R可视化分析美国的肥胖症,嘿!
邬书豪,车联网数据挖掘工程师 ,R语言中文社区专栏作者。微信ID:wsh137552775
知乎专栏:https://www.zhihu.com/people/wu-shu-hao-67/activities
往期回顾
kaggle案例:数据科学社区调查报告(附学习视频)
kaggle案例:员工离职预测(附学习视频)
Kaggle案例~R可视化分析美国枪击案(附数据集和代码)
kaggle:R可视化分析金拱门餐厅食物营养性(二)
kaggle:R可视化分析金拱门餐厅食物营养性(一)
本文章的主要目的是想研究美国成年人、儿童以及青少年中肥胖人口最多的州。其次展示如何在R中使用rvest包从HTML页面中抓取数据、以及使用ggplot绘制地图。
使用R去做项目的时候,经常会用到R社区的成员开发的程序包,为我们的数据重塑、特征选择以及后续建模等提供了一些列的方便。话不多说,先感谢一波......
首先呢,我们就加载后续将要用到的程序包,为后续的探索分析提供方便。
## 加载相关程序包
require(rvest)
require(ggplot2)
require(dplyr)
require(scales)
require(maps)
library(magrittr)
这次呢,我们所使用的数据是从网页上爬取的。复制代码中的链接,粘贴到搜索引擎就可以看到我们所需要的数据。如下图(展示了一部分我们需要爬取的数据):
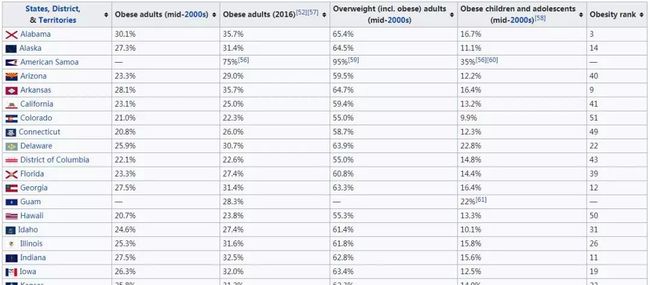
## 从网页上爬取数据
url <- "https://en.wikipedia.org/wiki/Obesity_in_the_United_States"
obesity <- read_html(url)
obesity %<>%
html_nodes(xpath = '//*[@id="mw-content-text"]/div/ table[2]') %>%
.[[1]] %>%
html_table(fill = T)
str(obesity) # 查看数据集的基本数据结构

通过str函数对数据结构的一个简单探索,发现数据需要清洗。比如说,变量名需要规整、有部分样本需要剔除。我们首先对数据变量进行重命名,便于清晰的去理解变量的含义。对列名进行重命名函数最常见的就是base包里面的names函数和colnames函数,使用rownames函数可以对行名进行修改。咱们的数据量是比较小的,所以呢,可以直接通过人工的浏览剔除那些不规整的数据。
## 数据预处理
# 剔除不规整数据+重命名
obesity <- obesity[-c(3, 13, 38, 43, 51), -3] # 剔除不规整数据
names(obesity) <- c('State and District of Columbia', 'Obese adults',
'Overweight (incl. obese) adults',
'Obese children and adolescents',
'Obesity rank')
str(obesity) # 查看数据集的基本数据结构

经过上面的部分清洗后,发现数据中的“%”可以剔除,因为后面我们需要使用数值型数据进行绘图。下面我们使用gsub函数对自定义的字符串进行替换。需要注意的是:字符串替换之后,依旧是字符串的形式,所以需要使用as.numeric函数将其转换为数值型数据。
## 数据预处理
# 去除“%”+ 转换数据类型
for(i in 2:5){
obesity[,i] = gsub("%", "", obesity[,i])
obesity[,i] = as.numeric(obesity[,i])
}
str(obesity)

在R里面,数据的变量名必须得规整,否则会对后续的使用带来不必要的影响,最常用的就是使用make.name函数。常见的不规整变量名有全部是数字的变量名,变量名中出现空格...
## 规范列名
names(obesity)
names(obesity) <- make.names(names(obesity))
names(obesity)

