论文阅读:LIF-Seg: LiDAR and Camera Image Fusion for 3DLiDAR Semantic Segmentation
LIF-Seg:用于 3D LiDAR 语义分割的 LiDAR 和相机图像融合
来源:华科 + 商汤 未发表2021
链接:https://arxiv.org/abs/2108.07511
个人觉得有用的和自己理解加粗和()内表示,尽量翻译的比较全,有一些官方话就没有翻译了,一些疑惑的地方欢迎大家探讨。如果对整个领域比较熟悉看一、三两章就可以了
0、摘要
摄像头和 3D LiDAR 传感器已成为现代自动驾驶汽车中不可或缺的设备,其中摄像头提供 2D 空间中的细粒度纹理、颜色信息,而 LiDAR 则捕捉周围环境更精确和更远的距离测量值。来自这两个传感器的互补信息使双模态融合成为理想的选择。然而,相机和 LiDAR 之间融合的两个主要问题阻碍了它的性能,即如何有效融合这两种模式以及如何精确对齐它们(遭受弱时空同步问题)。在本文中,我们提出了一种由粗到细的 LiDAR 和基于相机融合的网络(称为 LIF-Seg)用于 LiDAR 分割。对于第一个问题,与以前的这些以一对一的方式融合点云和图像信息的工作不同,所提出的方法充分利用了图像的上下文信息,并引入了一种简单但有效的早期融合策略。其次,由于弱时空同步问题,设计了一种偏移校正方法来对齐这些双模态特征。这两个组件的合作促使了有效的相机-LiDAR 融合的成功。 nuScenes 数据集上的实验结果表明,所提出的 LIF-Seg 优于现有方法的优势很大。消融研究和分析表明,我们提出的 LIF-Seg 可以有效解决弱时空同步问题。
索引词——LiDAR 和相机、LiDAR 分割、上下文信息、弱时空同步
1、引文INTRODUCTION
随着自动驾驶的快速发展,3 D场景感知近年来受到越来越多的关注,尤其是在计算机视觉和深度学习方面。LiDAR已成为自动驾驶中不可或缺的3D传感器。与其他传感器(例如照相机和雷达)的数据相比,LiDAR获取的点云可以提供丰富的几何、比例信息、精确的距离测量和精细的语义描述,这对于理解自动驾驶规划和执行的3D场景非常有用。
LiDAR点云语义分割旨在为每个3 D点分配一个特殊的语义类别,这是自动驾驶的关键任务。此任务可帮助感知系统识别和定位动态对象和可驱动曲面。虽然3D对象检测的经典任务已经开发出相对成熟的解决方桉[1]、[2]、[3]来支持现实世界中的自动驾驶,但难以识别和定位可行区域。一般来说,LiDAR点云稀疏,其稀疏度通常随着反射距离的增加而增加,这使得语义分割模型很难在远处分割小物体,如图1左侧所示。

如上所述,虽然LiDAR点可以提供准确的距离测量并捕获物体的结构,但它们通常是稀疏的、无序的和不均匀的分布。 最近,一些仅基于LiDAR的方法[5]、[6]、[7]、[8]显著改善了3D语义分割的性能,但这些方法的性能仍然有限,因为缺乏关于对象的密集和丰富的信息,如其颜色和纹理,如图1的右侧所示。 与点云相比,摄像机图像包含更规则和密集的像素并且具有更丰富的语义信息(例如,颜色、纹理)以区分不同的语义类别,同时遭受缺乏深度和缩放信息的痛苦。 因此,来自LiDAR和摄像机的互补信息使得两种模式融合成为期望的选择。 然而,如何有效地融合这两种模式,以便我们可以充分利用这两个传感器的优势来产生更好和更可靠的准确的语义分割结果。
最近,出现了一些包含 LiDAR 点云和图像的自动驾驶数据集,例如 KITTI [9] 和 nuScenes [4]。这些数据集不仅为结合点云和图像的优势提供了可能,而且对学术界和工业界点云语义分割的发展起到了重要的推动作用。然而,如图 2 所示,LiDAR 和相机之间存在弱时空同步问题。可以使用一些策略来缓解这个问题。例如,KITTI 和 nuScenes 将点云和图像与带时间戳的传感器元数据重新对齐,但仍然存在一定偏差。弱时空同步问题也限制了相机与激光雷达之间融合的性能。

