好像还挺好玩的GAN8——SRGAN实现图像的分辨率提升
好像还挺好玩的GAN8——SRGAN实现图像的分辨率提升
- 注意事项
- 学习前言
- 什么是SRGAN
- 代码与训练数据的下载
- 神经网络组成
-
- 1、生成网络
- 2、判别网络
- 训练思路
-
- 1、对判别模型进行训练
- 2、对生成模型进行训练
- 全部代码
-
- 1、data_loader全部代码
- 2、主函数全部代码
注意事项
该博客已经有重置版啦,重制版代码更清晰,效果更好一些:
https://blog.csdn.net/weixin_44791964/article/details/110630254
学习前言
SRGAN可以提升图像分辨率,俺很感兴趣,有必要了解一下。

什么是SRGAN
SRGAN出自论文Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network。
其主要的功能就是输入一张低分辨率图片,生成高分辨率图片。
文章提到,普通的超分辨率模型训练网络时只用到了均方差作为损失函数,虽然能够获得很高的峰值信噪比,但是恢复出来的图像通常会丢失高频细节。
SRGAN利用感知损失(perceptual loss)和对抗损失(adversarial loss)来提升恢复出的图片的真实感。
其中感知损失是利用卷积神经网络提取出的特征,通过比较生成图片经过卷积神经网络后的特征和目标图片经过卷积神经网络后的特征的差别,使生成图片和目标图片在语义和风格上更相似
对抗损失由GAN提供,根据图像是否可以欺骗过判别网络进行训练。
代码与训练数据的下载
这是我的github连接,代码可以在上面下载:
https://github.com/bubbliiiing/GAN-keras
这个是DIV高清图:
https://data.vision.ee.ethz.ch/cvl/DIV2K/DIV2K_train_HR.zip
大家也可以用其它的数据集进行训练:
人脸重建可以试试这些人脸数据集:
https://www.cnblogs.com/haiyang21/p/11208293.html
神经网络组成
1、生成网络
生成网络的构成如下图所示:
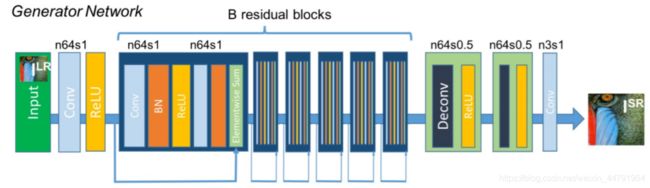
此图从左至右来看,我们可以知道:
SRGAN的生成网络由三个部分组成。
1、低分辨率图像进入后会经过一个卷积+RELU函数
2、然后经过B个残差网络结构,每个残差网络内部包含两个卷积+标准化+RELU,还有一个残差边。
3、然后进入上采样部分,将长宽进行放大,两次上采样后,变为原来的4倍,实现提高分辨率。
前两部分用于特征提取,第三部分用于提高分辨率。
def build_generator(self):
def residual_block(layer_input, filters):
d = Conv2D(filters, kernel_size=3, strides=1, padding='same')(layer_input)
d = BatchNormalization(momentum=0.8)(d)
d = Activation('relu')(d)
d = Conv2D(filters, kernel_size=3, strides=1, padding='same')(d)
d = BatchNormalization(momentum=0.8)(d)
d = Add()([d, layer_input])
return d
def deconv2d(layer_input):
u = UpSampling2D(size=2)(layer_input)
u = Conv2D(256, kernel_size=3, strides=1, padding='same')(u)
u = Activation('relu')(u)
return u
img_lr = Input(shape=self.lr_shape)
# 第一部分,低分辨率图像进入后会经过一个卷积+RELU函数
c1 = Conv2D(64, kernel_size=9, strides=1, padding='same')(img_lr)
c1 = Activation('relu')(c1)
# 第二部分,经过16个残差网络结构,每个残差网络内部包含两个卷积+标准化+RELU,还有一个残差边。
r = residual_block(c1, 64)
for _ in range(self.n_residual_blocks - 1):
r = residual_block(r, 64)
# 第三部分,上采样部分,将长宽进行放大,两次上采样后,变为原来的4倍,实现提高分辨率。
c2 = Conv2D(64, kernel_size=3, strides=1, padding='same')(r)
c2 = BatchNormalization(momentum=0.8)(c2)
c2 = Add()([c2, c1])
u1 = deconv2d(c2)
