DBSCAN: 基于密度对空间含噪声数据中不规则形状进行聚类
聚类算法是机器学习中使用频率较高的无监督学习方法,不需要样本标签,就可以将其进行分类,常常作为其他学习任务的前期粗加工。但是原始聚类算法在面对含有噪声或形状非凸的数据分布时表现较差,于是有研究人员提出了基于密度聚类的算法DBSCAN。它是一种基于高密度连接区域的密度聚类算法,可以在带有噪声的空间数据中对不规则形状进行聚类,并且具有更高的效率和性能。
1.背景
聚类算法是机器学习中经常使用的无监督学习方法,不需要借助样本的标签,就可以根据样本属性对一系列未分类的样本按照相似性进行划分,样本被划分为的不同类别称为“簇”。聚类算法不需要借助人工对样本的事先分类,就可以揭示数据的内在特征与规律,常常作为其他学习任务的前期粗加工。
但是现实中需要分类的数据往往不是简单的聚集,并且随着大数据的日益发展,需要处理的数据呈指数型增加,数据维度和数量也远超从前。这使得传统的聚类算法难以在有限的时间内计算出令人满意的结果,新的聚类方法亟需出现。于是在1996年,Martin Ester等教授提出了“密度聚类算法”DBSCAN[1],即具有噪声的基于密度的空间聚类应用。它是一种基于高密度连接区域的密度聚类算法,可以在带有噪声的空间数据中对不规则形状进行聚类,并且具有更高的效率和性能。
2.DBSCAN算法
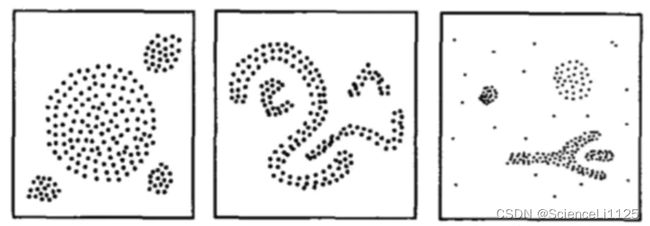
DBSCAN的划分指标就是点的紧密程度,即密度,将具有足够高密度的区域划分为同一簇。举个形象化的例子,如图中3个数据集所示:传统的聚类方法如K-Means聚类可以处理第1个数据集,但面对后两个分布形状不规律的样本容易出现较大的偏差。基于密度的聚类却可以通过量化方法(如连通性)计算样本之间的密度,最终达到很好的分类。
DBSCAN的定义[1]中引入了邻域半径、核心对象、最少点数目等基础概念,以及核心点,边界点和噪声点等点的类别。然后根据上述概念给出了点的不同关系:密度直达、密度可达、密度相连和非密度相连,其关系[2]如下:

由图中可以看到,密度直达是两个样本点最近的关联信息,即一个点在另一个点的有效邻域范围内。密度可达就是多个点传递密度直达的特性能够连接的点,密度相连则是多个点传递其可达性而连通的样本点。如果某两个点之间不能够用上述关系衡量,则称为非密度相连。点的不同关系刻画了点与点之间的多维密度,为密度聚类中簇的划分提供了量化指标。
DBSCAN算法的原理就在数据集中找出所有核心对象,再以任一核心对象为出发点,找出由其密度可达的样本生成聚类簇,直到所有核心对象均被访问过为止。算法流程[3]如下所示:

3.DBSCAN算法的优势与局限性
DBSCAN算法与传统聚类算法(以K-Means为例)相比,有着诸多优势:
- 簇数灵活:K-Means算法的执行前提是知道簇的数量;而DBSCAN 算法根本不需要给定簇数 k ,就可以使用算法分析数据特征对空间数据进行聚类;
- 样本空间形状任意:通过上述分析可知,DBSCAN可以对任意形状的稠密数据集进行聚类,而K-Means算法只适用于凸数据集;
- 噪声:实际应用中,需要处理的数据往往会含有噪声,DBSCAN可以在聚类的同时抛弃噪声,并且对数据集中的异常点也不敏感。
但DBSCAN 算法也带来一定的局限性:
- 参数:DBSCAN 算法的分类依据就是邻域半径和最少点数目,因此需要对其进行进行联合调参,难度较大,且不同的参数组合对最后的聚类效果有较大影响;
- 抛弃噪声点:DBSCAN 算法会过滤滤噪声点,对于某些安全性或精密性要求高的领域并不适用。
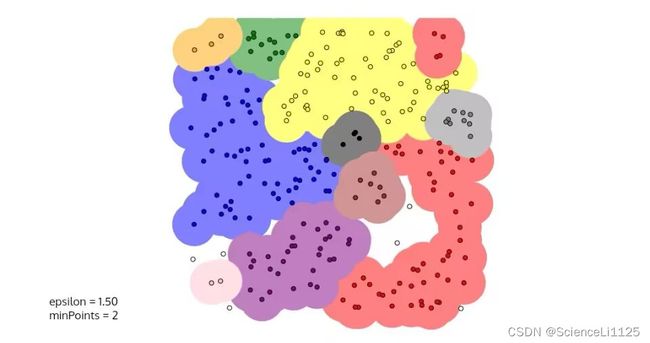
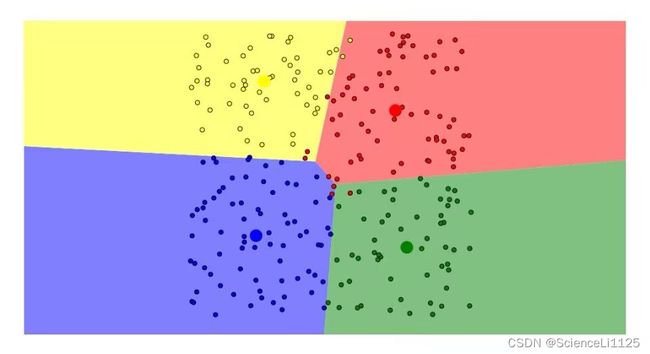
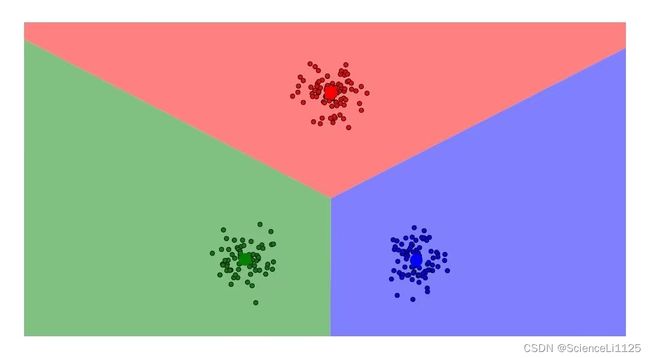
下面使用naftaliharris网站的聚类可视化对比DBSCAN 算法和K-Means算法的优缺点,共使用了7种不同的样本分布如下。下面对比两种算法的聚类效果,前者为DBSCAN聚类的结果,后者为K-Means聚类的结果。
(1)正态分布
(2)高斯混合分布

(3)笑脸分布

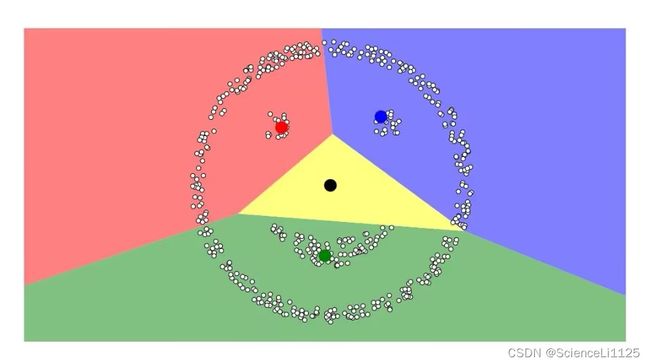
(4)密度堆
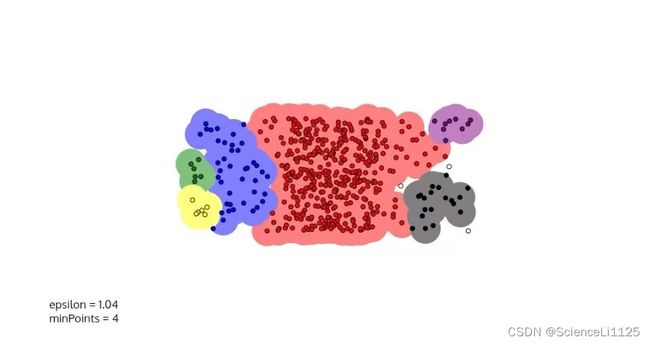

(5)堆积圆


(6)有噪声的笑脸分布

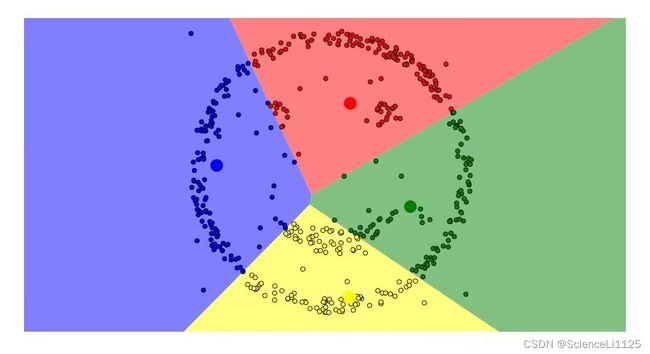
(7)DBSCAN环


图中可以看到,DBSCAN算法的聚类效果以点的关联性和密集性为依据,K-Means算法的聚类效果更偏向分块。在实际数据集的应用中,两种算法对于正态分布、高斯混合分布、堆积圆的聚类结果各有道理。对于笑脸分布,显然不是凸数据集,K-Means算法很难将其进行有效聚类;对比之下,基于密度聚类的DBSCAN算法可以很好的将样本进行划分。即使在含有噪声的笑脸分布中,DBSCAN算法仍然可以准确划分样本分布,根据实际情况形成簇,并抛弃噪声。这是DBSCAN算法最为显著的3个优点。对比密度堆和DBSCAN环样本分布,DBSCAN算法可以在人脑难以划分情况下作出较为合理的聚类,但K-Means算法不太稳定,划分结果也不理想。
其实上述对比中还可以发现,DBSCAN算法会抛弃一些噪声点,并没有把所有样本都划分到指定簇中,这在一些安全性或精密性要求高的领域,如军事信号拦截、网络安全恶意攻击判断等,会造成毁灭性的灾难。不仅如此,DBSCAN算法对参数邻域半径和最少点数目依赖严重,下面以笑脸分布为例,指定不同联合参数来查看聚类效果:

上面是不同邻域半径和最少点数目参数取值下的聚类结果,在参数选择不当时聚类结果让人难以接受。我认为,在全局范围使用固定的参数,没有兼顾到具体样本的数据分布,这是DBSCAN算法最大的局限性。为解决此问题,后人也提出了许多改进方法,如K-DBSCAN[4]、AA-DBSCAN[5]、kAA-DBSCAN、DDBSCAN[6]等。
在查阅资料时还找到了一篇文献讲解了如何确定最优邻域半径和最少点数目参数,以及DBSCAN聚类的评价方式,感兴趣可以查看参考文献[7]。
4.DBSCAN算法的应用
DBSCAN算法在现实生活中的较多应用是图像处理,可以在有噪声点的情况下进行较好的聚类划分,如噪声图像分割应用空间聚类[8]、基于PSO的道路事故黑点定位[9]、交通领域出行分析[10]等。
此处再介绍一种DBSCAN算法在农业生产中的应用[11]:在实际农业生产生活中,为了精准按地块统计农机在田地间的工作范围,会根据农机轨迹进行划分。但由于农机在行驶过程中折返、转向、变速,导致轨迹点密度变大,使其被误判为田间作业轨迹。另外,部分田间与道路交界处也会被误判为田间作业轨迹点。于是在实际生产应用中,通过使用DBSCAN算法对轨迹点进行聚类,利用聚类得到的类别信息,再通过其他集成集成方法进行训练。这样识别出来的聚类轨迹点允许有噪声点,比较符合实际情况,准确率较高。
5.总结
聚类算法在解决空间数据分类问题,尤其是图像处理中非常常见。但原始聚类算法在处理大型空间数据以及噪声较多的样本时问题突出。而改进后的基于密度聚类的DBSCAN算法,只依赖密度相关参数,就可以实现很好的聚类效果。在处理大型数据、不规则形状图像以及噪声点情况中效果明显。并且密度参数可以由用户根据实际情况自行定义,更加灵活。
参考文献
- Ester M, Kriegel H, Sander J, Xu X. A density-based algorithm for discovering clusters in large spatial databases with noise. In: 2nd International Conference on Knowledge Discovery and Data Mining, pp 1996: 226–231.
- DBSCAN详解. https://blog.csdn.net/hansome_hong/article/details/107596543
- 周志华. 机器学习. 北京: 清华大学出版社, 2016
- Gholizadeh, Nahid,Saadatfar, Hamid,Hanafi, Nooshin. K-DBSCAN: An improved DBSCAN algorithm for big data [J] JOURNAL OF SUPERCOMPUTING,2021,77(6):6214-6235
- Kim, Jeong-Hun,Choi, Jong-Hyeok,Yoo, Kwan-Hee,Nasridinov, Aziz. AA-DBSCAN: an approximate adaptive DBSCAN for finding clusters with varying densities [J] JOURNAL OF SUPERCOMPUTING,2019,75(1):142-169
- Hassanin, Mohammad F., Hassan, Mohamed, Shoeb, Abdalla. DDBSCAN: Different Densities-Based Spatial Clustering of Applications with Noise [M] IEEE International Conference on Control, Instrumentation, Communication and Computational Technologies (ICCICCT), 2015:401-404
- Kamil Mysiak. Using DBSCAN logo to group employees.https://zhuanlan.zhihu.com/p/185623849
- Chen, Qi, Yuen, Kevin Kam Fung, Guan, Chun. Towards a Hybrid Approach of Self-Organizing Map and Density-Based Spatial Clustering of Applications with Noise for Image Segmentation [M] 10th International Conference on Developments in eSystems Engineering (DeSE), 2017:238-241
- Sándor Szénási, Miklós Sipos, Péter Mogyorósi. PSO based Optimization of DBSCAN Algorithm Parameters for Road Accident Blackspot Localization [M] International Conference on Computational Cybernetics (ICCC), 1000:000043-000048
- Kieu L M, Bhaskar A, Chung E. A modified density-based scanning algorithm with noise for spatial travel pattern analysis from smart card AFC data[J]. Transportation Research Part C: Emerging Technologies, 2015, 58: 193-207.
- 李亚硕,赵博,王长伟,徐名汉,伟利国,庞在溪.基于DBSCAN和BP_Adaboost的农机作业地块划分方法[J/OL].农业机械学报:1-10[2022-12-14].http://kns.cnki.net/kcms/detail/11.1964.S.20221130.1722.008.html