线性回归之原理介绍
线性回归是研究平均意义下变量与变量之间的定量关系表达式
线性回归损失函数一般是均方误差(MSE)
求解线性回归参数通常有最小二乘法和梯度下降法
最小二乘法的几何意义是高维空间中的一个向量在低维子空间的投影
最小二乘法与noise为高斯分布的最大似然估计等价
L1正则化通过稀疏化(减少参数数量)来降低模型复杂度的(参数值可减小到0)
L2正则化通过减少参数值大小来降低模型复杂(参数值永远不会减小到0)
线性回归关系表达式
这节我们来对线性回归算法做一个介绍。为了适应一般性情况,直接从多元线性回归说起。
回归分析处理的是变量与变量间的关系。常见的关系有两种:确定性关系和相关关系。我们知道,变量间的相关关系不能用完全确定的函数形式表示,但在平均意义下有一定的定量关系表达式,寻找这种关系表达式就是回归分析的主要任务。
设y与x间有相关关系,称x为自变量(预报变量),y为因变量(响应变量),在知道x取值后Y的条件密度函数p(y|x),对于y的均值E(Y|x),有:
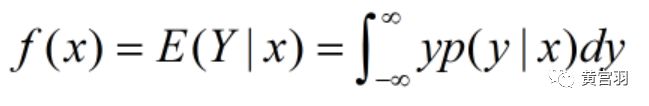
这是第一类回归问题,是在x与y均为随机变量场合进行的。
实际中,自变量x是可控变量,只有y是随机变量,它们之间的相关关系为:
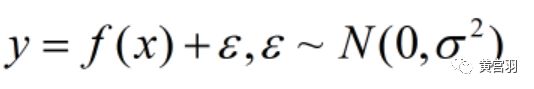
这是第二类回归问题。通常情况下,研究的是此类回归问题。
y关于x的多元线性回归数据结构式为:
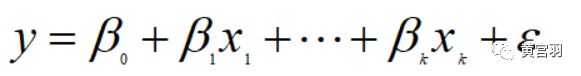
式中的ϵ称为噪声项,表示没被已有数据捕捉到的随机变动因子,对于噪声项可以这么理解:我们对y的预测是不可能达到与真实值完全一样的,这个真实值只有上帝知道,因此必然会产生误差,我们就用ϵ来表示这个无法预测的误差。
接下来的问题是要如何定义这个无法预测的误差项呢?在统计学中,高斯-马尔可夫定理陈述的是:在误差零均值,同方差,且互不相关的线性回归模型中,回归系数的最佳无偏线性估计(BLUE)就是最小方差估计。
因此,翻译为数学语言就是,线性回归分析有以下假设:
(1)误差项ϵ是一个期望为0的随机变量,即E(ϵ)=0
(2)对于自变量的所有值,ϵ的方差σ^2都相同
(3)误差项ϵ是一个服从正态分布的随机变量,且相互独立,即ϵ~N(0,σ^2)
有了这个假设,我们只需要求解里面的参数,就可以对新的样本进行预测。那么,怎么求解参数呢。
我们知道,既然模型最后的目的是为了预测的因变量y与实际的y越接近越好,也就是要优化如下式子:
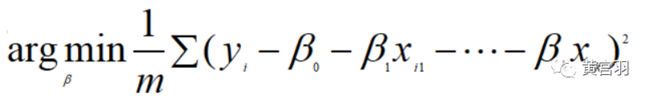
这个就是均方误差(MSE)损失函数,为什么要取个平方呢,是为了使得其为凸函数,那么就能保证其一定有最小值,进而能求解参数。
求解上面最优化问题通常有最小二乘法和梯度下降法,下面分别介绍。
2.最小二乘法(OLS)
损失函数分别对参数求导并令其等于0,有:
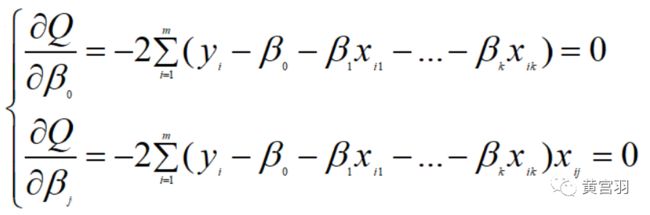
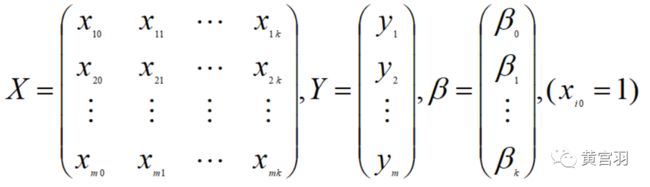
若记,
则上式可以用矩阵形式表示:
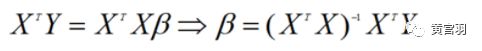
这样,我们就求得了线性回归的参数。
但对于最小二乘法的理解还不能止步于此,我们做一个深入拓展。
a.最小二乘法的几何意义是高维空间中的一个向量在低维子空间的投影
这里的高维空间的一个向量,就是因变量真实值构成的向量Y=(y1,y2,...,ym)。我们的目的就是去拟合Y,实际情况不可能完美拟合,拟合的本质使得最小化损失函数,也就是向量Y在X列向量的构成的空间上投影,而投影就是X列向量的一个线性组合,这个组合就是参数向量B.
