BERT gated multi-window attention network for relation extraction 用于关系抽取的BERT门控多窗口注意力网络
BERT gated multi-window attention network for relation extraction
用于关系抽取的BERT门控多窗口注意力网络

Abstract
实体关系抽取旨在识别句子中实体对之间的语义关系,是问答系统、语义搜索等后续任务的重要技术支持。现有的关系抽取模型主要依靠神经网络来提取句子的语义信息,忽略了重要短语信息在关系抽取中的关键作用。针对这一问题,提出了一种基于BERT门多窗口注意力网络的关系抽取模型(BERT-GMAN)。该模型首先使用BERT提取句子的语义表示特征及其约束信息。其次,构建关键短语提取网络,获取多粒度短语信息,并采用基于元素的最大汇集算法进行关键短语特征提取。再次,采用分类特征感知网络对关键短语特征进行进一步过滤和全局感知,形成关系分类的整体特征。最后,结合Softmax分类器进行关系抽取。在Semval 2010 Task8数据集上的实验结果表明,该模型的性能比现有方法有了进一步的提高,F1-Score达到了90.25%。
1 Instruction
随着互联网的快速发展,如何从海量的非结构化文本数据中有效地提取结构化信息已成为工业界和学术界的研究热点。关系抽取是从非结构化文本源中提取结构化信息的重要环节,其目的是从自然语言文本中提取显性或隐含的语义信息,以自动识别实体e1和e2之间的语义关系。此外,它还是构建知识图(KG)的中间环节,可以为下游的自然语言处理任务提供技术支持,如知识库构建、自动文本摘要、自动问答。如表1中的例子所示,实体"signal"(e2)是实体"transmitter"(e1)的effect,因此e1和e2之间是"Cause-Effect(e1,e2)"的关系。

