一种从局部到全局的多模态电影场景分割方法 A Local-to-Global Approach to Multi-modal Movie Scene Segmentation
一种从局部到全局的多模态电影场景分割方法
A Local-to-Global Approach to Multi-modal Movie Scene Segmentation
摘要
场景作为电影中讲故事的关键单元,包含了演员在物理环境中的复杂活动及其相互作用。识别场景的构成是理解电影语义的关键一步。这非常具有挑战性——与传统视觉问题(如动作识别)中研究的视频相比,电影中的场景通常包含更丰富的时间结构和更复杂的语义信息。为了实现这个目标,我们通过构建一个大规模的视频数据集来扩大场景分割任务,该数据集包含来自150部电影的21K个带注释的场景片段。我们进一步提出了一个从局部到全局的场景分割框架,它集成了跨三个层次的多模态信息,即剪辑、片段和电影。该框架能够从长电影的层次时间结构中提取复杂的语义,为场景分割提供自上而下的指导。我们的实验表明,该网络能够以高精度将电影分割成场景,始终优于以前的方法。我们还发现,对我们的电影进行预处理可以给现有的方法带来显著的改进。1
1.简介
想象一下,你正在看汤姆·克鲁斯主演的电影《碟中谍》:在一个打斗场景中,伊森跳到一架直升机的着陆滑橇上,在挡风玻璃上粘上一块爆炸的口香糖来消灭敌人。突然,故事跳到了一个激动人心的场景,伊森扣动了扳机,牺牲了自己的生命来救他的妻子朱莉娅。如此戏剧性的场景变化在电影的叙事中起着重要的作用。一般来说,一部电影是由一系列精心设计的有趣的场景和过渡组成的,其中底层的故事情节决定了场景呈现的顺序。因此,识别电影场景,包括场景边界的检测和场景内容的理解,有助于广泛的电影理解任务,如场景分类、跨电影场景检索、人机交互图和以人为本的故事情节构建。

当我们看图(a)中的任何一个镜头时,例如镜头B中的女人,我们不能推断当前的事件是什么。只有当我们考虑到这个场景中的所有镜头1-6,如图(b)所示,我们才能认识到“这个女人在邀请一对情侣和乐队跳舞。”
值得注意的是,场景和镜头本质上是不同的。一般来说,一个镜头是由一个不间断运行一段时间的摄像机拍摄的,因此在视觉上是连续的;而场景是更高级别的语义单元。如图1所示,一个场景由一系列镜头组成,呈现故事语义连贯的部分。因此,尽管可以使用现有工具基于简单的视觉线索将电影容易地划分成镜头[23],但是识别构成场景的那些镜头子序列的任务是具有挑战性的,因为它需要语义理解,以便发现语义一致但视觉上不同的那些镜头之间的关联。
关于视频理解已经有了广泛的研究。尽管在这一领域取得了很大进展,但大多数现有的工作都集中在从短视频中识别某些活动的类别上[28,6,14]。更重要的是,这些作品假设了一个预先定义的类别列表,这些类别在视觉上是可区分的。但是对于电影场景分割,不可能有这样的类别列表。此外,镜头是根据它们的语义连贯性而不仅仅是视觉线索来分组的。因此,需要为此开发一种新方法。
要把视觉上不同的镜头联系起来,我们需要语义上的理解。这里的关键问题是“没有类别标签怎么学语义?”我们解决这个问题的想法包括三个方面:1)我们不试图对内容进行分类,而是关注场景边界。我们可以通过监督的方式了解场景之间的边界是由什么构成的,从而获得区分场景内和跨场景过渡的能力。2)我们利用包含在多个语义元素中的线索,包括地点、演员、动作和音频,来识别镜头之间的关联。通过整合这些方面,我们可以超越视觉观察,更有效地建立语义联系。3)我们也从对电影的整体理解上探索自上而下的引导,带来进一步的性能提升。
