人工智能 ----- 深度学习篇之tensorflow(1)
深度学习篇之tensorflow
- 前言
- 手写数字识别
-
- 数据集简介
- mnist数据展示
- 将mnist数据集中第一张图片逐个像素读取放入csv文件
- 手写数字识别实战
-
- Estimator
-
- 常用内置的Estimator简介
- tf. estimator.DNNClassifier(深层神经网络算法)介绍
- 实战代码及其分析
- 使用tensorboard对过程进行可视化
- 寻找最优模型
前言
环境的配置详见我的这篇博客:安装tensorflow
切记:下边的过程记得先将自己创建的虚拟环境进行激活才能在新的虚拟环境下进行操作。
基于的tensorflow版本是1.6版本的,如果代码运行错误的话可以检测一下自己虚拟环境中的tensorflow版本是什么。错误类似(AttributeError: module ‘tensorflow_core._api.v2.train’ has no attribute ‘Optimizer’,tensorflow报错)
- tensorflow版本不对卸载重新安装:
pip uninstall tensorflow - 然后重装的1.6.0,没有再报这个错误.:
pip install tensorflow==1.6.0
同时,基于的python环境是3.6的,如果出现类似这样的错误:protobuf requires Python ‘>=3.7‘ but the running Python is 3.6.5的解决方法。
解决办法:更新pip
更新命令:python -m pip install --upgrade pip
手写数字识别
数据集简介
MNIST(Modified National Institute of Standards and Technology,MNIST)是一个大型手写数据库,来源是美国国家技术与标准研究院(NIST)数据库。原来的NIST数据库中的训练数据的书写者是美国人口普查局的员工,而测试数据集的来源是美国高中生,因此NIST数据集不太适合机器学习的初学者。
因此,MNIST将NIST中的训练数据和样本数据混合起来,将图片的大小归一化,将所有的手写数字图片都整理为28×28像素。同时,将数字居中对齐,使得数字部分集中在20×20像素范围,并且手写笔迹部分只保留单色,也就是黑白色。因此,MNIST数据库非常适合机器学习的初学者使用。
MNIST的官方网址: http://yann.lecun.com/exdb/mnist/ 。
mnist数据展示
#!/usr/local/bin/python3
# -*- coding: UTF-8 -*-
import os
import struct
import numpy as np
import urllib.request
from matplotlib import pyplot as plt
import gzip
# 以上部分是整个模型引用的软件包
'''
读取mnist数据文件。如果本地文件不存在,则从网络上下载并且保存到本地。
:param data_type: 要读取的数据文件类型,包括"train"和"t10k"两种,分别代表训练数据和测试数
据。
:Returns: 图片和图片的标签。图片是以张量形式保存的。
'''
def read_mnist_data(data_type="train"):
img_path = ('./mnist/%s-images-idx3-ubyte.gz' % data_type)
label_path = ('./mnist/%s-labels-idx1-ubyte.gz' % data_type)
# 如果本地文件不存在,那么,从网络上下载mnist数据
if not os.path.exists(img_path) or not os.path.exists(label_path) :
# 确保./mnist/目录存在,如果不存在,就自动创建此目录
if not os.path.isdir("./mnist/"):
os.mkdir("./mnist/")
# 从网上下载图片数据,并且,保存到本地文件
img_url = ('http://yann.lecun.com/exdb/mnist/%s-images-idx3-ubyte.gz' % data_type)
print("下载:%s" % img_url)
urllib.request.urlretrieve(img_url, img_path)
print("保存到:%s" % img_path)
# 从网上下载标签数据,并且保存到本地
label_url = ('http://yann.lecun.com/exdb/mnist/%s-labels-idx1-ubyte.gz' % data_type)
print("下载:%s" % label_url)
urllib.request.urlretrieve(label_url, label_path)
print("保存到:%s" % label_path)
# 使用gzip读取标签数据文件
print("\n读取文件:%s" % label_path)
with gzip.open(label_path, 'rb') as label_file:
# 按照大端在前(big-endian)读取两个32位的整数,所以,总共读取8个字节
# 分别是magic number、n_labels(标签的个数)
magic, n_labels = struct.unpack('>II', label_file.read(8))
print("magic number:%d,期望标签个数:%d 个" % (magic, n_labels))
# 将剩下所有的数据按照byte的方式读取
labels = np.frombuffer(label_file.read(), dtype=np.uint8)
print ("实际读取到的标签:%d 个" % len(labels))
# 使用gzip读取图片数据文件
print("\n读取文件:%s" % img_path)
with gzip.open(img_path, 'rb') as img_file:
# 按照大端在前(big-endian)读取四个32位的整数,所以,总共读取16个字节
magic, n_imgs, n_rows, n_cols = struct.unpack(">IIII", img_file.read(16))
# 分别是magic number、n_imgs(图片的个数)、图片的行列的像素个数
#(n_rows, n_cols )
print("magic number:%d,期望图片个数:%d个" % (magic, n_imgs))
