解决⾃动驾驶中计算机视觉的⽬标检测问题
来源:投稿 作者:cairuyi01
编辑:学姐
最近读了《Object detection with location-aware deformable convolution and backward attention filtering》,这是⼀篇2019年刊登在CVPR上的CV论⽂。与解决普适性的CV任务不同,作者CHEN ZHANG和JOOHEE KIM希望解决的是⾃动驾驶中计算机视觉的⽬标检测问题,如何检测距离摄像头较远的交通参与者,以及如何检测到互动的交通参与者。

这篇论⽂究竟想解决什么样的问题

⾸先,我们来看⼀个典型的交通场景,如上图,有⼀个架设在⾃动驾驶⻋辆上的摄像头,从摄像头的⻆度来看,会看到路⾯上的各种道路使⽤者和交通参与者,典型的类别包括了:⾏⼈,⾃⾏⻋,汽⻋。对于(a)和(b),我们发现本篇论⽂建议的模型,它能⽐Faster R-CNN多检测出了⾏⼈背后的⾃⾏⻋,以及两辆距离较远的汽⻋。对!参考图即便⽤⼈眼也较难发现的⽬标,论⽂建议的模型也检测出来了,这有什么意义?
- 汽⻋在⾼速⾏驶,这⼀秒距离还⽐较远的交通参与者,在下⼀秒可能就在⾯前了
汽⻋在⾼速地⾏驶,在城市道路上⾮拥堵时,会以时速约40-60KM前进,这意味着,这⼀秒距离还⽐较远的交通者,在下⼀秒就会来到⾯前了。要避免交通事故的发现,我们必须提前检测到他的存在。⽽当交通参与者距离摄像头较远时,往往他的外观都会⽐较⼩。
- 交通参与者之间存在互动,被遮挡的交通参与者容易造成漏检的情况
交通参与者在道路上总是运动着的,他们的⼀些交互和互动往往会导致交通状况的不确定性。试想⼀下,前⽅距离很近的两辆⻋正在⾏驶,此时因为他们局部重叠⽽造成漏检。在下⼀个时刻,被漏检的⻋辆忽然打灯切线更换⻋道,这就很容易造成事故,因为你⼀直追踪的⽬标并未与你发⽣相对位置的变动,⽽现在忽然多出来⼀个⽬标,并且⽴⻢出现在了⾯前。
⽽这辆漏检的汽⻋,被前⻋遮挡后只有局部的外观能被看到。再如,斑⻢线上的⾏⼈指示灯正在由⻩转红,道路指示灯正在由红转绿,计算机视觉检测到三五个⾏⼈的⼈群已经基本静⽌,于是准备发动⻋辆。此时,被⼈群遮挡的⾃⾏⻋忽然驶出,冲到了道路上。悲剧的是,由于⼀直没有感知到⾃⾏⻋的存在,突如其来的交通情况极其容易造成事故。⽽这辆被⼈群遮挡的⾃⾏⻋,往往是在那三五⼈群间隙中只露出了局部外观。
- 检测需求和⾯临的问题
上⽂谈及的两个检测需求,⽬标都⽐较⼩,他们要么远离摄像头,要么被其他交通参与者遮挡了只露出了局部的外观。要检测到他们,就需要在较⾼分辨率的特征图中进⾏,这样才能保证有⾜够的空间信息。
但,这是⼀个两难的问题:
1)在深度神经⽹络中,较⾼层级的特征图具备更丰富的语义,更容易归纳⽬标的特征,易于分类,但是,它过低的分辨率⼜会导致⼩⽬标在特征图上消失,难以作出有效定位。这样⼀来,简单地使⽤⾼层级的特征图并不能满⾜检测需求。
