self.linear(r_out[:,-1,:])
return output
model = RnnModel()
'''
设置损失函数和参数优化方法
'''
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
'''
模型训练
'''
EPOCHS = 5
for epoch in range(EPOCHS):
running_loss = 0
for i, data in enumerate(train_loader):
inputs, label = data
y_predict = model(inputs)
loss = criterion(y_predict, label.long())
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
# 预测
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
inputs, label = data
y_pred = model(inputs)
_, predicted = torch.max(y_pred.data, dim=1)
total += label.size(0)
correct += (predicted == label).sum().item()
print(f'Epoch: {epoch + 1}, ACC on test: {correct / total}')
分类效果基本上可以达到 98% 左右。