基于这些思想,我们开发了一个从局部到全局的框架,该框架通过三个阶段执行场景分割:1)从多个方面提取镜头表示,2)基于集成的信息进行局部预测,最后3)通过解决全局优化问题来优化镜头的分组。为了促进这项研究,我们构建了一个大规模的数据集,包含超过21K个场景,包含来自150部电影的超过270K个镜头。实验表明,我们的方法比现有的最佳方法提高了68%(平均精度从28.1提高到47.1)。在我们的数据集上预处理的现有方法在性能上也有很大的提高。
2.相关工作
场景边界检测和分割 最早的作品利用了各种无人监管的方法。[22]根据镜头颜色相似性对镜头进行聚类。在[17]中,作者根据低级视觉特征绘制了一条镜头响应曲线,并设置了一个阈值来剪切场景。[4,3]使用具有快速全局k-均值算法的谱聚类的进一步组镜头。[10,24]通过优化预定义的优化目标,用动态规划来预测场景边界。研究人员还求助于其他模态信息,例如,[13]利用带有隐马尔可夫模型的脚本,[23]使用低级视觉和听觉特征来构建场景转换图。这些无监督的方法不灵活,并且严重依赖于为不同的视频手动设置参数。研究人员转向监督方法,并开始建立新的数据集。IBM OVSD [21]由21个场景粗糙的短视频组成,可能包含不止一个情节。BBC星球地球[1]来自BBC纪录片的11集。[15]从地点205 [31]生成合成数据。然而,这些数据集中的视频缺乏丰富的情节或故事情节,因此限制了它们在现实世界中的应用。测试视频的数量很少,考虑到场景的多样性,这不能反映方法的有效性。另外,他们的方法以镜头为分析单元,在局部区域递归实现场景分割。由于缺乏对场景内部语义的考虑,很难学习高级语义并达到理想的效果。
图像和短视频中的场景理解 基于图像的场景分析[31,29,9]可以推断出关于场景的一些基本知识,例如该图像中包含什么。然而,很难从单个静态图像中辨别动作,因为它周围缺乏上下文信息。动态场景理解通过几秒钟长的短视频进一步研究[6,14]。然而,与长视频相比,所有这些视频都是单镜头视频,没有足够的变化来捕捉时间和地点的变化。
长视频中的场景理解 长视频中关注场景的数据集很少。大多数可用的长视频数据集侧重于识别电影或电视剧中的演员[2,12,16]以及定位和分类动作[8]。电影图解[26]关注电影中的单个场景片段和场景的语言结构。场景之间的一些过渡部分被丢弃,使得信息不完整。为了实现更一般的场景分析,可以扩展到长时间持续的视频,我们使用大规模的电影数据集来处理电影中的场景分割。我们提出了一个框架,使用多个语义元素来考虑局部镜头之间的关系和全局场景之间的关系,从而获得更好的分割结果。
3.电影场景数据集
为了便于理解电影中的场景,我们构建了一个大规模的场景分割数据集,该数据集包含21K个场景,这些场景是通过对150部电影中的270K个镜头进行分组而得到的。该数据集为研究场景内的复杂语义提供了基础,并有助于对场景顶部的基于情节的长视频理解。
3.1场景定义
根据先前对场景[17,4,10,24]的定义,场景是一个基于情节的语义单元,其中某一活动发生在某一组角色之间。虽然一个场景经常发生在一个固定的地方,但也有可能一个场景在多个地方之间不断穿梭,例如在电影中的打斗场景中,角色从室内移动到室外。场景中这些复杂的纠缠给需要高级语义信息的场景的准确检测带来了更多的困难。图2展示了电影中带注释场景的一些例子,展示了这一困难。

