全连接神经网络与3层神经网络搭建 2022-1-11
人工智能基础总目录
深度神经网络
- 一、概念说明
-
- 1.1 各种激活函数优缺点
- 1.2 拓扑排序
- 1.3 初始化原则与说明
- 1.4 优化器介绍
-
- 1 Gradient with momentum
- 2 RMS-prop (Root mean square prop)
- 3 ADAM
- 二、3层神经网络搭建
- 三、物体分类模型训练
-
- 1 下载数据
- 2 图片进行可视化展示
- 3 神经网络搭建
- 4 模型训练
- 5 模型测评
1、前向传播,反向传播作用是什么?
2、训练出模型,去预测,预测时候需要求Loss么? 需要做反向传播么?
3、求Loss 对wi 的偏导, 需要进行反向传播,前面一定需要前向传导求出估计值。
4、激活函数的作用是什么?
5. 什么是梯度下降,什么是随机梯度下降(SGD)?
6. 神经网络的拓扑排序是什么?
一、概念说明
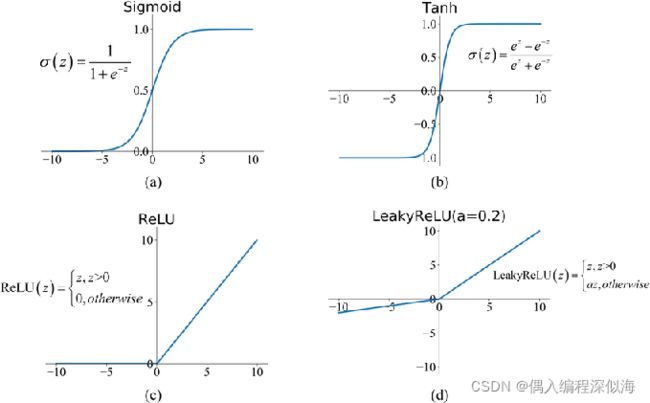
1.1 各种激活函数优缺点
因为神经网络中每一层的输入输出都是一个线性求和的过程,下一层的输出只是承接了上一层输入函数的线性变换,如果没有激活函数,最后的输出都是输入的线性组合,纯粹的线性组合并不能够解决更为复杂的问题。而引入激活函数之后,我们会发现常见的激活函数都是非线性的,因此也会给神经元引入非线性元素,使得神经网络可以逼近其他的任何非线性函数。
通常具有以下几点性质:
- 连续并可导(允许少数点上不可导),可导的激活函数可以直接利用数值优化的方法来学习网络参数;
- 激活函数及其导数要尽可能简单一些,太复杂不利于提高网络计算率;
- 激活函数的导函数值域要在一个合适的区间内,不能太大也不能太小,否则会影响训练的效率和稳定性。
-
sigmoid
0-1 处处可导,缺点: exp 指数运算费时,平均值在0.5左右。我们期望均值在0附近。比较好做梯度下降。 -
Tanh: 均值在0左右。 缺点:绝大多数 Loss 等于0(wi 不会更新)。
-
ReLu: 可导的部分增大了。(常用)
1.2 拓扑排序
拓扑排序在深度学习中的作用,为了能够链式求导。
TensorFlow 在train 之前将拓扑排序建立好, torch 一边train一边计算链式求导。
1.3 初始化原则与说明
- 初始化的全部参数不能0,否则梯度等均为0,无法继续进行。
- 我们期望的初始化的参数服从, 正态分布,均值0。同时X 维数越大,初始化参数越小,维度越高计算的梯度会越大。

1.4 优化器介绍
1 Gradient with momentum
类似动量的的增加,减少波动的情况。
- 基本的梯度下降公式
- 在变化的基础上增加上一次的变化量,减少变化的波动。

2 RMS-prop (Root mean square prop)
相比第一种,没有动量的增加。但是能够自动的调整变化的比率系数。

3 ADAM
将 Gradient with momentum 和 RMS-prop 的方法结合。

二、3层神经网络搭建
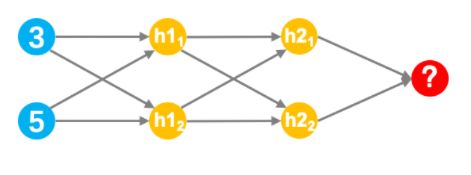
展示的是一个简单的神经网结构,它由一个输入层(蓝色)、两个隐藏层(黄色)和一个输出层(红色)组成。 通过代码实现说明
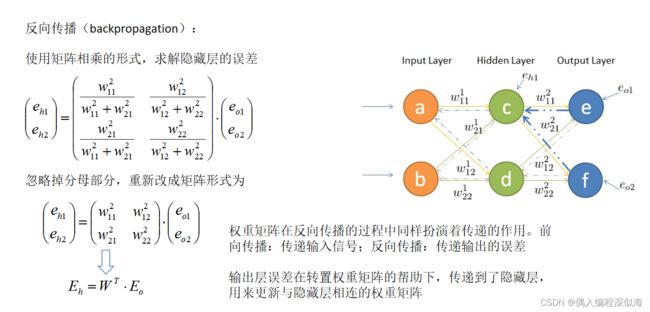
权重举证在前向传导与反向传播中的作用。
输入的值为[3,5]
隐藏层h1的两个权重为[2,4]、[4,-5]
隐藏层h2的两个权重为[-1,1]、[2,2]
输出层的权重为[-3,7]
所有层不使用偏置
所有隐藏层需添加tanh激活函数
请定义一个numpy数组,内容为神经网络的输入数据
# 基础运算库
import numpy as np
# 深度学习库
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torch.nn.functional as F
import torchvision.transforms as transforms
# 辅助绘图库
import matplotlib.pyplot as plt
# 时间操作库
import time
