一文看懂大数据测试
1、什么是大数据?
大数据是一个大的数据集合,通过传统的计算技术无法进行处理。这些数据集的测试需要使用各种工具、技术和框架进行处理。大数据涉及数据创建、存储、检索、分析,而且它在数量、多样性、速度方法都很出色,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
一文看懂大数据测试

2、大数据测试类型
测试大数据应用程序更多的是验证其数据处理,而不是测试软件产品的个别功能。当涉及到大数据测试时,性能和功能测试是关键。
处理可以是三种类型:批量、实时、交互
在测试应用程序之前,有必要检查数据的质量,并将其视为数据库测试的一部分。它涉及检查各种字段,如一致性,准确性,重复,一致性,有效性,数据完整性等。
3、测试步骤
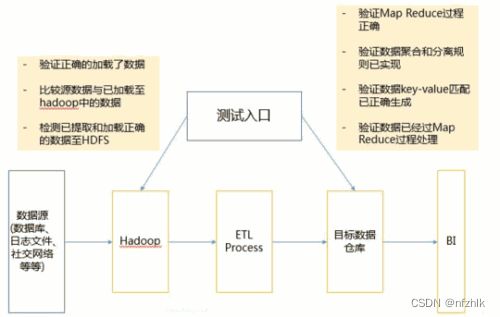
一文看懂大数据测试
步骤一、数据预处理验证
在进行大数据测试时,首先要预hadoop前验证数据的准确性等等。
我们数据来源可能是关系数据库、日志系统、社交网络等等,所以我们应该确保数据能正确地加载到系统中,我们要验证:
加载的数据和源数据是一致的
确保正确的提取和加载数据至HDFS中
步骤二、Map Reduce验证
在进行大数据测试时,第二个关键步骤是“Map Reduce”验证。在本阶段,我们主要验证每一个处理节点的业务逻辑是否正确,并验证在多个运行后,确保:
Map Reduce过程工作正常
数据聚合、分离规则已经实现
数据key-value关系已正确生成
验证经过map reduce后数据的准确性等特性
步骤三、结果验证
在本阶段主要验证在经过大数据工具/框架处理后,生成的最终数据的成果。
检查转换(Transformation)规则被正确应用
检查数据完整性和成功的数据加载到目标系统中
4、性能测试
性能是评估一个大数据分析系统的最为关键的维度,大数据系统性能主要包括吞吐量,任务完工时间,内存利用率等多个指标,可反应大数据分析平台的处理能力,资源利用能力等性能。可通过hadoop性能监控器来监测运行状态性能指标和瓶颈问题,性能测试采用自动化化方式进行,测试系统在不同负载情况下的性能。
5、容错性测试
可从部分失效中自动恢复,而且不会验证的影响整体性能,特别地,当故障发生时,大数据分析系统应该在进行恢复的同时继续以可接受的方式进行操作,在发生错误时某种程度上可以继续操作,需根据应用场景来设计解决方案和具体部署,然后手动测试。
6、可用性测试
高可用性也是大数据分析不可或缺的特性之一,从而保证数据应用业务的连续性.大数据高可用性对很多应用非常关键,需要严格进行测试和验证,以手动测试为主。
7、扩展性测试
弹性扩展能力对于大数据时代的文件系统尤其重要,文件系统扩展性测试主要包括测试系统弹性扩展能力(扩展/回缩)及扩展系统带来的性能影响,验证是否具有线性扩展能力,以手动测试为主。
8、稳定性测试
大数据分析系统通常是不间断长期运行,稳定性的重要性不言而喻,稳定测试主要验证系统在长时间(7/30/180/365*24)允许下,系统是否仍然能够正常运行,功能是否正常.稳定性测试通常采用自动化方式进行,LTP,10ZONE,POSTMARK,FIO等工具对测试系统产生负载,同时需要验证功能。
9、部署方式测试
大数据具备scale-out的特点,能够构建大规模,高性能的文件系统集群。针对不同应用和解决方案,文件系统部署方式会有显著不同;部署方式测试需要测试不同场景下的系统部署方式,包括自动安装配置,集群规模,硬件配置(服务器,存储,网络),自动负载均衡等,这部分测试不大可能进行自动化测试,需要根据应用场景来设计解决方案和具体部署,再进行手动测试。
10、数据一致性测试
这里的数据一致性是指文件系统中的数据与从外部写入前的数据保持一致,即写入数据与读出数据始终是一致的。数据一致性能够表明文件系统可保证数据的完整性,不会导致数据丢失或数据错误,这是文件系统最基本的功能,测试可用diff,md5sum编写脚本自动化测试,LTP也提供了数据一致性的测试工具。
11、压力测试
大数据分析系统的负载能力是存在上限的,系统过载时,系统就可能存在性能下降,功能异常,拒绝访问等问题。压力测试是验证系统造大压力下,包括数据多客户端,高OPS压力,高IOPS/吞吐量压力,系统是否仍然能够正常运行,功能是否正常,系统资源消耗情况,从而为大数据运营提供依。
12、大数据技术板块划分
数据采集
flume kafka logstash filebeat …
数据存储
mysql redis hbase hdfs …(虽然mysql不属于大数据范畴,但是我在这也列出来了,因为你在工作中离不开它)
数据查询
hive impala elasticsearch kylin …
数据计算
实时计算
storm sparkstreaming flink …
离线计算
hadoop spark …
zookeeper …
13、大数据学习步骤
1)linux基础和javase基础(包含mysql)
这些是基本功,刚开始也不可能学得很精通,最起码要对linux中的一些基本的命令混个脸熟,后面学习各种框架的时候都会用到,用多了就熟悉了。javase的话建议主要看面向对象,集合,io,多线程,以及jdbc操作即可。
2)zookeeper