u2 = deconv2d(u1)
gen_hr = Conv2D(self.channels, kernel_size=9, strides=1, padding='same', activation='tanh')(u2)
return Model(img_lr, gen_hr)
2、判别网络
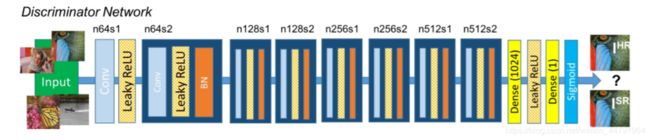
此图从左至右来看,我们可以知道:
SRGAN的判别网络由不断重复的 卷积+LeakyRELU和标准化 组成。
def build_discriminator(self):
def d_block(layer_input, filters, strides=1, bn=True):
"""Discriminator layer"""
d = Conv2D(filters, kernel_size=3, strides=strides, padding='same')(layer_input)
d = LeakyReLU(alpha=0.2)(d)
if bn:
d = BatchNormalization(momentum=0.8)(d)
return d
# 由一堆的卷积+LeakyReLU+BatchNor构成
d0 = Input(shape=self.hr_shape)
d1 = d_block(d0, 64, bn=False)
d2 = d_block(d1, 64, strides=2)
d3 = d_block(d2, 64*2)
d4 = d_block(d3, 64*2, strides=2)
d5 = d_block(d4, 64*4)
d6 = d_block(d5, 64*4, strides=2)
d7 = d_block(d6, 64*8)
d8 = d_block(d7, 64*8, strides=2)
d9 = Dense(64*16)(d8)
d10 = LeakyReLU(alpha=0.2)(d9)
validity = Dense(1, activation='sigmoid')(d10)
return Model(d0, validity)
训练思路
1、对判别模型进行训练
将真实的高分辨率图像和虚假的高分辨率图像传入判别模型中。
将真实的高分辨率图像的判别结果与1对比得到loss。
将虚假的高分辨率图像的判别结果与0对比得到loss。
利用得到的loss进行训练。
2、对生成模型进行训练
将低分辨率图像传入生成模型,得到高分辨率图像,利用该高分辨率图像获得判别结果与1进行对比得到loss。
将真实的高分辨率图像和虚假的高分辨率图像传入VGG网络,获得两个图像的特征,通过这两个图像的特征进行比较获得loss。
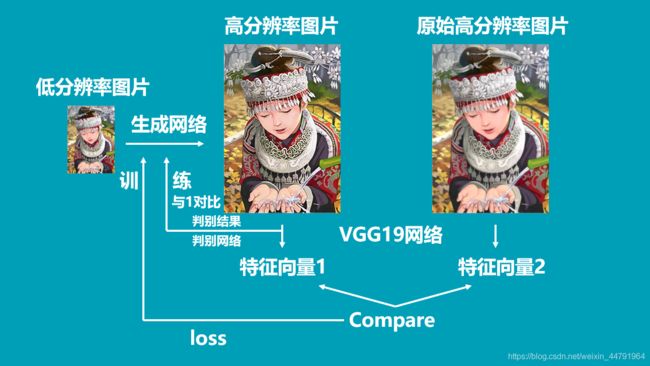
全部代码
1、data_loader全部代码
该部分用于对数据进行加载:
import scipy
from glob import glob
import numpy as np
import matplotlib.pyplot as plt
class DataLoader():
def __init__(self, dataset_name, img_res=(128, 128)):
self.dataset_name = dataset_name
self.img_res = img_res
def load_data(self, batch_size=1, is_testing=False):
data_type = "train" if not is_testing else "test"
path = glob('./datasets/%s/train/*' % (self.dataset_name))
batch_images = np.random.choice(path, size=batch_size)
imgs_hr = []
imgs_lr = []
for img_path in batch_images:
img = self.imread(img_path)
h, w = self.img_res
low_h, low_w = int(h / 4), int(w / 4)
img_hr = scipy.misc.imresize(img, self.img_res)
img_lr = scipy.misc.imresize(img, (low_h, low_w))
# If training => do random flip
if not is_testing and np.random.random() < 0.5:
img_hr = np.fliplr(img_hr)
img_lr = np.fliplr(img_lr)
imgs_hr.append(img_hr)
imgs_lr.append(img_lr)
imgs_hr = np.array(imgs_hr) / 127.5 - 1.
imgs_lr = np.array(imgs_lr) / 127.5 - 1.