2)如果我们使⽤浅层的特征图,那么空间信息是⾜够了,对定位带来了帮助,但是粗糙的特征提取⼜使得分类任务难以被满⾜。再者,我们并不能保证测试集和训练集中背景内容具备同质性,于是,更⼤的受视野才能有⾜够的上下信息帮助感知⽬标的存在与否。这样⼀来,简单地使⽤浅层级的特征图并不能满⾜检测需求。
那么,如何是好呢?
下⾯,我们来看看作者在论⽂中建议的模型是如何解决这些局限性,满⾜检测需求的。
- 作者使⽤的baseline⽹络
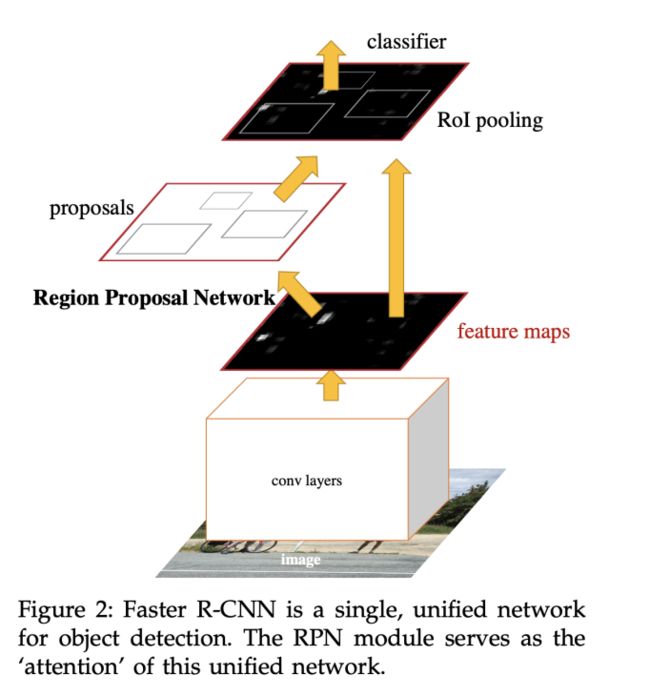
作者使⽤的是Faster R-CNN作为baseline⽹络的,它由以下的⼏个部分组成:
1)conv layers,使⽤诸如VGG,ResNet,MobileNet,GoogleNet,Inception ResNet等的backbone⽹络对图像进⾏特征的提取。
2)利⽤backbone提取的特征图,输⼊到Region Proposal Network(RPN),得到若⼲个的Region Proposal。
3)根据Region Proposal的坐标映射到第⼀步得到的特征图中,会得到⼀个个感兴趣的区域(ROI,Region of interesting)。这些区域会经由ROI Pooling统⼀为固定的⼤⼩尺⼨,放进后续的⽹络中进⾏分类预测和锚框回归,得到最终的检测结果。
在论⽂中,作者是以此作为baseline,并在这个基础上修改了backbone,以及加⼊了neck。
- 对backbone的修改
设计思路
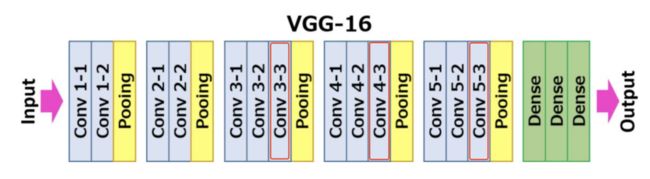
在论⽂中,作者是使⽤VGG16作为baseline的backbone,它可以被更换为上⽂提及的其他backbone。
在实验中,作者选择了VGG16和ResNet18,主要考虑了⾃动驾驶中⽬标检测往往对实时性有所要求。
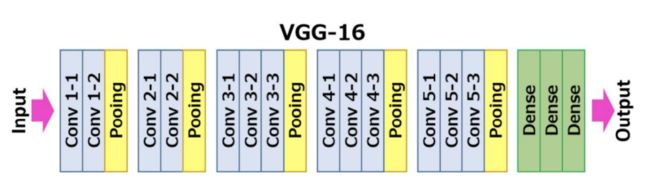
VGG16的⽹络架构如上图,它在每⼀层卷积层中⽤标准的3*3卷积核进⾏卷积操作,逐⼀提取特征,每层输出的特征图⽤于下⼀层的输⼊。
由于上⽂提及的问题:
1)⽬标在互动过程中可能产⽣变形(⾏为的动作变化)。
2)⽬标产⽣遮挡,有意义的外观只是局部(露出的局部可能是不规整的)。
于是,采⽤标准的3*3卷积核采样会弱化了待检测⽬标的特征浓度,作者提出了Location-aware deformable convolution(位置感知的可变形卷积)。
- 前置知识-Deformable convolutional(可变形卷积)

从上图中我们可以看到,(a)是标准的3*3卷积,与之相对的,(b)是可变形的卷积,采样的点可以根据需要进⾏偏移,按需进⾏采样。(c)和(d)是两种特殊情况,其中,(c)的变形⽅式使得采样相当于增⼤了受视野,⽽(d)的变形⽅式则是使得采样相当于进⾏旋转。

