A ConvNet for the 2020s论文阅读笔记
ConvNeXt阅读笔记
-
- (一) Title
- (二) Summary
- (三) Research Object
- (四) Problem Statement
- (五) Method
- (六) Experiments
-
- 6.1 ConvNeXt结构设计
- 6.2 ImageNet实验
- 6.3 目标检测任务和分割任务中的表现
- (七) Conclusions
- (八) Questions
(一) Title

论文地址:https://arxiv.org/abs/2201.03545
代码地址:https://github.com/facebookresearch/ConvNeXt
前言:这个文章重新燃起了对于卷积网络的兴趣,更重要的是在Transformer硬件化不太成熟的现在,一个具有更加优秀性能的卷积网络真的非常实用。然而,博主觉得整个模型设计的roadmap需要大量的实验来验证,也进行了很精细的设计,如果说对于Transformer结构同样进行更加精细的设计,是否能够在性能上取得更好的结果呢?(只是个人的粗浅感想)
(二) Summary
研究背景:
自从Vision Transformers(ViTs)的引入,在SOTA的图像分类任务上已经逐渐取代了ConvNets,到底是什么原因使得Vision Transformer能够起到更好地作用呢?
文中给出的理由是:the superior scaling behavior of Transformers with multi-head self-attention being the key component,这里的scaling behavior指的又是什么呢?这里说的应该是模型size以及对于数据量的scale能力,不同大小的模型在不同规模的数据或者不同视觉任务中都能够有出色的表现。
然后普通的ViT当应用到下游任务检测或者语义分割中时face difficulties,这里说的面临的difficulties到底是什么呢?
这里最大的问题是global attention design,attention的计算复杂度是同输入图像的尺寸成二次关系的,在图像分类中计算量不大,但是引入到目标检测以及分割任务中,计算量就会相当显著了。
hierarchical Transformers的设计重新引入了ConvNet的先验prior(实际上也就是inductive bias),在分层结构的帮助下,Swin Transformer等能够在各种各样的视觉任务中表现出显著的作用。卷积的Prior是什么呢?
CNN的inductive bias应该是locality和spatial invariance,translation equivariance.即空间相近的grid elements有联系而远的没有,和空间不变性(kernel权重共享)引自:https://www.zhihu.com/question/264264203
然而这种hybrid方式在很大程度上还是要归功于Transformer的intrinsic superiority,而并不是来自于卷积的固有inductive bias为什么前面提到说从卷积的先验中引入hierarchical设计,这里又说这种混合方式的成功实际上是依赖于Transformer的内在优势呢?
在Swin Transformer中除了,hierarchical transformer设计之外,还引入了local window attention,用于构建局部的attention,从本质上来看,是在让Transformer more likely with卷积,因为这里同样体现的是卷积的本质"locality".这叫什么?这叫如虎添翼嘛?
