- 蓝桥杯单片机刷题——串口发送显示
lzb759
一个月备赛蓝桥杯单片机蓝桥杯单片机
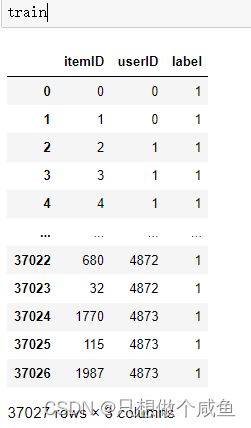
设计要求通过串口接收字符控制数码管的显示,PC端发送字符'A',数码管显示'A',发送其它非法字符时,数码管显示'E'。数码管显示格式如下:备注:单片机IRC振荡器频率设置为12MHz。串口通信波特率:9600bps。按键模式:BTN;扩展方式:IO模式除字符'A'外,其它字符均为非法字符。个人代码#includecodeunsignedcharSeg_Table[]={0x88,//A00x86
- RabbitMQ基本原理
码农小伙
消息队列rabbitmq分布式
一、基本结构所有中间件技术都是基于TCP/IP协议基础之上进行构建新的协议规范,RabbitMQ遵循的是AMQP协议(AdvancedMessageQueuingProtocol-高级消息队列协议)。生产者发送消息流程:1、生产者和Broker建立TCP连接;2、生产者和Broker建立通道;3、生产者通过通道消息发送给Broker,由Exchange将消息进行转发;4、Exchange将消息转发
- 万字深度解析:DeepSeek-V3为何成为大模型时代的“速度之王“?
羊不白丶
大模型算法
引言在AI军备竞赛白热化的2024年,DeepSeek-V3以惊人的推理速度震撼业界:相比前代模型推理速度提升3倍,训练成本降低70%。这背后是十余项革命性技术的叠加创新,本文将为您揭开这艘"AI超跑"的性能密码。DeepSeek-V3的技术路径证明:计算效率的本质是知识组织的效率。其MoE架构中2048个专家的动态协作,恰似人脑神经网络的模块化运作——每个专家不再是被动执行计算的"劳工",而是具
- React性能优化的8种方式
Mr.BoBo.
前端#Reactreact.js性能优化前端
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档文章目录前言1、Reac.memo缓存组件2、使用useMemo缓存大量的计算3、避免使用内联对象4、避免使用匿名函数5、延迟加载不是立即需要的组件6、调整CSS而不是强制组件加载和卸载7、使用React.Fragment避免添加额外的DOM8、使用React.PureComponent,shouldComponentUpdate9、
- 包管理工具
她的双马尾
JSjavascript包管理工具npmyarnpnpm
JavaScript包管理工具对比:npm、yarn和pnpm1.npm1.1历史与背景npm(NodePackageManager)是Node.js的默认包管理工具,首次发布于2010年。它是JavaScript生态系统中最早的包管理工具,主要用于管理和共享JavaScript模块。目前,npm拥有全球最大的JavaScript包注册中心(npmregistry),包含数百万个开源包。1.2核心
- React状态管理
她的双马尾
Reactreact.js前端javascript
状态管理概念状态管理是指如何高效地管理和共享组件中的状态。React提供了useState和useReducer来管理本地状态,而对于全局状态,可以使用ContextAPI或第三方库(如Redux)。用法本地状态:使用useState或useReducer。全局状态:使用ContextAPI或Redux。使用场景本地状态:组件内部的状态,如表单输入、按钮点击。全局状态:需要跨组件共享的状态,如用户
- 大疆C++开发面试题及参考答案
大模型大数据攻城狮
信号量C++面试C++面经堆和栈TCP和UDP智能指针C++11
虚函数的作用是什么?虚函数机制是如何实现的?虚表指针在内存中的存放位置在哪里?虚函数主要用于实现多态性。多态是面向对象编程中的一个重要概念,它允许通过基类指针或引用调用派生类中重写的函数。这样可以在运行时根据对象的实际类型来确定调用哪个函数,增强了程序的灵活性和可扩展性。在实现虚函数机制方面,C++使用了虚函数表(v-table)。当一个类包含虚函数时,编译器会为这个类创建一个虚函数表。虚函数表是