受上述发现的启发,我们提出了一个由粗到精的框架,名为 LIF-Seg,以融合 LiDAR 和相机以进行 3D LiDAR 点云语义分割。对于第一个问题,与之前的这些以一对一的方式融合点云和图像信息的工作不同,在粗糙阶段,LiDAR 点被投影到每个相机图像中,每个像素的 3×3 上下文信息是连接到 LiDAR 点的强度测量。连接的 LiDAR 点被馈送到 UNet 分割子网络(例如,Cylinder3D [6])以获得粗糙的 LiDAR 点特征。针对弱时空同步问题,设计了一种偏移校正方法来对齐粗特征和图像语义特征。具体来说,图像语义分割子网络(例如,DeepLabv3+ [10])用于提取图像语义特征。粗特征被投影到每个图像中。投影的粗糙特征进一步与图像语义特征融合,以预测每个投影点与相应图像语义像素之间的偏移量。预测的偏移量用于补偿和对齐这些双模态特征,然后将对齐的图像语义特征与粗特征融合。在细化阶段,融合的特征被送入子网络以细化并生成更准确的预测。 LIF-Seg不仅融合了激光雷达的点特征和不同层次的图像特征,还有效地解决了激光雷达和相机之间时空同步较弱的问题。
这项工作的主要贡献如下:
( 1 )我们充分利用低级图像上下文信息,并引入一个简单而有效的早期融合策略。
( 2 )我们提出了一种偏移整流方法来解决LiDAR和摄像机之间的弱时空同步问题。
( 3 )我们构建了一个粗糙到细的LiDAR和基于摄像机融合的网络LIF-Seg用于LiDAR语义分割。 NuScenes数据集的实验结果证明了我们方法的有效性。
2、相关工作 RELATED WORK
在本节中,我们将简要回顾与我们的方法相关的现有工作:3D 点云的深度学习、LiDAR 点云语义分割、LiDAR 和相机融合方法、图像语义分割。特别是,我们主要关注仅 LiDAR 和基于融合的方法。
2.1 3D点云深度学习 Deep learning for 3D Point Clouds
与2D图像处理方法不同,点云处理是一项具有挑战性的任务,因为其不规则和无序的特性。 PointNet [11]是通过共享多层Perceptron (MLP)和最大池直接学习基于原点云的点特征的首批作品之一。 一些后续作品[12] , [13] , [14] , [15] , [16] , [17] , [18] , [19] , [20]通常基于先驱作品(例如, PointNet , PointNet + + ) ,并进一步提高采样,分组和排序的有效性,以提高语义分割的性能。 其他方法[21] , [22] , [23]通过引入图形网络来提取分层点特征。 虽然这些方法在室内点云上取得了有希望的细分结果,但由于密度不同,场景范围广泛,大多数方法无法直接训练或扩展到大型室外LiDAR点云。 此外,许多点还导致这些方法在适应户外场景时具有昂贵的计算和存储器消耗。
2.2 激光雷达点云语义分割LiDAR Point Cloud Semantic Segmentation
随着公共数据集[4]、[24]的可用性增加,激光雷达点云语义分割研究正在发展。目前,这些方法可以分为三大类:基于投影的方法、基于体素的方法和基于多视图融合的方法。
基于投影的方法侧重于将 3D 点云映射到规则且密集的 2D 图像,以便 2D CNN 可用于处理伪图像。 SqueezeSeg [25]、SqueezeSegv2 [26]、RangeNet++ [27]、SalsaNext [28]和KPRNet [5]利用球面投影机制将点云转换为距离图像,并采用编码器-解码器网络获取语义信息.例如,KPRNet [5] 提出了一种改进的架构,并通过使用强大的 ResNeXt-101 主干和 Atrous Spatial Pyramid Pooling (ASPP) 块取得了可喜的结果,它还应用 KPConv [29] 作为分割头来取代低效的 KNN后期处理。 PolarNet [30] 使用鸟瞰图 (BEV) 而不是标准的基于 2D 网格的 BEV 投影。然而,这些基于投影的方法不可避免地会丢失和改变原始拓扑,导致几何信息建模失败。