zookeeper是很多大数据框架的基础,中文名称是动物园的意思,因为目前的大数据框架的图标很多都是动物的形状,所以zookeeper其实就是可以管理很多大数据框架的。针对这个框架,主要掌握如何搭建单节点和集群,以及掌握如何在zkcli客户端下对zookeeper的节点进行增删改查操作即可。
3)hadoop
目前企业中一般都是用hadoop2.x的版本了,所以就没有必要再去学hadoop1.x版本了,hadoop2.x主要包含三大块hdfs 前期,主要学习hdfs的一些命令即可,上传,下载,删除,移动,查看等命令…mapreduce 这个需要重点学习下,要理解mr的原理以及代码实现,虽然现在工作中真正写mr的代码次数很少了,但是原理还是要理解的。
yarn 前期了解即可,只需要知道yarn是一个资源调度平台,主要负责给任务分配资源即可,yarn不仅可以给mapreduce任务调度资源,还可以为 spark任务调度资源…yarn是一个公共的资源调度平台,所有满足条件的框架都可以使用yarn来进行资源调度。
4)hive
hive是一个数据仓库,所有的数据都是存储在hdfs上的,具体【数据仓库和数据库】的区别大家可以去网上搜索一下,有很多介绍。其实如果对 mysql的使用比较熟悉的话,使用hive也就简单很多了,使用hive主要是写hql,hql是hive的sql语言,非常类似于mysql数据库的 sql,后续学习hive的时候主要理解一些hive的语法特性即可。其实hive在执行hql,底层在执行的时候还是执行的mapredce程序。
注意:其实hive本身是很强大的,数据仓库的设计在工作中也是很重要的,但是前期学习的时候,主要先学会如何使用就好了。后期可以好好研究一下hive。
5)hbase
hbase是一个nosql 数据库,是一个key-value类型的数据库,底层的数据存储在hdfs上。在学习hbase的时候主要掌握 row-key的设计,以及列簇的设计。要注意一个特点就是,hbase基于rowkey查询效率很快,可以达到秒级查询,但是基于列簇中的列进行查询, 特别是组合查询的时候,如果数据量很大的话,查询性能会很差。
6)redis
redis也是一个nosql(非关系型数据库) 数据库和key-value类型的数据库,但是这个数据库是纯基于内存的,也就是redis数据库中的数据都是存储在内存中的,所以它的一个特点就是适用 于快速读写的应用场景,读写可以达到10W次/秒,但是不适合存储海量数据,毕竟机器的内存是有限的,当然,redis也支持集群,也可以存储大量数据。在学习redis的时候主要掌握string,list,set,sortedset,hashmap这几种数据类型的区别以及使用,还有 pipeline管道,这个在批量入库数据的时候是非常有用的,以及transaction事务功能。
7)flume
flume是一个日志采集工具,这个还是比较常用的,最常见的就是采集应用产生的日志文件中的数据。一般有两个流程,一个是flume采集数据存 储到kafka中,为了后面使用storm或者sparkstreaming进行实时处理。另一个流程是flume采集的数据落盘到hdfs上,为了后期 使用hadoop或者spark进行离线处理。在学习flume的时候其实主要就是学会看flume官网的文档,学习各种组件的配置参数,因为使用 flume就是写各种的配置。
8)kafka
kafka 是一个消息队列,在工作中常用于实时处理的场景中,作为一个中间缓冲层,例如,flume->kafka->storm/sparkstreaming。学习kafka主要掌握topic,partition,replicate等的概念和原理。
9)storm
storm是一个实时计算框架,和hadoop的区别就是,hadoop是对离线的海量数据进行处理,而storm是对实时新增的每一条数据进行处理,是一条一条的处理,可以保证数据处理的时效性。学习storm主要学习topology的编写,storm并行度的调整,以及storm如何整合 kafka实时消费数据。
10)spark
spark 现在发展的也很不错,也发展成了一个生态圈,spark里面包含很多技术,spark core,spark steaming,spark mlib,spark graphx。
spark生态圈里面包含的有离线处理spark core,和实时处理spark streaming,在这里需要注意一下,storm和spark streaming ,两个都是实时处理框架,但是主要区别是:storm是真正的一条一条的处理,而spark streaming 是一批一批的处理。
spark中包含很多框架,在刚开始学习的时候主要学习spark core和spark streaming即可。这个一般搞大数据的都会用到。spark mlib和spark graphx 可以等后期工作需要或者有时间了在研究即可。
11)elasticsearch
elasticsearch是一个适合海量数据实时查询的全文搜索引擎,支持分布式集群,其实底层是基于lucene的。在查询的时候支持快速模 糊查询,求count,distinct,sum,avg等操作,但是不支持join操作。elasticsearch目前也有一个生态 圈,elk(elasticsearch logstash kibana)是一个典型的日志收集,存储,快速查询出图表的一整套解决方案。在学习elasticsearch的时候,前期主要学习如何使用es进行增 删改查,es中的index,type,document的概念,以及es中的mapping的设计。