print("图片长宽:%d × %d 个像素" % (n_rows, n_cols))
# 读取剩下所有的数据,按照 labels * 784 重整形状,其中 784 = 28 × 28 (长×宽)
images = np.frombuffer(img_file.read(), dtype=np.uint8).reshape(n_imgs, n_rows, n_cols)
print ("实际读取到的图片:%d 个" % len(images))
# Labels的数据类型必须转换成为int32
return images, labels.astype(np.int32)
# 展示mnist数据的图片,总共展示十个图片,排列成2行、每行5个图片
def mnist_img_show():
# 读取mnist数据集,默认读取训练数据集
images, labels = read_mnist_data()
# 总共画出十个数字的图片,按照2行5列的顺序排列
fig, ax = plt.subplots(nrows=2, ncols=5, sharex=True, sharey=True,)
ax = ax.flatten()
for i in range(10):
img = images[i]
# 显示该图片中数字的值(对应标签)
ax[i].set_xlabel("{:d}".format(labels[i]))
# 按照灰度显示
ax[i].imshow(img, cmap='Greys', interpolation='nearest')
ax[0].set_xticks([])
ax[0].set_yticks([])
plt.tight_layout()
plt.show()
# mnist数据集展示入口
mnist_img_show()
将mnist数据集中第一张图片逐个像素读取放入csv文件
该函数用到了上边的函数,
#!/usr/local/bin/python3
# -*- coding: UTF-8 -*-
import os
import struct
import numpy as np
import urllib.request
from matplotlib import pyplot as plt
import gzip
import pandas as pd
# 以上部分是整个模型引用的软件包
'''
读取mnist数据文件。如果本地文件不存在,则从网络上下载并且保存到本地。
:param data_type: 要读取的数据文件类型,包括"train"和"t10k"两种,分别代表训练数据和测试数
据。
:Returns: 图片和图片的标签。图片是以张量形式保存的。
'''
def read_mnist_data(data_type="train"):
img_path = ('./mnist/%s-images-idx3-ubyte.gz' % data_type)
label_path = ('./mnist/%s-labels-idx1-ubyte.gz' % data_type)
# 如果本地文件不存在,那么,从网络上下载mnist数据
if not os.path.exists(img_path) or not os.path.exists(label_path) :
# 确保./mnist/目录存在,如果不存在,就自动创建此目录
if not os.path.isdir("./mnist/"):
os.mkdir("./mnist/")
# 从网上下载图片数据,并且,保存到本地文件
img_url = ('http://yann.lecun.com/exdb/mnist/%s-images-idx3-ubyte.gz' % data_type)
print("下载:%s" % img_url)
urllib.request.urlretrieve(img_url, img_path)
print("保存到:%s" % img_path)
# 从网上下载标签数据,并且保存到本地
label_url = ('http://yann.lecun.com/exdb/mnist/%s-labels-idx1-ubyte.gz' % data_type)
print("下载:%s" % label_url)
urllib.request.urlretrieve(label_url, label_path)
print("保存到:%s" % label_path)
# 使用gzip读取标签数据文件
print("\n读取文件:%s" % label_path)
with gzip.open(label_path, 'rb') as label_file:
# 按照大端在前(big-endian)读取两个32位的整数,所以,总共读取8个字节
# 分别是magic number、n_labels(标签的个数)
magic, n_labels = struct.unpack('>II', label_file.read(8))
print("magic number:%d,期望标签个数:%d 个" % (magic, n_labels))
# 将剩下所有的数据按照byte的方式读取
labels = np.frombuffer(label_file.read(), dtype=np.uint8)
print ("实际读取到的标签:%d 个" % len(labels))
# 使用gzip读取图片数据文件
print("\n读取文件:%s" % img_path)
with gzip.open(img_path, 'rb') as img_file:
# 按照大端在前(big-endian)读取四个32位的整数,所以,总共读取16个字节
magic, n_imgs, n_rows, n_cols = struct.unpack(">IIII", img_file.read(16))
# 分别是magic number、n_imgs(图片的个数)、图片的行列的像素个数(n_rows, n_cols )
print("magic number:%d,期望图片个数:%d个" % (magic, n_imgs))
print("图片长宽:%d × %d 个像素" % (n_rows, n_cols))
# 读取剩下所有的数据,按照 labels * 784 重整形状,其中 784 = 28 × 28 (长×宽)
images = np.frombuffer(img_file.read(), dtype=np.uint8).reshape(n_imgs, n_rows, n_cols)
print ("实际读取到的图片:%d 个" % len(images))
# Labels的数据类型必须转换成为int32
return images, labels.astype(np.int32)