基于体素的方法将点云转换为体素,然后应用普通 3D 卷积以获得分割结果。最近,提出了一些工作 [31]、[32] 来加速 3D 卷积,并以更少的计算和内存消耗提高性能。继之前的工作 [31]、[32]、3D-MPA [15]、PointGroup [33] 和 OccuSeg [34] 在室内点云上取得了显着的分割结果。如上所述,由于室外点云的固有特性,包括稀疏性和变化的密度,这些方法不能直接用于室外 LiDAR 点云分割。此外,Cylinder3D [6]利用圆柱分区并设计了一个非对称残差块以进一步减少计算量。
基于多视图融合的方法结合了基于体素、基于投影和/或逐点操作的 LiDAR 点云分割。为了提取更多的语义信息,一些最近的方法 [35]、[36]、[37]、[38]、[39]、[40]、[41]、[7]、[8] 混合了两个或多个不同的视图一起。例如,[38]、[39]在早期结合来自 BEV 和距离图像的逐点信息,然后将其提供给后续网络。 AMVNet [37] 利用不同视图输出的不确定性来进行后期融合。 PCNN [35]、FusionNet [40] 和 (AF)2-S3Net [7] 使用点体素融合方案来获得更好的分割结果。 RPVNet [8] 提出了一种深度融合网络,通过门控融合机制融合距离点体素三视图。然而,由于 LiDAR 点云缺乏丰富的颜色和纹理,这些方法的性能也受到限制。
2.3 激光和相机融合方法 LiDAR and Camera Fusion Methods
为了充分利用相机和激光雷达传感器的优势,一些方法[42]、[43]、[44]、[45]、[46]、[47]、[48]、[49]、[50] ] 已经提出用于相机和 LiDAR 融合,特别是在 3D 目标检测任务中。 PI-RCNN [47] 通过对 3D 点进行逐点卷积并将点池化与聚合操作来融合相机和 LiDAR 特征。 CLOCs [48] 在任何 2D 和任何 3D 检测器的非最大抑制之前对组合输出候选进行操作。 3DCVF [49] 通过使用交叉视图空间特征融合策略结合相机和 LiDAR 特征以获得更好的检测性能。 EPNet [50] 提出了一个 LiDAR 引导图像融合模块,以在多个尺度上增强具有相应图像语义特征的 LiDAR 点特征。 PointPainting [46] 将激光雷达点投影到纯图像语义分割网络的输出中,并将类别分数附加到每个点,然后将其馈送到激光雷达检测器。这些方法在 3D 对象检测中取得了令人鼓舞的性能。然而,之前有一些工作通过结合相机和 LiDAR 的优势专注于 3D 语义分割,并解决相机和 LiDAR 之间传感器的弱时空同步问题。
2.4 图像分割Image Semantic Segmentation
图像语义分割是计算机视觉中一项重要的基础性任务,取得了很大进展。FCN [51]是直接采用全卷积层生成图像语义分割结果的开创性工作。DeepLab [10]系列利用atrous卷积和ASPP模块来捕获图像的上下文信息。STDC2 [52]使用详细指导模块对低级空间信息进行编码,但性能相对较低,从而减少了推理的耗时。在效率和性能之间进行权衡,我们在本工作中采用DeepLabv3+[10]作为图像分割子模型。
3 我们的方法 PROPOSED METHOD
利用激光雷达和摄像机的优点互补,对于准确的激光雷达点云语义分割非常重要。 然而,大多数现有的方法都没有充分利用相机图像上下文信息,而忽略了LiDAR和相机之间的空间时空同步问题,限制了融合模型识别细粒度模式的能力。 本文提出了一个名为LIFSeg的粗细框架,从两个方面提高LiDAR分割的性能,包括早期低级图像上下文信息融合,以及中期对齐的高层图像语义信息融合。 LIF-Seg接受激光雷达点和摄像头图像作为输入,并预测每个点的语义标签。 它由三个主要阶段组成:粗特征提取阶段、偏移学习阶段和精炼阶段。 我们将在以下几个小节详细介绍这三个方面。
3.1 粗特征提取阶段Coarse Feature Extraction Stage
