23、Plenoxels: Radiance Fields without Neural Networks
简介
主页:https://alexyu.net/plenoxels/
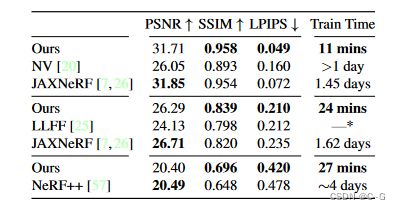
一个用于真实感视图合成的系统。Plenoxels将场景表示为带有球面谐波的稀疏3D网格。这种表示可以从校准图像通过梯度方法和正则化优化,而不需要任何神经组件。在标准、基准任务中,Plenoxels的优化速度比Neural Radiance Fields快了两个数量级,且视觉质量没有损失
实现流程
神经辐射场的关键元素不是神经网络,而是可微的体积渲染器
Classical Volume Reconstruction
体绘制最常见的经典方法是体素网格和多平面图像。
体素网格能够表示任意拓扑,但在高分辨率下内存有限,减少体素网格内存需求的一种方法是对层次结构进行编码,例如使用octrees,在论文中使用更简单的稀疏数组结构
使用这些基于网格的表示和某种形式的插值产生了一个连续的表示,可以使用标准信号处理方法任意调整大小。这种稀疏性和插值的结合使得即使是一个简单的基于网格的模型也能在没有过高内存需求的情况下表现出高分辨率的3D场景
对视图依赖建模进一步扩展了这些经典方法,通过在每个体素上优化每个颜色通道的球面调和系数来实现。球面谐波是球面上函数的标准基,以前被用来表示视图相关性
Method

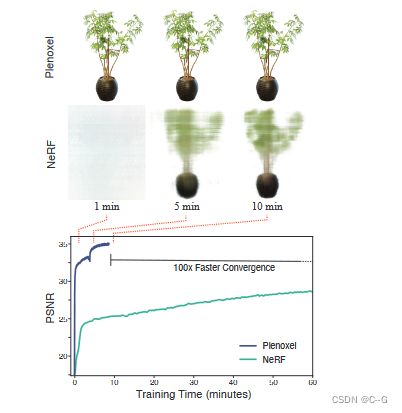
给定一组物体或场景的图像,重建一个(a)稀疏体素(“Plenoxel”)网格,每个体素具有密度和球形谐波系数。为了渲染光线,(b)通过相邻体素系数的三线性插值计算每个样本点的颜色和不透明度。使用©可微体渲染来整合这些样本的颜色和不透明度。然后,可以使用相对于训练图像的标准MSE重建损失,以及总变异正则化器来优化体素系数。
PlenOctrees将一个NeRF变体提取到一个稀疏体素网格中,其中每个体素使用球面调和系数表示视相关的颜色,Plenoxel模型是PlenOctrees的一种推广,支持任意分辨率的稀疏全光体素网格(不需要2的幂次),并能够执行三线性插值,使用这种稀疏体素结构更容易实现
Plenoxel模型是采用稀疏体素网格,每个占据的体素角存储一个标量的不透明度σ和一个球形调和(SH)系数向量的每个颜色通道,通过三线性插值存储在相邻体素上的值并在适当的观看方向上评估球谐波来确定任意位置和观看方向上的不透明度和颜色,最后使用经典渲染公式

