架构之经典分层
架构之经典分层
上一篇:《IDDD 实现领域驱动设计-上下文映射图及其相关概念》
在《实现领域驱动设计》书中,分层的概念作者讲述的很少,也就几页的内容,但对于我来说,有很多的感触需要诉说。之前的短消息项目使用的就是经典分层架构,但那时候是:瞎子过桥,啥也不会,现在再回过头看,满眼惆怅,还请我娓娓道来~
1. 层的含义
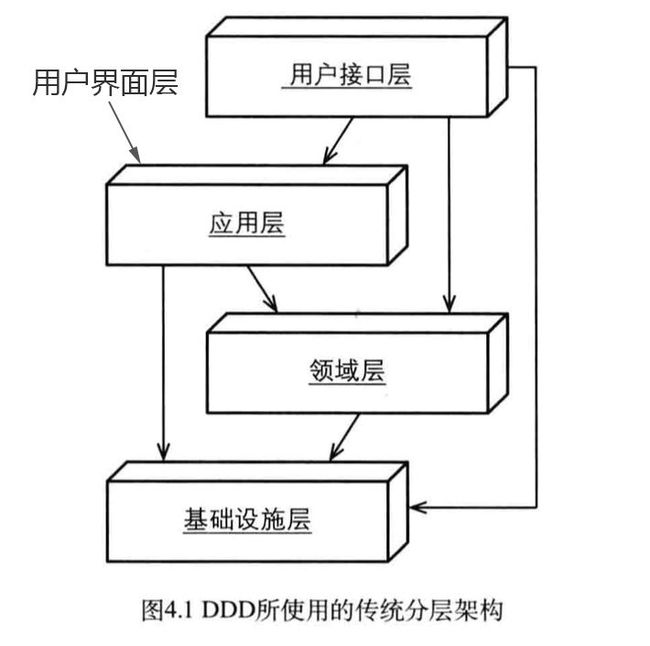
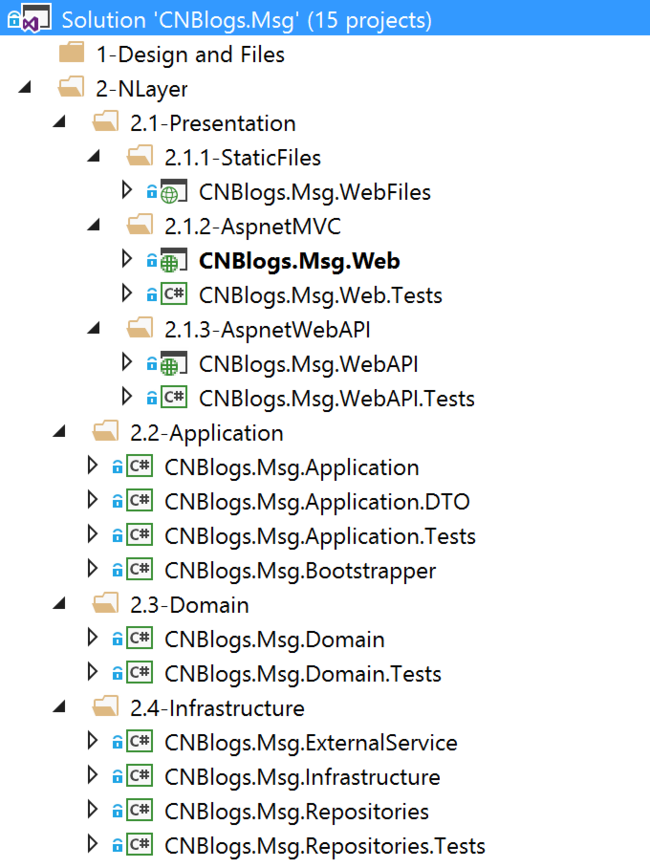
在第一张图中,用户界面层(User Layer)是我自作主张加上的,应用层的直接用户就是用户界面层,这里的用户界面层,也可以称之为表现层(Presentation Layer),上面箭头表示依赖关系,第二张是现在短消息项目的解决方案图(不是很完善),这两个图结合起来可以更加容易理解。
分层架构是所有架构的鼻祖,分层的作用就是隔离,不过,我们有时候有个误解,就是把层和程序集对应起来,就比如简单三层架构中,在你的解决方案中,一般会有三个程序集项目:UI.dll、BLL.dll 和 DAL.dll,然后把这三个程序集看成一个层,这没什么不可以,但当项目复杂的时候,如果还按照这种方式的话,你的程序集中的文件夹会越来越多,程序集也会越来越大。当你的视野跳出这个程序集的概念后,你会发现,层不只是和程序集对应,也和解决方案文件夹,或者是整个解决方案对应,一个层甚至可以对应一个系统,这个在之前的领域概念中可以对应理解,比如身份与访问通用子域,在不同的场景中,可以是一个独立的系统,也可以是项目中的一个通用组件。
关于层的概念,我再多说一点,因为之前了解过领域和限界上下文的概念,所以有些感触。首先,在开发人员眼里,一个业务系统的分层只是技术架构上的,所以,我们会把日志纪录、权限管理、数据库持久化、消息服务等等,把一些能分离出来的尽量分离出来,然后再把这些东西组合起来,我们一般称之为基础设施层,或者是系统帮助层,它们贯彻于整个业务系统,这些工作做完后,我们就会沿着“三层架构”的思想,再次进行分层,首先搭建 Web 层,然后是 BLL 和 DAL,可能名字有些差别(BLL 变成了 Application,DAL 变成了 Dao),解决方案中的项目可能很多(其实都是分离出来的),但如果你仔细分离项目,你会发现,其实还是三层架构,只不过在它基础之上,做了一些调整和完善。这时候,你看了一下自己的项目架构,然后觉得我是在胡说,我举一个例子,比如 Web 中一个简单的获取数据展示,调用 BLL 中的一个 GetDataById 方法,这个 BLL 对象,在 Web 层是通过 IoC 容器获取到的,所以 Web 只依赖于 IBLL,而不依赖 IBLL 的具体实现,然后你再看一下 BLL 中的 GetDataById 方法(名字一般不变),里面一般会有一些缓存处理、通知处理、日志处理、对象转换(DTO 映射)等等,但很少有一些业务处理,然后再调用 DAL 中的 GetDataById 方法,和 Web 层一样,也是通过 IoC 获取 IDAL 的对象,DAL 中的 GetDataById 方法实现,可以是 ADO.NET,也可以是 ORM,但看一下实现代码,你会发现你的真正业务一般会隐藏在这里面。
上面我说的是一个方法的调用过程,其他的也是类似,我说这么多是什么意思呢?就是你的思路会局限在一个解决方案中,或者是一个项目中,并且分层的概念也只是在一个解决方案,比如一个用户模块,这个在多个项目中一般会是通用的,而不必在每个项目中进行独立实现,还有缓存处理、日志处理、消息通知等等,这些都可以看作是领域概念中的通用子域,那么对这些通用模块该如何设计呢?在上一篇中,其实有提到这个,就是开放主机服务(Open Host Service),这是一种协议,可以是 REST 风格,除了这些通用模块,还有一些是其他项目中会用到本项目中的一些服务,比如一些本项目数据在其他项目中要进行展示,这个我们可以看下园子里的 Home 项目,它其实并不是一个“真正”的项目,而是一个各种服务“聚集地”,也可以看作是一个产品展览柜,里面包含有六七个项目,那如果我们在 Home 中分别这些涉及的项目进行实现,想想工作量会有多大,而且如果 Home 变更了,那这些工作都是白费的,那我们该如何设计会比较好呢?