BERT论文解读:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT
相信热爱NLP的朋友都对BERT十分熟悉,google提出的这个模型在NLP的多项任务中都取得了惊人的成绩,是目前NLP领域最厉害的武器之一。本文会以原论文为基础来详细解读一下BERT的来龙去脉。
在此声明一下,我并不会完全按照原论文的顺序进行解读,而是根据自己的理解来重点介绍我认为核心或者比较重要的部分。OK,我们开始。
首先我们先来看一下论文的abstract部分的关于BERT的介绍。

这句高亮语句其实已经对BERT做出了非常准确的说明。首先,BERT是一个已经经过预训练的模型,同时BERT预训练使用的就是无标签的文本数据集合,还有就是BERT相较于其他的语言模型,每一层都充分地利用整个文本信息,既包括当前位置token的左边也包括右边,也就是实现双向信息利用。OK,接下来我来为大家做具体说明。
Model Architecture
关于BERT的模型架构,其实简单来说就是Transformer的encoder部分的多重堆叠。如果大家对Transformer的架构还不理解的话,可以阅读一下我之前的一篇文章----Transformer详解:基于self-attention的大杀器 或者也可以阅读Google2017年的介绍Transformer的原paper:Attention is all you need.
那么在本文中,作者使用的是12个Transformer block的堆叠,关于embedding的维度,作者选择的768,对于self-attention 的num_head,作者选取的参数是12.原文如下

然后我们把BERT和其他两个相关的模型OpenAI GPT 和 ELMo做一个简单的比较,如果大家对这两个模型的细节感兴趣,可以去阅读一下相关的paper,这里不会过多展开。先看一下在原论文附录中的这张图。
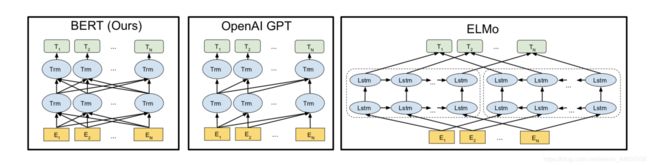
正如图中所示,BERT的每一层的transformer都是充分接收双向的信息,而对于GPT而言,它实现的是一个单向(left-to-right)的transformer。而对于ELMo,对于每个位置的token的输出,EMLo利用两个方向的LSTM的模型的输出的concate最终输出,确实这样的做法某种程度上也可以说完整利用了整个text的信息,但是毕竟这两个任务是独立的,相较于BERT的做法,这种concate的方法在语义的特征输出上只能算是次优的。
Model Input/Output Representations
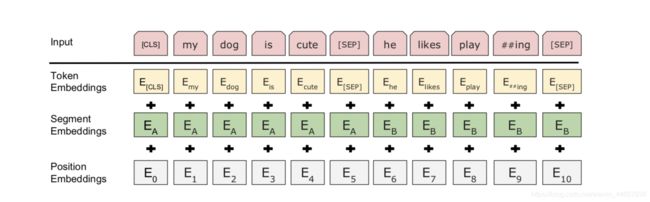
讲完模型的基本架构,我们在来思考另一个问题,模型的输入和输出的形式。我们知道BERT在多项NLP任务中都取得非常好的成绩,因此BERT必然是一个非常具有泛化能力的模型,那么自然模型的输入和输出设计自然也应该同时适用于多种不同任务的变化。那么BERT是如何做到这一点的呢?首先我们考虑一个简单的文本分类任务,根据single sentence 得到预测类别。那么面对这个问题,input端的设计就是将single sentence做tokenizaition,然后做一个max_len的设定就完事了。那么如果我们现在的原始数据是一个pair of sentences,比如
Pre-training BERT
在梳理完模型的架构和输入输出表示之后,我们已经对模型的整体有了一个大致的理解。现在我们进入几个核心细节问题的讨论。首先,前面已经提到了BERT是一个经过预训练的模型,同时是无监督(无标签)学习。那么究竟BERT究竟做了哪些预训练呢?
第一个任务叫做Masked LM(language model),我们知道传统的language model一般根据句子的语序进行建模以及训练(从左向右)。但是这训练得到的效果必然不如双向(bidirectional model),因此作者巧妙地采用masked 某些词汇,然后充分利用其左边的tokens 以及右边的tokens的信息来预测它们。在原文中,作者对于每个输入sequence随机mask掉15%的tokens作为待预测的tokens,同时在训练时,loss function也只focus这些masked tokens。但是这里有一个问题就是,因为在我们后续的fine-tuning任务中,我们是不会遇到所谓的[MASK] token的,那么如果将带有[MASK] token的pre-training任务训练得到的模型直接用在fine-tuning上,显然有点不太合理,毕竟[MASK]占到总token的15%。
 为了缓解这个问题,作者采用的方法是,我们在pre-training中对于被选中作为mask的tokens,我们只有80%的时间里使用[MASK],然后分配10%的时间显示真实的token,然后剩下10%的时间显示一个random的token。至于为什么要这么分配,结合作者的一些说明以及我自己的理解,解释如下,首先,10%分配给真实token让模型看见是为了使我们的output representation能够尽可能向我们的‘真实’ 靠拢(给一点额外的bias),但是又分配10%给random tokens, 让transformer encoder不知道究竟被random inputs替代的真实是什么,人为制造出一个分布式的表征,防止Transformer直接记住这个[MASK]的真实值。同时,因为对于整体的token而言,随机的替换只发生15%*10%,也就是1.5%,因此这样程度的替换并不会对模型的整体理解能力造成比较大的影响。
为了缓解这个问题,作者采用的方法是,我们在pre-training中对于被选中作为mask的tokens,我们只有80%的时间里使用[MASK],然后分配10%的时间显示真实的token,然后剩下10%的时间显示一个random的token。至于为什么要这么分配,结合作者的一些说明以及我自己的理解,解释如下,首先,10%分配给真实token让模型看见是为了使我们的output representation能够尽可能向我们的‘真实’ 靠拢(给一点额外的bias),但是又分配10%给random tokens, 让transformer encoder不知道究竟被random inputs替代的真实是什么,人为制造出一个分布式的表征,防止Transformer直接记住这个[MASK]的真实值。同时,因为对于整体的token而言,随机的替换只发生15%*10%,也就是1.5%,因此这样程度的替换并不会对模型的整体理解能力造成比较大的影响。
第二个任务叫做Next Sentence Prediction(NSP)。在面对一些pair-sentence输入的下游任务中,模型需要能够洞察两个语句的相关性。而这一点是language model无法直接捕捉到的。因此除了上面的第一个MLM之外,作者又设计了NSP。简单来说我们设计一个数据集。其中A代表first sentence,B代表second setence。在这个数据集中,一半的A,B是真实的上下句衔接,而对于另一半的数据,B是随机的next sentence,也就是说A,B并不是真实的上下句。通过训练,希望模型能够正确的识别上下句关系。下面是原论文中的相关说明