在早期,传统的关系抽取方法主要集中在基于规则的方法和传统的基于机器学习的方法,存在准确率低和人工经验有限的问题。为了克服这些问题,基于神经网络的方法成为近年来的研究热点。这些方法使用神经网络自动挖掘句子中的隐含特征,而不需要设计复杂的特征工程,在关系提取效果方面完全超过了传统方法。因此,递归神经网络(RNN)和卷积神经网络(CNN)模型已成为当前关系抽取任务的主要模型。
目前,基于神经网络的关系抽取方法大多侧重于模型的创新,而忽略了同一个词在不同句子中具有不同意义的问题。例如,“The tests are generated randomly from a bank of questions developed for each module.” and "We minimized excessive flows that cause flooding bank erosion and habitat loss."的"bank"一词在这两个句子中有不同的意思。
然而,在使用神经网络进行关系提取时,使用的是由word2vec预训练形成的静态单词向量作为输入,同一单词的语义信息不能根据不同句子中的上下文上下文动态调整,从而限制了对实体上下文信息的表示能力。而Google提出的双向编码转换器表示(BERT)模型能够捕捉单词之间的关联特征,并能根据单词的上下文信息动态调整预先训练的单词向量,有效地解决了单词的多义性问题。因此,为了解决句子中词的多义性问题对关系抽取结果的影响,本文采用BERT模型对句子中的词进行编码,以准确捕捉同一词在不同语境中的意义。
另一方面,在表1所示句子的情况下,仅依靠实体“signal”和“transmitter”的语义信息很难识别实体对之间的“Cause-Effect(e1,e2)”关系。因此,必须考虑句子的全局信息。研究人员使用CNN和LSTM等神经网络对句子的全局上下文进行编码,同时引入实体位置和潜在实体类型来增强句子中实体的上下文信息。虽然这些方法可以有效地在句子层面上对上下文进行建模,但句子中与关系分类无关的词会作为噪声信息影响分类结果。对表1中的句子进行分析可以看出,实体“signal”和“transmitter”包含的与关系范畴相关的语义信息较少,而实体“signal”和“transmitter”之间的关系类型可以从“transmitter”中推断出来。因此,本文使用最短依存路径来提取实体对之间的骨干信息,并构建了关键短语提取网络,使得关系提取模型更加关注关键字信息,如”emits“。
为了对现有方法进行改进,提出了一种BERT门控多窗口注意力网络模型。该模型保留了句子中实体对之间的主干信息,构造了约束信息来指导对原始句子的约束,并使用BERT对句子及其约束信息进行编码,形成动态词向量,既增强了实体上下文信息的语义表示,又减少了噪声信息的干扰。此外,该模型还构建了一个关键短语提取网络来捕获句子中的关键短语信息,以丰富句子的语义信息。具体而言,该模型由四个部分组成:词语语义表示网络、关键短语提取网络、分类特征感知网络和关系预测输出网络。
-
词的语义表示网络使用BERT对原始序列及其约束信息进行编码,构建词的动态语义表示特征。
-
关键短语提取网络采用门限多窗口CNN来获取句子中的多粒度短语特征,并使用基于元素的最大汇集算法(EWMP)过滤出关键词短语特征。
-
分类特征感知网络使用自我注意机制和BiLSTM-注意到屏幕和全局感知关键短语特征来形成分类的整体特征。
-
关系预测输出网络使用全连接层和Softmax进行分类处理。本文的主要贡献如下:
-
本文使用最短依存路径(SDP)对句子进行裁剪。该模型在不考虑实体间依赖关系的情况下,保留实体间的主干信息,构造语句约束信息,以减少噪声信息的干扰,有利于模型捕捉实体间的重要信息。
-
利用语料库对句子及其约束信息进行编码,形成具有约束意义的动态词向量,构建关键短语提取网络,获取实体上下文的关键短语特征,增强了实体上下文的语义表示能力。
-
提出了一种全局门控机制(GGM),用于将短语上下文信息传递给当前短语表示,以增强短语本身的信息表示。
-
在标准的SemEval-2010任务8数据集上的实验结果表明,本文的模型获得了最先进的结果,F1-Score达到了90.25%。
本文的其余部分结构如下。第2节概述了相关工作。在第三节中,介绍了模型的总体架构和技术细节。第四节给出了实验数据集、超参数设置以及对实验结果的分析。第五节分析了模型预测结果中的误差。第六部分对本文的工作进行了总结和展望。
2. Related work
目前,关系提取技术分为三种:基于规则的方法、基于传统机器学习的方法和基于神经网络的方法。基于规则的方法在很大程度上依赖于手动设计规则来进行关系提取,但设计规则既耗时又费力。传统的基于机器学习的方法包括基于特征的方法和基于核的方法。基于特征的方法通过预定义的特征模板从训练集中提取实体及其上下文信息,构造用于训练实体关系分类器的特征向量,并使用训练的分类器来识别测试集中的实体关系类别。基于核的方法是构造句子中关系实例的表示,并通过构造核函数来计算不同关系实例之间的相似度以进行关系提取。虽然传统的机器学习方法比基于规则的方法更通用和高效,但特征和核函数的设计更困难和费力。神经网络能够自动捕捉句子中的潜在特征,缓解了传统方法中人工设计特征耗时费力的问题。近年来,研究人员开始尝试使用神经网络来处理关系提取任务,并通过构建不同的神经网络模型来提高关系提取的性能。现有的主流神经网络关系抽取方法主要有基于RNN的方法、基于CNN的方法和基于注意机制的方法。
CNN擅长提取关系实例的局部特征,在句子相对较短的数据集上表现优于RNN。Relation extraction: Perspective from convolutional neural networks提出了一种多窗口CNN模型结构,该模型利用不同大小的卷积核提取不同粒度实体上下文的局部特征。与单窗口CNN关系提取模型相比,该模型的性能有了很大的提高。Wang等人。Relation classification via multi-level attention cnns提出了一种多关注度的CNN关系抽取模型,该模型能够关注上下文中词语之间以及标签与句子之间的关联,突出句子成分对关系抽取的贡献。Structural block driven enhanced convolutional neural representation for relation extraction提出了一种新颖的结构化块驱动的CNN结构。该模型使用依赖分析得到父子节点之间的基本跨度,并利用多尺度卷积神经网络对语义标签进行编码,增强了选择性顺序标注,有效地提高了关系抽取模型的性能和效率。Talla at semeval-2018 task 7: Hybrid loss optimization for relation classification using convolutional neural networks提出了一种主动学习扩展模块用于关系提取,将领域专家知识与CNN相结合进行特征提取。实验结果证明了该方法的有效性。
注意机制根据句子上下文信息捕捉词之间的关联特征,突出重要词对分类任务的贡献。Attention-based bidirectional long short-term memory networks for relation classification提出了一种基于BiLSTM的关系抽取注意机制。该方法使用BiLSTM对实体上下文语义信息进行编码,并利用注意力机制计算每个词对句子的贡献权重,得到句子向量进行分类。Bidirectional lstm with attention mechanism and convolutional layer for text classification提出了一种具有卷积层次的BiLSTM注意网络结构,该网络结构能够捕捉句子的局部特征和全局语义信息,在一定程度上有助于理解文本上下文信息。Attention-based lstm with filter mechanism for entity relation classification将BiLSTM与注意力机制相结合,获取句子的浅层局部信息,并通过基于注意力机制的过滤层来增强句子中的可用信息。该方法在关系抽取性能上有一定的提高。
3. Methodology
在这一部分中,本文介绍了一种基于BERT门控多窗口注意力网络的关系抽取模型。该模型主要包括以下四个部分:词义表示网络、关键短语提取网络、分类特征感知网络和关系预测输出网络。模型的总体架构如图1所示。本文中使用的所有符号都汇总在表2中。


