yolov4_u5版复现—2. 模型及相关原理model.py
1.关于yaml文件解析:
yolov4_u5 使用yaml文件存储模型结构信息,将其读入解析后再build模型。
# parameters
nc: 80 # number of classes
depth_multiple: 1.0 # expand model depth
width_multiple: 1.0 # expand layer channels
# anchors
anchors:
- [12,16, 19,36, 40,28] # P3/8
- [36,75, 76,55, 72,146] # P4/16
- [142,110, 192,243, 459,401] # P5/32
# yolov4l backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [32, 3, 1]], # 0
[-1, 1, Conv, [64, 3, 2]], # 1-P1/2
[-1, 1, Bottleneck, [64]],
[-1, 1, Conv, [128, 3, 2]], # 3-P2/4
[-1, 2, BottleneckCSP, [128]],
[-1, 1, Conv, [256, 3, 2]], # 5-P3/8
[-1, 8, BottleneckCSP, [256]],
[-1, 1, Conv, [512, 3, 2]], # 7-P4/16
[-1, 8, BottleneckCSP, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 9-P5/32
[-1, 4, BottleneckCSP, [1024]], # 10
]
# yolov4l head
# na = len(anchors[0])
head:
[[-1, 1, SPPCSP, [512]], # 11
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[8, 1, Conv, [256, 1, 1]], # route backbone P4
[[-1, -2], 1, Concat, [1]],
[-1, 2, BottleneckCSP2, [256]], # 16
[-1, 1, Conv, [128, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[6, 1, Conv, [128, 1, 1]], # route backbone P3
[[-1, -2], 1, Concat, [1]],
[-1, 2, BottleneckCSP2, [128]], # 21
[-1, 1, Conv, [256, 3, 1]],
[-2, 1, Conv, [256, 3, 2]],
[[-1, 16], 1, Concat, [1]], # cat
[-1, 2, BottleneckCSP2, [256]], # 25
[-1, 1, Conv, [512, 3, 1]],
[-2, 1, Conv, [512, 3, 2]],
[[-1, 11], 1, Concat, [1]], # cat
[-1, 2, BottleneckCSP2, [512]], # 29
[-1, 1, Conv, [1024, 3, 1]],
[[22,26,30], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
为了清晰起见画了个网络模型(不包含子模块数量,子模块结构见上一篇,纠正一下:最后一个BottleneckCSP2 的c=512,图中最后一层即,c=1024 的Conv前面一层):

2. Detect() 成员介绍:
其中
anchors: [[12,16, 19,36, 40,28],[36,75, 76,55, 72,146],[142,110, 192,243, 459,401] ]
anchors将会在Model初始化时映射到三个不同的特征图坐标系下,用以计算loss。
class Detect(nn.Module):
def __init__(self, number_class, anchors=(), channel_in=()):
super(Detect, self).__init__()
self.stride = None # build in Model()
self.number_class = number_class
self.number_output_per_anchor = number_class + 5 # class + location + score
self.number_anchor_per_pixel = len(anchors[0]) // 2
self.number_detection_layer = len(anchors)
anchors = torch.tensor(anchors).float().view(self.number_detection_layer, -1, 2)
# anchors will map to detecton layer in Model()
self.register_buffer('anchors', anchors) # shape [number_detection_layer, number_anchor_per_pixel, 2]
# shape [number_detection_layer, batchsize dim, number_anchor_per_pixel, ydim, xdim, 2]
self.register_buffer('anchor_grid', anchors.clone().view(self.number_detection_layer, 1, -1, 1, 1, 2))
self.detect_model = nn.ModuleList(
[nn.Conv2d(x, self.number_output_per_anchor*self.number_anchor_per_pixel, 1) for x in channel_in])
self.export = False # onnx export
def forward(self, x):
pass
3. 使用从yaml文件读入的模型字典 Build yolov4 的网络结构
(1). 首先读入的字典中 backbone+head 表示网络结构,[from, number, module, args]中,module表示yolov4每个模块,from表示当前module的输入是否来自前一module,-1即前一模块,number表示module的数量,args表示module的初始化参数,但并不是直接传入参数,而是需要解析才能作为module的传入参数,本程序的主要任务就是解析args并build网络模型。
(2)yolo v4 u5的主要剪枝策略(或者说是yolo v5)对网络层数和网络通道数的压缩就设计在此处。
depth_multiple决定每个module的数量,width_multiple决定每个module的网络通道数量
# depth gain, model pruning
number = max(round(number * depth_multiple), 1) if number > 1 else number
# width gain, model pruning
# The number of output channels in the feature map of the network module is a multiple of 8
channel_out = make_divisible(channel_out * width_multiple, 8) \
if channel_out != number_output_per_anchor else channel_out
def parse_model(model_dict, channel_in_list): # model_dict, input_channels(3)
# --------------------------------------------------------------------------------------------------------------
# parse number of classes, anchors
print('\n%3s%18s%3s%10s %-40s%-30s' % ('', 'from', 'n', 'params', 'module', 'arguments'))
number_class, depth_multiple, width_multiple, anchors = model_dict['number_class'], model_dict['depth_multiple'], \
model_dict['width_multiple'], model_dict['anchors']
number_anchor_per_pixel = len(anchors[0])//2
number_output_per_anchor = number_anchor_per_pixel * (number_class + 5)