好的方式就是不在 Home 项目中进行实现,而是在涉及的本项目中实现,最好就是把这些抽离出来,分别在涉及项目中实现,比如一些数据获取操作,本项目和 Home 项目都会用到,然后把这些操作用服务的方式发布出来,这样 Home 就是一个各种服务调用者,涉及项目发布出来的服务也不仅仅只是针对于 Home,也可以用于其他项目,比如消息服务,可以用于各种项目的评论内容回复通知,这就是业务抽离的真正好处:以不变应万变,因为消息发布是不会变,但其他的业务系统是千变万化。
我再总结一下上面说的内容,当你开发一个项目的时候,一定要从一个大局观去看待这个项目,而不只是仅仅局限于本项目中,要了解这个项目所真正蕴含的业务,然后接下来的工作,就是尽可能的去抽离这些业务,这个工作难度可能很大,并且时间成本也很高,但是,当你开发越来越多项目的时候,你就会发现当时的设计是多么的有价值,从一个项目到十个项目,别人会感觉到越来越累,越来越辛苦,但对于你的感觉来说,是越来越轻松,因为原有业务的真正抽离,使得这些项目就像一个个汽车零件,当你研发一款新汽车的时候,由于有很多的汽车零件早已经完成,你所要做的工作,就是把这些汽车零件组装起来,然后涂装你喜欢的漂亮颜色(可以看作是 UI),一款崭新的新汽车这样轻易完成了。
上面只是一些想法,真正落实起来的难度非常大,也不仅仅是对个人的要求,而是要对整个团队的要求,有点“站着说话不腰疼”的意思。
2. 经典分层架构
不扯了,言归正传,先回顾一下经典分层中的概念:
- 表现层(Presentation Layer):接受用户输入和数据展示。
- 应用层(Application Layer):很薄的一层,只包含工作流控制逻辑,不包含业务逻辑。
- 领域层(Domain Layer):核心层,包含整个业务系统的业务逻辑。
- 基础设施层(Infrastructure Layer):提供整个业务系统的基础服务。
上面的概念,懂得领域驱动设计的都应该知道,这些是表面上的,那层的具体内部以及各层之间的联系该如何设计呢?这些内容很杂,而且也不好进行说明,因为没有统一的做法。除去层的概念,还有一些模块的概念需要理解,比如 Entity、Value Object、Domain Service、Repository、UnitOfWork、DTO 等等,在层中去运用这些模块也是一门学问,用的好,你的业务系统就很健壮,用的不好,你的业务系统就是一团乱麻,在经典分层架构设计之前,有两个基本概念需要牢记在心(依赖倒置原则-DIP):
- 高层模块不应该依赖于底层模块,两者都应该依赖于抽象。
- 抽象不应该依赖于细节,细节应该依赖于抽象。
还需要说明一点,在上面解决方案图中,你会发现有很多的 XXXX.Tests 项目,这是 XXXX 项目对应的单元测试项目,DDD 和 TDD 并不冲突,反而在 DDD 中,使用 TDD 有相辅相成的作用,关于这一点,就不再探讨,在这篇博文中有说明:一个简单业务用例的回顾和理解。
2.1 领域层(Domain Layer)

先说领域层,因为它是所有层中最重要的,也是核心层。
上面是短消息的领域层项目结构,你可以看作是最简单、最不完善的领域层。麻雀虽小,但五脏俱全,其中包含 Entity、Value Object、Domain Service、IRepository 等等,也就是说关于领域模型的设计都在领域层中,这是对于架构设计上来说的,对于整个的业务系统来说,领域模型本身和包含的模块是整个业务系统的核心,所有的业务逻辑都体现在领域模型中,所以,开发人员和领域专家会把更多的时间,去探讨领域模型该如何进行设计?