return imgs_hr, imgs_lr
def imread(self, path):
return scipy.misc.imread(path, mode='RGB').astype(np.float)
2、主函数全部代码
训练代码
from __future__ import print_function, division
import scipy
from keras.datasets import mnist
from keras_contrib.layers.normalization.instancenormalization import InstanceNormalization
from keras.layers import Input, Dense, Reshape, Flatten, Dropout, Concatenate
from keras.layers import BatchNormalization, Activation, ZeroPadding2D, Add
from keras.layers.advanced_activations import PReLU, LeakyReLU
from keras.layers.convolutional import UpSampling2D, Conv2D
from keras.applications import VGG19
from keras.models import Sequential, Model
from keras.optimizers import Adam
import datetime
import matplotlib.pyplot as plt
import sys
from data_loader import DataLoader
import numpy as np
import os
import keras.backend as K
class SRGAN():
def __init__(self):
# 低分辨率图的shape
self.channels = 3
self.lr_height = 128
self.lr_width = 128
self.lr_shape = (self.lr_height, self.lr_width, self.channels)
# 高分辨率图的shape
self.hr_height = self.lr_height*4
self.hr_width = self.lr_width*4
self.hr_shape = (self.hr_height, self.hr_width, self.channels)
# 16个残差卷积块
self.n_residual_blocks = 16
# 优化器
optimizer = Adam(0.0002, 0.5)
# 创建VGG模型,该模型用于提取特征
self.vgg = self.build_vgg()
self.vgg.trainable = False
# 数据集
self.dataset_name = 'DIV'
self.data_loader = DataLoader(dataset_name=self.dataset_name,
img_res=(self.hr_height, self.hr_width))
patch = int(self.hr_height / 2**4)
self.disc_patch = (patch, patch, 1)
# 建立判别模型
self.discriminator = self.build_discriminator()
self.discriminator.compile(loss='binary_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])
self.discriminator.summary()
# 建立生成模型
self.generator = self.build_generator()
self.generator.summary()
# 将生成模型和判别模型结合。训练生成模型的时候不训练判别模型。
img_lr = Input(shape=self.lr_shape)
fake_hr = self.generator(img_lr)
fake_features = self.vgg(fake_hr)
self.discriminator.trainable = False
validity = self.discriminator(fake_hr)
self.combined = Model(img_lr, [validity, fake_features])
self.combined.compile(loss=['binary_crossentropy', 'mse'],
loss_weights=[5e-1, 1],
optimizer=optimizer)
def build_vgg(self):
# 建立VGG模型,只使用第9层的特征
vgg = VGG19(weights="imagenet")
vgg.outputs = [vgg.layers[9].output]
img = Input(shape=self.hr_shape)
img_features = vgg(img)
return Model(img, img_features)
def build_generator(self):
def residual_block(layer_input, filters):
d = Conv2D(filters, kernel_size=3, strides=1, padding='same')(layer_input)
d = Activation('relu')(d)
d = BatchNormalization(momentum=0.8)(d)
d = Conv2D(filters, kernel_size=3, strides=1, padding='same')(d)
d = BatchNormalization(momentum=0.8)(d)
d = Add()([d, layer_input])
return d
def deconv2d(layer_input):
u = UpSampling2D(size=2)(layer_input)
u = Conv2D(256, kernel_size=3, strides=1, padding='same')(u)
u = Activation('relu')(u)
return u
img_lr = Input(shape=self.lr_shape)
# 第一部分,低分辨率图像进入后会经过一个卷积+RELU函数
c1 = Conv2D(64, kernel_size=9, strides=1, padding='same')(img_lr)
c1 = Activation('relu')(c1)
# 第二部分,经过16个残差网络结构,每个残差网络内部包含两个卷积+标准化+RELU,还有一个残差边。
r = residual_block(c1, 64)
for _ in range(self.n_residual_blocks - 1):
r = residual_block(r, 64)
# 第三部分,上采样部分,将长宽进行放大,两次上采样后,变为原来的4倍,实现提高分辨率。
c2 = Conv2D(64, kernel_size=3, strides=1, padding='same')(r)
c2 = BatchNormalization(momentum=0.8)(c2)
c2 = Add()([c2, c1])
u1 = deconv2d(c2)
u2 = deconv2d(u1)
gen_hr = Conv2D(self.channels, kernel_size=9, strides=1, padding='same', activation='tanh')(u2)
return Model(img_lr, gen_hr)
def build_discriminator(self):