而且从Transformer的一些改进来看,在其中有一些往卷积上转换的意味,然而一个naive sliding window slef-attention的实现是expensive应该怎么实现naive sliding window self-attention呢?,为了将sliding window引入进行,出现了cyclic shifting(swin transformer)的设计,其实这里应该也没问题,只不过目前的硬件对于这种操作并不支持,也没有进行很好的优化,从而显得比较复杂。
然而,由于Hierarchical Transformer的在许多视觉任务上的设计超过了卷积神经网络,大量研究人员抛弃了ConvNets转战Transformer,
ConvNet和hierarchical Transformer的相同之处在于similar inductive biases,不同之处在于training procedure 以及 macro/micro-level 架构上的设计
本文内容
一个Pure ConvNets能够到达的极限是什么?难道说Transformer的效果一定会比ConvNet好嘛?为了解释上面的问题,我们从ResNet出发,在整理卷积模型的设计空间中(也就是卷积的结构设计研究中)去check对于模型性能提升有帮助design,不断地改进标准ResNet结构.从哪些trick开始呢?怎么选择design的结构呢?这篇文章给出一个reference,可以参考这里的设计来帮助提点儿
实验结果
本文提出的“modernize ResNet”称作ConvNeXt,它在准确性和可扩展性上由于transformer,实现了87.8的ImageNet准确率,在COCO detection以及ADE20k分割方面优于Swin Transformer,同时还保持了标准卷积的简单性和效率。
(三) Research Object
卷积神经网络在经历了近10年的发展,取得了突出的成绩,然而Transformer的横空出世打破了视觉领域的平静,取得的更好成绩使得大家纷纷涌入Transformer,如何利用之前卷积网络研究构成的design space以及Transformer结构来设计更加合理的全卷积结构呢?如何将一个ResNet50从Top1 Acc从76.1%提升到82.0%?作者通过本文给出了一个参考答案。
(四) Problem Statement
ConvNets的inductive bias在Transformer的设计中不断引入,并在各种各样的任务中取得了不错的性能表现,而Transformer在training procedure以及架构设计上同CNN是不一样的,
- 怎么样能够参考Transformer的架构设计,对ConvNet进行改进,或者说将ConvNet同Transformer进行比较呢?
- 有没有可能在架构设计上ConvNet同Transformer一一近似对标起来呢?
- Tranformer中的design decisions是怎么影响ConvNets的性能呢?
(五) Method
思考:本文的意图是ConvNet对标Transformer,首先,选定Transformer和ConvNet,从FLOPs大小上出发,选择了两组,第一组为ResNet-50/Swin-T FLOPs大概为 4.5 × 1 0 9 4.5 \times 10^9 4.5×109,第二组为ResNet-200/Swin-B FLOPs大概为 15.0 × 1 0 9 15.0 \times 10^9 15.0×109
本文设计了一个从ResNet50到ConvNeXt-T 的路线图如下所示:
图中深色的为ResNet50/Swin-T的,浅色的为ResNet200-Swin-B的,上面的一系列设计总结下来包括:宏观设计,ResNeXt,inverted bottleneck,更大的kernel size以及不同的layer-wise micro designs.并且在模型设计过程中对于模型的FLOPs进行了大致上的控制。
整个过程:
训练策略(76.1%->78.8%)
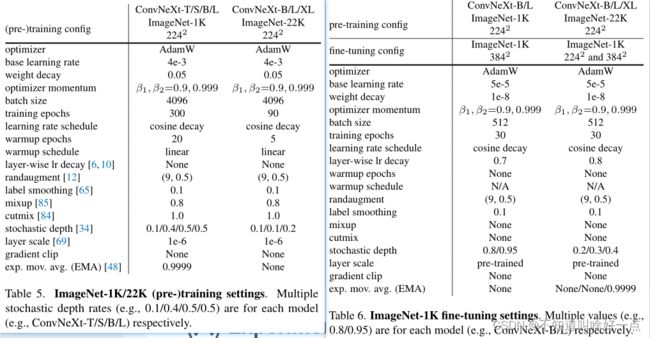
将Transformer的训练策略,引入到ResNet50训练过程中,具体的训练参数配置如下所示,采用了同Transformer相同的训练过程。
采用上面的训练策略,使得模型的性能从76.1%提升到78.8%,也就是说卷积神经网络同Vision Transformer之间的差异很可能是由于训练技术不同造成的。文中说we use a training recipe that is close to DeiT’s以及Swin Transformer’s,这里DeiT和Swin的训练设置又是什么样子的呢?宏观设计,这里从两个方面出发:the stage compute ratio以及the stem cell structure
Stage Compute Ratio 78.8%->79.4%
参考swin transformer四个stage的compute ratio(1:1:3:1),将原始ResNet50(3,4,6,3)的compute ratio改成ResNet-50(3,3,9,3)可能论文里的s3是写错了?Stem Cell Structure(79.4%->79.5%)
stem cell指的是在网络的开始位置,输入图像的处理方式。这主要是由于自然图像中往往包含较多的冗余,stem cell的作用是将原始图像下采样到具有合适大小的特征图上.