3.1. Word semantic representation network
词语义表示网络使用SDP对句子进行剪枝,保留实体之间的骨干信息形成句子约束信息,并使用BERT对句子及其约束信息进行编码,形成句子的词语义信息表示。
3.1.1. Constraint information约束信息
句子中与关系抽取无关的冗余词往往会影响关系抽取模型的性能。为了减少冗余词对关系抽取结果的干扰,本文提出了约束信息。约束信息是通过使用SDP策略对语句进行剪枝而形成的,并且只保留实体之间的骨干信息。就拿这句话来说,“The [trans-mitter]e1 emits a constant radio [signal]e2 to crea.”例如,Stanford NLP中的Stanford Parser工具被用来对这个句子执行依存分析。
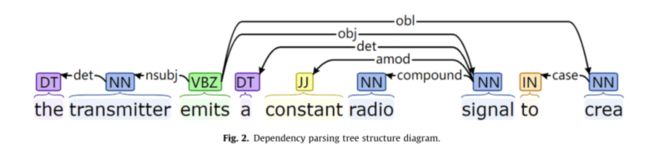
生成的分析树结构如图2所示,其中"emits"为依赖分析树的根节点,目标实体为"Transmitter"和"Signal",目标实体与根节点之间的SDP为:
![]()
然后去除对SDP的依赖关系,形成约束信息“transmitter emits signal”。约束信息只包含实体对之间最重要的信息,在引导对原句的约束时,可以减少原句中冗余信息的干扰。原句和约束信息的比较如表3所示。

3.1.2. Word semantic information representation
为了增强实体上下文信息的语义表示,本文使用预先训练好的BERT语言模型对句子及其约束信息进行编码,形成词的语义信息表示。预训练的BERT语言模型是多层双向转换器编码器,其使用掩码语言模型(MLM)通过预训练双向转换器来生成深层双向语言表示。BERT的输入一般包括标记嵌入、位置嵌入和分段嵌入,其中token嵌入是包含单词信息的单词向量,位置嵌入用于指示单词的位置,分段嵌入用于区分输入中的多个句子。上述三个嵌入是通过从大规模训练语料库中学习生成的。该模型根据输入的句子语境信息对三种嵌入方式进行动态微调。BERT模型通常需要在输入句子的开头添加‘’[CLS]‘’标签,而‘’[CLS]‘’的最终输出代表句子信息。当输入文本包含多个句子时,‘[SEP]“用作句子之间的分隔符标记。
为了使BERT能够获取两个实体的位置信息,本文在实体e1和e2的起始和结束位置分别添加了‘’[E11]和‘’[E12]和‘’[E21]“和‘’[E22]‘位置标记,用’‘[SEP]’分割句子及其约束信息,并在句子开头添加‘’[CLS]‘’来获得句子信息。
例如,句子的“The transmitter emits a constant radio signal to crea.“两个目标实体是‘’transmitter‘’和“signal”,约束信息是”transmitter emits signal“,加上各种标签后的句子S是:"[CLS] The [E11] transmitter [E12] emits a constant radio [E21] signal [E22] to crea [SEP] transmitter emits signal [SEP].“
如图3所示,使用预训练的BERT模型对句子S进行编码以形成语义表示矩阵:
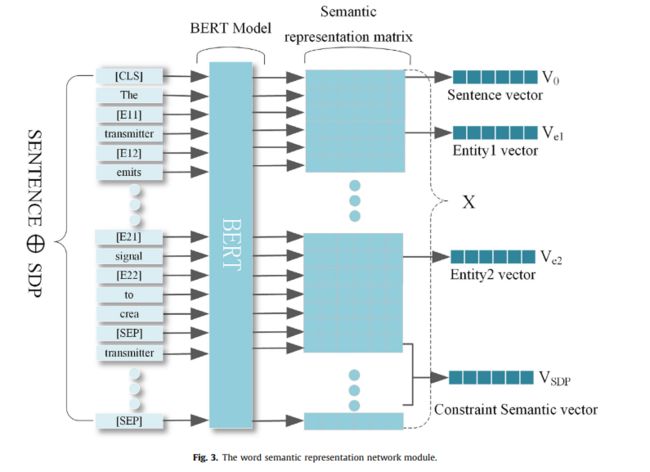

其中,n是句子的长度,Lm是句子的最大长度,Xi是第i个单词的单词向量,dw表示BERT模型输出的单词向量维度, x i x_i xi到 x i + h x_{i+h} xi+h 是实体e1的单词嵌入, x j x_j xj到 x j + 1 x_{j+1} xj+1 是实体e2的单词嵌入, x p x_p xp 到 x p + q x_{p+q} xp+q 是约束信息的单词嵌入。为了获得实体向量和约束信息向量,通过使用包含tanh激活函数和全连通层的平均池来处理实体词向量和约束信息词向量,形成实体向量表示 V e 1 V_{e1} Ve1; V e 2 V_{e2} Ve2 和约束信息向量表示 V S D P V_{SDP} VSDP,如等式所示。(1)-(3):