电影布鲁斯·阿尔米特(2003)的注释场景示例。底部的蓝线对应于整个电影时间线,其中深蓝色和浅蓝色区域代表不同的场景。在场景10中,角色在两个不同的地方打电话,因此需要对这个场景有语义上的理解,以防止它将他们分成不同的场景。在场景11中,任务变得更加困难,因为这个直播场景涉及三个以上的地方和角色组。在这种情况下,只有视觉提示可能会失败,因此包括其他方面,如音频提示变得至关重要。
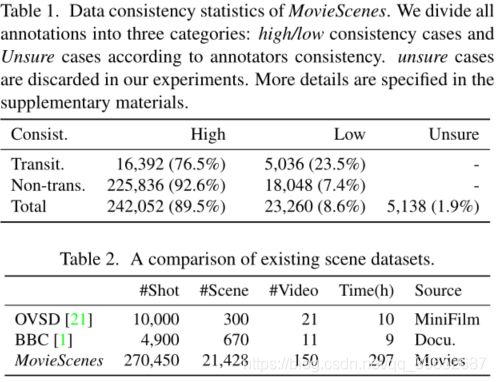
电影的数据一致性统计。根据注释者的一致性,我们将所有的注释分为三类:高/低一致性情况和不确定性情况。在我们的实验中,不确定的病例被丢弃。更多细节在补充材料中有详细说明。
电影场景的巨大多样性使得注释者很难相互遵从。为了确保来自不同注释的结果的一致性,在注释过程中,我们提供了一个带有具体指导的模糊示例列表,以阐明应该如何处理这种情况。而且,所有数据都由不同的标注器独立标注多次。最后,我们根据所提供的指导进行了多次注释,得到了高度一致的结果,即总共89.5%的高一致性案例,如表1所示
3.2标注工具与流程
我们的数据集包含150部电影,如果注释者一帧一帧地查看电影,工作量会大得惊人。我们采用了一种基于镜头的方法,这种方法基于这样一种理解,即一个镜头2应该总是被唯一地分类到一个场景中。因此,场景边界必须是所有镜头边界的子集。对于每部电影,我们首先用现成的方法把它分成镜头[23]。这种基于镜头的方法大大简化了场景分割任务,并加快了注释过程。我们还开发了一个基于网络的注释工具3来方便注释。所有的标注者都经历了两轮标注过程,以确保高一致性。在第一轮中,我们将每一个电影块分派给三个独立的注释器,以便以后进行一致性检查。在第二轮中,不一致的注释将被重新分配给另外两个注释器进行额外的评估。
3.3标注统计
大规模。表2比较了电影和现有的相似视频场景数据集。我们表明,就镜头/场景的数量和总持续时间而言,电影数据集明显大于其他数据集。此外,与短片或纪录片相比,我们的数据集涵盖了更广泛的各种数据源,捕捉各种场景。
多元化。我们数据集中的大多数电影持续时间在90到120分钟之间,提供了关于单个电影故事的丰富信息。涵盖了广泛的流派,包括最受欢迎的,如戏剧,惊悚片,动作电影,使我们的数据集更加全面和普遍。注释场景的长度从不到10秒到超过120秒不等,其中大多数持续10∞30秒。电影级别和场景级别都存在很大的可变性,这使得电影场景分割任务更具挑战性。
4.局部到全局的场景分割
如上所述,场景是一系列连续的镜头。因此,场景分割可以被公式化为二元分类问题,即确定镜头边界是否是场景边界。然而,这个任务并不容易,因为分割场景需要识别多个语义方面和使用复杂的时间信息。为了解决这个问题,我们提出了一个从局部到全局的场景分割框架(LGSS)。等式1显示了整个公式。具有n个镜头的电影被表示为镜头序列[s1,sn],其中每个镜头用多个语义方面来表示。我们设计了一个三层模型来整合不同层次的上下文信息,即剪辑级(B)、片段级(T)和电影级(G),基于镜头表示si。我们的模型给出了一系列预测[o1,on 1],其中oi∑{ 0,1}表示第I个和第(i + 1)个镜头之间的边界是否是场景边界。