在ConvNets和Vision Transformer中同时存在,只不过处理方式不一样,
原始ResNet中采用步长为2的 7 × 7 7\times7 7×7卷积,接着通过max pool下采样,得到输入图像为原始图像的4倍下采样。
ViT中采用很大的Kernel Size(14或者16)然后进行non-overlapping convolution。
Swin Transformer中采用更小的patch size来适应multi-stage的设计。
为了能够同Transformer结构的stem cell匹配上,这里采用 4 × 4 4\times4 4×4步长为4的卷积(即patchify,因为没有相交),模型精度从79.4%->79.5%,从计算量来看要更小ResNeXt-ify
采用ResNeXt中的思想(bottle neck中的3x3卷积采用分组卷积,并通过扩大网络宽度来弥补capacity loss,相比于ResNet具有更好的FLOPs/accuracy trade-off)
这里本文的思路是采用depthwise convolution,是分组卷积的一种特殊情况(分组数和卷积通道数相同),这里指出为什么说depthwise convolution和weighted sum operation in self-attention是相近的呢?通过增加网络的channels数量提升网络性能.
bottleneck中使用depthwise 卷积替换普通卷积:79.5%->78.3%
增加network width从64到96,这里的width指的是什么?:78.3%->80.5%Inverted Bottleneck
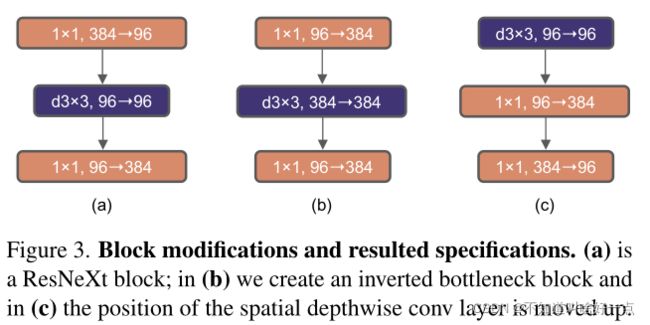
从Transformer block中可以看到MLP block中的隐状态维度是输入维度的4倍,在MobileNetv2中inverted bottleneck的设计就得到了应用,因此,这里思考采用inverted bottleneck结构的设计。
这里采用的是( b )的结构嘛?为什么说FLOPs会下降呢?文中说是shortcut 1 × 1 1\times1 1×1conv layer的作用,实验结果的话,是从80.5%->80.6%,在ResNet-200/Swin-B结构中从81.9%->82.6%。Large Kernel Sizes
Vision Transformer最distinguishing aspects是他的non-local self-attention,从而使得每一层都有一个global receptive field.虽然ConvNets也使用多较大的卷积核size,可是 3 × 3 3\times3 3×3是gold standard(黄金标准),并且在GPUs上也有高效的硬件实现.Swin Transformer中使用的是local attention,但是这里窗口的大小为 7 × 7 7 \times 7 7×7,要比ResNeXt 3 × 3 3 \times 3 3×3的大小大很多,使用更大的卷积核是否对性能提升有帮助呢?