- 【React】List使用QueueAnim动画效果不生效——QueueAnim与函数组件兼容性问题
Yvette-W
Reactreact.jslist前端前端框架javascript
版本:“antd-mobile”:“^5.37.1”,“rc-queue-anim”:“^2.0.0”,问题在使用QueueAnim时,如果动画的子元素是AntDesignMobile中的组件(如List.Item),可能会遇到动画不生效的问题,并且会看到类似以下警告:Warning:Functioncomponentscannotbegivenrefs.Attemptstoaccessthisr
- 1.✨学习系统浅探
*TQK*
自我认知规划(不让别人看)认知提升
不要过于苛求完美,允许自己偶尔放松,保持积极心态。长期坚持比短期高强度更重要,尤其是为三年后的考研做准备,需要持续的努力而不是一时的冲刺。定期复盘,调整计划。如果某天状态不好,可以适当减少任务量,保持弹性。同时,保证足够的睡眠和运动,这对维持多巴胺水平和整体精力很重要。一、系统构建一Deepseek指令我的大一下学期已经开始了,这一学期我又有新的计算机课程。上一学期我学了C语言,基础知识掌握的还可
- OpenStack 云平台的深度定制与性能优化
算法探索者
openstack
引言OpenStack作为一款领先的开源云平台,以其高度的灵活性和可扩展性,为企业构建云计算基础设施提供了强大的支持。然而,不同企业的业务场景和技术需求千差万别,原生的OpenStack部署往往无法完全满足企业特定的要求。因此,对OpenStack云平台进行深度定制,并在此基础上进行性能优化,成为了企业充分发挥OpenStack优势、提升云服务质量的关键。本文将深入探讨如何针对企业特定需求对Ope
- HTML5!进击2025web蓝桥杯复习之路
Deepsleep.
html5前端html
#HTML5全面解析##目录1.[HTML5简介](#1-html5-简介)2.[基本标签](#2-基本标签)3.[新特性](#3-新特性)4.[本地存储](#4-本地存储)5.[总结](#5-总结)---##1.HTML5简介HTML5是HTML的第五个主要版本,2014年由W3C正式发布。主要特性包括:-语义化标签-多媒体支持-图形绘制(Canvas/SVG)-本地存储能力-WebWorker
- uniapp
Deepsleep.
uni-app
uni-app是一个使用Vue.js开发所有前端应用的框架,可以编译到iOS、Android、H5、以及各种小程序等多个平台。以下是uni-app页面生命周期的详细介绍,包括一些简单的示例:初始化阶段onLoad(options)触发时机:页面加载时触发,且只触发一次。参数:options是一个包含页面路径参数的对象。示例:从上一个页面传递参数到当前页面。onLoad(options){conso
- Seata分布式事务框架及四种模式原理解析
Cloud_.
分布式seatajavaSeata-AXSeata-AT
一、Seata核心概念Seata(SimpleExtensibleAutonomousTransactionArchitecture)是阿里开源的分布式事务解决方案,核心思想是通过事务协调器(TC)统一管理全局事务分支的状态,协调资源管理器(RM)和事务管理器(TM)完成事务的提交与回滚。核心组件:TC(TransactionCoordinator):全局事务协调者,维护全局事务状态,驱动分支事务
- PV操作(Java代码)进程同步实战指南
Cloud_.
java开发语言操作系统并发
引言在Java并发编程中,资源同步如同精密仪器的齿轮咬合,任何偏差都可能导致系统崩溃。本文将以Java视角解析经典PV操作原理,通过真实可运行的代码示例,带你掌握线程同步的底层实现逻辑。一、Java信号量实现机制1.1Semaphore类解析importjava.util.concurrent.Semaphore;//创建包含5个许可的信号量(相当于计数信号量)Semaphoresemaphore
- Spring Boot 整合 RabbitMQ:注解声明队列与交换机详解
Cloud_.