![]()
在语义表示矩阵X中,x1是"[CLS]"的向量,x1由tanh激活函数和全连通层编码以形成句子向量 V 0 ∈ R d w V_0\in R^{d_w} V0∈Rdw,如等式4所示:
![]()
![]()
3.2. Key phrases extraction network 关键词抽取网咯
为了充分捕获句子中的关键短语特征,本文构建了关键短语提取网络,如图4所示。
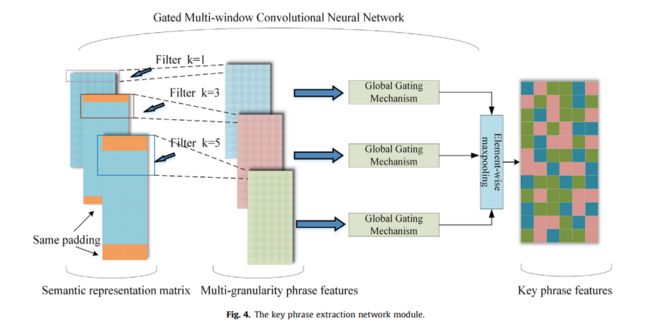
该网络使用不同窗口大小的CNN来捕获句子的多粒度短语特征,通过全局选通机制增强不同粒度短语本身的语义信息,并使用基于元素的最大汇集过滤来形成关键词组特征。
一个句子中的每个词都可以组成一个短语,这个词在它的前面或后面。为了捕捉单词前后两个方向上的重要短语信息,将过滤器设置为奇数,并将窗口大小设置为1,3,5 × d_w 数据仓库用于提取不同粒度的短语特征。为了保证不同卷积核卷积后的语句长度与输入语句长度相同,采用相同的填充策略填充输入语句。假设输入的语义表示矩阵为X,提取第i个词的短语特征,如下式5所示:

其中 c i k ∈ R d c c_i^k\in R^{d_c} cik∈Rdc是卷积核的窗口大小(k取1、3、5的值),dc表示滤波器数。输入语义表示矩阵X经卷积后生成短语特征矩阵 C k = [ c 1 k , . . . , c n k ] C^k=[c_1^k,...,c_n^k] Ck=[c1k,...,cnk],如公式(6)所示。
![]()
不同大小的过滤器可以用来捕获不同粒度的短语特征。为了增强每个粒度短语本身的语义信息,本文提出了全局门控机制,如图5所示。
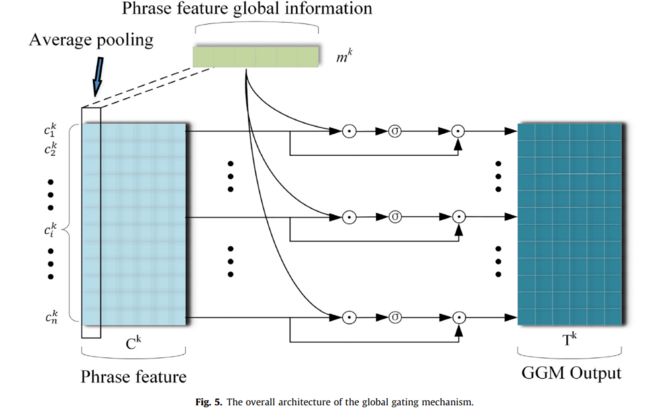
该机制的具体实现如等式所示。(7)-(11):


其中 c i , j k ∈ R 1 × 1 表示短语特征矩阵 c^k_{i,j}\in R^{1\times 1}表示短语特征矩阵 ci,jk∈R1×1表示短语特征矩阵c_k$ 中第i个短语特征向量 c i k c_i^k cik 的第j维值; m k ∈ R d c m^k\in R^{d_c} mk∈Rdc是短语特征全局信息, ⊙ \odot ⊙表示矩阵的点积运算, G k ∈ R n × d c G^k\in R^{n\times d_c} Gk∈Rn×dc是选通信息, T k ∈ R n × d c T^k\in R^{n\times d_c} Tk∈Rn×dc表示全局选通机制的输出。
具体地说,全局选通机制使用等式7,8平均汇集短语特征 C k C^k Ck,提取包含短语上下文语义信息的短语全局特征 m k m^k mk 。公式9,10用于计算短语全局信息 m k m^k mk 和短语特征向量 c k c^k ck 之间的相关性,并且全局选通信息 G k G^k Gk 是通过利用激励函数σ的切换作用保留与当前短语相关的全局信息而忘记与当前短语无关的全局信息而形成的。由于 G k G^k Gk 是从短语全局信息 m k m^k mk 计算产生的,使得 G k G^k Gk可以捕获 m k m^k mk 中的信息。通过使用公式(11)通过对全局选通信息 G k G^k Gk和短语特征向量 c k c^k ck进行点积运算,可以将全局选通信息 G k G^k Gk中包含的短语全局信息传递到当前短语表示中,从而达到利用短语上下文信息增强短语本身的语义表达信息的目的。
为了从多粒度短语特征中过滤出关键短语信息,本文采用基于元素的最大汇集策略对多粒度短语特征进行过滤,如图6所示,通过逐点选取不同粒度短语特征对应特征维度上的最大值形成关键短语特征T’,具体操作如等式(12)-(14)所示:
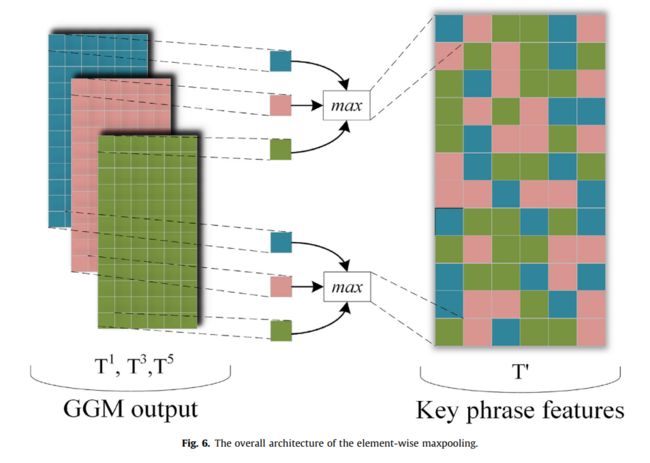
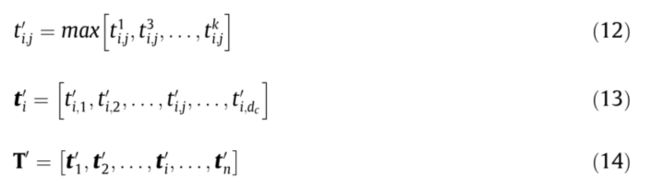
其中 T ′ ∈ R n × d c , t i , j k ∈ R 1 × 1 T'\in R^{n\times d_c},t^k_{i,j}\in R^{1\times 1} T′∈Rn×dc,ti,jk∈R1×1 表示第i个短语特征在 T k T^k Tk 中的第j个维度的值。
3.3. Classification feature perception network
分类特征感知网络使用自我注意机制和BiLSTM-注意对关键短语信息进行过滤和全局感知,形成关系分类的整体特征。
3.3.1. Self-Attention
为了增强关键短语特征T’中的重要短语信息对关系提取结果的影响,利用transformer中的自我注意机制对关键短语特征T’进行进一步过滤。自我注意机制主要由两部分组成:点积型注意和多头型注意。按比例计算的点积关注度主要包括Q、K和V,其计算方法如下式15所示:

多头注意将注意权重映射到多个并行子空间进行权重学习,并对子空间中学习到的信息进行拼接,以关注不同子空间中的相关权重信息。多头注意的具体操作在EQ 16, 17中有所展示:

关键词特征 T ′ = [ t 1 ′ , . . . , t n ′ ] T'=[t_1',...,t_n'] T′=[t1′,...,tn′]是使用自注意过滤得到具有不同权重信息的关联短语特征 Z = M u l t i H e a d ( T ′ , T ′ , T ′ ) , z ∈ R n × d c Z=MultiHead(T',T',T'),z\in R^{n\times d_c} Z=MultiHead(T′,T′,T′),z∈Rn×dc。
3.3.2. BiLSTM-Attention
为了捕捉关键短语特征的全局感知,使用BiLSTM对关键短语特征的上下文信息进行编码。与传统的RNN相比,BiLSTM解决了梯度消失的问题,并能在正向和反向对特征序列进行建模,如图7所示。

每个LSTM单元主要包含四个部分,在时间步长l,LSTM的方程如下:
首先是忘记门 f i f_i fi 的计算;LSTM使用忘记门来选择在先前时刻丢弃哪些信息,如公式18所示:
![]()
h i − 1 h_{i−1} hi−1 是前一状态的输出。下一步是计算输入门 r i r_i ri 和候选信息 g i g_i gi 。输入门从当前时刻的候选信息中选择需要存储在存储单元 c i c_i ci 中的信息,如等式19:

其中,tanh和σ表示非线性激发函数。接下来是存储单元 c i c_i ci 的计算,该存储单元 c i c_i ci 在上下文中存储重要信息,如公式所示(21):
![]()
这可以从方程21中看出 f i f_i fi 丢弃来自先前时刻的一些单元信息,并将新信息添加到当前单元。最后一部分是当前时刻的输出 h i h_i hi 的计算,其取决于当前时刻的输出gate o i o_i oi 和存储单元 c i c_i ci,如等式22、23:

如图7所示,关键短语特征 T ′ = [ t 1 ′ , . . . , t n ′ ] T'=[t_1',...,t_n'] T′=[t1′,...,tn′]作为BiLSTM的输入,用BiLSTM对关键短语特征上下文进行编码后,第i个词隐含层的输出如公式24所示:

关键短语特征T’由BiLSTM编码,并且所生成的短语上下文被表示为 H = [ h 1 , . . . , h n ] ∈ R n × d h H=[h_1,...,h_n]\in R^{n\times d_h} H=[h1,...,hn]∈Rn×dh
为了形成用于关系分类的句子表征,本文采用了句子级注意机制,并在句子级注意的基础上增加了实体特征。关联性短语特征Z和短语语境表征H是由句子表征 P 1 ∗ , P 2 ∗ ∈ R h d P^*_1,P^*_2\in R^{d}_h P1∗,P2∗∈Rhd和H的句级注意机制形成的,如等式(25)-(27)
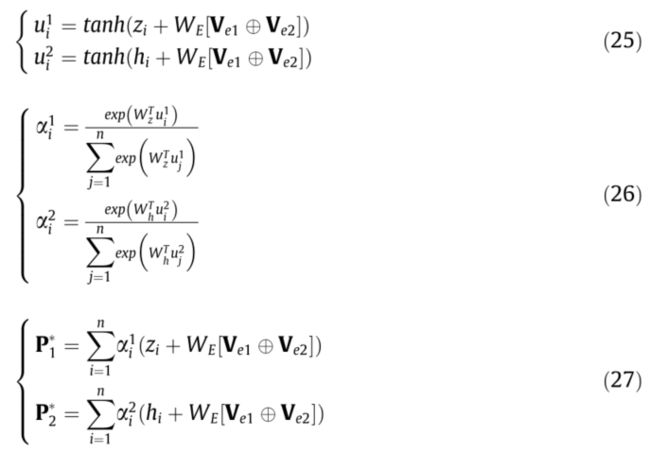
其中 z i ∈ R d c z_i\in R^{d_c} zi∈Rdc是Z中的第i个向量, h i ∈ R d h h_i\in R^{d_h} hi∈Rdh是短语上下文表示H中的第i个向量, d w , d c , d h d_w,d_c,d_h dw,dc,dh具有相同的大小。
3.4. Relationship prediction output network
将句子向量 V 0 V_0 V0 、实体向量 V e 1 V_{e1} Ve1 和 V e 2 V_{e2} Ve2 、约束信息向量 V S D P V_{SDP} VSDP 与句子表示 P 1 ∗ , P 2 ∗ ∈ R c d P_1^*,P^*_2\in R^d_c P1∗,P2∗∈Rcd融合,形成用于关系分类的语义向量Q,如等式28
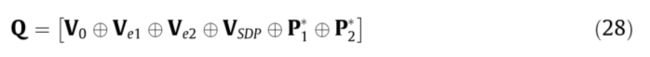
在得到用于关系分类的语义向量Q之后,本文使用完全连通层和Softmax函数来预测关系,并生成每个关系类的概率分布 p ∧ ( y ∣ s ) \overset{\wedge}{p}(y|s) p∧(y∣s),如公式Q(29):

其中,y表示目标关系类别,S是输入语句,θ表示网络中的可学习参数,|R|表示关系类别的数量。
在本文中,该模型使用交叉熵作为损失函数。为了减少过拟合度,提高网络泛化性能,该模型采用L2正则化对网络参数进行惩罚。网络的目标函数如方程(30):

其中|b|是训练数据的大小, y i y_i yi表示期望的输出,k表示L2正则化的超参数,h是模型中的所有可训练参数,其基于训练自动更新。
4. Experiments
4.1. Datasets and evaluation metrics
为了有效地评估本文提出的模型,使用语义评估会议SemEval的数据集SemEval-2010 Task8进行了训练和测试。该数据集包含8,000个训练样本和2,717个测试样本。SemEval2010任务8数据集包含十个类别,特别是以下关系类别:Cause-Effect (C-E), Instrument-Agency(I-A), Product-Producer (P-P), Content-Container (C–C), Entity-Origin (E-O), Entity-Destination (E-D), Component-Whole (C-W),Member-Collection (M-C), Message-Topic (M-T), and Other。每个类别的训练样本和测试样本的分布如图8所示。

在官方评估框架中,上述类别中排名前九的关系类别具有方向性,其他关系类别没有方向性。本文使用SemEval-2010任务8的官方评估指标来计算所有类别(除其他类别外)的宏观平均F1分数,以评估该模型的有效性。
4.2. Hyper-parameter settings
本文模型的主要超参数设置如表4所示。
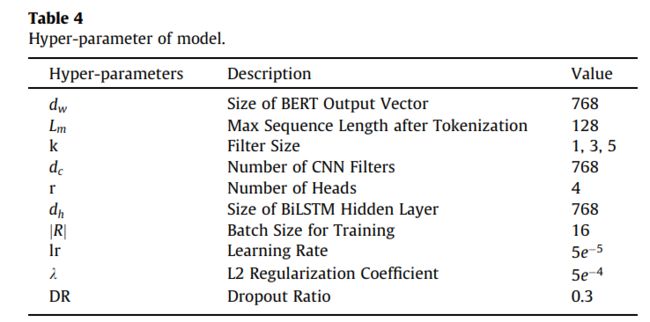
为了更好地将本文的模型与ERT相结合,本文将模型的每一层都设置为与BERT的输出维度相同的维度。
4.3. Experimental results
本文以BERT模型为基线,提出了一种BERT-GMAN关系抽取模型。该模型提取句子中的关键短语信息,以增强实体的上下文表示,同时减少句子中冗余信息的干扰。为了验证模型的有效性,在SemEval-2010任务8数据集上与当前最先进的9个模型进行了对比实验。对比实验的模型主要分为四类:基于RNN的模型、基于CNN的模型和基于预训练的模型,实验结果如表5所示。
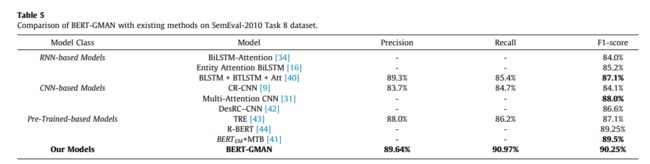
从表5可以看出,本文的模型BERT-GMAN在SemEval-2010任务8数据集上取得了更好的性能,宏观平均F1-Score达到了90.25%。与BLSTM+BTLST M+ATT、多注意力CNN和BERTEM+MTB相比,本文的模型分别将F1-Score提高了3.15%、2.25%和0.75%。结果表明,该模型引入了实体对之间的骨干信息,提取了句子中的关键短语信息,并利用全局选通机制增强了短语本身的语义信息表达能力,丰富了实体上下文的语义信息表达能力,提高了关系抽取的准确性。
4.4. Analysis and discussion
4.4.1. Effectiveness analysis of constraint information
在词约束语义表示网络中,本文使用SDP来提取句子的主干信息作为约束信息。为了考察约束信息是否能对关系抽取模型产生积极影响,在SemEval-2010 Task8数据集上进行了两组对比实验:
- 添加约束信息的BERT模型与BERT-SDP模型的对比实验;
- 去除约束信息后的BERT-GMAN模型的对比实验。
实验结果如表6和图9(A)-(B)所示。