G{T[B([s_1,s_2,⋯,s_n ])]}=[o_1,o_2,⋯,o_(n-1) ]
在本节接下来的部分,我们将首先介绍如何获取si,即如何用多个语义元素表示镜头。然后我们将说明我们模型的三个层次的细节,即B、T和g。总体框架如图3所示。
4.1 具有语义元素的镜头表现
电影是一种典型的多模态数据,包含不同的高级语义元素。由神经网络从镜头中提取的全局特征,在以前的工作中被广泛使用[1,24],不足以捕获复杂的语义信息。场景是一系列镜头共享一些共同元素的地方,例如地点、演员等。因此,考虑这些相关的语义元素对于更好的镜头表现是很重要的。在我们的LGSS框架中,镜头由四个在场景构成中起重要作用的元素来表示,即地点、演员、动作和音频。
为了获得每个镜头si的语义特征,我们利用1)预处理在关键帧图像上的位置数据集[31]上的ResNet50 [11]来获得位置特征,2)预处理在计算机集成制造数据集[12]上的更快的RCNN [19]来检测转换实例,预处理在PIPA数据集[30]上的ResNet50来提取转换特征,3)预处理在视听数据集[8]上的TSN [27]来获得动作特征,4)预处理在视听说话者数据集[20]上的导航网络[5] 和短时傅立叶变换[25]来分别获得它们在16K赫兹采样率和512窗口信号长度的镜头中的特征,并将它们连接起来以获得音频特征。
4.2剪辑级别的镜头边界表示
如前所述,场景分割可以表述为镜头边界上的二元分类问题。因此,如何表示镜头边界成为一个至关重要的问题。在这里,我们提出一个边界网络来模拟镜头边界。如等式2所示,表示为B的BNet将具有2个快照的电影剪辑作为输入,并输出边界表示bi。受边界表示应该捕捉前后镜头之间的差异和关系的直觉的驱使,BNet由两个分支组成,即Bdand Br。BDI由两个时间卷积层建模,每个层分别在边界前后嵌入镜头,然后进行内积运算来计算它们的差异。为了捕捉镜头的关系,它是由一个时间卷积层跟随一个最大池来实现
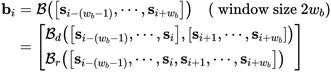
4.3段级粗略预测
在我们获得每个镜头边界bi的代表之后,问题变成基于代表序列[b1,,bn 1]预测二进制标记序列[o1,o2,on 1],这可以通过sequenceto-sequence模型[7]来解决。但是镜头数n通常大于1000,现有的序列模型很难包含这么长的内存。因此,我们设计了一个片段级模型来预测基于由wtshots (wt≪ n)组成的电影片段的粗略结果。具体来说,我们使用序列模型T,例如双LSTM [7],用步幅wt/2镜头来预测一系列粗略得分[p1,pn 1],如等式3所示。这里pi∈ [0,1]是镜头边界成为场景边界的概率。
[p_1,⋯,p_(n-1) ]=T([b_1,⋯,b_(n-1) ])
然后我们得到一个粗预测oi∑{ 0,1},它指示第I个镜头边界是否是场景边界。通过用阈值τ二值化pi,我们得到
4.4电影级全局最优分组
由片段级模型T获得的分割结果是不够好的,因为它只考虑了wtshots上的局部信息,而忽略了整个电影上的全局上下文信息。为了捕捉全局结构,我们开发了一个全局优化模型G来考虑电影级的上下文。它采用镜头表示sia和粗略预测oias输入,并作出如下最终决定oias,
[o1,· · · , on−1] = G([s1,· · · ,sn],[¯ o1,· · · , ¯ on−1])