java-rabbitmqspringbootrabbitmqMQ消息队列
RabbitMQ作为一款高性能的消息中间件,在分布式系统中广泛应用。SpringBoot通过spring-boot-starter-amqp提供了对RabbitMQ的无缝集成,开发者可以借助注解快速声明队列、交换机及绑定规则,极大简化了配置流程。本文将通过代码示例和原理分析,详细介绍如何用注解实现RabbitMQ的集成,并深入解析交换机的作用与类型。一、环境准备1.添加依赖在pom.xml中引入S
- 【STM32实物】基于STM32的扫地机器人/小车控制系统设计
阿齐Archie
单片机项目合集stm32机器人单片机mcu
基于STM32的扫地机器人/小车控制系统设计演示视频:基于STM32的扫地机器人小车控制系统设计简介:扫地机器人系统采用分层结构设计,主要包括底层硬件控制层、中间数据处理层和上层用户交互层。底层硬件控制层负责对各个硬件模块进行控制和数据采集,中间数据处理层负责对采集到的数据进行处理和解算,上层用户交互层负责与用户进行交互并显示系统状态信息。主控模块采用STM32F103C8T6开发板,具有高性能、
- AtCoder Beginner Contest 156题解(未完)
wdxcqupt
算法c++
AtCoderBeginnerContest156D-Bouquet题意:一共有n种不同的花,问将x种花组成一束花的方案数,1<=x<=n,x!=a,x!=b。思路:补集思想,总共有∑i=1n\sum_{i=1}^n∑i=1nCniC_n^iCni=2n−12^n-12n−1,种方案,不合情况的有CnaC_n^aCna与CnbC_n^bCnb减去即是答案。E-Roaming题意:有n个房间,每个房
- roaming是什么文件夹?
石大师
Windows系统windows
不少用户向小编发出疑问:roaming是什么文件夹?roaming文件夹是一种可以很容易地与服务器同步的文件夹,它的数据可以随用户的个人资料从一台PC移动到另一台PC中。那roaming文件夹在哪呢?下面就给大家介绍一下roaming的位置。Roaming文件夹是什么?Roaming文件夹是一种可以很容易地与服务器同步的文件夹。它的数据可以随用户的个人资料从一台PC移动到另一台PC——就像当您在w
- Appdata\Local Roaming LocalLow文件夹
ynchyong
系统运维localRoamingLocalLow
自Vista及Win7开始,微软更改了原有的应用程序存储目录结构,(XP是ApplicationData)C\用户\用户名\Appdata,并分为Roaming,Local,及LocalLow三个文件夹.更改原因如下:优化登录速度根据使用安全级别分别访问不同文件夹Windows使用Local及LocalLow文件夹存放非漫游的应用程序数据(类似注册表Local_machine)及一些空间占用大无法
- 最常用的Linux指令手册
忍界英雄
linux运维服务器
最常用的Linux指令手册一、远程连接1.连接远程服务器
[email protected]二、文件与目录操作2.查看目录内容ls:查看目录内容、ls-l:显示详细信息、ls-al/home:包含隐藏文件3.显示当前路径pwd4.切换目录cd/var/www/html5.创建文件touchfile1.txtfile2.txt、touchlinode{1..10}.txt:创建文件6.写入文件
- Kubernets命名空间
忍界英雄
dockerk8s
Kubernets命名空间什么是命名空间命名空间(Namespace)是一种用于组织和隔离Kubernetes资源的机制。在Kubernetes集群中,命名空间将物理集群划分为多个逻辑部分,每个部分都拥有自己的一组资源(如Pod、Service、ConfigMap等),彼此之间互不干扰,实现资源的隔离管理。不仅Kubernetes具备命名空间的概念,在Docker等容器技术中,也通过命名空间(Na
- 08 lua常用自带库(time,Math,package)
小超wuli
Lua语言lua
lua常用自带库(time,Math,package)1>字符串和表string和table2>时间系统时间:os.time(),os.date("*t")返回一个时间记录的表os.date("*t").day-------系统的某日自己传入参数,得到时间:os.time(year=2014,month=8,day=14)3>Mathmath.abs(-999)-----绝对值math.deg(m
- 191113面试题总结
快乐男孩小东
