基于tensorflow的猫狗分类
基于tensorflow的猫狗分类
- 数据的准备
-
- 引入库
- 数据集来源
- 准备数据
- 显示一张图片的内容
- 搭建网络模型
-
- 构建网络
- 模型的编译
- 数据预处理
- 模型的拟合与评估
-
- 模型的拟合
- 预测一张图片
- 损失和精度曲线
数据的准备
引入库
import os
import shutil
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
import tensorflow as tf
from keras import layers
from keras import models
from tensorflow.keras import optimizers
数据集来源
数据集来源于kaggle上的公开数据,链接:猫狗数据
该数据集包含25000张图片,但本项目只选取其中1000张猫的图片,1000张狗的图片作为训练集。500张猫的图片,500张狗的图片作为验证集。下载好数据集后,下面的操作就是提前本项目所需要的一个数据。
准备数据
1,显示当前路径
# 当前路径
current_dir = %pwd
current_dir
2,创建数据文件夹
# 创建数据文件夹
base_dir = current_dir + '/cats_dogs_small'
os.mkdir(base_dir)
3,创建数据集文件夹
train_dir = os.path.join(base_dir,'train')
os.mkdir(train_dir)#创建训练集
val_dir = os.path.join(base_dir,'val')
os.mkdir(val_dir)#创建验证集
test_dir = os.path.join(base_dir,'test')
os.mkdir(test_dir)#创建测试集
train_dir_cat = os.path.join(train_dir,'cat')
os.mkdir(train_dir_cat)#训练集猫
train_dir_dog = os.path.join(train_dir,'dog')
os.makedirs(train_dir_dog)#训练集狗
val_dir_cat = os.path.join(val_dir,'cat')
os.mkdir(val_dir_cat)#验证集猫
val_dir_dog = os.path.join(val_dir,'dog')
os.mkdir(val_dir_dog)#验证集狗
test_dir_cat = os.path.join(test_dir,'cat')
os.mkdir(test_dir_cat)#测试集猫
test_dir_dog = os.path.join(test_dir,'dog')
os.mkdir(test_dir_dog)#测试集狗

4,从下载解压好的数据文件中,复制我们需要的图片到指定目录。
# 复制文件到创建的文件中
fnames = ['cat.{}.jpg'.format(i) for i in range(1000)]
for name in fnames:
src = os.path.join(r'C:\Users\jiaoyang\Desktop\dogs-vs-cats\train\train', name)
dst = os.path.join(train_dir_cat, name)
shutil.copyfile(src,dst) #复制文件内容
fnames = ['dog.{}.jpg'.format(i) for i in range(1000)]
for name in fnames:
src = os.path.join(r'C:\Users\jiaoyang\Desktop\dogs-vs-cats\train\train', name)
dst = os.path.join(train_dir_dog,name)
shutil.copyfile(src,dst) #复制文件内容
fnames = ['cat.{}.jpg'.format(i) for i in range(1000,1500)]
for name in fnames:
src = os.path.join(r'C:\Users\jiaoyang\Desktop\dogs-vs-cats\train\train', name)
dst = os.path.join(val_dir_cat,name)
shutil.copyfile(src,dst) #复制文件内容
fnames = ['cat.{}.jpg'.format(i) for i in range(1000,1500)]
for name in fnames:
src = os.path.join(r'C:\Users\jiaoyang\Desktop\dogs-vs-cats\train\train', name)
dst = os.path.join(test_dir_cat,name)
shutil.copyfile(src,dst) #复制文件内容
fnames = ['dog.{}.jpg'.format(i) for i in range(1500,2000)]
for name in fnames:
src = os.path.join(r'C:\Users\jiaoyang\Desktop\dogs-vs-cats\train\train',name)
dst = os.path.join(val_dir_dog,name)
shutil.copyfile(src,dst) #复制文件内容
fnames = ['dog.{}.jpg'.format(i) for i in range(1500,2000)]
for name in fnames:
src = os.path.join(r'C:\Users\jiaoyang\Desktop\dogs-vs-cats\train\train',name)
dst = os.path.join(test_dir_dog,name)
shutil.copyfile(src,dst) #复制文件内容
注:shutil.copyfile()的作用就是将源文件复制到目标文件。
显示一张图片的内容
# 显示图片的内容
from PIL import Image
path = os.path.join('./cats_dogs_small/train/cat/cat.0.jpg')
Image.open(path)

搭建网络模型
构建网络
model = models.Sequential()
model.add(tf.keras.layers.Conv2D(32,(3,3),activation='relu',input_shape=(150,150,3))) #输入图片大小为(150,150,3)
model.add(tf.keras.layers.MaxPooling2D((2,2)))
model.add(tf.keras.layers.Conv2D(64,(3,3),activation='relu'))
model.add(tf.keras.layers.MaxPooling2D((2,2)))
model.add(tf.keras.layers.Conv2D(128,(3,3),activation='relu'))
model.add(tf.keras.layers.MaxPooling2D(2,2))
model.add(tf.keras.layers.Conv2D(128,(3,3),activation='relu'))
model.add(tf.keras.layers.MaxPooling2D(2,2))
model.add(tf.keras.layers.Flatten()) # 除第一维(样本个数),其它维度压缩成1维
model.add(tf.keras.layers.Dense(512,activation='relu')) # 512代表输出空间的维数,全连接层则起到将学到的特征表示映射到样本的标记空间的作用。
model.add(tf.keras.layers.Dense(1,activation='sigmoid')) # 1代表输出空间的维数
model.summary()#打印网络结构

