林轩田之机器学习课程笔记( combining predictive features之blending and bagging)(32之23)
- 概要
- 为什么要做模型聚合
- 投票制的blending
- 线性以及任意的blending
- bagging方式
欢迎转载,可以关注博客:http://blog.csdn.net/cqy_chen
对于模型融合可以参考:
http://scikit-learn.org/stable/modules/ensemble.html
blending的参考代码:https://heamy.readthedocs.io/en/latest/usage.html
题目可能不全,因为有字数限制,不好意思,可以参考:
https://www.csie.ntu.edu.tw/~htlin/course/ml15fall/
概要
前面讲述了kernel版本的各种模型,包括线性的回归模型到SVR到kernel版本的逻辑回归等等。
本节主要讲解bagging和blending,这不应该称之为算法,应该称之为框架。
为什么要做模型聚合
比如要预测明天股票是涨还是跌,现在有15个模型在做预测,那么我们应该怎么选择呢?
我们可能有如下的方式:
1)选择这15个模型中表现最好的模型,这就是相当于采用了validation的方式啦。
2)通过投票的方式,每个一票,每个模型的权重一样,根据票数来决定
3)也是通过投票的方式,但是每个人的权重不一样
4)由于每个模型可能侧重的面不一样,比如有的模型擅长科技股票,有的擅长美股,有的擅长A股,所以我们对于不同的股票调用不同的模型来测试。
这里稍微数学化一点:
假设有T个已经调至好的模型,不管是逻辑回归还是SVM等等: g1,g2,g3,g4,g5......gT ,记最后的结果是: G(x)
1)第一种方法是选取这其中最好的一个作为最后的结果。
2)第二种方法就是通过全民公投的方式
当选定某一个模型,其他模型权重归0,和方法1一致
3)第三种方法也是投票的方式,但是有的人的票多,有的人的票少
当设定所有的权重为1,和方法2一致
4)第四种也是投票,但是这个票数对于每个人可能不是固定的,比如对于科技类股票,科技型模型票数多,但是对于其他类型股票,票数少,如下:
当假设权重函数是一个定值,那么合方法3一致。
所以最后我们的第4个方法包括了所有的方法。
假如采用第一种方法,那么如果要使得最后的结果还不错,必须在这其中有一个还不错的模型才可以,不然如果所有的模型都不怎么地,比如准确率只有60%,那么无论怎么选第一种方法都没有办法得到好的结果。
所以有没有好的办法,即使这些模型的都不咋地,能不能凑成一个好的模型。三个臭皮匠赛过诸葛亮。
模型融合能做到两个方面:
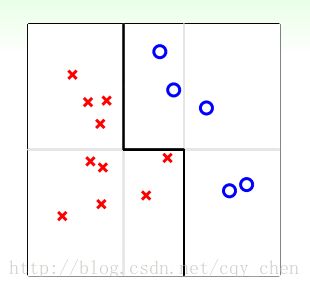
1)将一对差的模型融合成一个好的模型,如下图。这里基本的模型只能是垂直的直线,这样这些基本的模型是很难做好的,因为这个边界线应该是一条斜线。但是通过融合这几个基本模型,我们得到了折线,从而得到了一个好的模型。
2)防止过拟合,相当于做正则化。如下图。基本的模型都是采用的PLA,我们知道PLA模型只要分离了就停止了,所以得到了一堆灰色的线条,但是我们通过融合可以得到中间的那条线,有点像SVM的感觉,就像通过一堆PLA得到了SVM。所以这里通过模型的融合相当于做了正则化的操作,防止过拟合。

所以做模型的融合的目的是:三个臭皮匠赛过诸葛亮,可以将一堆差的模型融合成一个好的模型,同时也防止过拟合
这里稍微提一下,通过差的模型混合成好的模型用的多是adaboost算法,防止过拟合可以看看随机森林
投票制的blending
对于一个分类问题,通过投票制的blending算法,是很简单的一件事件,但是有几点是要注意的。

