sklearn与XGBoost
1.预备知识
(1)XGBoost全称eXtreme Gradient Boosting,可译为极限梯度提升算法。和传统的梯度提升算法相比,XGBoost进行了许多改进,是一个集大成的机器学习算法,它能够比其他使用梯度提升的集成算法更加快速,并且已经被认为是在分类和回归上都拥有超高性能的先进评估器。
(2)XGBoost的三大板块
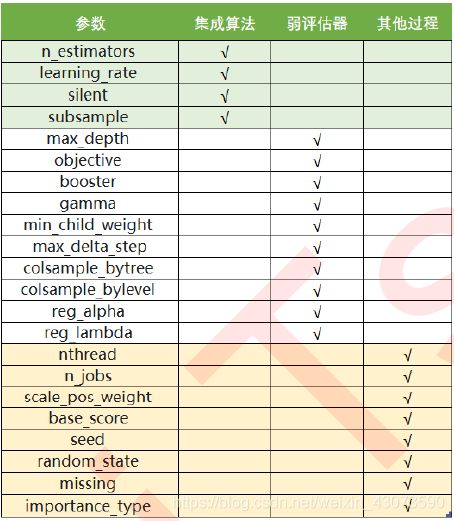
XGBoost本身的核心是基于梯度提升树实现的集成算法,整体来说可以有三个核心部分:集成算法本身;用于集成算法的弱评估器;应用中的其他过程。
2.梯度提升树GBDT
(1)提升集成算法
集成算法通过在数据上构建多个弱评估器,汇总所有弱评估器的建模结果,以获取比单个模型更好的回归或分类表现。弱评估器预测准确率不低于50%的任意模型。梯度提升(Gradient Boosting)是构建预测模型的最强大算法之一,它是集成算法中提升法(Boosting)的代表算法。
提升法中最著名的算法包括Adaboost和梯度提升树,XGBoost就是由梯度提升树发展而来的,梯度提升树可以有回归树也可以有分类树,两者都以CART树(CART假设决策树是二叉树,内部结点特征的取值为“是”和“否”)算法作为主流,这意味着XGBoost中所有的树都是二叉的。
对于GBDT来说,每个样本的预测结果可以表示为:所有树上的结果的加权求和。每棵树的权重不一样,每棵树对于一个样本的预测结果也是不同的。
(2)绘制学习曲线n_estimators
在机器学习中,用来衡量模型在未知数据上的准确率的指标,叫做泛化误差(Genelization error)。一个集成模型(f)在未知数据集(D)上的泛化误差E(f;D),由方差(var),偏差(bais)和噪声(ε)共同决定。其中偏差由模型在训练集上的拟合程度决定(R²=1-偏差),方差由模型的稳定性(模型在不同数据集上表现出的稳定性)决定,噪声是不可控的。泛化误差越小,模型越稳定。
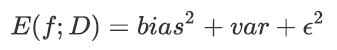
一般来说,模型极不稳定,方差很大的情况比较少见,所以直接取学习曲线获得分数最高点,即偏差最小的点。但有时数据量非常少,模型会相对不稳定,这时应该将方差和泛化误差中可控的部分也纳入考虑的范围。
cvresult = CVS(reg,Xtrain,Ytrain,cv=cv)
#记录1-偏差
rs.append(cvresult.mean())
#记录方差
var.append(cvresult.var())
#计算泛化误差的可控部分
ge.append((1 - cvresult.mean())**2+cvresult.var())
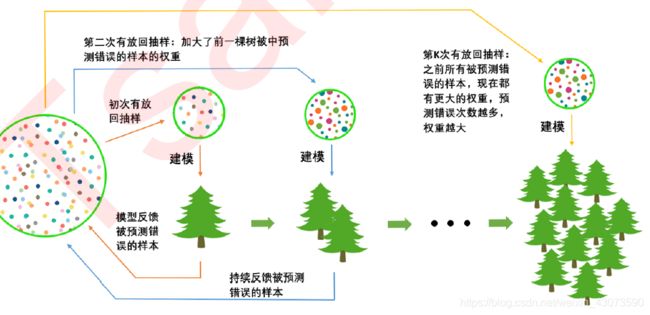
(3)有放回随机抽样:重要参数subsample
第一次迭代:首先有一个巨大的数据集,在建立第一棵树的时候,对数据进行初次有放回抽样,然后建模。建模完毕后,对模型进行评估,然后将模型预测错误的样本反馈给数据集。
第二次迭代:第二次有放回抽样中,加大了被第一棵树判断错误的样本的权重,即被第一棵树判断错误的样本,更有可能被我们抽中。
……
如此反复,新建的决策树会更加倾向于那些权重更大的,更容易被判断错误的仰恩,越到后面的树,越是专注于攻克那些之前的树所不擅长的数据。
在梯度提升树中,每构建一个评估器,都让模型更加集中于数据集中容易被判错的那些样本。
(4)迭代决策树:重要参数eta(learning rate)
如何让新建的树在被判断错误的样本上表现得比前面的树更好呢?