1.Maven中A依赖BB依赖C那么A可以使用C中的类吗?*按照依赖关系,可推C继承A,则C可以使用A中修饰符为public,protected的类2.SpringBoot中有一个类标记了@Controller注解,通过自动扫描把这个类的对象加入IOC,那么这个类应该放那?*在@SpringBootApplication所在包或者下面的子包,才能被自动扫描到#3.通过Maven下载jar包,下载失
- 通信之OTDR
玖Yee
信息与通信
OTDR,即光时域反射仪,是光纤测量中最主要的仪器,被广泛应用于光纤光缆工程的测量、施工、维护及验收工作中,形象地被称为光通信中的“万用表”。工作原理OTDR利用光纤传输通道存在的瑞利散射和菲涅尔反射特性,通过监测瑞利散射的反向散射光的轨迹制成。它向被测光纤发送一光脉冲,光脉冲在光纤本身及各特征点上会有光信号反射回OTDR,反射回的光信号又通过定向耦合到OTDR的接收器,并在这里转换成电信号,最终
- 量子化学仿真软件:Quantum Espresso_(8).dos.x模块使用
kkchenjj
分子动力学2分子动力学仿真模拟模拟仿真人工智能
dos.x模块使用在量子化学仿真软件中,dos.x模块用于计算和分析能态密度(DensityofStates,DOS)。能态密度是描述材料电子结构的重要物理量,可以提供关于材料能带结构、电子态分布和电子性质的详细信息。本节将详细介绍如何使用dos.x模块进行能态密度的计算和分析。1.基本概念1.1能态密度(DOS)定义能态密度(DOS)是指单位能量区间内的量子态数。在固体物理中,DOS可以描述材料
- Python 用户账户(创建用户账户)
钢铁男儿
Python从入门到精通pythonsqlite数据库
Web应用程序的核心是让任何用户都能够注册账户并能够使用它,不管用户身处何方。在本章中,你将创建一些表单,让用户能够添加主题和条目,以及编辑既有的条目。你还将学习Django如何防范对基于表单的网页发起的常见攻击,这让你无需花太多时间考虑确保应用程序安全的问题。然后,我们将实现一个用户身份验证系统。你将创建一个注册页面,供用户创建账户,并让有些页面只能供已登录的用户访问。接下来,我们将修改一些视图
- 202.HarmonyOS NEXT系列教程之图案锁错误处理机制详解
harmonyos-next
温馨提示:本篇博客的详细代码已发布到git:https://gitcode.com/nutpi/HarmonyosNext可以下载运行哦!HarmonyOSNEXT系列教程之图案锁错误处理机制详解效果预览1.错误处理架构1.1错误类型定义//振动功能错误处理try{vibrator.startVibration({type:'preset',effectId:'haptic.clock.timer
- 201.HarmonyOS NEXT系列教程之图案锁生命周期管理详解
温馨提示:本篇博客的详细代码已发布到git:https://gitcode.com/nutpi/HarmonyosNext可以下载运行哦!HarmonyOSNEXT系列教程之图案锁生命周期管理详解效果预览1.生命周期概述@ComponentexportstructPatternLockMainPage{//组件初始化privatepatternLockController:PatternLockC
- 192.HarmonyOS NEXT系列教程之图案锁事件处理机制详解
harmonyos-next
温馨提示:本篇博客的详细代码已发布到git:https://gitcode.com/nutpi/HarmonyosNext可以下载运行哦!HarmonyOSNEXT系列教程之图案锁事件处理机制详解效果预览1.事件系统概述1.1事件类型定义//点连接事件.onDotConnect(()=>{this.startVibrator();})//图案完成事件.onPatternComplete((inpu
- 194.HarmonyOS NEXT系列教程之图案锁交互反馈系统详解
harmonyos-next
温馨提示:本篇博客的详细代码已发布到git:https://gitcode.com/nutpi/HarmonyosNext可以下载运行哦!HarmonyOSNEXT系列教程之图案锁交互反馈系统详解效果预览1.交互反馈系统概述1.1反馈类型//反馈类型定义interfaceFeedbackTypes{visual:boolean;//视觉反馈haptic:boolean;//触觉反馈message:
- apache ftpserver-CentOS config
gengzg
apache