# 手写数字计算机眼里什么样?
def mnist_5_csv():
# 需要调用read_mnist_data,该函数在上一节的MNIST数据展示中已经出现过
images, labels = read_mnist_data()
# 我们读取训练数据中的第一个图片
# 它是以一个28 × 28张量形式保存的,每个元素的数值代表一个像素
# 像素的取值0~255,数值越大,代表颜色越深
# 其中0代表白色(背景色),255代表黑色(前景色)
img = images[0]
# 将这个图片的每个像素读取出来,逐行转换成字符串,保存到csv文件中
img_csv_value = ""
for n_row in range(0, 28):
for n_col in range(0, 28):
img_csv_value += str(img[n_row][n_col])
# 在每一列后面增加一个逗号分隔符
if (n_col != 27):
img_csv_value += ","
# 在每一行后面增加换行符,将图片的所有元素逐行转换成csv
img_csv_value += "\n"
# 将字符串写入到CSV文件
# 确保./data/存在,如果不存在,就自动创建此目录
if not os.path.isdir("./data/"):
os.mkdir("./data/")
with open('./data/mnist_number_5.csv', 'w') as csv_file:
csv_file.write(img_csv_value)
csv_file.close()
# 将mnist数据集中的数字5保存成CSV格式
mnist_5_csv()
手写数字识别实战
Estimator
Estimator是TensorFlow高级开发接口,使用Estimator可以极大地简化机器学习编程的过程。Estimator封装了机器学习的以下步骤。
(1)训练:Estimator将训练过程封装起来,我们无须关心训练过程,只需要按照Estimator的格式,将训练数据“喂”给Estimator即可。
(2)评估:针对某些业务场景,我们可以一次训练多个模型,然后使用验证数据对它们进行评估,选择效果最好的模型作为最后的输出。
(3)预测:在生产环境中,使用训练好的模型对数据进行预测。
(4)导出以供使用:将训练好的数据保存起来,供将来使用。
常用内置的Estimator简介
内置的Estimator模型能够让我们在更高层的概念上运用TensorFlowAPI。由于Estimator会自动创建、管理计算图和会话,所以我们无须担心计算图构建的细节及会话的细节。更大的好处是,借助Estimator,只需要少量地改动代码,我们就可以检验不同的模型架构对业务问题的影响。
TensorFlow中内置了常用的Estimator算法,大致可以分成两个类别。第一类是分类预测,就是预测数据属于哪一个。手写数字识别是定性的分类预测,核心是预测手写数字属于0~9中的哪一个。常见的分类预测场景如市场营销中预测客户会不会购买(将会买、将不会买两个类别);第二类是回归算法,用来对特定的业务目标进行打分。比如评估用户A对产品1、产品2⋯⋯产品n的偏好程度(分值)。
- 第一类的分类预测Estimator主要有
- tf. estimator.LinearClassifier(线性分类)、
- tf. estimator.Boosted TreesClassifier(Boosted Trees算法)、
- tf. estimator.DNNClassifier(深层神经网络算法)、
- tf. estimator.DNNLinearCombinedClassifier(结合了线性分类算法与深层神经网络算法)、
- tf. contrib. estimator.RNN Classifier(循环神经网络算法)。
- 第二类的回归预测Estimator主要有
- tf. estimator.LinearRegressor(线性回归算法)、
- tf. estimator.Boosted TreesRegressor(Boosted Trees回归算法)、
- tf. estimator.DNNRegressor(深层神经网络算法)、
- tf. estimator.DNNLinearCombinedRegressor(结合了线性回归与深层神经网络算法的回归模型)。
tf. estimator.DNNClassifier(深层神经网络算法)介绍
手写识别算法属于分类预测算法,同时采用深层神经网络算法。在这里介绍一下函数的用法
tf. estimator.DNNClassifier 是采用深层神经网络算法的分类器,用于分类预测场景。DNNClassifier的构造函数如下
__init__(
hidden_units,
feature_columns,
model_dir=None,
n_classes=2,
weight_columns=None,
lable_vocabulary=None,
optimize='Adagrad',
activation_fn=tf.nn.relu,
dropout=None,
input_layer_partitioner=None,
config=None,
warm_start_from=None,
loss_reduction=losses.Reduction.SUM,
batch_norm=False
)
hidden_units:表示每个隐藏层所包含的神经元数量,隐藏层之间采用全连接的形式。例如,[64,32]表示第一层有64个节点,第二层有32个节点。feature_columns:模型用来预测的特征列集合,支持 Iterator 接口。集合中的每个特征列都是FeatureColumn的实例。该参数对应输入列,所有的输入参数,都必须存在于 feature_columns 中。model_dir= None:用来保存模型、计算图的文件目录,也可以用来恢复之前该目录下保存的模型、检查点等,以便于从上次保存处开始训练。n_classes=2:标签类别的数量,即需要将样本数据分成的类别数。对应输出类别。默认分成两个类别,即二分场景。注意,标签类别是采用类别索引的形式(从0到n_classes-1的值)。其他形式的标签(如字符串标签),要转换为类别索引的形式。weight_column= None:可以是一个字符串或从 tf. feature_column. numeric_column 创建的数字列,代表特征列的权重。label_vocabulary= None:代表特征标签取值的字符串列表。如果指定了 label_vocabulary,那么特征标签必须是字符串且包含 label_vocabulary 中所有可能的取值。如果不指定 label_vocabulary,那么默认特征标签将编码为整数或浮点数。如果是二分分类,则编码为[0,1];如果是多类别分类,则编码为[0,1,…,n_classes-1]。如果目标特征 label 是字符串,同时又没有指定label_vocabulary,该函数会抛出一个异常。optimizer='Adagrad':用来完成模型训练的优化器,是tf. Optimizer的实例。它可以是一