# 进度条控制库
from tqdm import tqdm
# 输入数组实现
input_array = np.array([3,5])
# 权重字典
weights = {'h11': np.array([2,4] ),
'h12': np.array([4,-5] ),
'h21': np.array([-1,1] ),
'h22': np.array([2,2] ),
'out': np.array([-3,7] )}
# tanh激活函数
def tanh(x):
return (np.exp(x) - np.exp(-x)) / (np.exp(x) + np.exp(-x))
# 逐层计算神经网络输出
hidden_11_value = tanh(input_data * weights['h11']).sum()
hidden_12_value = tanh(input_data * weights['h12']).sum()
hidden_1_output = np.array([hidden_11_value, hidden_12_value])
hidden_21_value = tanh(hidden_1_output * weights['h21']).sum()
hidden_22_value = tanh(hidden_1_output * weights['h22']).sum()
hidden_2_output = np.array([hidden_21_value, hidden_22_value])
#将上层输出的数据与输出层的权重相乘、求和
output = (hidden_2_output * weights['out']).sum()
# 注:output应为9.887385002294863
三、物体分类模型训练
CIFAR-10数据集是图像分类任务中最为基础的数据集之一,它由60000张32像素*32像素的图片构成,包含10个类别,每个类别有6000张图片。其中50000张图片被划分为训练集,10000张为测试集。
1 下载数据
##定义对图像的各种变换操作,包括把array转换为tensor,对图像做正则化
#transforms.Compose主要是用于常见的一些图形变换,例如裁剪、旋转
#遍历list数组,对img依次执行每个transforms操作
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.4914, 0.48216, 0.44653),
(0.24703, 0.24349, 0.26159))])
#导出torchvision里的CIFAR10数据集,root是把数据下载之后存放的目录,train控制是不是在训练阶段,download控制是不是需要下载,transform把一系列的图像变换传入进来。
trainset = torchvision.datasets.CIFAR10(root='/data/course_data/AI/AI_homework_6/',
train=True,
download=True,
transform=transform)
testset = torchvision.datasets.CIFAR10(root='/data/course_data/AI/AI_homework_6/',
train=False,
download=True,
transform=transform)
#用来把训练数据分成多个小组,此函数每次抛出一组数据。
trainloader = torch.utils.data.DataLoader(trainset,
batch_size=16,
shuffle=True)
#用来把测试数据分成多个小组,此函数每次抛出一组数据。
testloader = torch.utils.data.DataLoader(testset,
batch_size=16,
shuffle=False)
# 简单查看数据label, 对应分类的10个类别
trainset.classes
2 图片进行可视化展示
#把图片进行可视化展示
#定义画图的函数
def imshow(inp, title=None):
"""Imshow for Tensor."""
