深度学习 | 梯度下降法
梯度下降法(Gradient descent optimization)
理想的梯度下降算法要满足两点:收敛速度要快;能全局收敛
重点问题:如何调整搜索的步长(也叫学习率,Learning Rate)、如何加快收敛速度、如何防止搜索时发生震荡
分类:
批量梯度下降法(Batch gradient descent)
随机梯度下降法(Stochastic gradient descent)
小批量梯度下降法(Mini-batch gradient descent)
概念公式:
![]()
Batch gradient descent:![]() 是在整个数据集上训练的,如果数据集比较大,可能会面临内存不足问题,而且其收敛速度一般比较慢。
是在整个数据集上训练的,如果数据集比较大,可能会面临内存不足问题,而且其收敛速度一般比较慢。
Stochastic gradient descent:
![]() 是针对训练集中的一个训练样本计算的,又称为在线学习,即得到了一个样本,就可以执行一次参数更新。所以其收敛速度会快一些,但是有可能出现目标函数值震荡现象,因为高频率的参数更新导致了高方差。
是针对训练集中的一个训练样本计算的,又称为在线学习,即得到了一个样本,就可以执行一次参数更新。所以其收敛速度会快一些,但是有可能出现目标函数值震荡现象,因为高频率的参数更新导致了高方差。
Mini-batch gradient descent:
![]() 小批量梯度下降算法是折中方案,选取训练集中一个小批量样本计算
小批量梯度下降算法是折中方案,选取训练集中一个小批量样本计算![]() ,这样可以保证训练过程更稳定,而且采用批量训练方法也可以利用矩阵计算的优势。这是目前最常用的梯度下降算法。
,这样可以保证训练过程更稳定,而且采用批量训练方法也可以利用矩阵计算的优势。这是目前最常用的梯度下降算法。
冲量梯度下降算法:Momentum optimization
概念公式:
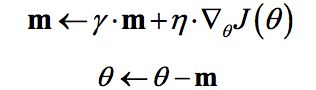
理解:参数更新时不仅考虑当前梯度值,而且加上了一个积累项(冲量),但多了一个超参![]() ,一般取接近1的值如0.9。相比原始梯度下降算法,冲量梯度下降算法有助于加速收敛。当梯度与冲量方向一致时,冲量项会增加,而相反时,冲量项减少,因此冲量梯度下降算法可以减少训练的震荡过程。TensorFlow中提供了这一优化器:
,一般取接近1的值如0.9。相比原始梯度下降算法,冲量梯度下降算法有助于加速收敛。当梯度与冲量方向一致时,冲量项会增加,而相反时,冲量项减少,因此冲量梯度下降算法可以减少训练的震荡过程。TensorFlow中提供了这一优化器:
NAG算法全称Nesterov Accelerated Gradient,是YuriiNesterov在1983年提出的对冲量梯度下降算法的改进版本,其速度更快。其变化之处在于计算“超前梯度”更新冲量项,具体公式如下:

既然参数要沿着 更新,不妨计算未来位置
更新,不妨计算未来位置![]() 的梯度,然后合并两项作为最终的更新项
的梯度,然后合并两项作为最终的更新项

AdaGrad
AdaGrad是Duchi在2011年提出的一种学习速率自适应的梯度下降算法。在训练迭代过程,其学习速率是逐渐衰减的,经常更新的参数其学习速率衰减更快,这是一种自适应算法。其更新过程如下:

其中是梯度平方的积累量,在进行参数更新时,学习速率要除以这个积累量的平方根,其中加上一个很小值是为了防止除0的出现。由于是该项逐渐增加的,那么学习速率是衰减的。考虑如图2所示的情况,目标函数在两个方向的坡度不一样,如果是原始的梯度下降算法,在接近坡底时收敛速度比较慢。而当采用AdaGrad,这种情况可以被改观。由于比较陡的方向梯度比较大,其学习速率将衰减得更快,这有利于参数沿着更接近坡底的方向移动,从而加速收敛。
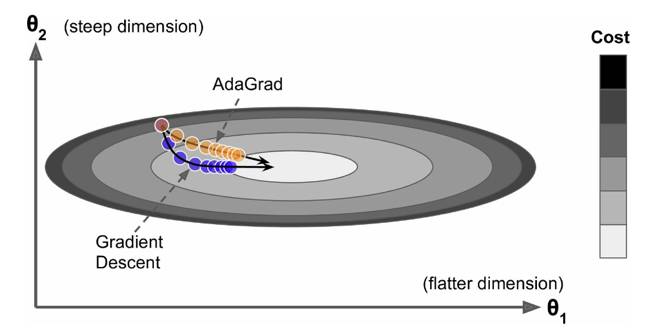
前面说到AdaGrad其学习速率实际上是不断衰减的,这会导致一个很大的问题,就是训练后期学习速率很小,导致训练过早停止,因此在实际中AdaGrad一般不会被采用,下面的算法将改进这一致命缺陷。
RMSprop
RMSprop是Hinton在他的课程上讲到的,其算是对Adagrad算法的改进,主要是解决学习速率过快衰减的问题。其实思路很简单,类似Momentum思想,引入一个超参数,在积累梯度平方项进行衰减:
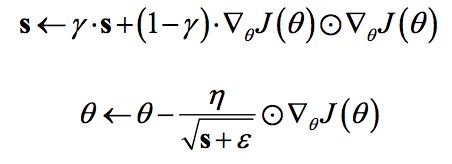
可以认为仅仅对距离时间较近的梯度进行积累,其中一般取值0.9,其实这样就是一个指数衰减的均值项,减少了出现的爆炸情况,因此有助于避免学习速率很快下降的问题。同时Hinton也建议学习速率设置为0.001。RMSprop是属于一种比较好的优化算法了,在TensorFlow中当然有其身影:tf.train.RMSPropOptimizer(learning_rate=learning_rate,momentum=0.9, decay=0.9, epsilon=1e-10)。
05
Adam
Adam全称Adaptive moment estimation,是Kingma等在2015年提出的一种新的优化算法,其结合了Momentum和RMSprop算法的思想。相比Momentum算法,其学习速率是自适应的,而相比RMSprop,其增加了冲量项。所以,Adam是两者的结合体:
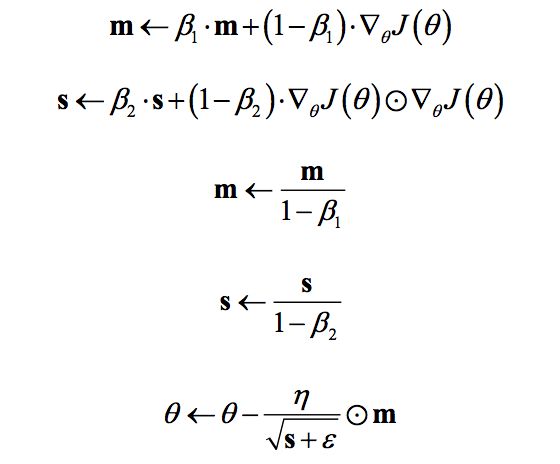
可以看到前两项和Momentum和RMSprop是非常一致的,由于和的初始值一般设置为0,在训练初期其可能较小,第三和第四项主要是为了放大它们。最后一项是参数更新。其中超参数的建议值是 。Adm是性能非常好的算法,在TensorFlow其实现如下: tf.train.AdamOptimizer(learning_rate=0.001,beta1=0.9, beta2=0.999, epsilon=1e-08)。
。Adm是性能非常好的算法,在TensorFlow其实现如下: tf.train.AdamOptimizer(learning_rate=0.001,beta1=0.9, beta2=0.999, epsilon=1e-08)。
本文简单介绍了梯度下降算法的分类以及常用的改进算法,总结来看,优先选择学习速率自适应的算法如RMSprop和Adam算法,大部分情况下其效果是较好的。还有一定要特别注意学习速率的问题。其实还有很多方面会影响梯度下降算法,如梯度的消失与爆炸,
理想的学习速率是:刚开始设置较大,有很快的收敛速度,然后慢慢衰减,保证稳定到达最优点。所以,前面的很多算法都是学习速率自适应的。除此之外,还可以手动实现这样一个自适应过程,如实现学习速率指数式衰减:

-
学习率较小时,收敛到极值的速度较慢。
-
学习率较大时,容易在搜索过程中发生震荡。