个字符串,如’Adagrad’,'Adam′,'Ftrl′,'RMSProp′,'SGD′,也可以是一个可调用接口。默认为Adagrad优化器。activation_fn= tf. nn. relu:激活函数,应用于所有的隐藏层。如果设置为 None,默认采用tf. nn. relu作为激活函数。dropout=None:如果不是None,表示丢弃相关神经元的概率input_layer_partitioner= None:可选,用来对输入层的数据进行分区。默认采用 min_max_variable_partitioner 分区器,参数 min_slice_size 为64<<20config=None:RunConfig对象,用于配置运行时设置。warm_start_from= None:一个指向事先保存好的检查点文件路径的字符串,或者一个WarmStartSettings对象,能够从上次保存的检查点开始模型训练。如果本参数是字符串,那么所有的权重和偏置项都从检查点中保存的数值开始训练,默认所有的张量和词汇的名称都与现有的模型保持一致。logs₋reduction=losses.Reduction.SUM:一个训练批次的损失坍缩算法,除非是None,否则是tf. losses. Reduction对象。默认是求和。- batch_norm=False:是否需要在每个隐藏层之后使用批量标准化(Batch Normalization,BN)操作。针对性解决梯度消失的问题。
实战代码及其分析
使用estimator开发模型的4个步骤。
-
定义输入特征列:本例中只定义了一个输入特征,也就是只定义了一个特征变量,即x。它是一个形状为28×28的张量。该张量的每个元素对应手写数字图片的一个像素。
# 返回值是输入特征列的集合(列表) # 请注意,返回对象是被方括号包含在内的 return [tf.feature_column.numeric_column(key="x", shape=[28, 28])] -
创建Estimator实例:创建Estimator实例,包括创建优化器和创建DNNClassifier实
例。创建DNNClassifier实例的过程中,需要注意的是model₋dir和config两个参数的设置。其中, model_dir 不仅可以用来保存模型的计算图和相关变量,还可以用来保存模型训练过程中的参数和数值。参数config是模型训练过程中的配置数据。这些模型训练过程中的数据,可以通过ensorboard来实现模型可视化。 -
定义数据输入函数。
-
模型训练。将样本数据"喂"给模型,指定模型训练的轮次。
#!/usr/local/bin/python3
# -*- coding: UTF-8 -*-
import os
import struct
import numpy as np
import urllib.request
import gzip
import tensorflow as tf
import time
# 以上部分是整个模型引用的软件包
'''
读取mnist数据文件。如果本地文件不存在,则从网络上下载并且保存到本地。
:param data_type: 要读取的数据文件类型,包括"train"和"t10k"两种,分别代表训练数据和测试
数据。
:Returns: 图片和图片的标签。图片是以张量形式保存的。
'''
def read_mnist_data(data_type="train"):
img_path = ('./mnist/%s-images-idx3-ubyte.gz' % data_type)
label_path = ('./mnist/%s-labels-idx1-ubyte.gz' % data_type)
# 如果本地文件不存在,那么,从网络上下载mnist数据
if not os.path.exists(img_path) or not os.path.exists(label_path) :
# 确保./mnist/目录存在,如果不存在,就自动创建此目录
if not os.path.isdir("./mnist/"):
os.mkdir("./mnist/")
# 从网上下载图片数据,并且,保存到本地文件
img_url = ('http://yann.lecun.com/exdb/mnist/%s-images-idx3-ubyte.gz' % data_type)
print("下载:%s" % img_url)
urllib.request.urlretrieve(img_url, img_path)
print("保存到:%s" % img_path)
# 从网上下载标签数据,并且保存到本地
label_url = ('http://yann.lecun.com/exdb/mnist/%s-labels-idx1-ubyte.gz' % data_type)
print("下载:%s" % label_url)
urllib.request.urlretrieve(label_url, label_path)
print("保存到:%s" % label_path)
# 使用gzip读取标签数据文件
print("\n读取文件:%s" % label_path)
with gzip.open(label_path, 'rb') as label_file:
# 按照大端在前(big-endian)读取两个32位的整数,所以,总共读取8个字节
# 分别是magic number、n_labels(标签的个数)
magic, n_labels = struct.unpack('>II', label_file.read(8))
print("magic number:%d,期望标签个数:%d 个" % (magic, n_labels))
# 将剩下所有的数据按照byte的方式读取
labels = np.frombuffer(label_file.read(), dtype=np.uint8)
print ("实际读取到的标签:%d 个" % len(labels))
# 使用gzip读取图片数据文件
print("\n读取文件:%s" % img_path)
with gzip.open(img_path, 'rb') as img_file:
# 按照大端在前(big-endian)读取四个32位的整数,所以,总共读取16个字节
magic, n_imgs, n_rows, n_cols = struct.unpack(">IIII", img_file.read(16))
# 分别是magic number、n_imgs(图片的个数)、图片的行列的像素个数
# (n_rows, n_cols )
print("magic number:%d,期望图片个数:%d个" % (magic, n_imgs))