Fine-tuning
OK,当我们已经完成了pre-training,接下来,我们可以将这个模型运用到各种下游任务中去了,不管是single-sentence input的任务还是text-pair的任务,BERT都可以handle。原论文中,作者共尝试了11个不同的NLP任务。这边列出几个具有代表性的task来做一下大致说明。下图同样拷贝自原论文。
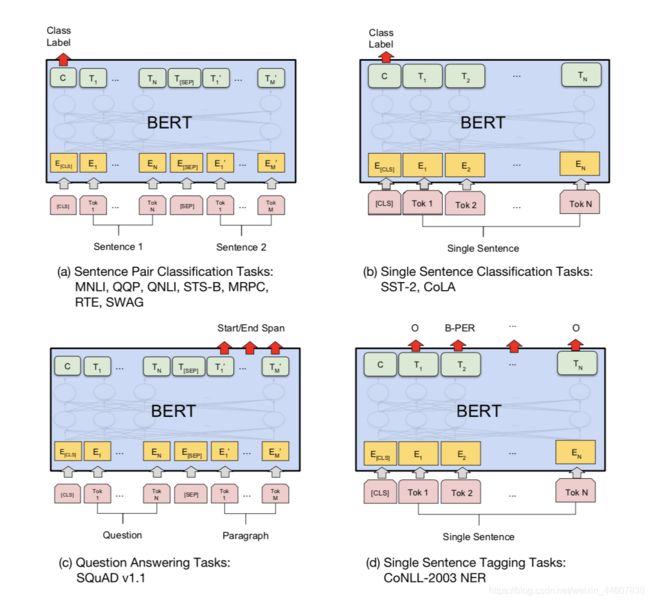
首先我们先对fine-tuning做一个基本的说明,fine-tuning可以简单地理解为首先我们已经根据大量的corpus训练好了一个基础语言模型(pre-training),然后我们将它应用到下游任务时,只需要在这个基础模型上添加一些task-specific layers,然后根据下游任务的数据重新训练。总结来说,在fine-tuning的训练过程中,task-specific layers的参数和BERT本身的参数都是需要更新的。
OK,那我们先来看一下上图左上角的这类任务。Sentence Pair Classification Tasks,简而言之就是我们的输入是2个sentences,然后模型的输出是一个类别标签,比如MNLI(Multi-Genre Natural Language Inference)任务就是用模型来判断第二个sentence是与第一个sentence呈赞同,反对还是中立的态度,那么就是一个三分类的问题。再比如像QQP(Quora Question Pairs) 就是一个典型的二分类问题,我们的输入会是Quera的两个问题,然后让模型来判断这两个问题是否在语义上相近。这里我们依赖的最后输出是[CLS]token(第一个token)对应位置的hidden layer output。比如我们在这个位置的输出为一个512维的vector。然后比如我们面对一个三分类的问题,我们就再接一个input_dim=512,output_dim=3的全连接层,然后将输出做softmax得到概率最大的那个作为预测的标签。在fine-tuning的过程中重点是用我们自己带标签的任务数据去训练这个(512,3)的权重矩阵,但是一般我们会设置BERT基础模型的参数也为trainable,也就是在训练过程中也会包括BERT的参数更新,对它们在特定任务下进行微调,尽管它们已经经过了大量语料的pre-training。
右上角的single sentence classification tasks这里就不过多展开了,就是最基本的NLP文本分类任务。我们接下来来重点看一下左下角的这类任务,Question Answering Tasks–SQuAD v1.1。具体的意思就是说我们希望让模型看到一个question,和一段document,然后希望模型能够得到question对应的answer在document的哪个位置,输出一个start和一个end的位置(s , e) 。当然对于这个问题,我们基于的假设还是answer必定会出现在我们的document中。但是在SQuAD v2.0中,我们放宽了假设,让answer不一定出现在document中,但是我们这里还是主要讨论一下v1.1。OK,那么具体我们该怎么做呢?我们需要的是输入一堆标注有answer位置(s,e)的question-document pair,然后在fine-tuning阶段的目标是去学到两个vector,一个是S,一个是E,分别代表 start vector和end vector,它们的维度都等于BERT的最后hidden layer输出的embedding 维度。对于我们的一个新的question-document pair,在document部分的每个token对应有一个输出Ti,i=1,2,…n。n=document中token的个数。然后我们拿我们的每个Ti和fine-tuning训练得到的S和E分别做dot product。然后再经过softmax处理得到概率分布。与S得到的最大概率位置为我们的预测开始位置s,与E得到的最大概率位置为我们的预测结束位置e。从而我们得到我们的(s,e)对应的document text。