因此,(Y-XB)向量和X每一个列向量都垂直,根据内积定义有:
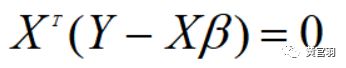
化简后得:
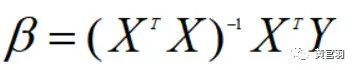
这就是最小二乘法的几何意义。
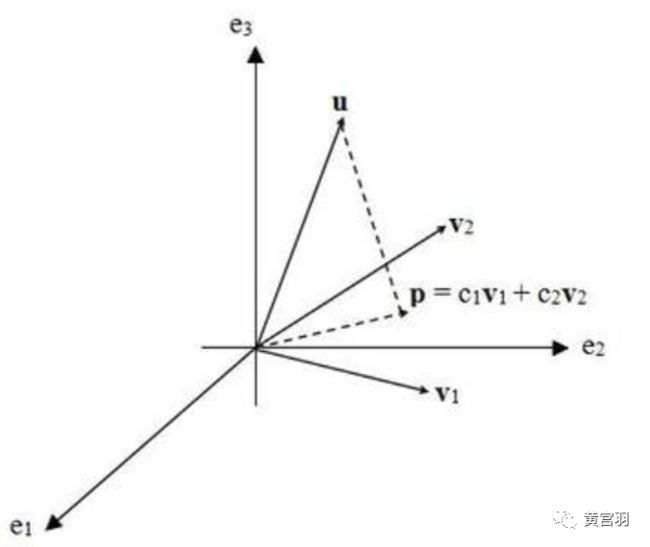
给出一张图更加直观:u为因变量,v1和v2是两个自变量,c1和c2就是求解的参数,p为预测的因变量
b.最小二乘法与noise为高斯分布的最大似然估计等价
根据前面的假设ϵ~N(0,σ^2),我们用最大似然估计来求解参数。
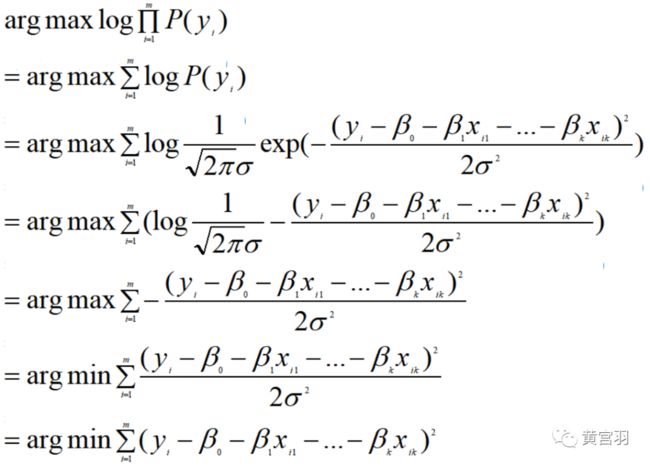
可见,最后优化的函数与损失函数MSE一致。因此最小二乘法与noise为高斯分布的最大似然估计等价。
c.最小二乘法局限性
首先,观察到,最小二乘法需要计算矩阵的逆矩阵,但并非所有矩阵都存在逆矩阵(充要条件是矩阵的行列式不为0,也就是矩阵的秩为满秩),这种情况仍然可以通过对样本数据进行处理,去掉冗余特征,让矩阵可逆
其次,计算逆矩阵耗时费力,如果样本特征非常大,几乎无法求解。此时仍然可以通过降维方法降低维度。
最后,如果拟合函数非线性的,也无法使用最小二乘法。
3.梯度下降法
梯度下降法是另外一种求解线性回归参数的方法,同时能弥补最小二乘的局限性。也就是当逆矩阵不存在、特征数过大、拟合函数非线性时,梯度下降法仍可用。梯度下降法不仅仅适用于线性回归,而且有很多衍生方法,如批量梯度下降。以后会专门针对梯度下降出一期文章。这里只给出以线性回归为例的梯度下降求解步骤。
step1:确认模型损失函数
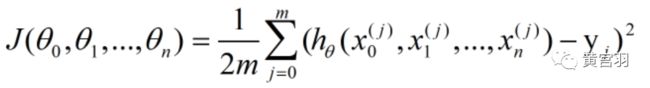
step2:初始化相关参数,主要是初始化θ0,θ1...,θn,算法终止距离ε以及步长α
step3:以初始化参数θi开始,利用梯度更新所有θi:
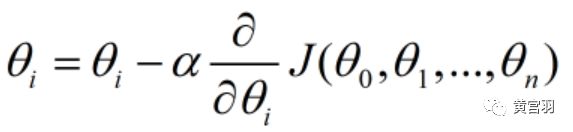