在短消息项目中,领域层就一个项目,但对于复杂性的业务系统来说,一个项目是远远不够的,比如 IDDD 中所说的 ProjectOvation 项目,整个领域就划分为敏捷项目管理核心域、协作子域和身份与访问通用子域,对于单个的核心域和通用子域来说,又可以划分成多个限界上下文,当然你也可以更加深入的细分这些模块,这些模块单个拿出来就比现在的消息领域层复杂的多,所以领域层不只是表面上那么简单,越多的子域和限界上下文,领域层实现起来就越复杂。
领域层、核心域、子域、限界上下文、类库项目、领域模型,这些概念并不是一一对应,关于他们之间的关系,我简单说一下自己的理解,领域层可以看作是很大,它对应的概念是整个领域(Domain),核心域和子域只不过是它的一部分,而限界上下文存在于核心域和子域,关于类库项目和领域模型,这个没办法判断,但一般来说,一个领域模型只会存在于一个类库项目中。
领域层的设计没办法进行概括,我说一下上面图中的一个设计不好的地方,在 DomainService、Repositories 文件夹中,其中的接口定义,应该放在独立的项目中,对于 Domain Service 来说,接口定义和实现都是在领域层中,可能没关系,但对于 Repository 来说,因为接口定义在领域层,实现在基础设施层,如果不使用依赖倒置,就会违背 DIP 原则的第一点,而且也会造成循环引用情况的发生。
根据上面第一张图中,我们可以得知,应用层依赖于领域层和基础设施层,领域层依赖于基础设施层,DIP 原则第一点:高层模块不应该依赖于底层模块,两者都应该依赖于抽象。也就是说层与层之间的关系应该依赖于抽象,如果把 Domain Service 和 Repository 的接口独立出来,这样应用层和基础设施层就只需要引用这些接口即可,反过来基础设施层的接口也一样。项目中所有的接口对象映射注入获取,都通过 IoC 进行管理,这是一个独立的项目,基本上会引用其他所有的项目,就是解决方案中的 Bootstrapper 项目。
2.2 基础设施层(Infrastructure Layer)

关于基础设施层,其实也没什么东西要说明,它和我们使用三层架构中的帮助类类似,其作用都是为这个项目提供最基础的服务,像一般的日志纪录、缓存处理、消息通知等等,都会放在基础设施层,它是唯一贯彻整个项目的一个层,表现层、应用层、领域层都要引用它,在最开始的那张图中就可以看出来。
除去一些基础服务,最具话题性的就是 Repository 实现,我记得之前写过不少博文去探讨它,找到相关的两篇:
你也可以看下最近的这个博问:
因为 Repository 的接口定义在领域层,所以有时候我们会把它和领域层挂钩,其实并没有什么关系,Repository 的含义就是仓储,领域模型对象的存取点,它只管存储,不管任何的业务逻辑,这个要首先明确,不要把之前的一些业务逻辑封装成一大串的 Where SQL 代码,这不是领域驱动设计所干的事。有人会说,为啥要把 Repository 的接口定义放在领域层?其实很简单,领域层要实现业务逻辑,必然要涉及到领域模型的对象存取(一般是实体对象),比如,我们在领域服务中定义一种业务行为,要对某个实体进行获取操作,这个我们一般会在上面创建这个实体涉及的 Repository 接口对象,创建方式通过构成函数注入,或者是用 Bootstrapper 进行管理,关于 Repository 的具体实现,领域层丝毫不关系,所以,在业务系统开发的最初阶段,开发人员和领域专家可以先进行领域层的设计,即使没有其他层的实现,领域层的设计也是可以照常进行的,我们一般采取的方式是,对 Repository 的实现用模拟对象方式,比如在 Repository 中定义一个集合的内存对象,然后对它进行一个存储操作,当领域层设计完成的时候,可以随时把 Repository 的实现替换掉,比如改成持久化的方式,对于这些操作,丝毫不会影响领域层的设计,因为它依赖的是 Repository 接口,而不是具体实现。
Repository 实现层只和两个层有关,一个是领域层,另一个就是应用层。对于 Repository 来说,领域层是它的上级,因为接口定义在它那边,应用层是它的客户,因为在它那边被使用。关于 Repository 的使用,又回设计到另一个东西,那就是工作单元(Unit Of Work),之前也写过关于它的一篇博文:
首先,UOW 和 EF 中的 Context 很类似,其实 Repository 中关于 UOW 接口定义的实现,就是 EF 中的 Context 操作,说白了就是偷懒省事。我再描述一下它的使用,有一个简单场景:应用层中的一个服务方法,要对多个 Repository 进行操作,而且要进行对象持久化,那具体该如何操作呢?我在上面那个博问中,贴了这样一段伪代码:
using (IRepositoryContext repositoryContext = new EntityFrameworkRepositoryContext()) { IContactRepository contactRepository = new ContactRepository(repositoryContext); IMessageRepository messageRepository = new MessageRepository(repositoryContext); .......... repositoryContext.Commit(); }IRepositoryContext 接口继承于 IUnitOfWork 接口,在 EntityFrameworkRepositoryContext 的具体实现中,对 UOW 进行了简单重写实现,用的就是 EF,所以,你可以把 repositoryContext 对象看作是 UOW,下面是 Repository 对象的创建,传递的是 UOW 具体实现,因为在一个 using 块中,所以,UOW 的生命周期可以跨 Repository 共享,那关于 Repository 中的 UOW 如何定义的呢?其实就是单例实现,也可以进行构造函数注入后进行单例,repositoryContext 访问的 Commit 操作,其实就是 IUnitOfWork 接口中进行定义的。关于 Repository 的内部实现,在上面 UOW 那篇博文中的一张图中有详细说明,就不多说了。
2.3 应用层(Application Layer)
关于应用层的设计,其实,给我印象最深的是这一篇博文:
如果你的领域层设计的不好,最直接的反应就是在应用层中,所以,检验你领域驱动设计的好坏,不需要看你的领域层怎么设计的?只需要看应用层的实现代码就行了,为什么?因为领域层的直接客户就是应用层,应用层和三层架构中的 BLL 并不一样,BLL 是业务逻辑层,而应用层只是管理工作流程的进行,它和业务逻辑不挂边,因为它在业务系统中的职责较小,所以,应用层很薄,在上面那篇博文中,贴出了一段发送短消息的应用层代码,一看那么长,就知道肯定有问题,这个就不分析了,在那篇博文中有详细的探讨。
我们来看一段标准的应用层代码:
namespace SaaSOvation.AgilePM.Application.Sprints
{
public class SprintApplicationService { public SprintApplicationService(ISprintRepository sprintRepository, IBacklogItemRepository backlogItemRepository) { this.sprintRepository = sprintRepository; this.backlogItemRepository = backlogItemRepository; } readonly ISprintRepository sprintRepository; readonly IBacklogItemRepository backlogItemRepository; public void CommitBacklogItemToSprint(CommitBacklogItemToSprintCommand command) { var tenantId = new TenantId(command.TenantId); var sprint = this.sprintRepository.Get(tenantId, new SprintId(command.SprintId)); var backlogItem = this.backlogItemRepository.Get(tenantId, new BacklogItemId(command.BacklogItemId)); sprint.Commit(backlogItem); this.sprintRepository.Save(sprint); } } }上面的代码摘自 SprintApplicationService.cs,这段代码的含义就是提交待定项到冲刺,这个业务用例的工作流程很好的在 CommitBacklogItemToSprint 方法中进行了体现,首先,通过 backlogItemRepository 和 sprintRepository 分别获取待定项对象和冲刺对象,Repository 的创建方式就是通过构造函数获取,下面最关键的一段代码是 sprint.Commit(backlogItem);,这是领域层中的内容,应用层不管其如何实现,它只管调用提交待定项到冲刺这个操作,也就是纯粹的流程控制,然后再对操作完成的对象进行持久化,就这么简单,如果在个操作中有很多冗余的操作,和我一样,那就是失败的!
2.4 表现层(Presentation Layer)
关于表现层,其实没有什么好说的,就是应用程序展现的一个东西,可以是 Web 应用程序,也可以是桌面应用程序、也可以是一个服务等等。它是与用户打交道的窗口,也接受用户反应的信息,在这其过程中,就必然设计到数据的传递,那如何传递呢?使用 MVC 中的 View Model?在一般的 Web 应用程序中,可以使用 View Model,但对于领域驱动设计来说,最好的方式是使用 DTO,关于具体的相关信息,可以查看这个博文分类列表(共八篇):
我再补充一下 DTO 的使用,在一开始的解决方案图中,我们可以看到,DTO 项目的位置,是处在应用层中,而且被独立出来,其实,我一开始设计是没独立的,和应用服务方法放在同一个项目中,但是后来我遇到了一个问题:在应用层中,Repository 获取的是领域模型对象(实体对象),如果是集合形式的,而且这个领域模型对象非常的庞大,而应用服务方法里面只需要领域模型对象的一部分属性,这就会造成一些不必要的性能开销,因为 DTO 是按照表现层和应用层设计的,所以它有一定的针对性,能不能按照 DTO 的设计,进行领域模型对象的获取呢?其实,实现很简单,就是使用 AutoMapper 的 Project.To() 操作,按需来获取属性对象,但这个实现是在 Repository 内部的,而应用层当时引用的是 Repository 层,如果 Repository 层再进行引用 应用层,就会造成循环引用,最后的改变就是把 DTO 独立出来,然后供应用层、Repository 层和表现层调用。
上面解决方式看似没有什么问题,但这种为了解决性能问题,而造成 Repository 的一些破坏,其实是有悖架构设计的,因为 Repository 的含义就是领域模型对象的存储,它其实是和 DTO 没半毛钱关系,另外,还有一个严重问题是,因为 Repository 的接口定义在领域层,而有些方法签名返回的是领域模型对象,但实现返回的却是 DTO 类型对象,这就造成了对领域层的破坏,一个看似小小的 DTO 问题,如果不进行好的设计和处理,就会像“一粒老鼠屎,坏了一锅粥”这样严重。
上面只是一个问题实例,经过实践后,你会发现,经典分层架构并不是万能的,它也存在一些缺陷,其实,使用 CQRS(命令和查询职责分离)架构,就可以很好的解决上面的问题,领域驱动设计并不只有经典分层架构,你需要打开视野,接受新鲜事物,未完待续~~~
经受我如唐僧一般的啰嗦和折磨,如果你还能坚持看到这,我打算再送你一曲《Only You》:
- only you can take me 取西经
- only you 能杀妖精鬼怪
- only you 能保护我
- .......