经过上述数据的清洗,我们已经得到了我们后面探索分析所需要的规整的数据,下面我们就开始对美国各地区的肥胖者占比进行探索其分布。
## 探索成年人肥胖症占比最高的前十个地区
# 将“State.and.District.of.Columbia”列转换为小写
obesity$region <- tolower(obesity$State.and.District.of.Columbia)
states <- map_data("state") # 获取美国地图数据
states <- merge(states, obesity, by = "region", all.x = T) # 按‘region’列合并数据
## 按地区统计成年人肥胖症占比,并降序排列选取前十位
topstate <-
states %>%
group_by(region) %>%
summarise(Obese.adults = mean(Obese.adults)) %>%
arrange(desc(Obese.adults)) %>%
top_n(10)
## 绘制条形图
ggplot(topstate, aes(x = reorder(region, Obese.adults), y = Obese.adults)) +
geom_bar(stat = 'identity', color = "black", fill = "#87CEEB") +
labs(x = "Top 10 States", y = "Percentage of Obese Adults") +
coord_flip() +
theme_minimal()
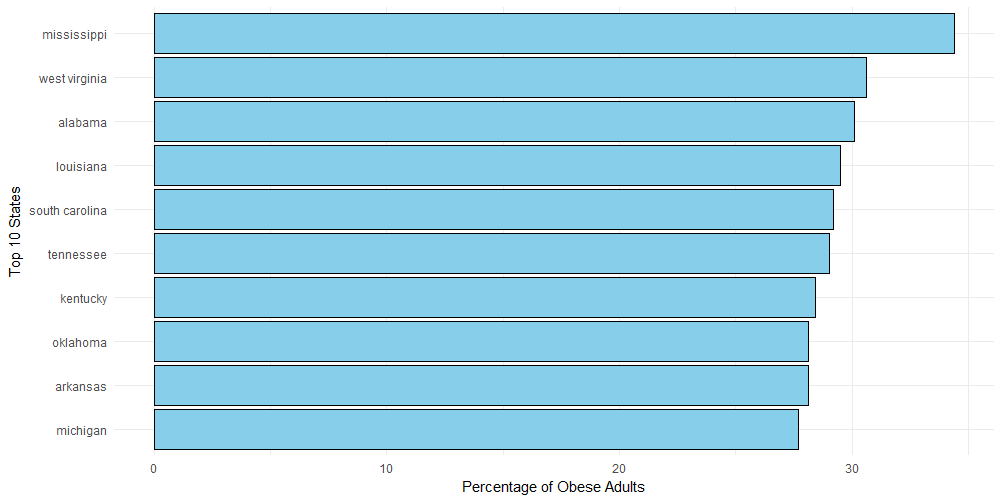
通过上面的美国肥胖成年人占比条形图的展示,我们可以看出,密西西比州的成年肥胖者最多,占比将近35%(太可怕了,三人行,必有”胖子“焉!),其次就是西维吉尼亚州、阿拉巴马州、路易斯安那州......正因为这样呢,美国密西西比州早在2008年,就通过了一个很神奇的法案——《禁止持该州营业执照的餐馆向肥胖人士供应食物》。我猜,这个法案当时引起了不少人的反对吧。
从上面的条形图中,我们可以清晰的看到美国肥胖占比较高的十个地区。下面呢,我们绘制一张美国地图来展示美国各地区的肥胖占比率。
## 可视化美国地图上成年人肥胖症占比分布
ggplot(states, aes(x = long, y = lat, group = group, fill = Obese.adults)) +
geom_polygon(color = "white", show.legend = T) +
scale_fill_gradient(name = "Percent", low = "#FAB8D2", high = "#F91C74", guide = "colorbar", na.value = "black", breaks = pretty_breaks(n = 5)) +
labs(title = "Obesity in Adults for USA", x = "Longitude", y = "Latitude") +
theme_minimal() +
theme(plot.title = element_text(hjust = 0.5, size = 16)) +
geom_text(data = statenames, aes(x = long, y = lat, label = region), size = 3)
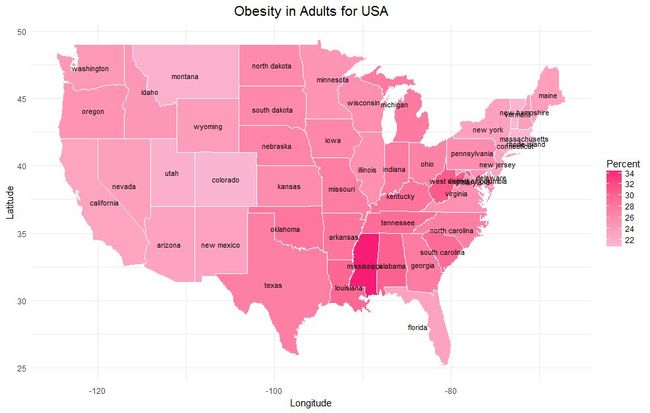