关于如何训练得到S,E,这两个vector的训练通过监督学习完成。具体来说,我们给定训练样本,包括question-document pair和answer在document的位置(s , e)。在真实的answer位置的token设置为1,其余位置均为0。然后我们在训练的每个阶段,都会得到每个位置为s和e的概率分布(通过softmax),那么我们的训练目标就是让这个概率分布和我们的真实分布(for both s和e),类似于这种,[0,0,1,0,0,…]的差距最小。

我们最后再来快速看一下右下角的最后一类任务。Single Sentence Tagging Task,其实本质上就是预测sentence中每个token对应的Entity。当然我们也可以使用BERT fine-tuning的方式去解决这个问题,但是对于这个问题,作者尝试了另一种方法,也就是 Feature-based Approach。这里先简单介绍一下Feature-based Approach。在NLP领域,可以理解为用预训练模型训练产生的词向量,作为提取的特征用来作为下游任务的输入补充特征。那么对于我们的BERT而言,我们知道它是通过堆叠多个transformer encoder来提取语义信息的,那么有那么多层的embedding,我们究竟该使用哪一层呢?在原文中作者共使用了6种不同的方式,如下

我们可以看到其中包括最后一个hidden layer的output, 最后4层的加权平均以及全部12层的加权平均等。然后我们看到concat last 4 layers作为特征的结果达到96.1,是其中最好的,当然作者也使用了fine-tuning的方式来解决这个task,结果是96.4,相差并不明显。因此,对于BERT而言,我们使用feature-extraction的方式被证明也能在下游任务中取得非常好的效果。
好了,关于BERT这篇paper的介绍先写到这里,从我个人理解的角度,我认为已经把最重要的部分全部讲清楚了,当然还有一些具体的实现细节,希望大家还是自己去认真读一下原文。如果有想到什么遗漏的,我会在后续的博客中继续补充。
最后祝大家生活愉快哈~
参考:
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
arxiv.org/pdf/1810.04805.pdf
B站上一个非常不错的讲解视频,下面是链接
https://www.bilibili.com/video/BV1qb411h75Jfrom=search&seid=100494164155061466