def d_block(layer_input, filters, strides=1, bn=True):
"""Discriminator layer"""
d = Conv2D(filters, kernel_size=3, strides=strides, padding='same')(layer_input)
d = LeakyReLU(alpha=0.2)(d)
if bn:
d = BatchNormalization(momentum=0.8)(d)
return d
# 由一堆的卷积+LeakyReLU+BatchNor构成
d0 = Input(shape=self.hr_shape)
d1 = d_block(d0, 64, bn=False)
d2 = d_block(d1, 64, strides=2)
d3 = d_block(d2, 128)
d4 = d_block(d3, 128, strides=2)
d5 = d_block(d4, 256)
d6 = d_block(d5, 256, strides=2)
d7 = d_block(d6, 512)
d8 = d_block(d7, 512, strides=2)
d9 = Dense(64*16)(d8)
d10 = LeakyReLU(alpha=0.2)(d9)
validity = Dense(1, activation='sigmoid')(d10)
return Model(d0, validity)
def scheduler(self,models,epoch):
# 学习率下降
if epoch % 20000 == 0 and epoch != 0:
for model in models:
lr = K.get_value(model.optimizer.lr)
K.set_value(model.optimizer.lr, lr * 0.5)
print("lr changed to {}".format(lr * 0.5))
def train(self, epochs ,init_epoch=0, batch_size=1, sample_interval=50):
start_time = datetime.datetime.now()
if init_epoch!= 0:
self.generator.load_weights("weights/%s/gen_epoch%d.h5" % (self.dataset_name, init_epoch),skip_mismatch=True)
self.discriminator.load_weights("weights/%s/dis_epoch%d.h5" % (self.dataset_name, init_epoch),skip_mismatch=True)
for epoch in range(init_epoch,epochs):
self.scheduler([self.combined,self.discriminator],epoch)
# ---------------------- #
# 训练判别网络
# ---------------------- #
imgs_hr, imgs_lr = self.data_loader.load_data(batch_size)
fake_hr = self.generator.predict(imgs_lr)
valid = np.ones((batch_size,) + self.disc_patch)
fake = np.zeros((batch_size,) + self.disc_patch)
d_loss_real = self.discriminator.train_on_batch(imgs_hr, valid)
d_loss_fake = self.discriminator.train_on_batch(fake_hr, fake)
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
# ---------------------- #
# 训练生成网络
# ---------------------- #
imgs_hr, imgs_lr = self.data_loader.load_data(batch_size)
valid = np.ones((batch_size,) + self.disc_patch)
image_features = self.vgg.predict(imgs_hr)
g_loss = self.combined.train_on_batch(imgs_lr, [valid, image_features])
print(d_loss,g_loss)
elapsed_time = datetime.datetime.now() - start_time
print ("[Epoch %d/%d] [D loss: %f, acc: %3d%%] [G loss: %05f, feature loss: %05f] time: %s " \
% ( epoch, epochs,
d_loss[0], 100*d_loss[1],
g_loss[1],
g_loss[2],
elapsed_time))
if epoch % sample_interval == 0:
self.sample_images(epoch)
# 保存
if epoch % 500 == 0 and epoch != init_epoch:
os.makedirs('weights/%s' % self.dataset_name, exist_ok=True)
self.generator.save_weights("weights/%s/gen_epoch%d.h5" % (self.dataset_name, epoch))
self.discriminator.save_weights("weights/%s/dis_epoch%d.h5" % (self.dataset_name, epoch))
def sample_images(self, epoch):
os.makedirs('images/%s' % self.dataset_name, exist_ok=True)
r, c = 2, 2
imgs_hr, imgs_lr = self.data_loader.load_data(batch_size=2, is_testing=True)
fake_hr = self.generator.predict(imgs_lr)
imgs_lr = 0.5 * imgs_lr + 0.5
fake_hr = 0.5 * fake_hr + 0.5
imgs_hr = 0.5 * imgs_hr + 0.5
titles = ['Generated', 'Original']
fig, axs = plt.subplots(r, c)
cnt = 0
for row in range(r):
for col, image in enumerate([fake_hr, imgs_hr]):
axs[row, col].imshow(image[row])
axs[row, col].set_title(titles[col])
axs[row, col].axis('off')
cnt += 1
fig.savefig("images/%s/%d.png" % (self.dataset_name, epoch))
plt.close()
for i in range(r):
fig = plt.figure()
plt.imshow(imgs_lr[i])
fig.savefig('images/%s/%d_lowres%d.png' % (self.dataset_name, epoch, i))
plt.close()
if __name__ == '__main__':
gan = SRGAN()
gan.train(epochs=60000,init_epoch = 0, batch_size=1, sample_interval=50)
实现效果