Move up depthwise conv layer:80.6%->79.9%
将depthwise 卷积从图3中的b位置向上移动到c位置处,这种结构上的设计也是参考Transformer设计:在Transformer中MSA层防止在MLP层的前面。一个很自然的设计就是:复杂低效的MSA具有更少的通道,而高效密集的 1 × 1 1\times1 1×1的卷积将完成复杂的工作,这种方式会使得性能从80.6%->79.9%
Increasing the kernel size:
采用更大的卷积核带来的提升也是比较显著的,这里测试了3,5,7,9,11.模型性能从79.9%( 3 × 3 3\times 3 3×3)->80.6%(7\times 7),而FLOPs依旧保持不变,当卷积核大小超过 7 × 7 7\times7 7×7之后,达到了饱和,再继续增加不会带来更多的增益了。Micro Design
在微观尺度的结构进行调整,主要是激活函数和正则化层
用GELU替换ReLU:80.6%->80.6%
GELU是ReLU的平滑版本,使用GELU替换掉ReLU之后,精度上并没有发生变化
更少的激活函数:80.6%->81.3%
Transformer和ConvNets的一个区别是Transformer中只有在MLP block中存在着一个激活函数,在卷积中几乎每一个卷积层之后都会增加激活函数(包括 1 × 1 1\times1 1×1的卷积),这里ConvNeXt采用的方案是将residual block中的GELU层全部取消掉,除了两个 1 × 1 1\times1 1×1层之间
通过这种方式,能够将模型性能提升0.7%,相对来说是比较大的提升.
更少的正则化层:81.3%->81.4%
Transformer中的正则化层也很少,这里ConvNeXt的设计中去掉了 1 × 1 1\times 1 1×1的两个BN层,仅仅保留了 1 × 1 1\times1 1×1前面的Batch Normalization,这里使得模型性能提升0.1%,最终ConvNeXt中每一个block中的正则化层比Transformer还要少,并且在实验中发现,在residual block前面增加一个BN layer并不会提升性能。
用LN替换BN:81.4%->81.5%
在视觉任务中BN还是占有主导地位,而在Transformer中,使用了更加简单的Layer Normalization(LN),直接在卷积网络中使用LN替换掉BN中会使得模型性能变差,然而随着之前网络架构的改变以及训练方式的变换,这里发现LN在卷积网络中的训练没有任何困难,算法性能从81.4%->81.5%这里有点儿想吐槽的是,越来越像实验学了,只能通过实验来说明,然而结论会随着训练策略和网络结构的改动发生变化.看着没啥规律啊!
将下采样层分离
在ResNet中,每一个residual block中的空间下采样通常是在每一个stage的起始位置,通过一个步长为2的 3 × 3 3\times 3 3×3卷积(在shortcut中使用步长为2的 1 × 1 1\times1 1×1卷积)。在swin transformer中每一个stage之间使用的是一个单独的下采样层,通过一个步长为2的 2 × 2 2\times2 2×2的卷积层进行空间下采样。
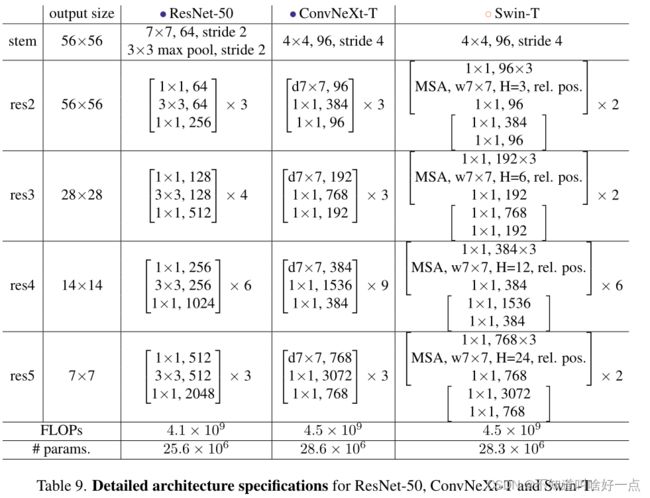
进一步的研究中发现,在空间分辨率发生变化的地方增加归一化层有助于稳定训练,在Swin Transformer中使用的LN层,一个在每一个下采样层的前面,一个在stem之后另一个在最后的global average pooling之后,这里准确率从81.5%提升到82.0%,超过了swin-T的81.3%。最终得到了我们的模型,ConvNeXt.ResNet-50,ConvNeXt-T以及Swin-T的比较是:


(六) Experiments
6.1 ConvNeXt结构设计
不同Scal的ConvNeXt变体