<server xmlns="http://mina.apache.org/ftpserver/spring/v1"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://mina.apache.o
- 优化MySQL数据库性能的八种方法
AILIKES
sqlmysql
1、选取最适用的字段属性 MySQL可以很好的支持大数据量的存取,但是一般说来,数据库中的表越小,在它上面执行的查询也就会越快。因此,在创建表的时候,为了获得更好的 性能,我们可以将表中字段的宽度设得尽可能小。例如,在定义邮政编码这个字段时,如果将其设置为CHAR(255),显然给数据库增加了不必要的空间,甚至使用VARCHAR这种类型也是多余的,因为CHAR(6)就可以很
- JeeSite 企业信息化快速开发平台
Kai_Ge
JeeSite
JeeSite 企业信息化快速开发平台
平台简介
JeeSite是基于多个优秀的开源项目,高度整合封装而成的高效,高性能,强安全性的开源Java EE快速开发平台。
JeeSite本身是以Spring Framework为核心容器,Spring MVC为模型视图控制器,MyBatis为数据访问层, Apache Shiro为权限授权层,Ehcahe对常用数据进行缓存,Activit为工作流
- 通过Spring Mail Api发送邮件
120153216
邮件main
原文地址:http://www.open-open.com/lib/view/open1346857871615.html
使用Java Mail API来发送邮件也很容易实现,但是最近公司一个同事封装的邮件API实在让我无法接受,于是便打算改用Spring Mail API来发送邮件,顺便记录下这篇文章。 【Spring Mail API】
Spring Mail API都在org.spri
- Pysvn 程序员使用指南
2002wmj
SVN
源文件:http://ju.outofmemory.cn/entry/35762
这是一篇关于pysvn模块的指南.
完整和详细的API请参考 http://pysvn.tigris.org/docs/pysvn_prog_ref.html.
pysvn是操作Subversion版本控制的Python接口模块. 这个API接口可以管理一个工作副本, 查询档案库, 和同步两个.
该
- 在SQLSERVER中查找被阻塞和正在被阻塞的SQL
357029540
SQL Server
SELECT R.session_id AS BlockedSessionID ,
S.session_id AS BlockingSessionID ,
Q1.text AS Block
- Intent 常用的用法备忘
7454103
.netandroidGoogleBlogF#
Intent
应该算是Android中特有的东西。你可以在Intent中指定程序 要执行的动作(比如:view,edit,dial),以及程序执行到该动作时所需要的资料 。都指定好后,只要调用startActivity(),Android系统 会自动寻找最符合你指定要求的应用 程序,并执行该程序。
下面列出几种Intent 的用法
显示网页:
- Spring定时器时间配置
adminjun
spring时间配置定时器
红圈中的值由6个数字组成,中间用空格分隔。第一个数字表示定时任务执行时间的秒,第二个数字表示分钟,第三个数字表示小时,后面三个数字表示日,月,年,< xmlnamespace prefix ="o" ns ="urn:schemas-microsoft-com:office:office" />
测试的时候,由于是每天定时执行,所以后面三个数
- POJ 2421 Constructing Roads 最小生成树
aijuans
最小生成树
来源:http://poj.org/problem?id=2421
题意:还是给你n个点,然后求最小生成树。特殊之处在于有一些点之间已经连上了边。
思路:对于已经有边的点,特殊标记一下,加边的时候把这些边的权值赋值为0即可。这样就可以既保证这些边一定存在,又保证了所求的结果正确。
代码:
#include <iostream>
#include <cstdio>
- 重构笔记——提取方法(Extract Method)
ayaoxinchao
java重构提炼函数局部变量提取方法
提取方法(Extract Method)是最常用的重构手法之一。当看到一个方法过长或者方法很难让人理解其意图的时候,这时候就可以用提取方法这种重构手法。
下面是我学习这个重构手法的笔记:
提取方法看起来好像仅仅是将被提取方法中的一段代码,放到目标方法中。其实,当方法足够复杂的时候,提取方法也会变得复杂。当然,如果提取方法这种重构手法无法进行时,就可能需要选择其他