print("图片长宽:%d × %d 个像素" % (n_rows, n_cols))
# 读取剩下所有的数据,按照 labels * 784 重整形状,其中 784 = 28 × 28 (长×宽)
images = np.frombuffer(img_file.read(), dtype=np.uint8).reshape(n_imgs, n_rows, n_cols)
print ("实际读取到的图片:%d 个" % len(images))
# Labels的数据类型必须转换成为int32
return images, labels.astype(np.int32)
'''
定义输入特征列。输入的是手写数字的图片,图片的大小是固定的,每个图片都是长28个像素、
宽28个像素、单色。
:Returns: 输入特征列的集合。本例中输入特征只有一个,命名为x
'''
def define_feature_columns():
# 返回值是输入特征列的集合(列表)
# 请注意,返回对象是被方括号包含在内的
return [tf.feature_column.numeric_column(key="x", shape=[28, 28])]
# 构建深层神经网络模型
# model_name:模型的名称。如果需要训练多个模型,然后,通过验证数据来选择最好的
# 模型,那么,模型保存的路径需要区分开。这里使用model_name来区分多个模型。
# hidden_layers :隐藏层神经元的数量,一个以为数组,其中,每个元素带个一个隐藏层的
# 神经元个数。例如[256, 32],代表两个隐藏层,第一层有256个神经元,第二层有32个神经元
# [500, 500, 30]代表有三个隐藏层,神经元数量分别是500个、500个、30个
def mnist_dnn_classifier(name="mnist", hidden_layers=[256, 32]):
# (1)定义输入特征列表,在这个例子中,输入特征只有一个就是“x”,
# 该输入特征是一个28 × 28张量,其中,每个元素代表一个像素
feature_columns = define_feature_columns()
# (2)创建DNNClassifier实例
# 构建优化函数,本例中采用AdamOptimizer优化器,初始学习率设置为1e-4
adam_optimizer = tf.train.AdamOptimizer(learning_rate=1e-4)
classifier = tf.estimator.DNNClassifier(
# 指定输入特征列(输入变量),本例中只有一个“x”
feature_columns=feature_columns,
# 隐藏层,一个列表,其中的每个元素代表隐藏层神经元的个数
hidden_units=hidden_layers,
# 优化器,这里使用AdamOptimizer优化器
optimizer=adam_optimizer,
# 分类个数。手写数字的取值范围是0到9,总共有10个数字,所以,是十个类别。
n_classes=10,
# 将神经元dropout的概率。所谓的dropout,是指将神经元暂时地从神经网络中剔除,
# 这样可以避免过拟合,提高模型的健壮性。
# 这里设置丢弃神经元的概率是10%(0.1)
dropout=0.1,
# 模型的保存的目录,如果是,多次训练,能够从上一次训练的基础上开始,能够提高模型的
# 训练效果,一般来说,通过多次训练能够提高模型识别的精确度。
model_dir=('./tmp/%s/mnist_model' % name),
# 设置模型保存的频率。设置为每10次迭代,将训练结果保存一次。
# 可以通过 tensorboard --logdir=model_dir,
# 然后,通过http://localhost:6006/,来可视化的查看模型的训练过程
config=tf.estimator.RunConfig().replace(save_summary_steps=10))
# (3)定义数据输入函数
# 读取训练数据。读取数据文件train-images-idx3-ubyte.gz、train-labels-idx1-ubyte.gz
features, labels = read_mnist_data(data_type="train")
# 样本数据输入函数
train_input_fn = tf.estimator.inputs.numpy_input_fn(
# 数据输入函数中的Dictionary对象,key=“x”,value是28 × 28的张量
x={"x": features},
# 数据输入函数中的标签
y=labels,
# 训练轮数
num_epochs=None,
# 每批次的样本个数。对于模型训练来说,每一批数据就调整一次参数的方式能提高训练
# 速度,实现更快的拟合。
batch_size=100,
# 是否需要乱序。乱序操作可以提高程序的健壮性。避免因为顺序数据中所包含的规律
shuffle=True)
# (4)模型训练
print ("\n模型训练开始时间:%s" % time.strftime('%Y-%m-%d %H:%M:%S'))
time_start = time.time()
classifier.train(input_fn=train_input_fn, steps=20000)
time_end = time.time()
print ("模型训练结束时间:%s" % time.strftime('%Y-%m-%d %H:%M:%S'))
print("模型训练共用时: %d 秒" % (time_end - time_start))
# 读取测试数据集,用于评估模型的准确性
# 读取测试数据文件t10kimages-idx3-ubyte.gz、t10k-labels-idx1-ubyte.gz
test_features, test_labels = read_mnist_data(data_type="t10k")
test_input_fn = tf.estimator.inputs.numpy_input_fn(
# 数据输入函数中的Dictionary对象,key=“x”,value是28 × 28的张量
x={"x": test_features},
# 数据输入函数中的标签
y=test_labels,
# 轮数,对于测试来说,一轮就足够了。训练的过程才需要多轮
num_epochs=1,
# 是否需要乱序。测试数据只需要结果,不需要乱序
shuffle=False)
# 评价模型的精确性
print ("\n模型测试开始时间:%s" % (time.strftime('%Y-%m-%d %H:%M:%S')))
accuracy_score = classifier.evaluate(input_fn=test_input_fn)["accuracy"]