#定义画图的画布
fig = plt.figure(figsize=(30, 30))
#转换图片的纬度
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
#对图片进行标准化
inp = std * inp + mean
#整个图片数组的值限制在指定值a_min,与a_max之间
inp = np.clip(inp, 0, 1)
#对图片进行可视化展示
plt.imshow(inp, )
# 获取一个batch的数据
inputs, classes = next(iter(trainloader))
# 以网格的格式展示,作用是将若干幅图像拼成一幅图像
out = torchvision.utils.make_grid(inputs)
# plt.imshow()就可显示图片同时也显示其格式。
imshow(out, title=[trainset.classes[x] for x in classes])
3 神经网络搭建
数据准备就绪后,就需要你来搭建一个简单神经网络。输入维度是32*32*3,第一层输出维度是1000,第二层输出维度是500,第三层输出维度是10。
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
######## your code ########
self.fc1 = nn.Linear(32*32*3,1000 )
self.fc2 = nn.Linear(1000,500 )
self.fc3 = nn.Linear(500,10)
######## your code ########
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
return self.fc3(x)
#实例话神经网络的类
net = Net()
在定义好模型结构之后,还需确定损失函数及优化器。
# 定义损失函数-交叉熵
criterion = nn.CrossEntropyLoss()
# 定义优化器,将神经网络的参数都传入优化器,并定义学习率
optimizer = optim.Adam(net.parameters(), lr=3e-4)
4 模型训练
模型主要内容都已完成,下面就可以进行训练了。在模型训练过程中,一般遵循如下步骤:
大for循环-epochs,用于管理一套数据循环训练几遍
小for循环-step,用于以batchsize为单位,从dataloader中调取数据
清空优化器的梯度
读入data和label,并进行形状变换(可做可不做)
运行模型前向传播过程
基于模型输出生成最终结果
计算损失
基于损失计算梯度
基于梯度更新参数
num_epochs = 10
since = time.time()
net.train()
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch + 1, num_epochs))
running_loss = 0.0
running_corrects = 0
# 从trainloader里循环取出每一批次数据,
for data in tqdm(trainloader):
######## your code ########
inputs, labels = data
inputs = inputs.view(-1, 32 * 32 * 3)
optimizer.zero_grad() # 用于清空优化器梯度
outputs = net(inputs) # 用于模型前向传播
_, preds = torch.max(outputs, 1) # 用于生成最终输出结果
loss = criterion(outputs, labels) # 用于计算损失
loss.backward()
optimizer.step() # 用于参数更新
######## your code ########
# 一个批次数据的损失函数的计算
running_loss += loss.item() * inputs.size(0)
# 一个批次数据准确率的计算
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / trainloader.dataset.data.shape[0]
epoch_acc = running_corrects.double() / trainloader.dataset.data.shape[0]
print('train Loss: {:.4f} Acc: {:.4f}'.format(
epoch_loss, epoch_acc))
print('-' * 10)
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
5 模型测评
correct, total = 0, 0
net.eval()
for data in tqdm(testloader):
######## your code ########
inputs, labels = data
inputs = inputs.view(-1, 32 * 32 * 3)
outputs = net(inputs)
######## your code ########
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('The testing set accuracy of the network is: %d %%' % (100 * correct / total))