- 为UILabel添加点击事件
bewithme
UILabel
默认情况下UILabel是不支持点击事件的,网上查了查居然没有一个是完整的答案,现在我提供一个完整的代码。
UILabel *l = [[UILabel alloc] initWithFrame:CGRectMake(60, 0, listV.frame.size.width - 60, listV.frame.size.height)]
- NoSQL数据库之Redis数据库管理(PHP-REDIS实例)
bijian1013
redis数据库NoSQL
一.redis.php
<?php
//实例化
$redis = new Redis();
//连接服务器
$redis->connect("localhost");
//授权
$redis->auth("lamplijie");
//相关操
- SecureCRT使用备注
bingyingao
secureCRT每页行数
SecureCRT日志和卷屏行数设置
一、使用securecrt时,设置自动日志记录功能。
1、在C:\Program Files\SecureCRT\下新建一个文件夹(也就是你的CRT可执行文件的路径),命名为Logs;
2、点击Options -> Global Options -> Default Session -> Edite Default Sett
- 【Scala九】Scala核心三:泛型
bit1129
scala
泛型类
package spark.examples.scala.generics
class GenericClass[K, V](val k: K, val v: V) {
def print() {
println(k + "," + v)
}
}
object GenericClass {
def main(args: Arr
- 素数与音乐
bookjovi
素数数学haskell
由于一直在看haskell,不可避免的接触到了很多数学知识,其中数论最多,如素数,斐波那契数列等,很多在学生时代无法理解的数学现在似乎也能领悟到那么一点。
闲暇之余,从图书馆找了<<The music of primes>>和<<世界数学通史>>读了几遍。其中素数的音乐这本书与软件界熟知的&l
- Java-Collections Framework学习与总结-IdentityHashMap
BrokenDreams
Collections
这篇总结一下java.util.IdentityHashMap。从类名上可以猜到,这个类本质应该还是一个散列表,只是前面有Identity修饰,是一种特殊的HashMap。
简单的说,IdentityHashMap和HashM
- 读《研磨设计模式》-代码笔记-享元模式-Flyweight
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
import java.util.ArrayList;
import java.util.Collection;
import java.util.HashMap;
import java.util.List;
import java
- PS人像润饰&调色教程集锦
cherishLC
PS
1、仿制图章沿轮廓润饰——柔化图像,凸显轮廓
http://www.howzhi.com/course/retouching/
新建一个透明图层,使用仿制图章不断Alt+鼠标左键选点,设置透明度为21%,大小为修饰区域的1/3左右(比如胳膊宽度的1/3),再沿纹理方向(比如胳膊方向)进行修饰。
所有修饰完成后,对该润饰图层添加噪声,噪声大小应该和
- 更新多个字段的UPDATE语句
crabdave
update
更新多个字段的UPDATE语句
update tableA a
set (a.v1, a.v2, a.v3, a.v4) = --使用括号确定更新的字段范围
- hive实例讲解实现in和not in子句
daizj
hivenot inin
本文转自:http://www.cnblogs.com/ggjucheng/archive/2013/01/03/2842855.html
当前hive不支持 in或not in 中包含查询子句的语法,所以只能通过left join实现。
假设有一个登陆表login(当天登陆记录,只有一个uid),和一个用户注册表regusers(当天注册用户,字段只有一个uid),这两个表都包含
- 一道24点的10+种非人类解法(2,3,10,10)
dsjt
算法
这是人类算24点的方法?!!!