以两层卷积层的采样过程为例,标准33卷积采取固定的空间位置进⾏采样,⽽可变形的33卷积则是每层中根据感兴趣的空间位置进⾏了采样。诚然,在最后的特征图表征上,变形的3*3卷积得到的语义更加丰富。

具体的实现上,在input feature map之后进⾏可变形卷积之前会同时建⽴⼀个⽹络分⽀,这个分⽀会利⽤⼀个卷积层学习可变卷积核中每个采样点的位置偏移。值得注意的是,这个分⽀⽹络上的卷积层所采⽤的是与可变形卷积受视野⼀致的标准卷积核,换句话来说,如果可变形卷积核计划⽤膨胀率为1的3*3的卷积核。


综上所述,完成了⼀个可变卷积的过程。
Location-aware deformable convolution(位置感知的可变形卷积)在有了可变形卷积的前置知识后,下⾯我们来看看作者在论⽂中建议的位置感知的可变形卷积。看看他在可变形卷积的基础上做了那些改变,⼜起到了哪些作⽤。
学习偏移量的卷积层使⽤的卷积核,可以和位置感知的可变形卷积核有不同的受视野在input feature map之后进⾏可变形卷积之前所建⽴的⽹络分⽀上。
1)可变形卷积⽹络中,如果计划使⽤的可变形卷积核是膨胀率为1的33卷积核,那么学习偏移量的卷积核也必须是使⽤标准的33卷积核;
2)位置感知的可变形卷积⽹络中,虽然计划使⽤的可变卷积核是膨胀率为2的33卷积核,但是学习偏移量的卷积核依然可以随意选择⾃⼰的受视野,例如下图中,是使⽤标准的33卷积核。
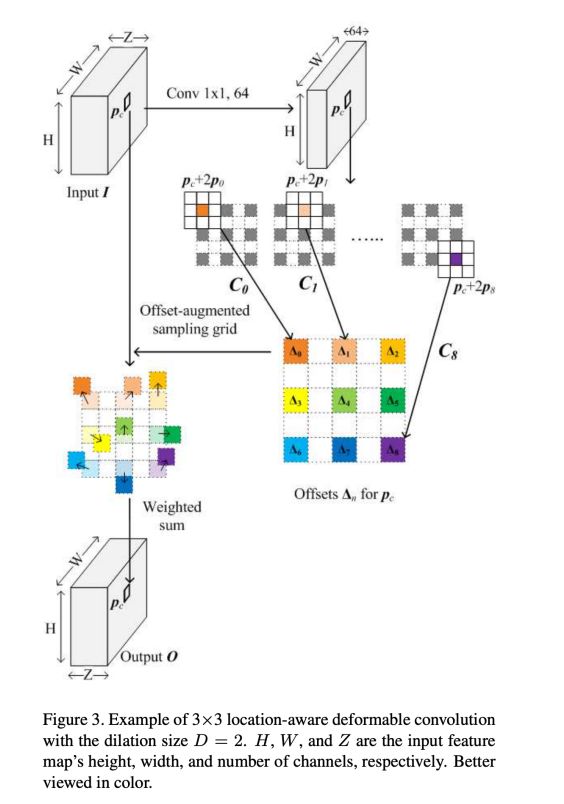
