Deep Learning学习笔记(4)——长短期记忆网络LSTM
读《神经网络与深度学习》一书,随笔。
在NLP领域几乎都是序列标注问题,上下文信息非常重要,与图像有明显不同。本节需要HMM、Collins感知机、CRF等传统序列标注模型的基础才能好理解。
1 RNN(Recurrent Network)
前面学习的CNN更适合图像领域,而RNN是针对文本领域提出的,专门处理序列化数据的神经网络结构。RNN的一个循环神经单元和按时间展开后的样子如下图:

数学表达式为:![]() ,理解为,t时刻的输出
,理解为,t时刻的输出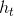 与当前的输入
与当前的输入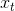 和上一时刻的输出
和上一时刻的输出 有关。
有关。
输入一句话时RNN的过程如下图,可以看出前面所有的输入都对未来的输出产生了影响,圆形隐藏层中包含了前面所有的颜色。
理论上讲,RNN能够处理“长期依赖”问题。但在实践中,RNN效果却并不好。Hochreiter和Bengio深入探讨了这个问题,为普通RNN无法解决长期记忆问题提供了理论证明。从上图中也能看出,短期的记忆影响较大(如橙色区域),但是长期的记忆影响就很小(如黑色和绿色区域),这就是 RNN 存在的短期记忆问题。RNN另外一个缺点就是训练需要投入极大的成本。
2 LSTM(Long Short Term Memory Networks)
1997年,Hochreiter和Schmidhuber提出了LSTM,而深度学习是在2012年兴起的,LSTM又经过了若干代大牛(Felix Gers, Fred Cummins, Santiago Fernandez, Justin Bayer, Daan Wierstra, Julian Togelius, Faustino Gomez, Matteo Gagliolo, and Alex Gloves)的发展,由此便形成了比较系统且完整的LSTM框架,并且在很多领域得到了广泛的应用。
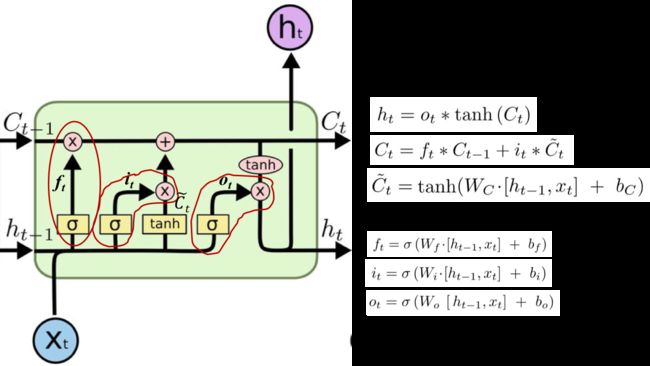
LSTM引入了门(gate)机制来控制特征的流通和损失,如上图红色圈住的部分是一个整体,表示一个门,共有3个门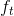 、
、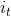 和
和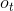 ,每个门都是一个[0,1]之间的权重向量。
,每个门都是一个[0,1]之间的权重向量。
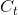 理解为特征,理解为t时刻的输出状态。
理解为特征,理解为t时刻的输出状态。
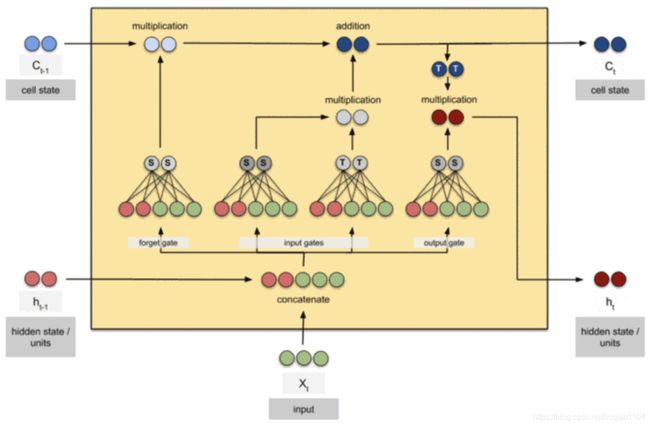
:遗忘门,由和经由sigmod激活函数计算而成,作用于 上,直观解释是用来确定中哪些特征被用于计算。
上,直观解释是用来确定中哪些特征被用于计算。
:输入门,由和经由sigmod激活函数计算而成,作用于 上,直观解释是用来确定中哪些特征被用于更新。
上,直观解释是用来确定中哪些特征被用于更新。
:由和经过一个神经网络层得到,激活函数采用tanh([-1,1]之间,比sigmod收敛的慢),直观解释是t时刻新创建出来的候选特征。
:输出门,由和经由sigmod激活函数计算而成,作用于上,直观解释是用来计算当前h时刻的预测值。
的计算公式,直观解释是从中丢弃我们之前决定忘记的东西,然后从中加上新的信息。
LSTM的计算流程如下:
3 LSTM变体
LSTM的变体非常多,其中最有名的是GRU(the Gated Recurrent Unit,门重复单元),由Kyunghyun Cho等人于2014年提出,它结合了遗忘和输入门,合成了一个“更新门”。这也融合了单元状态和隐藏状态,使得模型比标准LSTM模型更简单,也越来越为大家所接受。
哪些变体是最好的?它们之间有什么差异?
2015年,Jozefowicz等人采集了能采集到的100个最好模型,然后在这100个模型的基础上通过变异的形式产生了10000个新的模型,对这超过一万种的RNN结构进行了测试,得出的重要结论总结如下:
(1)GRU,LSTM是表现最好的模型
(2)GRU在除了语言模型的场景中表现均超过LSTM
(3)LSTM的输出门的偏置的均值初始化为1时,LSTM的性能接近GRU
(4)在LSTM中,门的重要性排序是遗忘门 > 输入门 > 输出门