人工智能助力复工复产,模版OCR轻松搞定健康码识别

背景介绍
在有序推进复工复产过程中,公司为完成常态化核酸筛查工作,北京和上海两地办公室的员工需要每天提交本人所在地的健康宝/随申码和行程码。有关部门收到上传图片后,要核查每位员工的核酸状态,并确认是否去过高风险地区,审核工作需要花费大量的时间和人力,目前急需寻求一种既能高效采集员工健康信息,又能保证员工个人健康数据隐私的人工智能解决方案来应对繁重的健康数据审核工作。
目前该公司遇到的难点
可以归结为如下方面:
1.图片数量暴增:需要审核的健康码/行程码等图片每天都在大量增加。
2.传统文字识别无法满足需求:由于图片来源不固定,可能为手机截屏(分辨率不固定),或者手机屏幕翻拍(拍摄角度随机),传统文字识别技术无法通过固定位置来准确获取文字内容。
待处理图片示例

3.机器学习方面研发能力弱:如果针对三码识别单独研发新功能,开发周期过长,无法满足当下需求。
4.个人健康数据安全:健康信息属于员工个人隐私数据,要最大程度保证这些数据的安全。
5.服务器运维成本高,预算有限:图片上传会随时随地发生,需要有稳定的计算资源支持,如果采用传统架构会加大运维成本。
员工健康信息文字识别需求分析
针对三码(健康码/随申码/行程码)内需要提取的文字信息分别为:

如图所示,三码中要提取的文字信息分别位于图片中相对固定的区域,所以可以使用通用模版文字识别功能来通过预定义模版实现文字内容提取。
亚马逊云科技的AI Solution Kit解决方案中的文本识别类功能包括:通用文字识别OCR(支持简体/繁体),自定义模版文字识别OCR和车牌识别,其中自定义模版文字识别功能(Custom OCR)可以基于预定义的模版信息,针对固定版式的票据或表格,自动识别其中的文字内容并返回结果,可以满足健康信息提取的需求。
所以,只需要针对三类截图创建好对应的模版,就可以提取截图中的健康信息了。在使用上只需在亚马逊云平台上部署该解决方案,就可以马上调用模版文字识别功能对应的URL发送图片请求,从而获得所需的健康信息,不需要任何额外的机器学习知识,开发量极少,非常符合现有的公司需求。
利用模版OCR解决方案
识别健康信息
具体操作可以分为四个步骤:部署解决方案,创建自定义模版,开发调用逻辑完成文字识别并结构化输出结果。

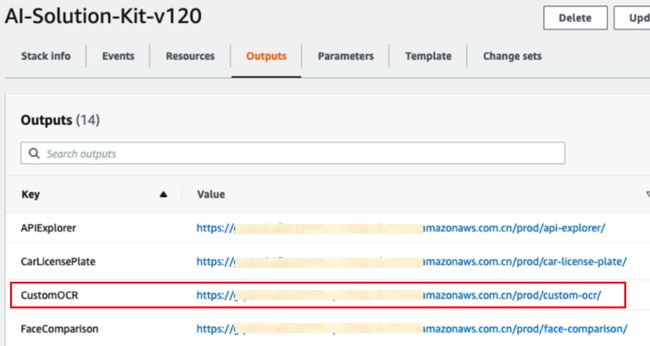
首先是部署AI Solution Kit解决方案,通过AI solution kit解决方案的部署链接与实施手册(https://awslabs.github.io/aws-ai-solution-kit/zh/ ),可以在10分钟内将方案部署完成。由于方案整体设计是基于无服务器架构的,所以只会按调用量付费,不用担心会有额外的支出(成本预估:https://awslabs.github.io/aws-ai-solution-kit/zh/deploy-custom-ocr/#_7 ),在亚马逊云科技 CloudFormation堆栈(Stack)创建成功后,就可以在亚马逊云科技 CloudFormation的输出(Outputs)页面看到基于Amazon API Gateway的调用URL,对应URL名称(Key)为CustomOCR。
接下来我们可以测试一下生成的API调用URL,首先需要新建一个行程码识别模版。这里我们使用开源图像处理软件 GIMP (https://www.gimp.org/downloads/ )来获取坐标点。如下图所示,先在在电脑上用GIMP打开行程码手机截图后,再把鼠标移动到图片上,就可以看到指定位置坐标点X,Y值,请按照左上,右上,右下,左下的顺时针顺序创建矩形框四个坐标点序列。
先把鼠标移动到行程卡中日期的四个角上(下图中矩形框位置),分别记录下四角对应坐标(坐标值显示在GIMP窗口的左下角区域)并指定该识别区域名称为“更新时间”。