print ("模型测试结束时间:%s" % (time.strftime('%Y-%m-%d %H:%M:%S')))
print("\n模型识别的精确度: {:.2f} % \n".format ((accuracy_score * 100)))
# 手写数字识别示例入口函数
#mnist_dnn_classifier(name="dnn_2_layers_100_50", hidden_layers=[100, 50])
mnist_dnn_classifier(name="dnn_3layers", hidden_layers=[500, 500, 30])
使用tensorboard对过程进行可视化
- 首先我们要确保当前环境中tensorflow的版本和tensorboard的版本尽量一致。
- 之后,打开

- 因为我是用虚拟环境,我会先激活虚拟环境,之后在虚拟环境下用cmd命令跳转到日志文件所在的目录下,如上边的例子,我们保存的日志的文件夹为
mnist_model,依据该文件夹的属性来跳转是一个不错的办法

- 然后使用命令:
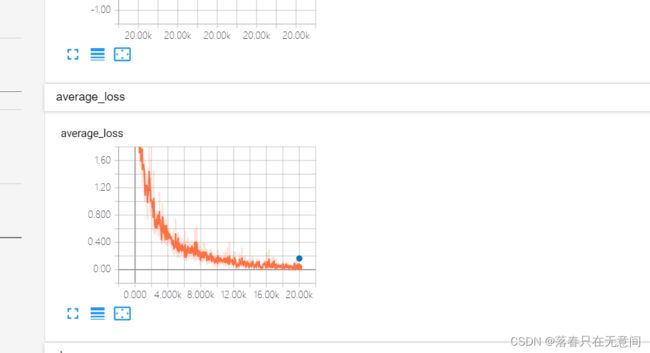
tensorboard --logdir=mnist_model,mnist_model是日志所在文件夹名。之后运行结果中会有网址出现,将该网址复制到浏览器就可以看到可视化过程了。
寻找最优模型
在该模型中对模型准确率影响较大的参数组合起来,包括隐藏层的层数、神经元数量、优化器、激活函数、droput参数。那么我们就可以对其可以的取值进行组合,同时为了防止组合情况过多,我们可以先固定其余的参数不变,只改变其中的一个参数的值,然后选出该参数下较优的值的可能,这样就减少的组合的情况。
完整代码:
#!/usr/local/bin/python3
# -*- coding: UTF-8 -*-
import os
import struct
import numpy as np
import urllib.request
import gzip
import tensorflow as tf
import time
# 以上部分是整个模型引用的软件包
'''
读取mnist数据文件。如果本地文件不存在,则从网络上下载并且保存到本地。
:param data_type: 要读取的数据文件类型,包括"train"和"t10k"两种,分别代表训练数据和测试
数据。
:Returns: 图片和图片的标签。图片是以张量形式保存的。
'''
def read_mnist_data(data_type="train"):
img_path = ('./mnist/%s-images-idx3-ubyte.gz' % data_type)
label_path = ('./mnist/%s-labels-idx1-ubyte.gz' % data_type)
# 如果本地文件不存在,那么,从网络上下载mnist数据
if not os.path.exists(img_path) or not os.path.exists(label_path) :
# 确保./mnist/目录存在,如果不存在,就自动创建此目录
if not os.path.isdir("./mnist/"):
os.mkdir("./mnist/")
# 从网上下载图片数据,并且,保存到本地文件
img_url = ('http://yann.lecun.com/exdb/mnist/%s-images-idx3-ubyte.gz' % data_type)
print("下载:%s" % img_url)
urllib.request.urlretrieve(img_url, img_path)
print("保存到:%s" % img_path)
# 从网上下载标签数据,并且保存到本地
label_url = ('http://yann.lecun.com/exdb/mnist/%s-labels-idx1-ubyte.gz' % data_type)
print("下载:%s" % label_url)
urllib.request.urlretrieve(label_url, label_path)
print("保存到:%s" % label_path)
# 使用gzip读取标签数据文件
print("\n读取文件:%s" % label_path)
with gzip.open(label_path, 'rb') as label_file:
# 按照大端在前(big-endian)读取两个32位的整数,所以,总共读取8个字节
# 分别是magic number、n_labels(标签的个数)
magic, n_labels = struct.unpack('>II', label_file.read(8))
print("magic number:%d,期望标签个数:%d 个" % (magic, n_labels))
# 将剩下所有的数据按照byte的方式读取
labels = np.frombuffer(label_file.read(), dtype=np.uint8)
print ("实际读取到的标签:%d 个" % len(labels))
# 使用gzip读取图片数据文件
print("\n读取文件:%s" % img_path)
with gzip.open(img_path, 'rb') as img_file:
# 按照大端在前(big-endian)读取四个32位的整数,所以,总共读取16个字节
magic, n_imgs, n_rows, n_cols = struct.unpack(">IIII", img_file.read(16))
# 分别是magic number、n_imgs(图片的个数)、图片的行列的像素个数
# (n_rows, n_cols )
print("magic number:%d,期望图片个数:%d个" % (magic, n_imgs))
print("图片长宽:%d × %d 个像素" % (n_rows, n_cols))
# 读取剩下所有的数据,按照 labels * 784 重整形状,其中 784 = 28 × 28 (长×宽)
images = np.frombuffer(img_file.read(), dtype=np.uint8).reshape(n_imgs, n_rows, n_cols)
print ("实际读取到的图片:%d 个" % len(images))
# Labels的数据类型必须转换成为int32
return images, labels.astype(np.int32)
'''
定义输入特征列。输入的是手写数字的图片,图片的大小是固定的,每个图片都是长28个像素、
宽28个像素、单色。
:Returns: 输入特征列的集合。本例中输入特征只有一个,命名为x
'''
def define_feature_columns():