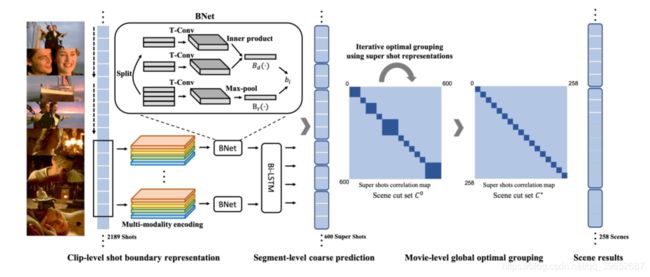
本地到全球场景分割框架(LGSS)。在剪辑级别,我们为每个镜头提取四个编码,并使用一个BNet来模拟镜头边界。局部序列模型在片段级输出粗略的场景切割结果。最后,在电影层面,采用全局最优分组来细化场景分割结果。
全局最优模型G被公式化为优化问题。在介绍之前,我们先建立超镜头和目标函数的概念。局部分割为我们提供了一个初始的粗略场景切割集C = {Ck},这里我们将Ckas表示为一个超级镜头,即由分割级别结果[ o1,on 1]确定的连续镜头序列。我们的目标是将这些超级镜头合并成j个场景φ(n = j)= {φ1,。。。,φj},其中C = S +j k=1φkand |φk| ≥ 1。由于没有给出j,为了自动决定目标场景号j,我们需要查看所有可能的场景切割,即F = maxj,j<|C|F(n = j)。用固定的j,我们想找到最佳场景切集φ⋆(n = j)。总体优化问题如下,

这里,g(φk)是由场景φk获得的最佳场景切割分数。它规定了超级镜头C1∈φ和其余超级镜头Pk,l =φk \ C1之间的关系。g(φk)由两个项组成,以捕捉全局关系和局部关系,Fs(Ck,Pk)是Ckand Pk之间的相似性分数,Ft(Ck,Pk)是指示Ckand与来自Pkaiming的任何超级镜头之间是否有非常高的相似性的指示函数,以形成场景中的镜头线索。具体来说
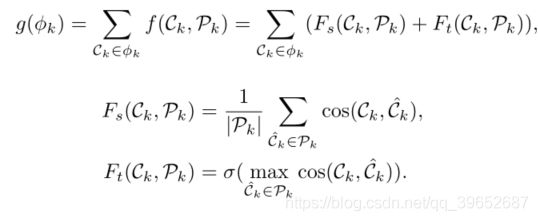
DP。动态规划可以有效地解决优化问题和确定目标场景数。F(n = j)的更新为
max k F ⋆ n = j − 1 ∣ C 1 : k + g ϕ j = C k + 1 , … , C | C | C1:k这是包含前k个超级镜头的场景。迭代优化。上面的DP可以给我们一个场景切割结果,但是我们可以进一步将这个结果作为一个新的超级镜头集,并迭代地合并它们以改善最终结果。当超级镜头更新时,我们也需要更新这些超级镜头表示。对所有包含的镜头进行简单的求和可能不是超级镜头的理想表示,因为有些镜头包含的信息较少。因此,如果我们在最佳分组中细化超级镜头的表示会更好。关于超镜头表现的细节在补充中给出。
5.实验
5.1实验准备
数据。我们用我们的电影数据集实现了所有的基线方法。整个注释集分为训练集、虚拟集和测试集,在视频级别上的比例为10:2:3。
**实施细节。**对于二元分类,我们采用交叉熵损失。由于数据集中存在不平衡,即非场景过渡镜头边界占主导地位(大约9:1),我们对非场景过渡镜头边界和场景过渡镜头边界分别取1:9的交叉熵损失权重。我们用adams优化器为30个时代训练这些模型。初始学习率为0.01,学习率将在第15个纪元除以10。在全局最优分组中,我们根据获得的这些镜头边界的分类分数,从局部分割中取出j = 600个超级镜头(一部电影通常包含1k∞2k个镜头边界。)目标场景的范围是50到400,也就是i ∈ [50,400]。这些值是根据电影统计数据估算的。
**评估指标。**我们采用三个常用指标:1)平均精度。具体来说,在我们的实验中,它是每部电影oi= 1的AP的平均值。2) Miou:检测到的场景边界的并集的交集相对于其到最近的地面真实场景边界的距离的加权和。3)回忆@3s:回忆在3秒时,位于预测边界3s内的注释场景边界的百分比。
5.2定量结果