对于一个回归问题,最后的模型如下:
要使得最后有好的结果,我们知道基本的模型必须要有差异化。
这个很重要。
这里假设目标函数是 f ,这里证明下为什么通过平均的方式可以得到还不错的结果:

所以我们得到:

这里证明了在回归中采用了平方的损失函数,会得到平均每个基本模型的表现要比通过blending方式得到的G差。
这里要说明一点,如果误差采用的是绝对值的方式这两个是差不多的。因为回归一般采用的都是平方误差,会更多的被噪音干扰,所以我们通过平均的方式得到的G要好。
我们来看看当我们的模型个数趋于无穷大的时候的情况:

线性以及任意的blending
上面是通过一致性的投票方式,每个人的票数一样,这里介绍每个人的票数不一样。因为有的模型能力强,有的模型能力差,会不会给能力强的票数多点好?类似全国人大?
这里讨论线讨论线性的blending
首先看公式,这个是对于分类模型
如果是回归问题呢?如下:
就是我们需要最小化:

这两个其实差不多嘛,所以
但是一般情况下呢,我们会忽略掉权重大于0的条件。为什么呢?
可以假设得到的权重小于0。比如在做分类的问题,明明是+1,却说成-1,这个时候可以反着用模型,同时取权重的绝对值。

所以:
线性的blending=线性模型+基模型作为特征转换
实际操作是如何做的呢?
1)首先要在一堆资料中学习到一堆的模型,比如 g¯1,g¯2,g¯3,......g¯n ,这里是通过训练集求解得到的,选择最小的 Ein ,不用拿去验证集调节参数。
2)将得到的基本模型将验证集进行转换。
3)通过外层的线性模型进行交叉验证,得到权重系数。
4)再将所有数据拿去训练重新训练得到 g1,g2,g3,......gn ,回传权重系数。
上面只是进行了线性的blending,也可以进行非线性的blending。两者差不多如下:

林轩田老师所在的台大队伍在2012年kdd cup中拿到第一名采用了如下流程:

bagging方式
上面我们说我们得到了一堆模型,然后通过blending的方式。那么这些模型在实际操作过程中是怎么得到的呢?能不能一边得到基模型,一边计算系数呢?
ok,首先说如何得到一堆的基模型:
1)模型本身选择就不一样,不然SVM,逻辑回归等
2)调节不同的超参数得到,比如逻辑回归采用梯度下降的步长
3)通过一种随机的方式,比如PLA会根据开始点不同而结果不同
4)通过数据的不同,比如只取一部分数据通过交叉验证形成其中一个基模型,因为数据少嘛,所以交叉验证靠谱点。
这里能不能通过随机的方式生成数据,然后形成一堆基模型呢?比如放回抽样?
我们再看看模型可以拆分成方差和偏差。
模型的平均表现=模型偏离一致表现+一致表现
要达到一致的表现,首先要很多的基本模型,由于每个模型要求差异很大,都需要不同的数据集。
所以面临两个问题:
1)很多模型,这里就用比较大的代替
2)很多不同的数据集,这里用放回抽样代替。
Bootstrapping(拔靴法):
是通过具有估计值特性的样本数据来描述该特性,它不断地从真实数据中进行抽样,以替代先前生成的样本。此法样本数越大越好,对于估计结果的准确性更为有利。与解析方法相比,bootstrapping 的优点在于,它无需对分布特性做严格的假定就能进行推断分析,这是因为它使用的分布就是真实数据的分布。
所以我们每次从N个数据中有放回的抽取 N′ 个样本,然后训练模型,不断重复。这里 N′ 个样本会有重复的出现
我们把通过拔靴法得到样本然后得到一堆基模型,最后拿去做融合的方法称之为bagging。
下面展示采用了bagging的方式,PLA作为基本模型。

因为bagging的方法采用随机放回抽样,所以如果算法如果对随机比较敏感,差异会比较大,这样结果会更好点。
欢迎转载,可以关注博客:http://blog.csdn.net/cqy_chen