# 返回值是输入特征列的集合(列表)
# 请注意,返回对象是被方括号包含在内的
return [tf.feature_column.numeric_column(key="x", shape=[28, 28])]
# 构建深层神经网络模型
# model_name:模型的名称。如果需要训练多个模型,然后,通过验证数据来选择最好的
# 模型,那么,模型保存的路径需要区分开。这里使用model_name来区分多个模型。
# hidden_layers :隐藏层神经元的数量,一个以为数组,其中,每个元素带个一个隐藏层的
# 神经元个数。例如[256, 32],代表两个隐藏层,第一层有256个神经元,第二层有32个神经元
# [500, 500, 30]代表有三个隐藏层,神经元数量分别是500个、500个、30个
def mnist_dnn_classifier(name="mnist", hidden_layers=[256, 32]):
# (1)定义输入特征列表,在这个例子中,输入特征只有一个就是“x”,
# 该输入特征是一个28 × 28张量,其中,每个元素代表一个像素
feature_columns = define_feature_columns()
# (2)创建DNNClassifier实例
# 构建优化函数,本例中采用AdamOptimizer优化器,初始学习率设置为1e-4
adam_optimizer = tf.train.AdamOptimizer(learning_rate=1e-4)
classifier = tf.estimator.DNNClassifier(
# 指定输入特征列(输入变量),本例中只有一个“x”
feature_columns=feature_columns,
# 隐藏层,一个列表,其中的每个元素代表隐藏层神经元的个数
hidden_units=hidden_layers,
# 优化器,这里使用AdamOptimizer优化器
optimizer=adam_optimizer,
# 分类个数。手写数字的取值范围是0到9,总共有10个数字,所以,是十个类别。
n_classes=10,
# 将神经元dropout的概率。所谓的dropout,是指将神经元暂时地从神经网络中剔除,
# 这样可以避免过拟合,提高模型的健壮性。
# 这里设置丢弃神经元的概率是10%(0.1)
dropout=0.1,
# 模型的保存的目录,如果是,多次训练,能够从上一次训练的基础上开始,能够提高模型的
# 训练效果,一般来说,通过多次训练能够提高模型识别的精确度。
model_dir=('./tmp/%s/mnist_model' % name),
# 设置模型保存的频率。设置为每10次迭代,将训练结果保存一次。
# 可以通过 tensorboard --logdir=model_dir,
# 然后,通过http://localhost:6006/,来可视化的查看模型的训练过程
config=tf.estimator.RunConfig().replace(save_summary_steps=10))
# (3)定义数据输入函数
# 读取训练数据。读取数据文件train-images-idx3-ubyte.gz、train-labels-idx1-ubyte.gz
features, labels = read_mnist_data(data_type="train")
# 样本数据输入函数
train_input_fn = tf.estimator.inputs.numpy_input_fn(
# 数据输入函数中的Dictionary对象,key=“x”,value是28 × 28的张量
x={"x": features},
# 数据输入函数中的标签
y=labels,
# 训练轮数
num_epochs=None,
# 每批次的样本个数。对于模型训练来说,每一批数据就调整一次参数的方式能提高训练
# 速度,实现更快的拟合。
batch_size=100,
# 是否需要乱序。乱序操作可以提高程序的健壮性。避免因为顺序数据中所包含的规律
shuffle=True)
# (4)模型训练
print ("\n模型训练开始时间:%s" % time.strftime('%Y-%m-%d %H:%M:%S'))
time_start = time.time()
classifier.train(input_fn=train_input_fn, steps=20000)
time_end = time.time()
print ("模型训练结束时间:%s" % time.strftime('%Y-%m-%d %H:%M:%S'))
print("模型训练共用时: %d 秒" % (time_end - time_start))
# 读取测试数据集,用于评估模型的准确性
# 读取测试数据文件t10kimages-idx3-ubyte.gz、t10k-labels-idx1-ubyte.gz
test_features, test_labels = read_mnist_data(data_type="t10k")
test_input_fn = tf.estimator.inputs.numpy_input_fn(
# 数据输入函数中的Dictionary对象,key=“x”,value是28 × 28的张量
x={"x": test_features},
# 数据输入函数中的标签
y=test_labels,
# 轮数,对于测试来说,一轮就足够了。训练的过程才需要多轮
num_epochs=1,
# 是否需要乱序。测试数据只需要结果,不需要乱序
shuffle=False)
# 评价模型的精确性
print ("\n模型测试开始时间:%s" % (time.strftime('%Y-%m-%d %H:%M:%S')))
accuracy_score = classifier.evaluate(input_fn=test_input_fn)["accuracy"]
print ("模型测试结束时间:%s" % (time.strftime('%Y-%m-%d %H:%M:%S')))
print("\n模型识别的精确度: {:.2f} % \n".format ((accuracy_score * 100)))
# 完成模型训练和识别准确率的评价
def mnist_model(estimator, train_input_fn, test_input_fn):
estimator.train(input_fn=train_input_fn, steps=20000)
accuracy_score = estimator.evaluate(input_fn=test_input_fn)["accuracy"]
accuracy_score *= 100
return accuracy_score
# 构建隐藏层
def create_hidden_layers(n_layers, n_neurals):
hidden_layers = []