LiDAR 点可以提供精确的距离测量和捕获物体的结构,并且相机图像包含更规则和密集的像素并且具有更丰富的语义信息。一些方法 [46]、[47]、[48] 试图在不同阶段(例如,早期融合、中期融合和晚期融合)将 LiDAR 和相机视图混合在一起以进行 3D 对象检测。大多数这些方法仅以一对一的方式融合低级或高级图像信息。然而,在融合 LiDAR 和相机的视图时,图像的上下文信息也很重要。在粗阶段,我们融合 LiDAR 点和低级图像上下文信息以获得粗特征。
如图 3 和算法 1 所示,LiDAR 点 L 中的每个点都具有空间位置(x,y,z)和反射率 r 等。LiDAR 点通过齐次变换和投影转换为每个相机图像的信息。这个过程可以表述如下:
![]()
其中 ![]() 和
和![]() 分别是相机图像
分别是相机图像![]() 对应的相机固有矩阵和齐次变换矩阵。
对应的相机固有矩阵和齐次变换矩阵。![]() 是LiDAR点L在相机图像
是LiDAR点L在相机图像![]() 上的索引(像素坐标),其中N是LiDAR点数。一般变换由
上的索引(像素坐标),其中N是LiDAR点数。一般变换由![]() 给出。对于 nuScenes 数据集,对每个摄像机的完整转换是:
给出。对于 nuScenes 数据集,对每个摄像机的完整转换是:
![]()
激光雷达点变换到相机坐标后,对应的相机矩阵Ki将这些点投影到图像![]() 中。之后,每个投影点位置的 w×w(例如 3×3)图像上下文信息被重塑并连接到相应的 LiDAR 点。连接点被馈送到 UNet 语义分割子网络(例如,Cylinder3D [6])以获得粗特征
中。之后,每个投影点位置的 w×w(例如 3×3)图像上下文信息被重塑并连接到相应的 LiDAR 点。连接点被馈送到 UNet 语义分割子网络(例如,Cylinder3D [6])以获得粗特征 ![]() 。
。

3.2偏移学习阶段 Offset Learning Stage
尽管早期融合和中期融合的方法在基准数据集上取得了可喜的成果,但由于激光雷达和相机之间的时空同步问题较弱,这些方法的性能也受到限制。为了解决上述问题,我们提出的 LIF-Seg 预测了投影 LiDAR 点和相应像素之间的偏移量。预测的偏移量用于补偿和更新投影点特征的位置,然后将对齐的图像语义特征与粗特征融合以更好地分割。
在这个阶段,如图4和算法1所示,我们首先利用图像语义分割子网络来获得高层图像语义特征![]() 。 效率和性能之间的权衡,我们采用DeepLabv3 + [10]作为我们的图像分割子网络来提取图像特征。 同时,粗糙外形
。 效率和性能之间的权衡,我们采用DeepLabv3 + [10]作为我们的图像分割子网络来提取图像特征。 同时,粗糙外形![]() 也被投影到图像特征图中,并形成与图像外形大小相同的伪图像特征图
也被投影到图像特征图中,并形成与图像外形大小相同的伪图像特征图![]() 。特征图
。特征图 ![]() 进一步与图像语义特征
进一步与图像语义特征![]() 融合,以预测投影 LiDAR 点和相应像素之间的偏移量。预测的Offset可用于补偿和更新投影点在图像特征中的位置。然后根据更新后的位置,将图像语义特征
融合,以预测投影 LiDAR 点和相应像素之间的偏移量。预测的Offset可用于补偿和更新投影点在图像特征中的位置。然后根据更新后的位置,将图像语义特征![]() 反投影到3D空间,生成逐点特征
反投影到3D空间,生成逐点特征![]() 。逐点图像特征
。逐点图像特征![]() 用于与粗特征
用于与粗特征 ![]() 融合,以提高 LiDAR 分割的性能。
融合,以提高 LiDAR 分割的性能。
(融合后的信息指导 偏移 偏移负责选一些新的特征点出来 和之前的拼在一起)

3.3 细化阶段 Refinement Stage
细化阶段如图5所示。在粗特征提取阶段和偏移学习阶段之后,我们通过连接融合点图像特征![]() 图像和粗特征