不同的变体在通道数量以及block数量上有所不同,具体的配置情况如下所示:

6.2 ImageNet实验
ImageNet-1K数据集上的训练
采用AdamW,学习率4e-3,20个epoch的warmup以及cosine decaying策略,使用batch size大小4096,weight decay为0.05,对于数据增强采用了Mixuo,Cutmix,RandAugment,Random Erasing,使用随机深度以及标签平滑来正则化网络,采用初始值为1e-6的Layer Scale。使用EMA来缓解大型模型的过拟合。
ImageNet-22k的预训练
这里在ImageNet-22K上训练90个epoch,warmup预训练在前5个epoch,这里不使用EMA,其他的设置都同ImageNet-1K相同
在ImageNet-1K上fine-tune
使用ImageNet-22K预训练好的模型在ImageNet-1K上训练30个epoch,使用AdamW,学习率5e-5,余弦学习率策略,layer-wise learning rate decay,不使用warmup,batch size大小为512,weight decay为1e-8,模型pre-training,fine-tuning,testing resolution都是224,在fine-tune的时候采用的是384的分辨率。使用全卷积网络能够对不同大小的图像进行适配。
实验结果如下所示:
性能好,并且对于部署友好,此外具有更高的推理吞吐量,推理效率更高。之前普遍认为是的Vision Transformer中只有较少的inductive biases,所以在更大规模的预训练下比卷积网络表现得更好。然而这里适当设计的卷积网络在采用大规模数据集预训练时,并不逊色于Vision Transformer了
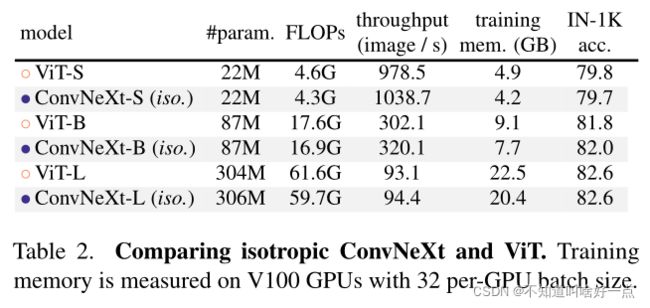
Isotropic ConvNeXt同ViT比较
在ViT-style中没有下采样层,并且具有相同的feature resolutions,我们构建了Isotropic ConvNeXt同ViT结构进行比较,block结构依旧同图4中保持一致,ViT-S/B采用了DeiT的监督训练结果,ViT-L采用了MAE的预训练,ConvNeXt跟之前的训练保持一致,不过warmup epoch更长了,实验结果如下:
我们的ConvNeXt在非分层( non-hierarchical)结构中同样表现很好。

6.3 目标检测任务和分割任务中的表现
在COCO数据集上使用ConvNeXt骨干网络对Mask R-CNN以及Cascade Mask R-CNN进行了fine-tune,在swin transformer中使用多尺度训练,AdamW优化器以及3x训练策略。
在下游任务中同样验证了我们模型设计的有效性。ConvNeXt消耗更少的显存,同时具有更好地准确率-FLOPs bias,这种提升主要是依赖于之前卷积网络的prior工作,而不是Vision Transformer的self-attention机制造成的。

(七) Conclusions
2020s,Transformer特别是swin Transformer开始取代ConvNets成为通用视觉骨干的首选,人们往往认为Transformer比卷积网络更加精确,更高效,可扩展性更强,然而我们提出的ConvNeXt可以保持ConvNets的简单和效率,同时具备和Transformer匹配的性能,尽管我们的设计都不是全新的,我们希望人们能够重新思考卷积在计算机视觉中的重要作用
(八) Questions
Vision Transformer到底有什么优势或者特征,使得其能够在图像分类任务中取代ConvNets呢?
为什么文献[23]中说local Transformer attention和inhomogenous dynamic depthwise conv是等价的呢?