用同样的方式,继续标注“手机号码”与“途径地区”的文字识别区域,标注好后的完整JSON数据如下:
[[[116, 335], [410, 335], [410, 374], [116, 374]], "手机号码"],
[[[176, 387], [452, 384], [452, 429], [176, 429]], "更新时间"],
[[[53, 710], [465, 710], [465, 837], [54, 837]], "途经地区"]*左滑查看更多
接下来需要把图片转码成模版OCR能够处理的Base64格式,我们可以使用 Base64Guru (https://base64.guru/converter/encode/image) 在线上传图片,即可将图片转换为Base64编码的格式,转换完成后,与刚才标注的识别区域JSON合并成完整的JSON数据,如下:
{
"type" : "add",
"img": "行程码图片的Base64编码",
"template": [
[[[116, 335], [410, 335], [410, 374], [116, 374]], "手机号码"],
[[[176, 387], [452, 384], [452, 429], [176, 429]], "更新时间"],
[[[53, 710], [465, 710], [465, 837], [54, 837]], "途经地区"]
]
}*左滑查看更多
然后我们通过如下Python代码,把创建模版的请求发送到模版OCR调用URL,完成行程码模版的创建。
import json
import requests
import base64
jkb_img = open('jkb-template.png', 'rb')
base64_data = base64.b64encode(jkb_img.read())
payload = json.dumps({
"type" : "add",
"img": str(base64_data, encoding="utf-8"),
"template": [
[[[116, 335], [410, 335], [410, 374], [116, 374]], "手机号码"],
[[[176, 387], [452, 384], [452, 429], [176, 429]], "更新时间"],
[[[53, 710], [465, 710], [465, 837], [54, 837]], "途经地区"]
]
})
url = "https://[API-ID].execute-api.[REGION-ID].amazonaws.com.cn/prod/custom-ocr/"
response = requests.request("POST", url, data=payload)
json.loads(response.text)*左滑查看更多
输出结果:
{'template_id': '3e2183c63b139f6870c7d0ac53ffdc138bd21c95'}在输出中里我们看到模版已经创建好了,对应的模版ID(template_id)为‘3e2183c63b139f6870c7d0ac53ffdc138bd21c95’,请记下模版ID用于后面的文字识别。
我们找来另一张翻拍格式的行程码图片,用来测试识别效果

我们用了短短12行代码,就完成了行程码健康信息的提取任务。
import base64
import json
import requests
import pandas as pd
jkb_img = open('scan-xjm-1.jpeg', 'rb')
base64_data = base64.b64encode(jkb_img.read())
payload = json.dumps({
"template_id": "3e2183c63b139f6870c7d0ac53ffdc138bd21c95",
"img": str(base64_data, encoding="utf-8")
})
url = "https://gqi4z1k9fl.execute-api.cn-northwest-1.amazonaws.com.cn/prod/custom-ocr/"
response = requests.request("POST", url, data=payload)
df = pd.DataFrame.from_dict(json.loads(response.text))*左滑查看更多
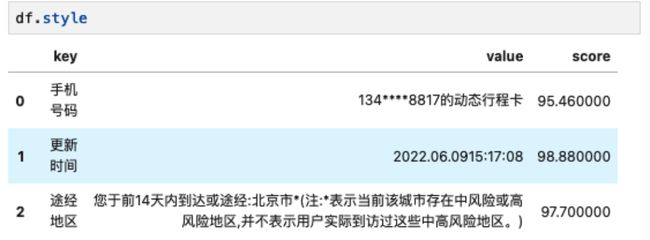
可以看出,AI Solution Kit的模版文字识别功能能够自动将不同手机分辨率截图甚至是翻拍的图像,准确检测识别区域,并进行精准文字识别,提取到所需的行程码信息。
接下来,我们用与创建行程码模版相同的方法,创建健康宝模版,创建健康宝模版的JSON数据如下:
{
"type" : "add",
"img": "健康宝图像的Base64编码",
"template": [
[[[173, 177], [364, 173], [364, 210], [173, 210]], "日期"],
[[[211, 206], [319, 210], [319, 233], [208, 231]], "时间"],
[[[190, 575], [361, 575], [361, 628], [191, 629]], "状态"],
[[[217, 668], [317, 671], [309, 709], [205, 710]], "核酸"],
[[[386, 658], [424, 660], [424, 708], [386, 708]], "核酸时间"],
[[[263, 810], [483, 828], [483, 864], [289, 867]], "姓名"],
[[[220, 876], [482, 870], [479, 909], [222, 908]], "身份证号"],
[[[277, 917], [478, 909], [482, 954], [272, 950]], "查询时间"],
[[[272, 955], [483, 956], [475, 990], [269, 992]], "失效时间"]
]
}*左滑查看更多