事件缘由:今天晚上突然看到一条24点状态,当时惊为天人,这NM叫人啊?以下是那条状态
朱明西 : 24点,算2 3 10 10,我LX炮狗等面对四张牌痛不欲生,结果跑跑同学扫了一眼说,算出来了,2的10次方减10的3次方。。我草这是人类的算24点啊。。
然后么。。。我就在深夜很得瑟的问室友求室友算
刚出完题,文哥的暴走之旅开始了
5秒后
- 关于YII的菜单插件 CMenu和面包末breadcrumbs路径管理插件的一些使用问题
dcj3sjt126com
yiiframework
在使用 YIi的路径管理工具时,发现了一个问题。 <?php
- 对象与关系之间的矛盾:“阻抗失配”效应[转]
come_for_dream
对象
概述
“阻抗失配”这一词组通常用来描述面向对象应用向传统的关系数据库(RDBMS)存放数据时所遇到的数据表述不一致问题。C++程序员已经被这个问题困扰了好多年,而现在的Java程序员和其它面向对象开发人员也对这个问题深感头痛。
“阻抗失配”产生的原因是因为对象模型与关系模型之间缺乏固有的亲合力。“阻抗失配”所带来的问题包括:类的层次关系必须绑定为关系模式(将对象
- 学习编程那点事
gcq511120594
编程互联网
一年前的夏天,我还在纠结要不要改行,要不要去学php?能学到真本事吗?改行能成功吗?太多的问题,我终于不顾一切,下定决心,辞去了工作,来到传说中的帝都。老师给的乘车方式还算有效,很顺利的就到了学校,赶巧了,正好学校搬到了新校区。先安顿了下来,过了个轻松的周末,第一次到帝都,逛逛吧!
接下来的周一,是我噩梦的开始,学习内容对我这个零基础的人来说,除了勉强完成老师布置的作业外,我已经没有时间和精力去
- Reverse Linked List II
hcx2013
list
Reverse a linked list from position m to n. Do it in-place and in one-pass.
For example:Given 1->2->3->4->5->NULL, m = 2 and n = 4,
return
- Spring4.1新特性——页面自动化测试框架Spring MVC Test HtmlUnit简介
jinnianshilongnian
spring 4.1
目录
Spring4.1新特性——综述
Spring4.1新特性——Spring核心部分及其他
Spring4.1新特性——Spring缓存框架增强
Spring4.1新特性——异步调用和事件机制的异常处理
Spring4.1新特性——数据库集成测试脚本初始化
Spring4.1新特性——Spring MVC增强
Spring4.1新特性——页面自动化测试框架Spring MVC T
- Hadoop集群工具distcp
liyonghui160com
1. 环境描述
两个集群:rock 和 stone
rock无kerberos权限认证,stone有要求认证。
1. 从rock复制到stone,采用hdfs
Hadoop distcp -i hdfs://rock-nn:8020/user/cxz/input hdfs://stone-nn:8020/user/cxz/运行在rock端,即源端问题:报版本
- 一个备份MySQL数据库的简单Shell脚本
pda158
mysql脚本
主脚本(用于备份mysql数据库): 该Shell脚本可以自动备份
数据库。只要复制粘贴本脚本到文本编辑器中,输入数据库用户名、密码以及数据库名即可。我备份数据库使用的是mysqlump 命令。后面会对每行脚本命令进行说明。
1. 分别建立目录“backup”和“oldbackup” #mkdir /backup #mkdir /oldbackup
- 300个涵盖IT各方面的免费资源(中)——设计与编码篇
shoothao
IT资源图标库图片库色彩板字体
A. 免费的设计资源
Freebbble:来自于Dribbble的免费的高质量作品。
Dribbble:Dribbble上“免费”的搜索结果——这是巨大的宝藏。
Graphic Burger:每个像素点都做得很细的绝佳的设计资源。
Pixel Buddha:免费和优质资源的专业社区。
Premium Pixels:为那些有创意的人提供免费的素材。
- thrift总结 - 跨语言服务开发
uule
thrift
官网
官网JAVA例子
thrift入门介绍
IBM-Apache Thrift - 可伸缩的跨语言服务开发框架
Thrift入门及Java实例演示
thrift的使用介绍
RPC
POM:
<dependency>
<groupId>org.apache.thrift</groupId>