for _ in range(0, n_layers):
hidden_layers.append(n_neurals)
return hidden_layers
# 将隐藏层的各层神经元转换成为逗号分隔的字符串
# 为了便于后面的分析,隐藏层一律按照5层计算,不足5层的,填充0个神经元隐藏层
# 返回的字符串最后一个字符是“逗号”。要求hidden_layers不超过5层
def to_csv(hidden_layers):
csv = ""
for idx in range(0, len(hidden_layers)):
csv += (str(hidden_layers[idx]) + ",")
# 不足5层的,将后面的层按照0个神经元补齐
for idx in range(len(hidden_layers), 5):
csv += "0,"
return csv
# 寻找准确率最高的模型,将以下的所有参数组合起来
# 比较所有的隐藏层层数为2层、3层、4层、5层
# 每层神经元数量分别为50, 100, 200, 400, 500,800的情况
# 尝试常见4种优化器,[adagrad , adam, ftrl, RMSProp]
# 尝试常见5种激活函数
# dropout取值从0.0 ~ 0.8 的9种情况
# 共有 4 × 6 × 4 × 5 × 9 = 4320 中组合
def search_best_model_ex():
features, labels = read_mnist_data(data_type="train")
train_input_fn = tf.estimator.inputs.numpy_input_fn(
x={"x": features},
y=labels,
num_epochs=None,
batch_size=100,
shuffle=True)
test_features, test_labels = read_mnist_data(data_type="t10k")
test_input_fn = tf.estimator.inputs.numpy_input_fn(
x={"x": test_features},
y=test_labels,
num_epochs=1,
shuffle=False)
feature_columns = define_feature_columns()
# 隐藏层层数分计算是2层、3层、4层、5层,共计4种情况
# 由于2层的情况已经搜索完毕,我们只搜索3层以上的情况
layers_list = [3, 4, 5]
# 隐藏层各层神经元的个数,共计6种情况
# 我们只搜索400,500,800的三个情况
n_neurals_list = [400, 500, 800]
# dropout取值分别为0.0 ~ 0.8,共计9种情况
# 我们只搜索0.1~0.4的四种情况
dropout_list = np.arange(0.1, 0.5, 0.1)
# 分别构建优化器。共计4中情况
# 优化器的初始学习率设置对准确率影响巨大,针对这些优化器设置他们最常用的初始参数
adagrad = tf.train.AdagradOptimizer(learning_rate=0.1)
adam = tf.train.AdamOptimizer(learning_rate=1e-4)
ftrl = tf.train.FtrlOptimizer(0.03, l1_regularization_strength=0.01,
l2_regularization_strength=0.01)
# 优化器RMSProp的准确率太低,剔除
# RMSProp = tf.train.RMSPropOptimizer(learning_rate=1, decay=0.9, momentum=0.9)
optimizer_list = [adam, ftrl, adagrad]
# 激活函数。共计5种情况。
activation_fn_list = [tf.nn.relu, tf.nn.relu6, tf.nn.sigmoid, tf.nn.elu, tf.nn.tanh]
for n_layers in layers_list:
for n_neurals in n_neurals_list:
for optimizer in optimizer_list:
for activation_fn in activation_fn_list:
# 输出结果的字符串,保存9种dropout取值情况
msg_list = []
for dropout in dropout_list:
# 创建隐藏层。为了方便,每层的神经元数量都相同
hidden_layers = create_hidden_layers(n_layers, n_neurals)
# 优化器的名称,从优化器对象中读取
optimizer_name = optimizer.__class__.__name__
# 激活函数的名称,从激活函数的属性中读取
fn_name = getattr(activation_fn, '__name__')
dropout_i = (10 * dropout).astype(np.int32)
m_dir = "./tmp/nn_{:d}_{:d}/{}/{}/dropout_{:d}/mnist_model".format(
n_layers, n_neurals, optimizer_name, fn_name, dropout_i)
# 构建模型;
classifier = tf.estimator.DNNClassifier(
feature_columns=feature_columns,
hidden_units=hidden_layers,
optimizer=optimizer,
n_classes=10,
activation_fn=activation_fn,
dropout=dropout,
model_dir=m_dir)
# 计算该模型识别准确率
score = mnist_model(classifier, train_input_fn, test_input_fn)
# 第一个占位符之后不需要逗号,to_csv返回的字符串最后字符是逗号
msg = "{} {}, {}, {:d}, {:.2f}%".format(to_csv(hidden_layers),
optimizer_name, fn_name, dropout_i, score)
msg_list.append(msg)
print (msg)
with open("./data/model_selection.csv", "a+", encoding="utf-8") as fd:
for line in msg_list:
fd.write(line + "\n")
fd.close()
# 查找准确率最高的模型
search_best_model_ex()