由于位置感知的可变形卷积核本身和学习它的偏移量的卷积核在受视野上进⾏了解耦,于是,在学习偏移量的过程中可以更灵活,这促使了⽹络更容易得到最优解。
- 在学习每个采样点的偏移量时,卷积运算的中⼼点以采样点为基础
在使⽤卷积核进⾏卷积运算学习偏移量时:
1)可变形卷积⽹络中,学习偏移量的卷积操作是以当前input feature map的输⼊样本点为中⼼的。
例如,假设当前坐标为(0,0),那么它的9个偏移量都是以(0,0)作为中⼼点进⾏卷积操作的。
2)位置感知的可变形卷积⽹络中,学习偏移量的卷积操作是以可变性卷积核的采样点为中⼼的。
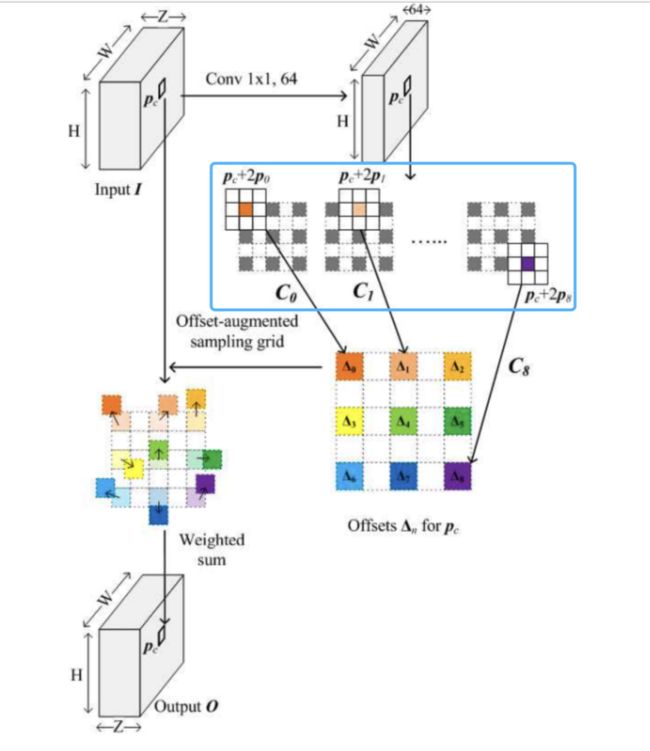
例如,假设当前坐标为(0,0),根据膨胀率为2的情况下,那么它的9个偏移量都是以对应(0,0)(-2,-2)(-2,0)(-2,2)(0,-2)(0,2)(-2,2)(0,2)(2,2)的9个采样点作为中⼼点进⾏卷积操作的。
- 把位置感知的可变形卷积整合到VGG16中
位置感知的可变形卷积将被整合到VGG16的Conv3-3,Conv4-3,Conv5-3中。
在整合时,VGG16原来的标准3*3卷积是保留的,在此基础上,再添加⼀个位置感知的可变形卷积分⽀:
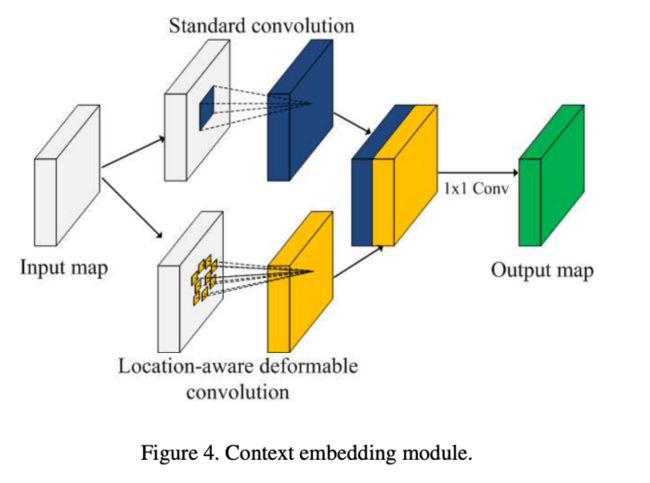
⾸先把标准3*3卷积分⽀的输出和位置感知的可变形卷积分⽀的输出按照通道进⾏拼接,然后,再使⽤⼀个1*1的卷积层将它们进⼀步融合。