图像和粗特征![]() 。然后,连接的特征 F 被送入 UNet 分割子网络以获得更准确的预测结果。为方便起见,在细化阶段,我们使用与粗特征提取阶段相同的分割子网络。
。然后,连接的特征 F 被送入 UNet 分割子网络以获得更准确的预测结果。为方便起见,在细化阶段,我们使用与粗特征提取阶段相同的分割子网络。

在训练时,我们使用语义分割损失 ![]() 来监督 LIF-Seg 的学习。语义分割损失
来监督 LIF-Seg 的学习。语义分割损失![]() 由两项组成,包括经典的交叉熵损失和 lovasz-softmax 损失 [53],分别用于最大化点精度和交叉联合分数。对于 III-B 小节中的偏移预测,以 nuScenes [4] 数据集为例,没有直接可用的偏移学习监督信息,因为对应于 LiDAR 点云的相机图像不提供像素级语义或实例注解。在这项工作中,我们利用辅助损失
由两项组成,包括经典的交叉熵损失和 lovasz-softmax 损失 [53],分别用于最大化点精度和交叉联合分数。对于 III-B 小节中的偏移预测,以 nuScenes [4] 数据集为例,没有直接可用的偏移学习监督信息,因为对应于 LiDAR 点云的相机图像不提供像素级语义或实例注解。在这项工作中,我们利用辅助损失![]() 来监督偏移学习。具体来说,对于属于前景类别的点,我们通过 L1 回归损失
来监督偏移学习。具体来说,对于属于前景类别的点,我们通过 L1 回归损失![]() 来约束它们学习的逐点偏移
来约束它们学习的逐点偏移![]() :
:
![]()
其中 m = {m1, . . . ,mN} 是二进制掩码。 mi = 1 如果点 i 在图像平面上的 2D 边界框内,否则 mi = 0。![]() 是点 i 所属的 2D 边界框的中心。因此,可以将
是点 i 所属的 2D 边界框的中心。因此,可以将![]() 表述如下:
表述如下:
![]()
其中g (i)将点i映射到包含点i的对应2D边界框的索引。 NB g (i)是2D边界框Bg (i)中的点数。 为了确保这些点在水平方向上朝向其对应的中心移动,我们利用方向损耗Ldir来约束预测的点偏移O的方向。在[33]之后, Ldir被公式化为减去余弦相似性的平均值:
![]()
因此,辅助损失可以被配方为![]() 。 我们的网络的训练目标是。
。 我们的网络的训练目标是。
![]()
α 是辅助细分损失的重量,并在我们的实验中设置为0.01。
(![]() ,sem就是语义分割损失,这里aux可以理解为偏移结构的损失,同样包含两部分。
,sem就是语义分割损失,这里aux可以理解为偏移结构的损失,同样包含两部分。![]() ,reg是位置,dir是方向。损失都是越朝着中心点损失越小这也是loss函数优化的方向)
,reg是位置,dir是方向。损失都是越朝着中心点损失越小这也是loss函数优化的方向)
4、实验
在本节中,我们评估了我们在 nuScenes [4] 数据集上的方法,以证明所提出的 LIFSeg 的有效性。在下文中,我们首先在第 IV-A 小节中简要介绍数据集和评估指标。然后,在第 IV-B 小节中提供了实施细节。随后,我们在第 IV-C 小节中展示了有关 LiDAR-相机融合的详细实验以及与 nuScenes 数据集上最先进方法的比较。最后,我们进行消融研究以验证 IV-D 小节中偏移学习的有效性。
4.1. 数据集和评估度量 Dataset and Evaluation Metric
新发布的 nuScenes [4] 数据集是用于 LiDAR 语义分割的大规模多模态数据集,收集了来自波士顿和新加坡不同地区的 1000 多个场景。场景分为 28,130 个训练帧和 6,019 个验证帧。带注释的数据集最多提供 32 个类。合并相似类并去除稀有类后,总共保留了 16 个用于 LiDAR 语义分割的类。数据集是使用 Velodyne HDL-32E 传感器、摄像头和雷达收集的,具有完整的 360 度覆盖范围。在这项工作中,我们使用来自所有 6 个相机的 LiDAR 点云和 RGB 图像。此外,该数据集在不同类别中存在不平衡挑战。特别是像汽车和行人这样的类是最常见的,而自行车和工程车辆的训练数据相对有限。此外,nuScenes 数据集具有挑战性,因为它是从不同的位置和不同的天气条件下收集的。 nuScenes 的点云密度也较低,因为传感器的光束数量较少,水平角分辨率较低。