# --------------------------------------------------------------------------------------------------------------
# parse backbone, head.
# [from, number, module, args]
module_blocks, input_not_from_last_layer, channel_out = [], [], channel_in_list[-1]
for i, (origin, number, module, args) in enumerate(model_dict['backbone'] + model_dict['head']):
# --------------------------------------------------------------------------------------------------------------
# eval module, args
module = eval(module) if isinstance(module, str) else module
for j, arg in enumerate(args):
try:
args[j] = eval(arg) if isinstance(arg, str) else arg
except:
pass
# depth gain, model pruning
number = max(round(number * depth_multiple), 1) if number > 1 else number
# --------------------------------------------------------------------------------------------------------------
# update args in yaml file to module input
# for module = Conv, args = [channel_input, channel_output, kernel, stride]
# for module = Bottleneck, BottleneckCSP, SPPCSP, BottleneckCSP2, args = [channel_input,channel_output, number]
# for module = nn.Upsample, args = [size, scale_factor, mode]
# for module = Concat, args = [dims]
# for module = detect, args = [nc, anchors] to args = [nc, anchors, channel_input]
if module in [Conv, Bottleneck, BottleneckCSP, BottleneckCSP2, SPPCSP]:
channel_in, channel_out = channel_in_list[origin], args[0]
# width gain, model pruning
# The number of output channels in the feature map of the network module is a multiple of 8
channel_out = make_divisible(channel_out * width_multiple, 8) \
if channel_out != number_output_per_anchor else channel_out
# update args
args = [channel_in, channel_out, *args[1:]]
if module in [BottleneckCSP, BottleneckCSP2, SPPCSP]:
args.insert(2, number)
number = 1
elif module is Concat:
channel_out = sum([channel_in_list[-1 if i == -1 else i+1] for i in origin])
elif module is Detect:
channel_in = [channel_in_list[i+1] for i in origin]
args.append(channel_in)
else:
channel_out = channel_in_list[origin]
# input channel number list
channel_in_list.append(channel_out)
# --------------------------------------------------------------------------------------------------------------
# instantiation module according to depth gain number
module_ = nn.Sequential(*[module(*args) for _ in range(number)]) if number > 1 else module(*args)
# --------------------------------------------------------------------------------------------------------------
# module type "" -> 'Conv'
module_type = str(module)[8:-2].replace('__main__.', '')
# Returns the total number of parameters in module_
module_number_params = sum([x.numel() for x in module_.parameters()])
# attach index, origin index, type, number params
module_.index, module_.from_which_layer, module_.type, module_.number_params = \
i, origin, module_type, module_number_params
print('%3s%18s%3s%10.0f %-40s%-30s' % (i, origin, number, module_number_params, module_type, args)) # print
# --------------------------------------------------------------------------------------------------------------
input_not_from_last_layer.extend(x % i for x in ([origin] if isinstance(origin, int) else origin) if x != -1)
module_blocks.append(module_)
model = nn.Sequential(*module_blocks)
return model, sorted(input_not_from_last_layer)
4. Model() 成员介绍
(1)这里关于 self._initialize_biases()中对Detect()的bias 初始化的数学原理不明白,如果有大神看到可以指点我一下!!!
