Kaggle服务器初体验记录
文章目录
-
- 开启网络
- 环境查询与配置
- 了解路径
- 安装自己提供的三方包
- 调用自己模块
- 更改自己上传的代码
- 保存自己环境
- 后台运行
- 参考内容
使用Kaggle服务器有一段时间了,下面记录一下自己遇到的相关问题与解决方法
官网:https://www.kaggle.com/
Kaggle给每个用户提供了以下资源,自己可使用私人数据集空间100G,CPU使用时间不限,GPU每周使用时间为41小时,TPUv3-8使用时间为20小时;大概每周六早上刷新GPU与TPU使用时间。注意CPU与GPU每次最大使用时长为12小时,TPU不知。

开启网络
首先用户需要用梯子电话验证之后,才能在右侧Settings开启网络。
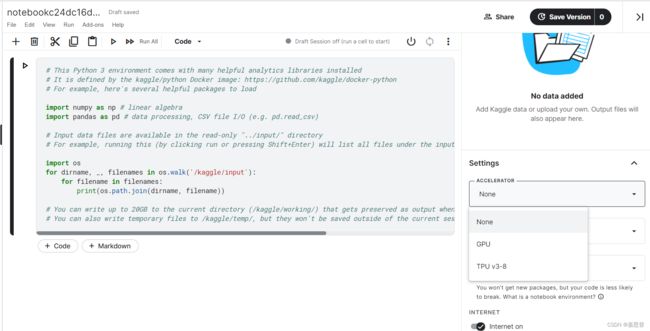
自己代码运行服务器类型需要自己选择,一般默认是CPU服务器。
环境查询与配置
torch以及CUDA版本查询
import torch
print(torch.__version__)
print(torch.version.cuda)
print(torch.backends.cudnn.version())
print(torch.cuda.is_available())
!nvcc -V #就可以看到CUDA的版本

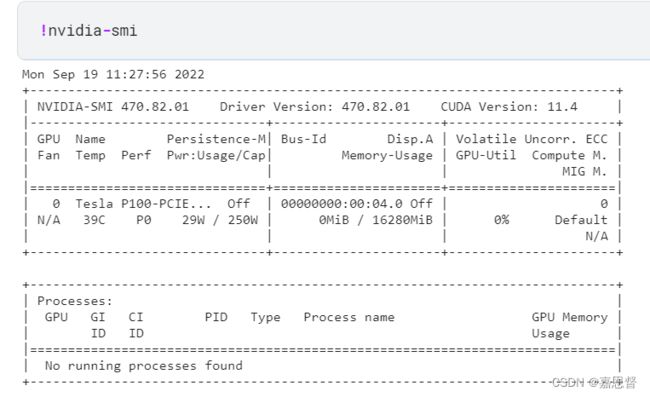
GPU性能查询
!nvidia-smi --query-gpu=name --format=csv,noheader

!nvidia-smi
import sys
sys.version
只要使用!就可以在.ipynb格式的jupyter notebook中使用bash命令
卸载安装包,-y 提前输入y参数
!pip uninstall -y tensorflow

了解路径
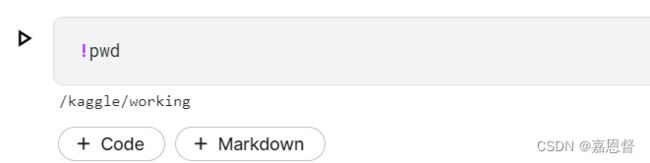
默认运行路径是/kaggle/working/,不知道如何改变
!pwd
安装自己提供的三方包
由于每次环境要重置,可以将自己代码已及需要安装的三方包通过上传数据集方式上传

安装自己提供的三方环境包
!pip install -q /kaggle/input/mmdet-lib-ds-v2/torch-1.7.0%2Bcu110-cp37-cp37m-linux_x86_64.whl
也可以直接安装,但要打开右侧internet开关
!pip install SlideRunner_dataAccess

调用自己模块
调用自己的代码(方式一)
import sys
sys.path.append('../input')
from 文件名字 import 函数
from 文件夹.文件 import 函数
调用自己的代码(方式二)
利用以下代码将自己所有文件复制到/kaggle/working/当前运行路径,就可以按照正常方式调用代码;其中/*代表该文件夹下所有路径
!cp -rf ../input/mmdetection/* ./
调用自己的代码(方式三,比较麻烦)
将自己需要调用的代码新建为程序脚本(utility script)保存后,然后可以在运行代码处Add utility script
(如下图)

添加utility script后就会在input与output之间多一块utility script的内容,并且可以通过正常调用模块方式调用,如下图:
from sliderunnerdatabase import Database

更改自己上传的代码
由于input路径中的内容只能被读取,我们可以将自己要改的代码先复制到工作目录output/working/下
!cp -rf ../input/filename.py ./
%load filename.py # 加载刚才的文件,不用自己复制粘贴
%%writefile filemane.py
下面是代码
也可以自己创建文件夹到目录output/working/下
!mkdir 文件夹
或者
import os
os.mkdir("文件夹")
保存自己环境
下面是一种保存自己安装的模块的方法,不太好用
pip install forever
后台运行
将调试好的代码点击File中的Save Version

在弹出的如下界面中选择Advanced Setting

这里可以选择是否保存输出(每次如果没保存,output中的文件会被清空),同时可以选择是否使用GPU,这个一般会和自己调试使用的设备相同。

最后点击两次Save,然后点击左下角图标,弹出如下浮动窗口,并点击浮动窗口最上面的一行后面三个点弹出另一个浮动窗口,并点击Open Logs in Viewer。

这样就可以看到后台运行的代码详情,并且可以直接关闭浏览器都是不影响的啦!
请愉快的使用Kaggle吧!
参考内容
[1] pip install forever
[2] 查看kaggle的GPU类型