完整的迭代决策树的公式:
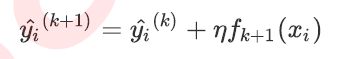
η是迭代决策树的步长,又叫学习率。η越大,迭代的速度越快,算法的极限很快就被达到,有可能无法收敛到真正的最佳值。
(5)梯度提升树的三个重要组成部分:
①能够衡量集成算法效果的,能够被最优化的损失函数;
②能够实现预测的弱评估器;
③能够让弱评估器集成的手段,包括迭代方法、抽样方法、样本加权等等。
(6)GBDT与XGBoost的区别:
①GBDT是一种算法,而XGBoost则是GBDT的系统性工程实现。
②XGBoost优化了GBDT的求解过程:
直接用XGBoost打分函数(包括了损失与正则两部分)去指导树的生成,避免了line search。而GBDT则是用平方(对数)损失指导树的生成,再做line search。GBDT只用了一阶导数信息,而XGBoost则利用泰勒公式进行二阶展开。求解更快,还可以自定义损失函数。XGBoost打分函数综合了loss和正则,避免了决策树容易过拟合的问题。
③XGBoost优化了分裂点搜索算法。不是简单地利用样本个数进行分位,而是以二阶导数值作为权重。
④传统的GBDT每轮使用全部数据,XGBoost支持对数据进行采样。
⑤传统的GBDT没有设计对缺失值处理,XGBoost能够学习出默认的节点分裂方向来处理缺失值。
3.XGBoost的智慧
XGBoost是在梯度提升树的三个核心要素上运行的,它重新定义了损失函数和弱评估器,并且对提升算法的集成手段进行了改进,实现了运算速度和模型效果的高度平衡。而且XGBoost将原来的梯度提升树扩展开来,让XGBoost不再是单纯的树的集成模型,也不只是单单的回归模型,只要调节参数,可以选择任意希望的集成模型以及任意希望实现的功能。
(1)选择弱评估器:重要参数booster
在XGB中,主流的模型虽然是树模型,但还可以选择线性模型,比如线性回归,来进行集成,有参数“booster”来控制究竟使用怎样的弱评估器。
gbtree代表梯度提升树;dart代表抛弃提升树;gblinear代表线性模型。
(2)XGB的目标函数:重要参数objective(每棵树的损失函数)
在众多机器学习算法中,损失函数的核心是衡量模型的泛化能力,即模型在未知数据上的预测准确与否。不同于逻辑回归和SVM等算法中固定的损失函数,集成算法中的损失函数是可选的,要选用什么损失函数取决于我们要解决什么问题,以及希望使用怎样的模型。
XGB中,每一棵树都有一个对应的目标函数,写作:传统损失函数+模型复杂度。
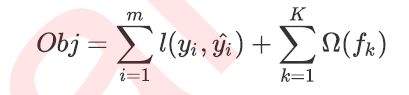
常用的损失函数:

如果可以的话,建议脱离sklearnAPI直接调用xgboost库,因为XGBoost库本身的调参要方便很多。
(3)求解XGB的目标函数
①求解目标函数的目的:为了求得在第t次迭代中最优的树ft。
②XGB与其他机器学习算法求解目标函数的不同:
在逻辑回归和支持向量机中,通常先将目标函数转化成一种容易求解的方式,然后使用梯度下降或者SMO之类的数学方法执行最优化过程。在XGB中无法使用梯度下降,因为XGB的损失函数没有需要求解的参数。传统梯度下降中迭代的是参数,而XGB中迭代的是树,其结构不受到特征矩阵x取值大小的直接影响,尽管这个迭代过程可以类比到梯度下降上。
③在求解XGB的目标函数的过程中,考虑的是如何能够将目标函数转化成更简单的,与树的结构直接相关的写法,以此来建立树的结构与模型的效果(包括泛化能力与运行速度)之间的直接联系。因为这种联系的存在,XGB的目标函数又被称为“结构分数”。
(4)参数化决策树:参数λ和α
在XGB中,当λ和α越大,惩罚越重,正则化所占的比例就越大,在尽全力最小化目标函数的最优化方向下,叶子节点数量就会被压制,模型的复杂度就越来越低,所以对于天生过拟合的XGB来说,正则化可以一定程度上提升模型的效果。
对于树模型来说,剪枝参数的地位更高更优先。在实际使用中,正则化参数往往不是调参的最优选择,如果真的希望控制模型的复杂度,往往调节别的参数。
如果希望调节λ和α,往往使用网格搜索。
(5)寻求最佳树结构:求解ω与T
转化目标函数的目的:建立树的结构(叶子节点的数量)与目标函数的大小之间的直接联系,以求出第t次迭代中需要求解的最优的树ft。只要最小化目标函数,就能求出结构最简的树。
(6)寻找最佳分枝:结构分数之差
贪婪算法指的是控制局部最优来达到全局最优的算法,决策树本身是一种贪婪算法的方法,XGB作为树的集成模型,自然也采用这种方法进行计算。一般认为,当每片叶子都是最优,则整体生成的树结构就是最优,如此就可以避免去枚举所有可能的树结构。
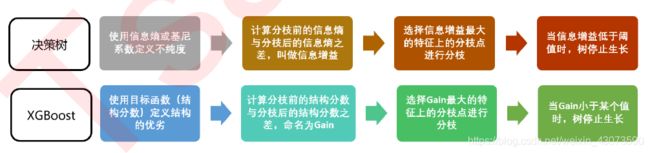
在现实中,对所有特征的所有分枝点进行计算,然后选出让目标函数下降最快的结点进行分枝。对于每一棵树的每一层,都进行这样的计算,比起原始的梯度下降,实践证明这样的求解最佳树结构的方法运算更快。
(7)让树停止生长:重要参数γ
γ被定义为,在树的叶节点上进行进一步分枝所需的最小目标函数减少量。实践证明,γ是对梯度提升树影响最大的参数之一,其效果丝毫不逊色于n_estimators和防止过拟合的神器max_depth。