(2) 这里关于pytorch 中的thop.profile计算模型复杂度FLOPs有话要说
首先是FLOPS,FLOPs,MACs几个基本概念介绍:
FLOPS 是“每秒所执行的浮点运算次数”(floating-point operations per second)的缩写。它常被用来估算电脑的执行效能,尤其是在使用到大量浮点运算的科学计算领域中。
FLOPs:注意s小写,是floating point operations的缩写(s表复数),意指浮点运算数,理解为计算量。可以用来衡量算法/模型的复杂度。
MACs(Multiply–Accumulate Operations):乘加累积操作数,常常被人们与FLOPs概念混淆实际上1MACs包含一个乘法操作与一个加法操作,大约包含2FLOPs。
所以在物理上1 MACs相当于2FLOPs,实际上在计算数值上1FLOPs = 2 MACs,
但是profile的返回值第一项是macs,所以如果大家统计的是FLOPs一定要再乘以2才是正确结果。*
更多细节可参考这里: https://zhuanlan.zhihu.com/p/364543528
class Model(nn.Module):
# model, input channels, number of classes
def __init__(self, cfg='models/yolov4s-mish.yaml', channel_in=3, number_class=15):
super(Model, self).__init__()
# --------------------------------------------------------------------------------------------------------------
# input model .yaml
if isinstance(cfg, dict):
self.model_yaml = cfg
else:
import yaml
with open(cfg) as file:
self.model_yaml = yaml.load(file, Loader=yaml.FullLoader)
# --------------------------------------------------------------------------------------------------------------
# Define model
if number_class and number_class != self.model_yaml['number_class']:
print('Overriding %s nc=%g with nc=%g' % (cfg, self.model_yaml['number_class'], number_class))
self.model_yaml['number_class'] = number_class # override yaml value
self.model, self.input_not_from_last_layer = parse_model(self.model_yaml, [channel_in])
# --------------------------------------------------------------------------------------------------------------
# Build strides, anchors in Detect()
detect = self.model[-1]
if isinstance(detect, Detect):
s = 128
detect.stride = torch.tensor([s/x.shape[-2] for x in self.forward(torch.zeros(1, 3, s, s))])
# mapping anchors (h,w) to detecton layer
detect.anchors /= detect.stride.view(-1, 1, 1)
check_anchor_order(detect)
self.stride = detect.stride
self._initialize_biases()
# --------------------------------------------------------------------------------------------------------------
# Init weights, biases
torch_utils.initialize_weights(self)
self.info()
def _initialize_biases(self, cf=None): # initialize biases into Detect(), cf is class frequency
# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1.
m = self.model[-1] # Detect() module
for modle_i, stride in zip(m.detect_model, m.stride): # from
bias = modle_i.bias.view(m.number_anchor_per_pixel, -1) # conv.bias(255) to (3,85)
bias[:, 4] += math.log(8 / (640 / stride) ** 2) # obj (8 objects per 640 image)
bias[:, 5:] += math.log(0.6 / (m.number_class - 0.99)) if cf is None else torch.log(cf / cf.sum()) # cls
modle_i.bias = torch.nn.Parameter(bias.view(-1), requires_grad=True)
def info(self): # print model information
torch_utils.model_info(self)
def model_info(model, verbose=False, imgsz=1024, device='0'):