从表6可以看出,BERT-SDP模型的F1-分数比BERT模型提高了0.59%,BERT-GMAN的F1-分数比没有SDP的BERT-GMAN提高了1.18%。这是因为约束信息降低了句子中冗余信息的权重,帮助模型捕捉到实体对之间的重要信息,提高了实体关系抽取的准确性。
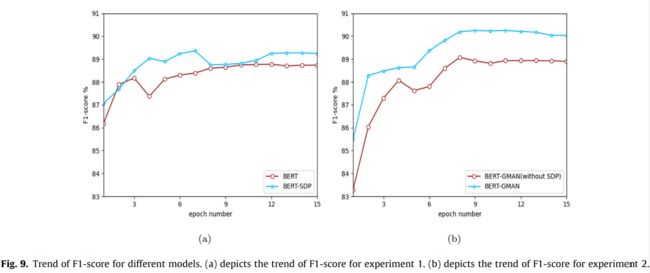
从图9(A)和(B)中可以观察到,BERT-SDP模型和BERT-GMAN模型的F1得分曲线都优于它们的比较模型。BERT-GMAN的F1-Score曲线收敛更快,改善更显着。结果表明,约束信息对提高关系抽取的性能是有效的。
4.4.2. Experimental analysis of phrase combinations with different granularity
在3.2节中,本文介绍了提出的关键短语提取网络结构,该网络结构用于提取多粒度短语特征,并对其进行过滤以形成关键短语特征。不同的过滤器可以提取不同粒度的短语特征,选择合适的短语特征组合可以有效提高模型的关系提取性能。在这项工作中,设置了四种不同的卷积核组合来计算BERT-GMAN模型的宏观平均F1得分。在SemEval-2010任务8数据集上的实验结果如表7所示。

从表7可以看出,组合(D)的F1得分高于其他三个组合。这是因为不同粒度的短语特征所包含的语义信息不同。通过选取多个不同粒度的短语特征进行筛选形成的关键短语特征包含了更丰富的语义信息。增强了实体的上下文表达,提高了关系抽取的准确性。在使用两个不同卷积核的组合中,(A)组合的F1得分高于(B)和©组合。这是因为大多数实体依赖于关于单词本身的信息
以及关于由它们之前和之后的单词组成的关键短语的信息来确定实体关系类。
4.4.3. Effectiveness analysis of different components
该模型分别引入了约束信息、多窗口注意力网络(MAN)和基于ERT的全局门控机制。为了调查每个成分对关系提取模型F1得分的贡献,在数据集SemEval-2010 Task8上进行了对比实验,结果如表8和图10所示。

从表8可以看出,在BERT模型上引入约束信息后,BERT-SDP的F1-得分达到89.36%,说明约束信息可以减少噪声信息对关系分类的负面影响。加入基于BERT-SDP的MAN,BERT-SDP-MAN的F1-得分达到89.72%。这是因为人工获取的关键短语特征及其上下文信息可以丰富实体上下文语义的表达能力,提高关系抽取模型的性能。在BERT-SDP-MAN的基础上引入GGM,BERT-GMAN的F1-得分达到90.25%。结果表明,GGM能够将短语全局信息转化为当前短语表示,并利用短语上下文信息增强短语本身的语义表达信息,从而进一步提高关系抽取模型的性能。

