python高级脚本使用及详细介绍,建议收藏
这是本文的标题
- 前言
- 1、Jpg转Png
- 2、PDF加密和解密
- 3、获取电脑的配置信息
- 4、解压文件
- 5、Excel工作表合并
- 6、将图像转换为素描图
- 7、获取CPU温度
- 8、提取PDF表格
- 9、截图
- 10、拼写检查器
- 零基础Python学习指南
-
- Python学习路线汇总
- Python必备开发工具
- Python学习视频600合集
- 实战案例
- 100道Python练习题
- 面试刷题
- 资料领取
前言
在日常的工作中,我们总会面临到各式各样的问题。其中不少的问题,使用一些简单的Python代码就能解决。
比如不久前的复旦大佬,用130行Python代码硬核搞定核酸统计,大大提升了效率,节省了不少时间。
今天,小编就带大家学习一下10个Python脚本程序。虽然简单,不过还是蛮有用的。有兴趣的可以自己去实现,找到对自己有帮助的技巧。
1、Jpg转Png
图片格式转换,以前我们可能第一时间想到的是【格式工厂】这个软件。如今编写一个Python脚本就能完成各种图片格式的转换,此处以jpg转成png为例。有两种解决方法,都分享给大家:
# 图片格式转换, Jpg转Png
# 方法①
from PIL import Image
img = Image.open('test.jpg')
img.save('test1.png')
# 方法②
from cv2 import imread, imwrite
image = imread("test.jpg", 1)
imwrite("test2.png", image)
2、PDF加密和解密
如果你有100个或更多的PDF文件需要加密,手动进行加密肯定是不可行的,极其浪费时间。
使用Python的pikepdf模块,即可对文件进行加密,写一个循环就能进行批量加密文档。
# PDF加密
importpikepdf
pdf = pikepdf.open( "test.pdf")
pdf.save( 'encrypt.pdf', encryption=pikepdf.Encryption(owner= "your_password", user= "your_password", R= 4))
pdf.close
有加密那么便会有解密,代码如下。
# PDF解密
importpikepdf
pdf = pikepdf.open( "encrypt.pdf", password= 'your_password')
pdf.save( "decrypt.pdf")
pdf.close
3、获取电脑的配置信息
很多小伙伴可能会使用鲁大师来看自己的电脑配置,这样还需要下载一个软件。使用Python的WMI模块,便可以轻松查看你的电脑信息。
4、解压文件
使用zipfile模块进行文件解压,同理也可以对文件进行压缩。
# 解压文件
fromzipfile importZipFile
unzip = ZipFile( "file.zip", "r")
unzip.extractall( "output Folder")
5、Excel工作表合并
帮助你将Excel工作表合并到一张表上,表内容如下图。

6张表,其余表的内容和第一张表都一样。
设置表格数量为5,将会合并前5张表的内容。
import pandas as pd
# 文件名
filename = "test.xlsx"
# 表格数量
T_sheets = 5
df = []
for i in range(1, T_sheets+1):
sheet_data = pd.read_excel(filename, sheet_name=i, header=None)
df.Append(sheet_data)
# 合并表格
output = "merged.xlsx"
df = pd.concat(df)
df.to_excel(output)
结果如下:

6、将图像转换为素描图
和之前的图片格式转换有点类似,就是对图像进行处理。以前大家可能会使用到美图秀秀,现在可能就是抖音的滤镜了。其实使用Python的OpenCV,就能够快速实现很多你想要的效果。
# 图像转换
import cv2
# 读取图片
img = cv2.imread("img.jpg")
# 灰度
grey = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
invert = cv2.bitwise_not(grey)
# 高斯滤波
blur_img = cv2.GaussianBlur(invert, (7, 7), 0)
inverse_blur = cv2.bitwise_not(blur_img)
sketch_img = cv2.divide(grey, inverse_blur, scale=256.0)
# 保存
cv2.imwrite('sketch.jpg', sketch_img)
cv2.waitKey(0)
cv2.destroyAllWindows()
原图如下:

素描图如下,还挺好看的:

7、获取CPU温度
有了这个Python脚本,你将不需要任何软件来了解CPU的温度。
# 获取CPU温度
from time import sleep
from pyspectator.processor import Cpu
cpu = Cpu(monitoring_latency=1)
with cpu:
while True:
print(f'Temp: {cpu.temperature} °C')
sleep(2)
8、提取PDF表格
有的时候,我们需要从PDF中提取表格数据。
第一时间你可能会先想到手工整理,但是当工作量特别大,手工可能就比较费劲。
然后你可能会想到一些软件和网络工具来提取 PDF 表格。
下面这个简单的脚本将帮助你在一秒钟内完成相同的操作。
# 方法①
import camelot
tables = camelot.read_pdf("tables.pdf")
print(tables)
tables.export("extracted.csv", f="csv", compress=True)
# 方法②, 需要安装Java8
import tabula
tabula.read_pdf("tables.pdf", pages="all")
tabula.convert_into("table.pdf", "output.csv", output_format="csv", pages="all")
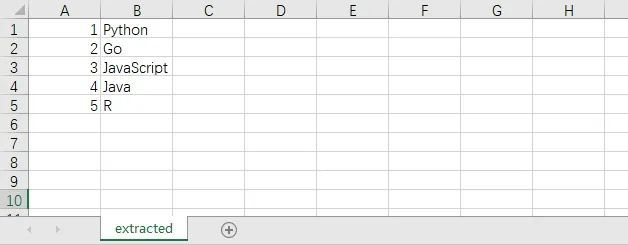
PDF文档的内容如下,包含了一个表格。

提取到的CSV文件内容如下。
9、截图
该脚本将简单地截取屏幕截图,而无需使用任何屏幕截图软件。
在下面的代码中,给大家展示了两种Python截取屏幕截图的方法。
# 方法①
from mss import mss
with mss() as screenshot:
screenshot.shot(output='scr.png')
# 方法②
import PIL.ImageGrab
scr = PIL.ImageGrab.grab()
scr.save("scr.png")
10、拼写检查器
这个Python脚本可以进行拼写检查,当然只对英文有效,毕竟中文博大精深呐。
# 拼写检查
# 方法①
import textblob
text = "mussage"
print("original text: " + str(text))
checked = textblob.TextBlob(text)
print("corrected text: " + str(checked.correct()))
# 方法②
import autocorrect
spell = autocorrect.Speller(lang='en')
# 以英语为例
print(spell('cmputr'))
print(spell('watr'))
print(spell('survice'))
零基础Python学习指南
Python学习路线汇总
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

Python必备开发工具

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
Python学习视频600合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

100道Python练习题
检查学习结果。
面试刷题


资料领取
这份完整版的Python全套学习资料已为大家备好,朋友们如果需要可以微信扫描下方二维码添加,输入"领取资料" 可免费领取全套资料【有什么需要协作的还可以随时联系我】朋友圈也会不定时的更新最前言python知识。

这世界上赚钱成本最低的就是:用知识投资大脑
人生什么时候学习都不晚,晚的是你一直想学却一直没有行动,而导致大量内耗
最后祝你学习愉快