显而易见,在这幅地图中,最”红“的地区也就是肥胖的成年人占比最多的地区。整体而言呢,美国中部肥胖的成年人占比较多、西部和东南部/东北部较小。
接下来,我们对青少年和儿童肥胖者占比做一个统计。依旧是先绘制条形图去查看肥胖占比较多的前十五个地区,再者就是绘制地区去查看分布趋势。
## 探索青年和儿童肥胖症占比最高的前十五个地区
## 按地区统计青年和儿童肥胖症占比,并降序排列选取前十五位
topChild <-
states %>%
group_by(region) %>%
summarise(Obese.Child.and.Teens = mean(Obese.children.and.adolescents)) %>%
top_n(15)
## 绘制条形图
ggplot(topChild, aes(x = reorder(region, Obese.Child.and.Teens),
y = Obese.Child.and.Teens)) +
geom_col(color = "black", fill = "#87CEEB", alpha = 0.8) +
labs(x = 'Top 15 States', y = 'Percentage of Obese Child and Teens') +
coord_flip() +
theme_minimal()
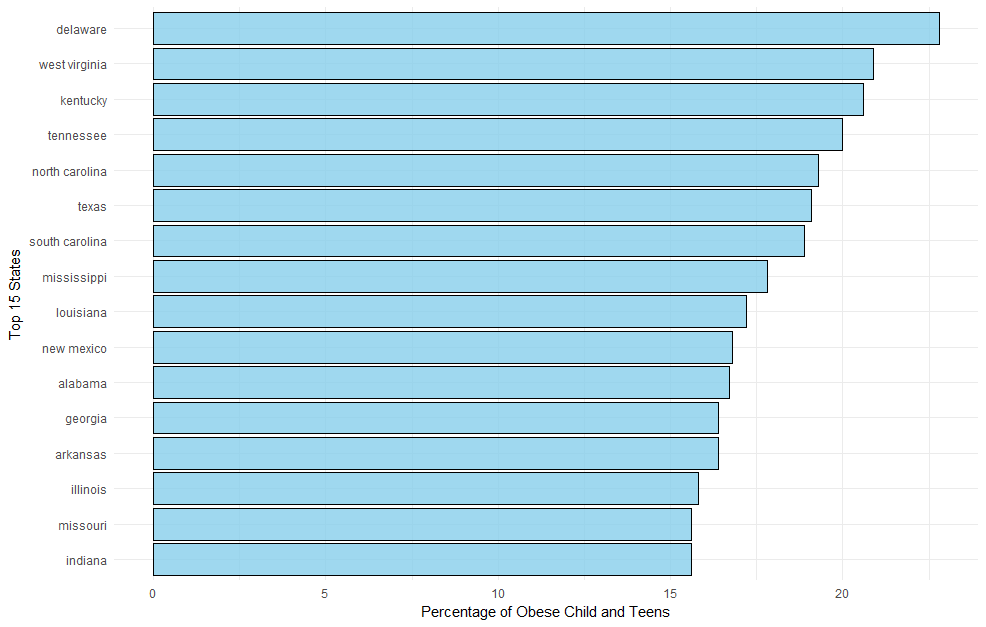
从条形图中可以看到,青少年和儿童肥胖者占比较高的前三个地区分别是:特拉华州、西维吉尼亚州和肯塔基州。密西西比州肥胖的青少年和儿童排名第八,不像成年肥胖者一样,遥居第一!
## 可视化美国地图上青年和儿童肥胖症占比分布
ggplot(states, aes(x = long, y = lat, group = group, fill = Obese.children.and.adolescents)) +
geom_polygon(color = "white") +
scale_fill_gradient(name = "Percent Obese", low = "#B8D5EC",
high = "#0A4B7D", guide = "colorbar", na.value = "black",
breaks = pretty_breaks(n = 5)) +
labs(title = "Obesity in Children and Teens", x = "Longitude",y = "latitude") +
theme_minimal() +
theme(plot.title = element_text(hjust = 0.5, size = 16)) +
geom_text(data = statenames, aes(x = long, y = lat, label = region), size = 3)
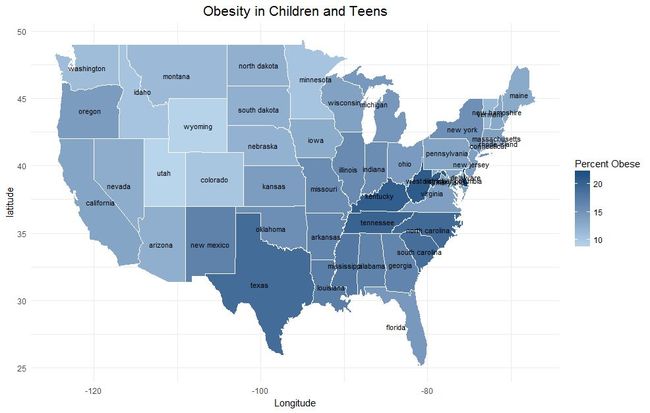
从地图中看得出来,东南部地区肥胖的青少年和儿童占比较高,西北部较低。
到这里,我们对于美国成年人、青少年和儿童的肥胖占比的探索也就结束了。至于都有什么原因导致的美国的肥胖如此严重,成年人、青年人和儿童肥胖者分布区域有并不完全一致,有待有兴趣的大家去查阅相关资料啦......
2017年R语言发展报告(国内)
R语言中文社区历史文章整理(作者篇)
R语言中文社区历史文章整理(类型篇)
相关课程推荐
Kaggle十大案例精讲课程(连载中)

☟☟☟ 猛戳阅读原文,即刻加入课程。