step4:确定是否所有的θi,梯度下降的距离都小于ε,如果小于ε则算法终止,当前所有的θi(i=0,1,...n)即为最终结果.否则重复step3。
梯度下降注意的地方:
初始值不同,获得的最小值也有可能不同,因此梯度下降求得的只是局部最小值;当然如果损失函数是凸函数则一定是最优解。
对数据进行归一化处理能提高收敛速度
4.正则化(L1&L2)
模型一般会出现过拟合情况,所谓的过拟合,就是模型过度拟合了训练样本,而在测试集上性能很差(关于过拟合以后也会专门出文章讲解)。
为了防止过拟合,一般有三种处理办法:
1.增加数据量
2.简化模型(特征筛选或特征提取)
3.正则化
这里我们对正则化做一个深入的拓展。
所谓正则化,就是通过对模型参数进行调整(数量和大小),降低模型的复杂度,以达到可以避免过拟合的效果。
机器学习主要有L1正则和L2正则,这也是线性回归和逻辑回归等算法运用最广泛的两个。在回归模型中,我们一般把的带有L1正则化项的回归模型叫做LASSO回归,而把带有L2正则化项的回归叫做岭回归:
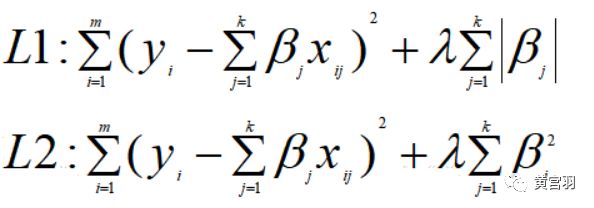
加入正则化以后,不再是最小化损失函数了,而是变成以最小化损失和复杂度为目标了,这个称为结构风险最小化。
正则项前面的系数称为惩罚系数。这个惩罚系数是调节模型好坏的关键参数,我们通过两个极端的情况说明它是如何调节模型复杂度的。
* λ值为0:损失函数将与原来损失函数一样(即最小二乘估计形式),说明对参数权重β没有任何惩罚。
* λ为无穷大:在惩罚系数λ无穷大的情况下,为保证整个结构风险函数最小化,只能通过最小化所有权重系数β达到目的了,即通过λ的惩罚降低了参数的权重值,而在降低参数权重值的同时我们就实现了降低模型复杂度的效果。
正则项的几何意义
先来看L2正则,观察损失函数,其实相当于一个约束问题,
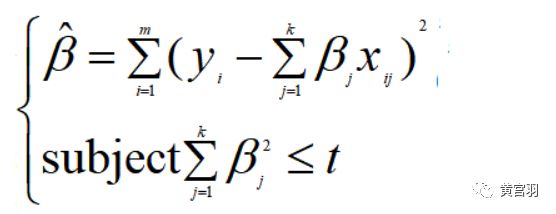
这时候,我们相当于拆分了原来的结构化风险函数,目标就转换为:最小化原来的训练样本误差,但是要遵循β平方和小于t的条件。
我们来看只有两个参数下的情况更易于理解:
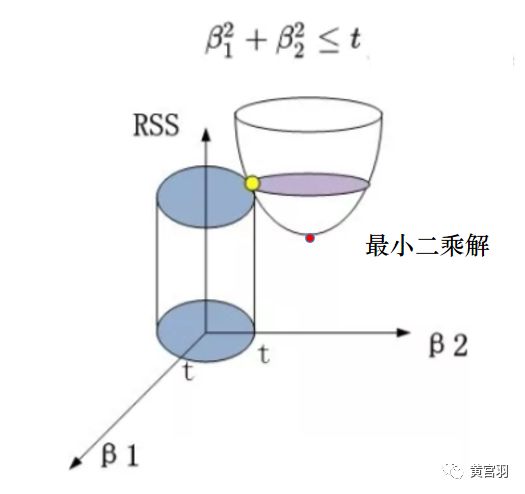
不加约束条件,最小二乘解在红色处最优,加入了正则条件,在给定t下,黄色点处最优。这里的t 和 λ 是成反比的,也就是说t越小,惩罚程度越大。
因此,如果我们减小t,圆柱体就会向内缩,导致与漏斗的交点向上移动,而向上移动的同时 β1 和 β2 的值也在减小,即达到了降低参数权重的效果。但是随着向上移动,结构化风险函数的值也越来越大了,趋于欠拟合的方向,这也就揭示了为什么说要选择一个合适的惩罚系数了。
理解L2正则的几何意义,L1正则也类似,只不过将平方换成了绝对值,也就是约束条件不再是一个圆柱,而是一个长方体。我们画出等高线可以一目了然做个对比。
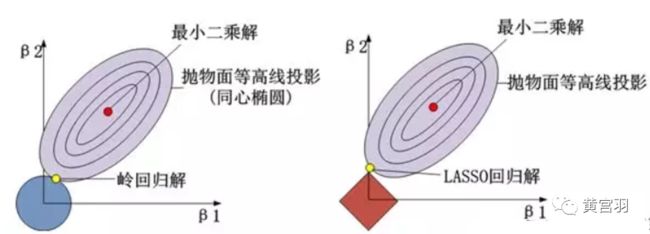
L1正则化:通过稀疏化(减少参数数量)来降低模型复杂度的,即可以将参数值减小到0。
L2正则化:通过减少参数值大小来降低模型复杂的,即只能将参数值不断减小但永远不会减小到0。
岭回归中两个图形(没有棱角)的交点永远不会落在两个轴上,而LASSO回归中,正则化的几何图形是有棱角的,可以很好的让交点落在某一个轴上。这种稀疏化的不同也导致了LASSO回归可以用于特征选择(让特征权重变为0从而筛选掉特征),而岭回归却不行。
此外,L1和L2在下降速度上也不一样,最开始的时候岭回归下降的非常快,但是随着值越来越小,岭回归下降速度也越来越慢,当快接近0的时候,速度会非常慢,即很难减小到0。相反,LASSO回归是以恒定的速度下降的,相比于岭回归更稳定,下降值越接近近0时,下降速度越快,最后可以减小到0。
拓展:
加入L2正则后,最小二乘法的矩阵表达式为:
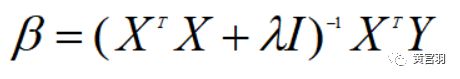
这里,对称矩阵加上一个对角化矩阵后,必定为一个正定矩阵,因此行列式不为0,矩阵可逆。
参考资料:
《概率论与数理统计(理工类第四版)》
《概率论与数理统计教程第二版》
https://mp.weixin.qq.com/s/Q-UNFXIUeW3IcquaNGx1UQ