进行测试验证后,输出结果如下:
import base64
import json
import requests
import pandas as pd
jkb_img = open('jkb-1.png', 'rb')
base64_data = base64.b64encode(jkb_img.read())
payload = json.dumps({
"template_id": "158ad1b39a4cba9ce4a1cade1fae2bb0740ccb10",
"img": str(base64_data, encoding="utf-8")
})
url = "https://[API-ID].execute-api.[REGION-ID].amazonaws.com.cn/prod/custom-ocr/"
response = requests.request("POST", url, data=payload)
df = pd.DataFrame.from_dict(json.loads(response.text))*左滑查看更多
输出结果:
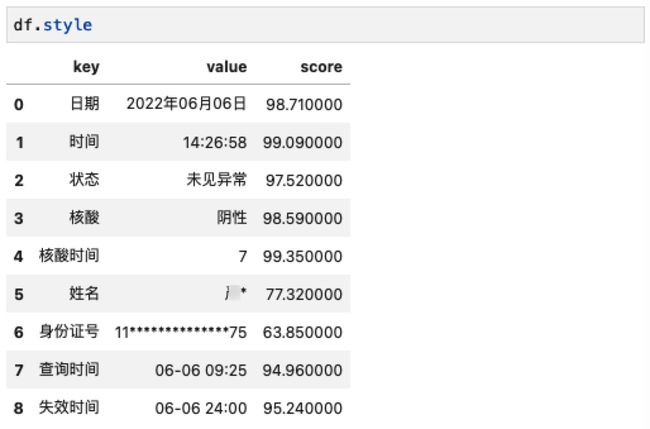
可见,模版OCR同样可以完成较复杂的北京健康宝的识别任务。最后,让我们来创建随申码的模版,创建随申码模版的JSON数据如下:
{
"type" : "add",
"img": "随申码参考样图的Base64编码"
"template": [
[[[189, 256], [257, 261], [261, 293], [192, 296]], "姓名"],
[[[140,366], [356,369], [350,406], [138,402]], "查询时间"],
[[[208,673], [285,675], [284,713], [211,712]], "状态"],
[[[108,774], [181,777], [181,838], [114,839]], "天数"]
]
}*左滑查看更多

随申码识别结果如下:
import base64
import json
import requests
import pandas as pd
jkb_img = open('xsm_1.png', 'rb')
base64_data = base64.b64encode(jkb_img.read())
payload = json.dumps({
"template_id": "531030f86c071571e54c19c9ac5c63751e97cddf",
"img": str(base64_data, encoding="utf-8")
})
url = "https://[API-ID].execute-api.[REGION-ID].amazonaws.com.cn/prod/custom-ocr/"
response = requests.request("POST", url, data=payload)
df = pd.DataFrame.from_dict(json.loads(response.text))*左滑查看更多
输出结果:
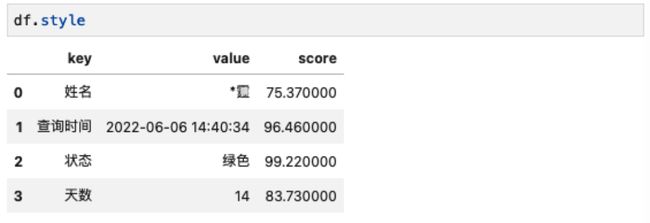
示例代码
文中示例代码请参考如下链接:
https://github.com/awslabs/aws-ai-solution-kit/tree/main/samples/custom-ocr-healthy-code
总结
AI Solution Kit解决方案中的模版文本识别功能通过自动部署预训练的文本识别模型,结合大词库,增强了对中文语言的处理与识别能力,能够通过预定义模版自动校正并识别结构化信息,从而提高了输入转化效率。
基于亚马逊云科技的Amazon CloudFormation 自动在Amazon API Gateway中创建调用RESTful API ,用户在部署解决方案后只需将 HTTP(s) 请求参数提交到 Amazon API Gateway 自动创建的 URL 即可实现文本识别功能。
该解决方案基于Amazon Lambda等无服务架构,用户无需运维任何基础设施,只需按实际使用量支付费用。用户数据全程不做持久化存储,计算和存储资源在API执行完毕后即销毁。AI Solution Kit开源解决方案中更多更有意思的功能等待您去探索。https://github.com/awslabs/aws-ai-solution-kit
本篇作者

严一
亚马逊云科技 创新解决方案架构师,负责基于 亚马逊云科技 的云计算方案的架构设计,在应用开发, Serverless, 大数据方向有丰富的实践经验。

何孝霆
亚马逊云科技 创新解决方案架构师,负责基于 亚马逊云科技 的云计算方案的架构设计,在应用开发, 人智能,Serverless方向有丰富的实践经验。

听说,点完下面4个按钮
就不会碰到bug了!