为了评估我们提出的方法的LiDAR语义分割性能,将所有类别的平均交叉重合(mIoU)作为评估指标。 MIoU可以被配制为
![]()
其中 C 是类的数量,pij 表示从类 i 预测为类 j 的点数。
4.2 实施细节 Implementation Details
图像语义网络细节。对于图像语义分割子网络 DeepLabV3+ [10],它以 ResNet [54] 网络为骨干以生成步长为 16 的特征,并以 FCN [51] 分割头生成全分辨率语义特征 Fimage ∈ Rn×H× W×C1 ,其中 n = 6 是摄像机的数量, C1 = 16 是特征的维度。但是,nuScenes 上没有公开的分割预训练模型,因此我们使用 nuImages 2 数据集训练 DeepLabV3+ 1。 nuImages 由 10 万张带有语义分割标签的图像组成。请注意,所有 nuImage 类都是 nuScenes 的一部分。此外,nuImages的图像几乎不存在于nuScenes数据集的LiDAR点云对应的图像集中。
LiDAR网络详情:对于LiDAR点云分割粗细阶段的子网络,采用Cylinder3D [6]作为这两个阶段的子网络。 对于nuScenes数据集,圆柱形分区将LiDAR点云拆分为三维表示,大小为480 × 360 × 32 ,其中三维分别指示半径、角度和高度。 另外,粗糙特征Fcoarse的特征尺寸C0被设置为C0 = C ,其中C是类别的数量。 将图像上下文信息的窗口大小w设置为3。
4.3. 结果表现和分析Performance Results and Analyses
在本小节中,我们首先对 nuScenes [4] 数据集的验证集进行广泛的实验,以验证不同 LiDAR-相机融合策略的有效性,包括 LiDAR 与相机图像不同上下文之间的早期融合、中期融合LiDAR 点特征和图像语义特征之间的关系。之后,我们展示了与 nuScenes 数据集上最先进方法的比较。对于所有实验,我们采用重新训练的 DeepLabV3+ [10] 来提取图像特征,并采用 Cylinder3D [6] 作为 LiDAR 分割基线。为了更公平清晰的比较,我们使用作者在GitHub上发布的代码重新训练基线网络Cylinder3D 3 ,如果没有额外注释,我们使用相同的融合策略在所有模型中融合LiDAR和相机图像。
早期融合和中期融合。对于早期融合,LiDAR 点通过变换矩阵和相机矩阵投影到相机图像中。根据投影点的位置,我们可以查询1×1、3×3、5×5等窗口大小为w×w的图像的上下文信息。 w×w 上下文信息被重塑为向量并连接到相应的 LiDAR 点。将拼接后的点送入基线网络Cylinder3D得到分割结果,不同上下文信息融合的模型分别记为C+1×1、C+3×3和C+5×5。此外,DeepLabV3+获得的通道图像语义特征也被附加到每个LiDAR点以增强点特征(表示为C+Sem.)。此外,我们还在早期融合中融合了 3×3 图像上下文信息和图像语义特征(表示为 C+3×3+Sem.)。对于mid-fusion,图像语义特征通过连接(表示为C+Mid.)与基线网络获得的LiDAR点特征融合。融合的特征应用于两个卷积层以生成分割结果。此外,我们还基于中期融合方法C+Mid融合了早期的3×3图像上下文信息。 (表示为 C+3×3+Mid.)。最后,Cylinder3D也作为一个细化子网络来替代C+3×3+Mid中的两个卷积层。 (表示为 C+3×3+Mid.+Ref.)。