Voxel Grid with Spherical Harmonics
体素网格使用了密集的3D索引数组,指针指向一个单独的数据数组,数据数组只包含所占用的体素的值,每个被占用的体素存储每个颜色通道的标量透明度σ和球形谐波系数向量
球面谐波形成了定义在球面上的函数的正交基,低次谐波编码平滑(更朗伯)的颜色变化,高次谐波编码更高频率(更镜面)的效果,样本ci的颜色只是每个颜色通道的这些谐波基函数的和,由相应的优化系数加权,并在适当的观看方向评估
论文使用球面2次谐波,这需要每个颜色通道9个系数,每个体素总共27个谐波系数,没有使用高次谐波是因为高次谐波只带来最小的好处
网格使用三线性插值来定义一个贯穿整个体积的连续的全光函数,所有的系数(不透明度和球面谐波)直接优化,没有任何特殊的初始化或预先训练与神经网络
Interpolation
插值通过表示颜色和不透明度的亚体素变化来提高有效分辨率,插值产生连续函数逼近,这是成功优化的关键,其中三线性插值在学习率变化方面更稳定
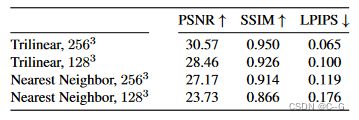
Coarse to Fine
使用粗到精的策略来实现高分辨率,从分辨率较低的密集网格开始,优化、删除不必要的体素,通过在每个维度中将每个体素细分为两半来细化剩余的体素,并继续优化
例如2563d1网格上采样为5123
每个体素细分步骤之后,使用三线性插值来初始化新增的网格值,接着进行体素修剪,对每个体素在所有训练射线上的最大权重 Ti(1−exp(−σiδi)) (或者,对每个体素中的密度值) 应用一个阈值,执行一个扩张操作,只有当体素本身和它的邻居都被认为是空的时候,体素才会被修剪
Optimization
通过渲染像素颜色的均方误差(MSE)与总变化(TV)正则化 优化体素不透明度和球面调和系数
![]()
MSE重构损失(MSE reconstruction loss)Lrecon,总变差正则化器(total variation regularizer) LT V
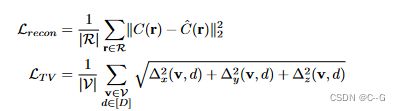
total variation regularizer用∆2x(v, d)表示由分辨率归一化的体素v(i,j,k)中的第d值与体素(i + 1, j, k)中的第d值之间的平方差,并类似地表示∆2y(v, d)和∆2z(v, d)

在实践中,对SH系数和σ值使用不同的权值,这些权重是固定的每个场景类型(有界,向前,和360◦)
为了更快的迭代,每个优化步骤中使用射线的随机样本R来评估MSE项,并使用体素的随机样本V来评估TV项
直接优化体素系数是一个具有挑战性的问题,因为需要优化的值很多(该问题是高维的)、由于渲染公式的原因,优化目标是非凸的、目标的条件很差,一般使用二阶优化算法解决,但是在这里对高维优化问题的实现具有挑战性并且Hessian太大了,很难在每一步中轻松计算和反算,论文使用RMSProp来缓解这些问题,而不需要二阶方法的全部计算复杂性
Unbounded Scenes
对于360°场景,论文参考NeRF++做法。使用多球图像(MSI)背景模型增强稀疏体素网格前景表示,它还使用学习体素颜色和三线性插值球内和球之间的不透明度,这实际上与前景模型相同,只是体素使用简单的等距柱状投影(体素在球体角θ和φ上的指数)扭曲成球体。64个球体线性地放置在从1到∞的反半径中(预先缩放内部场景以近似包含在单位球体中)。为了节省内存,只存储颜色的rgb通道(只有零阶SH),并使用不透明度阈值来稀疏地存储所有图层,就像在主模型中一样
Regularization
除了鼓励平滑度并用于所有场景的TV正则化之外,对于某些类型的场景,还使用其他正则化器
在真实的,向前和360◦场景,使用稀疏先验基于以下SNeRG柯西损失
![]()
σ(ri(tk))表示样本k沿着训练射线i的不透明度,在面向场景的每个小批优化中,我们在每个有源射线上的每个样本上评估这个损失项,这也类似于PlenOctrees中使用的稀疏性损失,并鼓励体素为空,这有助于节省内存并减少上采样时的质量损失。
在真实的,360◦场景,使用beta分布正则器在每个小批量的每条射线的累积前景透光率,鼓励前景是完全不透明或空的,促进了清晰的前景-背景分解
![]()
r为训练射线,TF G®为射线r在0到1之间的前景累计透射率
效果