device = select_device(device)
# Plots a line-by-line description of a PyTorch model
n_p = sum(x.numel() for x in model.parameters()) # number parameters
n_g = sum(x.numel() for x in model.parameters() if x.requires_grad) # number gradients
if verbose:
print('%5s %40s %9s %12s %20s %10s %10s' % ('layer', 'name', 'gradient', 'parameters', 'shape', 'mu', 'sigma'))
for i, (name, p) in enumerate(model.named_parameters()):
name = name.replace('module_list.', '')
print('%5g %40s %9s %12g %20s %10.3g %10.3g' %
(i, name, p.requires_grad, p.numel(), list(p.shape), p.mean(), p.std()))
try: # FLOPS
from thop import profile
# FLOPs floating point operations
# macs,params=profile(model, inputs=(input, ), custom_ops={YourModule: count_your_model})
# 1MACs contains 2FLOPs, so FLOPs = 2*macs https://zhuanlan.zhihu.com/p/364543528
flops = profile(deepcopy(model), inputs=(torch.zeros(1, 3, imgsz, imgsz).to(device),), verbose=verbose)[0] / 1E9 * 2
fs = ', %.1f GFLOPS_%dx%d' % (flops, imgsz, imgsz) # FLOPS
except:
fs = ''
print('Model Summary: %g layers, %g parameters, %g gradients%s' % (len(list(model.parameters())), n_p, n_g, fs))
5. Model() forward部分
class Model(nn.Module):
# model, input channels, number of classes
def __init__(self, cfg='models/yolov4s-mish.yaml', channel_in=3, number_class=15):
super(Model, self).__init__()
pass
def forward(self, x):
# y is used to save input of route, Concat, Detect
y = []
for m in self.model:
# input of layer is not from previous layer, change x
if m.from_which_layer != -1:
# int: input of route, Conv(after BottleneckCSP2, stride=2),
# [...]: input of Concat, Detect
x = y[m.from_which_layer] if isinstance(m.from_which_layer, int) \
else [x if i == -1 else y[i] for i in m.from_which_layer]
# forward
x = m(x)
# add index in input_not_from_last_layer to y
y.append(x if m.index in self.input_not_from_last_layer else None)
return x
def set_mish(self, mish_cuda=True):
# Sets mish function as mish_cuda (for training) or Mish (for export).
for m in self.model:
if isinstance(m, (Conv, Bottleneck, BottleneckCSP, BottleneckCSP2, SPPCSP)):
# print(m)
m.set_mish(mish_cuda)
6. Detect() forward部分
(1) 关于xywh偏移的问题
yolov3中,输出公式如下,tx,ty为 预测框 在x,y方向上相对于anchor的偏移量, tw,th为预测框相对anchor的w.h的比例因子, cx,cy,pw,ph分别表示anchor的中心点坐标和宽高。


但是在yolov4_u5中 输出公式如下:
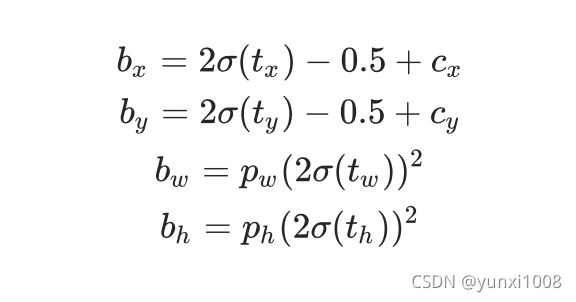
这里有一些数学原理无法理解,不知道为什么要这样做,随后我去查了一些资料发现yolov5作者给出了解释(传送门:https://github.com/ultralytics/yolov5/issues/471):
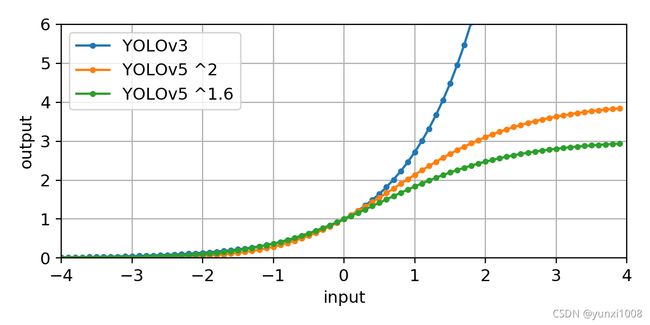
首先关于为什么乘以2再减去0.5的问题,作者解释了两点,先来看sigmoid函数:
![]()

a. 作者提到由于batchnorm的原因平均输入tx接近0,而平均的偏移量通常是grid cell的中间,也就是0.5,设计成2 * sigmoid(tx) - 0.5 符合这个特性。
b. 对于偏移量靠近0或者1的情况,输入的tx将会非常极端,造成不稳定,而2 * sigmoid(tx) - 0.5相对原来的sigmoid(tx)将值域从0-1扩大到了-0.5-1.5,对于偏移量在0或者1附近的输入的tx将不会那么极端