不同LiDAR-camera融合策略的LiDAR语义分割结果如表一所示。与基线方法Cylinder3D和C+1×1相比,我们可以看出直接融合LiDAR和图像信息可以提高LiDAR的性能语义分割。与早期融合方法 C+1×1、C+3×3 和 C+5×5 相比,由于融合图像上下文信息,C+3×3 获得了最好的 mIoU 分数。融合方法 C+1×1 缺乏上下文信息,限制了其识别细粒度模式的能力。融合方法C+5×5的上下文窗口尺寸过大,过多的冗余信息限制了中心点语义类别的识别。类似于 3D 检测器 PointPainting [46],早期融合方法 C+Sem。还可以提高 LiDAR 分割的性能。此外,障碍自行车公共汽车建筑摩托车行人交通锥拖车卡车可驾驶其他人行道地形人造植被 C+3×3+Sem。表明融合激光雷达点、图像上下文信息和语义特征可以有效提高语义分割的性能。融合方法C+Mid。和 C+3×3+中。由于缺少精心设计的 midfusion 模块,因此也略好于基线。 C+3×3+Mid.+Ref.的实验结果表明设计良好的中融合模块可以有效提高分割性能。这些实验结果表明,图像上下文信息和图像语义特征有助于 LiDAR 分割。在这项工作中,激光雷达点和图像上下文信息在粗阶段融合,点特征和对齐图像语义特征在细化阶段融合。
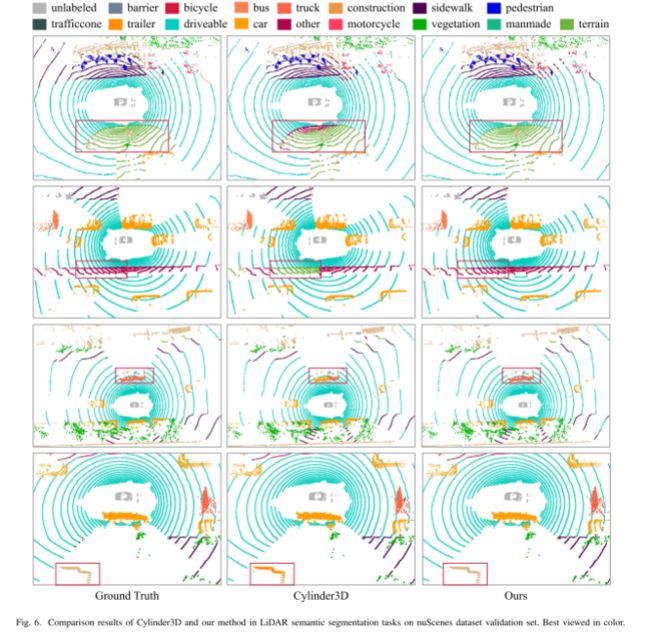
与 SOTA 方法的比较。在 [6] 之后,我们对 nuScenes [4] 数据集进行了实验,以评估我们方法的有效性。表 II 展示了在 nuScenes 验证集上的 LiDAR 语义分割结果。 RangeNet++ [27] 和 Salsanext [28] 执行后处理。从表二可以看出,我们提出的方法比其他方法取得了更好的性能,并且在许多类别中都处于领先地位。具体来说,所提出的方法优于 Cylinder3D [6] 2.1 mIoU。此外,与最先进的基于投影的方法(例如 RangeNet++ 和 Salsanext)相比,LIF-Seg 实现了大约 6% ∼ 12% 的性能增益。请注意,nuScenes 的点非常稀疏(35k 点/帧),尤其是自行车、摩托车、交通锥和行人等。因此,LiDAR 分割任务更具挑战性。从表 II 中,我们可以看出我们的方法在那些稀疏类别中明显优于其他方法,因为 LIF-Seg 通过粗到细的框架有效地融合了 LiDAR 点、相机图像上下文信息和图像语义特征。 LiDAR 分割的定性结果如图 6 所示。

4.4 消融实验
在本小节中,我们对 nuScenes [4] 数据集的验证集进行消融实验,以验证偏移学习的有效性。为了更公平和清晰的比较,如果没有额外的注释,我们对所有模型使用相同的配置和顺序融合策略。详细的消融实验结果列于表 III 中。我们从完整流水线 LIF-Seg 中删除了偏移学习阶段,这导致 LiDAR 分割的性能从 78.2 mIoU 下降到 77.6 mIoU。偏移预测结果如图 7 所示。从图 7 中,我们可以看到投影点在水平方向上向其对应的质心移动,这使得这些点尽可能多地落在实例对象上。这些结果证明了我们方法的有效性。
5结论
在本文中,我们提出了一个从粗到精的框架 LIFSeg,从两个方面提高 3D 语义分割性能,包括早期的低级图像上下文信息融合,以及通过解决弱点对齐的高级图像语义信息融合。 LiDAR 和相机之间的时空同步。 LIF-Seg 由三个主要阶段组成:粗略阶段、偏移学习阶段和细化阶段。在粗阶段,激光雷达点和低级图像上下文信息被融合并馈送到 UNet 子网络中以生成粗特征。通过图像分割子网络获得的粗特征和图像语义特征被融合以预测每个投影 LiDAR 点和图像像素之间的偏移。预测的偏移量用于对齐粗特征和图像语义特征。在细化阶段,粗特征和对齐的图像语义特征被融合并馈入 UNet 子网络以获得更准确的语义分割结果。 nuScenes 数据集上的广泛实验结果证明了我们方法的有效性。未来,可以将无监督学习方法添加到我们的 LIF-Seg 中,以预测 LiDAR 和相机之间的转换矩阵,以彻底解决弱时空同步问题,并进一步提高 LiDAR 分割的性能。
整理不易,求点赞~