从图10可以看出,图中所示的所有四种方法的F1得分都随着模型迭代次数的增加而增加,但它们都有一定的波动。在SemEval-2010任务8数据集上,与BERT、BERT-SDP和BERT-SDP-MAN相比,BERT-GMAN具有最好的F1得分和最小的波动。实验结果表明,该方法能有效提高关系抽取的性能。
4.4.4. Categorical comparison of BERT-GMAN and BERT
为了验证BERT-GMAN模型的有效性,本文比较了BERT-GMAN和BERT每个关系类别的准确率、召回率和F1-分数。比较结果如表9和图11所示。
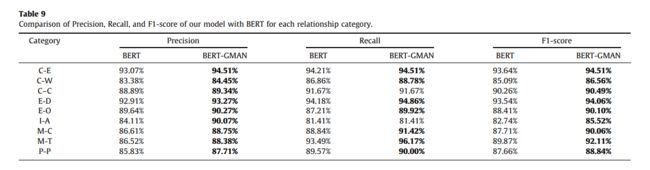
从表9可以看出,与BERT模型相比,BERT-GMAN模型的各个实体关系类别的精度都有了显著的提高。“仪器-机构”和“会员-收藏”的精确度显著提高,分别提高了5.96%和2.14%。大多数类别的召回都有所增加,但不包括“工具-代理”和“内容-容器”。《Entity-Origin》和《MessageTheme》的召回率提升最大,分别增长了2.71%和2.68%。BERT-GMAN模型的所有关系类别的F1-得分均好于BERT模型。“仪器代理”和“会员收藏”的F1-得分显著上升,分别上升了2.78%和2.35%。
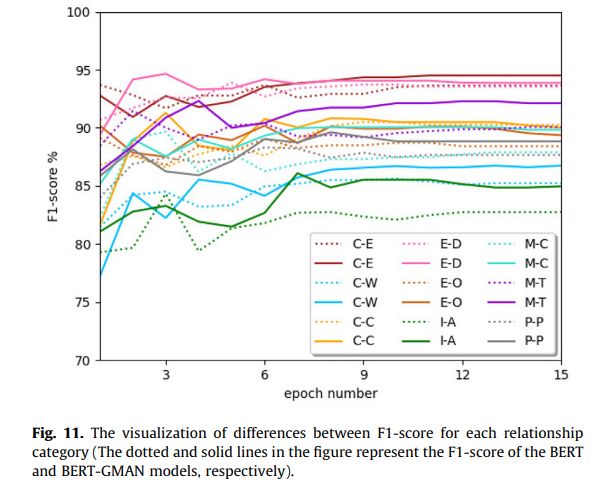
图11的可视化结果可以直观地反映出,在BERT-GMAN模型训练达到稳定后,各关系类别的F1-Score曲线都高于BERT模型。这表明本文的模型可以对每一种关系类别产生积极的影响。
4.4.5. Case study
为了进一步探讨BERT-GMAN模型对关系抽取性能的影响,本文选取了一些实验案例进行分析。表10显示了SemEval-2010 Task8数据集上关系抽取的案例研究。

-
在第一个例子中,BERT和BERT(没有SDP)错误地将范例归类为‘’Other‘范畴,但带有约束信息的BERT-SDP和BERT-GMAN模型正确地预测了范例的标签为’‘Entity-Destination(e1,e2)’‘范畴。BERT倾向于对完整的句子进行编码,但句子中与分类无关的信息往往会干扰分类结果。因此,引入约束信息可以减少句子中无关信息对模型的干扰,提高模型的分类效果。
-
在第二个例子中,只有BERTGMAN模型能够正确地预测例子的标签,原因是在对句子中的无关信息生成约束时,考虑了句子中的关键短语信息,这可以增强句子和实体的语义表示。
结果表明,该模型能有效地提高关系抽取的准确率。
5. Analysis of errors
本文使用混淆矩阵法将BERT-GMAN模型的预测结果与真实结果进行比较,如图12所示。混淆矩阵中对角线上的值表示正确的预测结果,其他区域反映了模型预测结果的误差分布。

从图12的最后一栏可以看出,本文的模型将更多的句子错误归类为“其他”类别,
-
例如‘‘At the bottom of the [E11] church [E12] [E21] steps [E22] were three brown parishioners”,这是“Component-whole”类别,而本文模型的预测结果是“其他”类别。
-
对于另一句话‘‘The [E11] rabbits [E12] are unhappy when left alone in a [E21] hutch [E22] in the garden as they need company”是”Content-Container“类别,而本文模型的预测结果是”“Other”“类别。
该模型预测误差的原因是缺少用于表示实体对周围关系类别的词或短语,因此该模型只能依靠实体本身的语义信息进行分类,这降低了实体关系提取的准确性。
在未来的研究工作中,将引入外部知识,以增强模型对实体语义信息的理解,并有效地解决句子中实体上下文信息不足的问题。
6. 启示
- 这篇paper写的也太鸡儿详细了,笔记给我都做快疯了。
- related work部分写的并不是特别亮眼,本文主要抓住一个点进行叙述:忽略了重要短语信息在关系抽取中的关键作用,但是个人感觉instruction并没有说服我DSP能解决这个问题,这是当做一个query而已。
- 试验也是真的多,太多定量分析了,对于试验结果的分析不错,各位炼丹师们赶紧拿去copy。
- 欢迎关注微信公众号:自然语言处理CS,一起来交流NLP。