由于后续的后向注意⼒过滤的需要,在VGG16常规的Conv5之后还添加⼀个Conv6的卷积层,在Pooling后,Conv6的feature map相⽐Conv5再缩⼩⼀倍。
⾄此,作者就对backbone⽹络的改造就完成了,他要解决的是⽬标与环境互动产⽣外观变形或局部被遮挡时导致外观不规整时,卷积能针对⽬标的空间位置有更灵活的采样,使得特征提取更有意义。

从作者的实验中,我们也可以 看到,采取位置感知的可变形卷积(Method B)要⽐标准卷积(Method C)和可变形卷积(Method A)有更⾼的检测准确率。
添加neck⽹络——后向注意⼒过滤(backward attention filtering)
设计思路
要进⾏⼩⽬标的检测,对⾼分辨率的特征图是有严重依赖的,因为只有特征图上有⾜够的空间信息,⼩⽬标才能被检测出来。不过,如果我们直接使⽤浅层的⾼分辨率特征图,它们虽然有⾜够的空间信息,但同时⼲扰的信息也多,这对于模型⽹络后续的分类预测和锚框回归也带来不少负⾯作⽤。
作者提出了⼀种后向注意⼒过滤的⽅法,他希望利⽤深层⽹络中富有语义的特征图作为过滤器对相对浅层的特征图进⾏过滤,把⼲扰的背景信息逐⼀滤除,留下当前分辨率特征图该有的⽬标信息。这样⼀来,每个分辨率的特征图送⼊后续的检测⼦⽹络,都能得到不错的,对应该分辨率的⽬标检测效果。
- 后向注意⼒过滤的原理
建⽴过滤器
作者是使⽤深层的特征图作为基础进⾏滤波器的制作的。以Conv6为例,它的输出将被⽤作Conv5的过滤器。作为过滤器,作者需要:
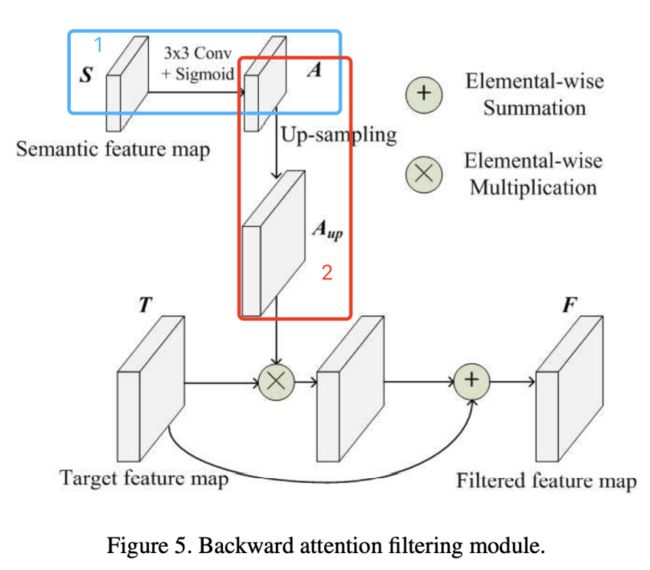
1)把它的特征图取值范围映射到(0,1)之间,如此⼀来,后续与⽬标特征图进⾏相乘时,可以起到越接近0,⽬标特征图该处的特征被抹除,越接近1,⽬标特征图该处的特征被保留的作⽤。
2)Conv6的feature map相⽐Conv5缩⼩了⼀倍,于是,接下来还需要做⼀次upsample(上采样),使得滤波器特征图还原到与Conv5的feature map⼀样的⼤⼩,如此⼀来,后续的逐像素相乘才能⼀⼀对应。
进⾏过滤操作
作者利⽤滤波器特征图与⽬标特征图进⾏相乘,同时,⽬标特征图再做了⼀次skip,逐像素相加到相乘的结果之上。
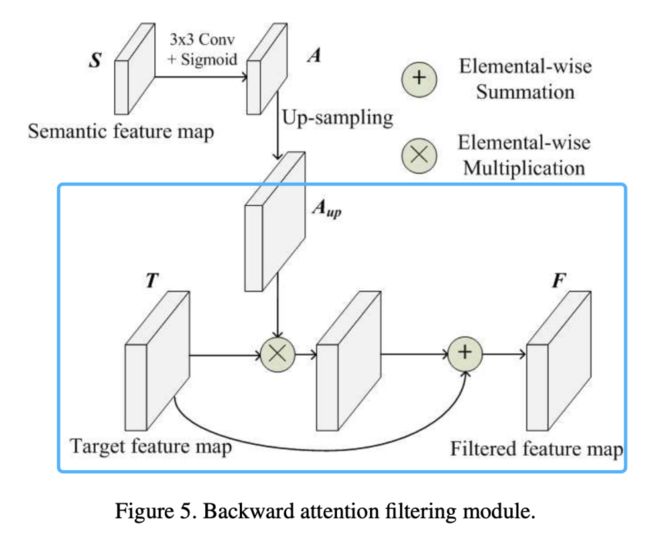
加⼊skip的⽬的应该是借鉴了ResNet设计的思路,作为最后的学习保障,这个过滤层可以在学习⽆果时不起任何作⽤。这⼀选择交由模型⽹络⾃⾏决策。最后,整个后向注意⼒滤波的计算公式为:
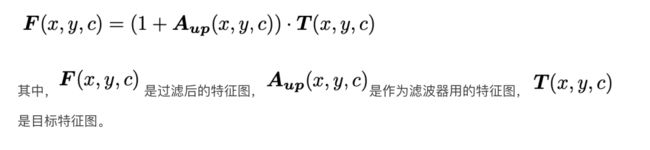
- 添加后向注意⼒过滤后的模型