网络的结构如上图所示。
注:
- param列代表可以训练的参数,如:第一层卷积可以训练参数896个
- 训练参数个数的由来,如896 = 32 (卷积核个数)* [ 3 * 3(卷积核大小)*3(通道数)+1(偏置)]
- 池化的作用:减小计算,局部区域更突出。本例中,池化层的大小为(2*2)使得(None,148,148,32)---->(None,74, 74,32)
- tf.keras.layers.Flatten(),作用:使得数据转换为1维的,扁平化数据。
- 全连接中的参数,代表输出数据的大小。
模型的编译
from tensorflow.keras import optimizers
model.compile(loss="binary_crossentropy",
optimizer = optimizers.RMSprop(learning_rate=1e-4),
metrics=['acc'])
#损失函数交叉熵损失函数,优化方法RMSprop,评价指标acc
数据预处理
keras有个处理图像的模块:keras.preprocessing.image
它包含ImageDataGenerator类,可以快速创建Python生成器,将图形文件处理成张量批量
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(rescale=1./255)#进行缩放
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
train_dir,#训练集所在目录
target_size=(150,150),#将图片转换为目标大小
batch_size=20,#每一批的数量
class_mode='binary' # 损失函数是binary_crossentropy 所以使用二进制标签
)
valid_generator = test_datagen.flow_from_directory(
val_dir,
target_size=(150,150),
batch_size=20,
class_mode = 'binary'
)
查看生成的数据
for data_batch,labels_batch in train_genertor:
print(data_batch.shape)
print(labels_batch.shape)
break
(20, 150, 150, 3)
(20,)
模型的拟合与评估
模型的拟合
history = model.fit_generator(
train_generator,#第一个参数必须是python生成器
steps_per_epoch=100,#批量数
epochs = 10,#迭代次数
validation_data = valid_generator,#待验证的数据集
validation_steps = 50
)
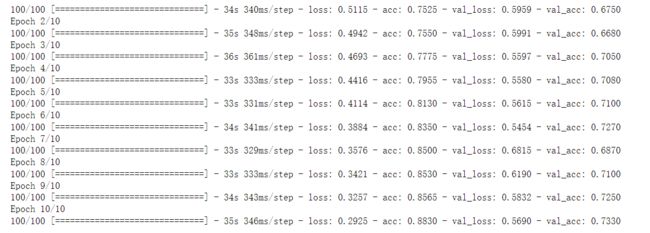
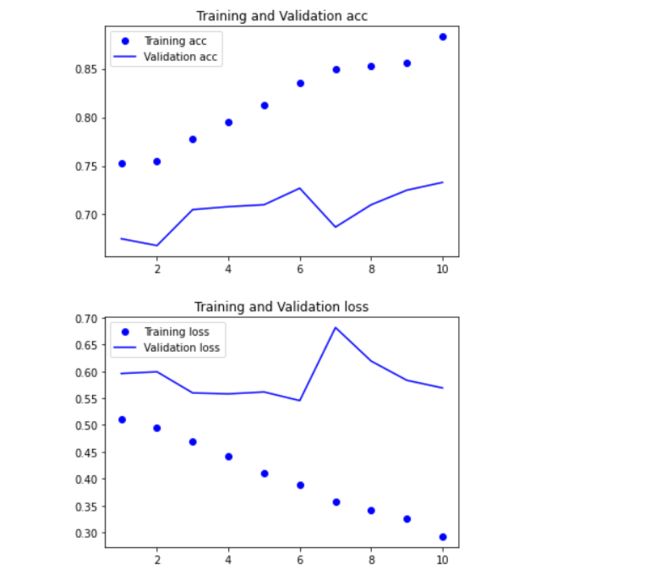
可以看到,随着不断的迭代,模型的准确率在训练集上和测试集上都在不断的提升。模型的损失在训练集上和测试集上,不断的下降。
预测一张图片
image = np.array(train_generator[0][0])
image[0]
pred = model.predict(image[1].reshape(1,150,150,3))
xx = {0: '猫', 1: '狗'}
print(xx[pred.argmax()])
plt.imshow(image[1].reshape(150,150,3))
plt.show()

损失和精度曲线
import matplotlib.pyplot as plt
history_dict = history.history # 字典形式
for key, _ in history_dict.items():
print(key)
# 获取数据
acc = history_dict["acc"]
val_acc = history_dict["val_acc"]
loss = history_dict["loss"]
val_loss = history_dict["val_loss"]
绘制
epochs = range(1, len(acc)+1)
# acc,准确度
plt.plot(epochs, acc, "bo", label="Training acc")
plt.plot(epochs, val_acc, "b", label="Validation acc")
plt.title("Training and Validation acc")
plt.legend()
plt.figure()
# loss,损失
plt.plot(epochs, loss, "bo", label="Training loss")
plt.plot(epochs, val_loss, "b", label="Validation loss")
plt.title("Training and Validation loss")
plt.legend()