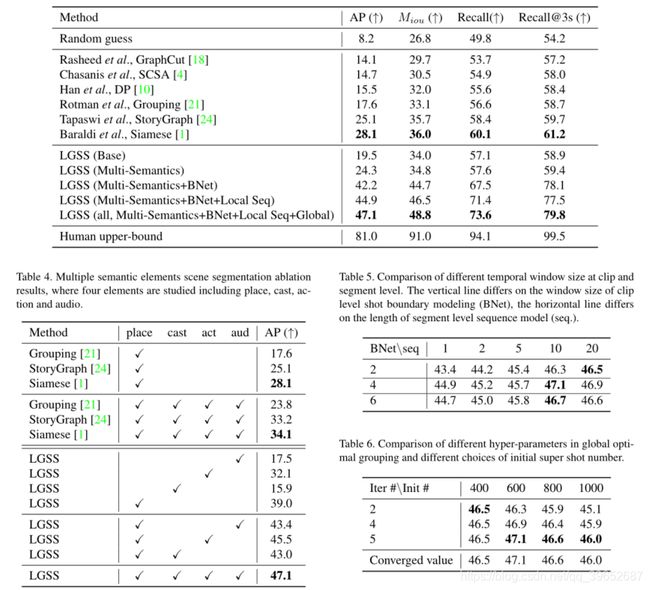
总体结果如表3所示。我们复制了现有的方法[18,4,10,21,24,1],这些方法具有深层特征,以便进行公平的比较。基本模型对具有位置特征的镜头应用时间卷积,并且我们逐渐向其添加以下四个模块,即1)多个语义元素(多语义),2)剪辑级镜头边界表示(BNet),3)利用局部序列模型(Local Seq)在片段级粗略预测,以及4)电影级全局最优分组(global)。
总体结果分析。随机方法的性能取决于测试集中场景过渡/非场景过渡镜头边界的比例,约为1 : 9。所有的传统方法[18,4,10,21]都优于随机猜测,但是没有获得好的性能,因为它们只考虑了局部上下文信息,而没有捕获语义信息。[24,1]通过考虑大范围信息,获得比常规方法[18,4,10,21]更好的结果。对我们框架的分析。我们的基本模型对具有位置特征的镜头应用时间卷积,并且在AP上实现了19.5。在多个语义元素的帮助下,我们的方法从19.5(基本)提高到24.3(多语义) (相对提高了24.6%)。使用BNet的镜头边界建模框架将性能从24.3(多语义)提高到42.2(多语义+BNet)(相对提高73.7%),这表明在场景分割任务中,直接建模镜头边界是有用的。采用局部序列模型(多语义+贝叶斯网络+局部序列)的方法比模型(多语义+贝叶斯网络)的绝对改进率为2.7%,相对改进率为6.4%,从42.2%提高到44.9%。完整的模型包括局部序列模型和全局优化分组(多语义+局部序列+全局)进一步将结果从44.9提高到47.1,这表明电影级优化对场景分割很重要。总之,在多个语义元素、剪辑级镜头建模、片段级局部序列模型和电影级全局最优分组的帮助下,我们的最佳模型大大优于基础模型和以前的最佳模型[1],在基础模型(base)上绝对提高了27.6%,相对提高了142%,在暹罗模型[1]上绝对提高了19.0%,相对提高了68%。这些验证了这种本地到全球框架的有效性。
5.3.消融研究
多个语义元素。
我们以镜头边界建模的流水线、局部序列模型和全局最优分组为基础模型。如表4所示,逐渐添加中层语义元素提高了最终结果。从仅使用place的模型开始,音频提高了4.4,动作提高了6.5,casts提高了4.0,以及8.1。该结果表明,地点、演员、动作和音频都是有助于场景分割的有用信息。此外,借助我们的多语义元素,其他方法[21,24,1]实现了20%∞30%的相对改进。这个结果进一步证明了我们的假设,即多语义元素有助于场景分割。
时间长度的影响。我们在片段级的镜头边界建模中选择不同的窗口大小,在片段级选择不同的双LSTM序列长度。结果如表5所示。实验表明,信息范围越大,性能越好。有趣的是,最好的结果来自于镜头边界建模的4个镜头和作为局部序列模型的输入的10个镜头边界,这总共涉及14个镜头信息。这大约是一个场景的长度。表明这一范围的时间信息有助于场景分割。