可以看到,整个过滤的过程是从深层⽹络⼀步⼀步向浅层递进的。每次过滤后的特征图⼀⽅⾯会作为下⼀个浅层特征图过滤的过滤器,过滤三次后送进RPN进⾏锚框的⽣成,另外⼀⽅⾯也会送进ROI Pooling中,为最后⼀步的分类预测和锚框回归作准备。
- head⽹络——接上Faster R-CNN的detector
后向注意⼒过滤之后,⽹络会把过滤后的特征图送进⼦检测⽹络中。

1)送⼊RPN⽹络的特征图,是三次过滤后的特征图,它拥有较⾼的分辨率,也就具备了⾜够的空间信息。在它的基础上进⾏锚框的⽣成将有利于把不同尺度的⽬标进⾏初定位。
2)根据⽣成的Region proposal,提取不同分辨率特征图上对应的区域进⾏ROI Pooling,此时,不同层级的特征图拥有不同受视野的语义,在之后的分类预测和锚框回归中起到⾮常好的正⾯作⽤。

由上图我们可以看到,过滤了⼲扰信息后,RPN只需要⽣成更少的锚框,就能使得平均准确率⽐之前⾼,这也就意味着,此时模型中的RPN能⽣成质量更⾼的锚框。
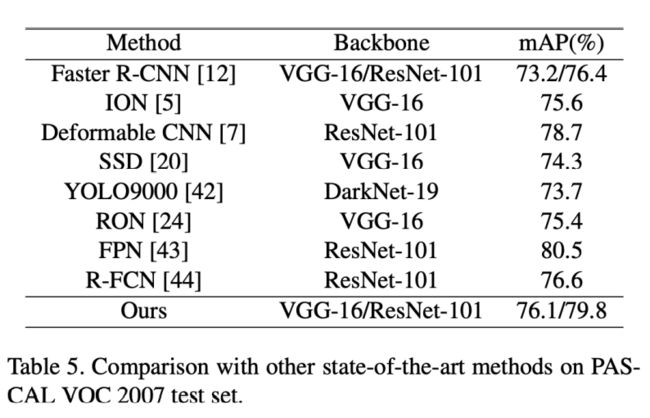
最后,我们可以看到,作者把他建议的模型与当时的其他具有最佳性能的检测模型在PASCAL VOC2017测试集上进⾏了对⽐,其检测性能仅次于FPN,取得了⾮常有竞争⼒的结果。

⽽值得注意的是,作者建议的模型在运⾏性能上⾮常优秀,Runtime仅为0.22 sec(backbone VGG16)和0.14 sec(backbone ResNet18),为⾃动驾驶领域提供了⾼效运⾏的性能⽀持。
结论
在⾃动驾驶领域,交通参与者的检测是计算机视觉关⼼的话题。由于这些交通参与者者需要提前被感知,此时,他们因为远离摄像头⽽显得外观较⼩;同时,这些交通参与者可能因为互动⾏为或者被遮挡导致了外观的变形或不规整,⽽露出的外观也可能是较⼩的,这些都成为了⽬标检测中的难题。
作者建议的模型,通过使⽤位置感知的可变形卷积解决了⽬标与环境互动产⽣外观变形或局部被遮挡时导致外观不规整时,卷积能针对⽬标的空间位置有更灵活的采样,使得特征提取更有意义。同时,通过后向注意⼒过滤的⽅法,利⽤深层⽹络中富有语义的特征图作为过滤器对相对浅层的特征图进⾏过滤,把⼲扰的背景信息逐⼀滤除,留下当前分辨率特征图该有的⽬标信息。借此平衡了浅层特征图有⾜够空间信息但语义不强,⽽深层特征图有丰富语义但缺乏空间信息的问题,⼩⽬标的检测也能在逐层过滤中得到更⾼质量的检测。
最终,截⽌论⽂发表时,作者建议的模型在保证了运⾏性能的同时,检测性能上取得良好表现,其检测性能仅次于FPN,取得了⾮常有竞争⼒的结果。
220+篇AI必读论文
关注下方《学姐带你玩AI》即可领取
码字不易,欢迎大家点赞评论收藏!