c. 20220721补充一下从loss计算角度解释为什么这样设置,为了扩充正样本,作者设置了对于某一个target,比如坐标为[51.3, 49.4],作者认为此target距离顶点[51, 49]不足0.5, 所以更靠近左上方,从而将左侧网格[50, 49]和上侧网格[51,48]的anchor都认为是正样本,同理如果距离大于0.5,则将右侧和下侧的anchor认为是正样本。这样target相对于新的anchor网格点坐标偏移就变成了[1.3,0.4], [0.3,1.4], 而2 * sigmoid(tx) - 0.5相对原来的sigmoid(tx)将值域从0-1扩大到了-0.5-1.5,这样预测的偏移才能和正样本相对于target的偏移取值范围相同。(具体的选取正样本的策略可以看我写的另一篇分析,yolov4_u5版复现—5. compute_loss)
然后对于宽高因子乘以2再平方的问题,
其认为yolov3中的out=exp(in)会造成runaway gradients, instabilities, NaN losses等问题,其将阈值设置到0-4可以有效的避免这些问题,另外似乎和计算损失时选择正负样本的超参数有关,这个后面再聊。
(b)20220721补充一下从loss计算角度解释为什么这样设置,因为在选取正负样本时,对正样本的要求是和target的宽高比例要小于4,而这里正好可以可以将预测的宽高比例提升四倍,从而和正样本与target的宽高比例范围一致。
(2)关于mesh_grid 纵横坐标的问题
anchor的中心点设置在网格点上,所以需要使用格网点表示anchor 的 cx,cy
pytorch的meshgrid输入是先y,后x,即先高,后宽,这样得出的y_,x_才能合理的表示特征图的h,w,这里有个很容易弄反的问题,就是 生成最终的格网点坐标时: torch.stack((x_, y_), dim=2)为什么 又反过来把x_放在前面,这里是因为
x[i][…, 0:2] = x[i][…, 0:2] * 2 - 0.5 + self.grid[i] * self.stride[i] # xy
中网络的输出保存坐标的顺序是(xywh),所以x_放在前边就是为了对应x,y的先后顺序。
顺便提一句self.grid[i] * self.stride[i]是为了把特征图格网点影射回输入图像坐标系。
def _meshgrid(nx, ny):
# torch.meshgrid:h first, w second.
y_, x_ = torch.meshgrid(torch.arange(ny), torch.arange(nx))
# the output of network is (x,y,w,h,score,class), so should stack x_ first, y_ second.
return torch.stack((x_, y_), dim=2).view(1, 1, ny, nx, 2)
class Detect(nn.Module):
def __init__(self, number_class, anchors=(), channel_in=()):
super(Detect, self).__init__()
pass
def forward(self, x):
self.training |= self.export
# inference output
y = []
for i in range(self.number_detection_layer):
# ----------------------------------------------------------------------------------------------------------
# forward
x[i] = self.detect_model[i](x[i])
bs, _, ny, nx = x[i].shape
x[i] = x[i].view(bs, self.number_anchor_per_pixel, self.number_output_per_anchor, ny, nx)\
.permute(0, 1, 3, 4, 2).contiguous()
# ----------------------------------------------------------------------------------------------------------
# inference
if not self.training:
# grid coordinate, [1,1,ny,nx,[grid_x,grid_y]]
self.grid[i] = self._meshgrid(nx, ny).to(x[i].device)
x[i] = torch.sigmoid(x[i])
x[i][..., 0:2] = x[i][..., 0:2] * 2 - 0.5 + self.grid[i] * self.stride[i] # xy
x[i][..., 2:4] = (x[i][..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
y.append(x[i].view(bs, -1, self.number_output_per_anchor))
# ----------------------------------------------------------------------------------------------------------
return x if self.training else [torch.cat(y, dim=1), x]
@staticmethod
def _meshgrid(nx, ny):
# torch.meshgrid:h first, w second.
y_, x_ = torch.meshgrid(torch.arange(ny), torch.arange(nx))
# the output of network is (x,y,w,h,score,class), so should stack x_ first, y_ second.
return torch.stack((x_, y_), dim=2).view(1, 1, ny, nx, 2)