全局最优分组中超参数的选择。我们不同的优化迭代次数(Iter #)和表5。剪辑和片段级别的不同时间窗口大小的比较。垂直线取决于剪辑级镜头边界建模(BNet)的窗口大小,水平线取决于片段级序列模型(seq)的长度。).BNet \ seq 1 2 5 10 20 2 43.4 44.2 45.4 46.3 46.5 4 44.9 45.2 45.7 47.1 46.9 6 44.7 45.0 45.8 46.7 46.6表6。全局最优分组中不同超参数的比较及初始超射数的不同选择。ITER # \ Init # 400 600 800 1000 2 46.5 46.3 45.9 45.1 4 46.5 46.9 46.4 45.9 5 46.5 47.1 46.6 46.0收敛值46.5 47.1 46.6 46.0初始超级镜头数(Init #)并在表6中显示结果。我们首先看一看每一行,并更改初始超级镜头数。初始数量为600的设置达到了最佳效果,因为它接近目标场景数量50∞400,同时确保了足够大的搜索空间。然后我们在看每一列的时候,观察到初始数为400的设定以最快的方式收敛。它在2次迭代后很快达到最佳结果。所有的设置都在5次迭代中覆盖。
5.4定量结果
显示我们多模态方法有效性的定性结果如图4所示,全局最优分组的定性结果如图5.5
多语义元素所示。为了量化多个语义元素的重要性,我们对每个模态取余弦相似性的范数。图4 (a)显示了一个例子,其中演员在连续镜头中非常相似,有助于场景的形成。在图4 (b)中,人物和他们的动作很难辨认:第一个镜头是人物很小的长镜头,最后一个镜头只显示了人物的一部分,没有清晰的脸。在这些情况下,由于这些镜头之间共享的相似音频特征,场景被识别。图4 ©是一个典型的“电话”场景,每个镜头中的动作都是相似的。在图4 (d)中,只有一个地方是相似的,我们仍然将其总结为一个场景。从以上对更多此类案例的观察和分析中,我们得出以下经验结论:多模态信息是相辅相成的,有助于场景分割。
最佳分组。我们用两个例子来说明最优分组的有效性。图5中有两个场景。在没有全局最优分组的情况下,具有突然视点变化的场景很可能预测场景转变(图中的红线),例如,在第一种情况下,当镜头类型从完整镜头变为近景镜头时,粗略预测得到两个场景剪辑。在第二种情况下,当一个极端的特写镜头出现时,粗略的预测得到一个场景剪辑。我们的全局最优分组能够像我们预期的那样平滑掉这些冗余场景剪辑。
5.5.跨数据集转移
我们在现有数据集OVSD [1]和英国广播公司[21]上测试了不同的方法DP [10]和暹罗[1],并对我们的电影数据集进行了预处理,结果如表7所示。通过对数据集的预处理,性能得到了显著的提高,即绝对性能提高了10%,相对性能提高了15%。这是因为我们的数据集覆盖了更多的场景,并为预处理后的模型带来了更好的泛化能力。

图4 多语义元素解释,其中每个语义元素的相似性范数由对应的条长表示。这四个电影片段说明了不同的元素如何对场景的预测做出贡献。
图5。两种情况下全局最优分组的定性结果。在每种情况下,第一行和第二行分别是全局最优分组前后的结果。两个镜头中间的红线表示有场景切换。每个案例的基本事实是,这些镜头属于同一个场景。
6.结论
在这项工作中,我们收集了150部电影的大规模场景分割标注集,其中包含270K个标注。我们提出了一个从局部到全局的场景分割框架来覆盖分层的时间和语义信息。实验表明,该框架非常有效,比现有方法取得了更好的性能。一个成功的场景分割能够支持许多电影理解应用。6本文的所有研究表明,场景分析是一个具有挑战性但有意义的课题,值得进一步研究。本项工作得到了香港普通研究基金(GRF)(编号:14203518 &编号:14205719)和SenseTime大规模多模态分析合作基金的部分资助。