【搜索/推荐排序】FM,FFM,AFM,PNN,DeepFM:进行CTR和CVR预估
文章目录
- 1.FM
-
- 1.1代码-是否点击预测
-
- 效果和参数量级
- 1.3 和其他模型的比较
-
- SVM
- MF
- 2. FFM
-
- one-hot的比较
- eg
- 训练注意事项
-
- 效果和参数量级
- 实现
- 3. AFM
- 4.FNN/PNN
-
- 4.1 FNN
- 4.2 PNN
- 5. DeepFM
-
- 与Wide&Deep比较
- 与NFM
- FM 本来就可以在稀疏输入的场景中进行学习,为什么要跟 Deep 共享稠密输入?
用于:进行CTR和CVR预估
点击率CTR(click-through rate)和转化率CVR(conversion rate)
特征的选择:
离散or连续
1.FM
用处:用于是否点击预测、评分
优点:数据稀疏也可用
对于每个二阶组合特征的权重,是根据对应两个特征的Embedding向量内积,来作为这个组合特征重要性的指示。当训练好FM模型后,每个特征都可以学会一个特征embedding向量
介绍
code
一个例子
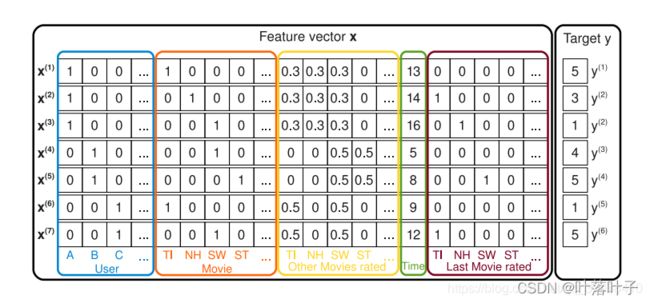

wij分解为v:减少参数量,使训练更容易,这是矩阵分解的思路
v是特征的向量
交叉特征

其中f/k:是v的size,n是特征的个数
1.1代码-是否点击预测
vx:使用embedding实现
wx:也用embedding实现
class FactorizationMachineModel(torch.nn.Module):
"""
A pytorch implementation of Factorization Machine.
Reference:
S Rendle, Factorization Machines, 2010.
"""
def __init__(self, field_dims, embed_dim):
super().__init__()
self.embedding = FeaturesEmbedding(field_dims, embed_dim)
self.linear = FeaturesLinear(field_dims)
self.fm = FactorizationMachine(reduce_sum=True)
def forward(self, x):
"""
:param x: Long tensor of size ``(batch_size, num_fields)``
"""
x = self.linear(x) + self.fm(self.embedding(x))
# (batch_size, 1) + (batch_size, 1)
# sigmoid:二分类,是/否点击
return torch.sigmoid(x.squeeze(1))
vx:
class FeaturesEmbedding(torch.nn.Module):
def __init__(self, field_dims, embed_dim):
super().__init__()
# print(field_dims, embed_dim)
"""
对于MovieLens而言,只有两种特征,用户,电影
所以field_dims = [用户数n,电影数k],是每种特征的维度的列表
加个offset,embedding :0-n代表用户特征,n-n+k代表电影特征
"""
self.embedding = torch.nn.Embedding(sum(field_dims), embed_dim)
# print(self.embedding)
self.offsets = np.array((0, *np.cumsum(field_dims)[:-1]), dtype=np.long)
# print(self.offsets)
torch.nn.init.xavier_uniform_(self.embedding.weight.data)
def forward(self, x):
"""
:param x: Long tensor of size ``(batch_size, num_fields)``
return ``(batch_size, num_fields, embed_size)``
"""
x = x + x.new_tensor(self.offsets).unsqueeze(0)
# print(x.shape, self.embedding(x).shape)
return self.embedding(x)
wx:
class FeaturesLinear(torch.nn.Module):
def __init__(self, field_dims, output_dim=1):
"""
从特征向量直接映射到embedding,相当于做了次linear
"""
super().__init__()
self.fc = torch.nn.Embedding(sum(field_dims), output_dim)
# print(self.fc)
self.bias = torch.nn.Parameter(torch.zeros((output_dim,)))
self.offsets = np.array((0, *np.cumsum(field_dims)[:-1]), dtype=np.long)
def forward(self, x):
"""
:param x: Long tensor of size ``(batch_size, num_fields)``
return ``(batch_size, num_fields, output_dim)``
"""
x = x + x.new_tensor(self.offsets).unsqueeze(0)
# print(self.fc(x).shape, torch.sum(self.fc(x), dim=1).shape)
return torch.sum(self.fc(x), dim=1) + self.bias

因子:和的平方-平方的和
class FactorizationMachine(torch.nn.Module):
def __init__(self, reduce_sum=True):
super().__init__()
self.reduce_sum = reduce_sum
def forward(self, x):
"""
:param x: Float tensor of size ``(batch_size, num_fields, embed_dim)``
"""
square_of_sum = torch.sum(x, dim=1) ** 2 # (batch_size, embed_dim)
sum_of_square = torch.sum(x ** 2, dim=1) # (batch_size, embed_dim)
ix = square_of_sum - sum_of_square # (batch_size, embed_dim)
if self.reduce_sum:
ix = torch.sum(ix, dim=1, keepdim=True) # (batch_size, 1)
return 0.5 * ix
效果和参数量级
MovieLens:
k=16
n=6040+3952(用户数加电影数)
epoch=31,test auc: 0.8142968981785388,early stop
1.3 和其他模型的比较
SVM
相比SVM的二阶多项式核而言,FM在样本稀疏的情况下是有优势的;而且,FM的训练/预测复杂度是线性的,而二项多项式核SVM需要计算核矩阵,核矩阵复杂度就是N平方。
MF
FM:我们可以加任意多的特征,比如user的历史购买平均值,item的历史购买平均值等,
但是MF只能局限在两类特征。
SVD++与MF类似,在特征的扩展性上都不如FM
2. FFM
美团的文章
FM公式

有n*k个二次项
FFM公式
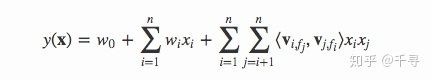
有nkf个二次项,表达能力更强
v i v_i vi-> v i , f j v_{i,f_j} vi,fj
特征的embedding->特征i对特征j的场,每个特征有多个场(向量?),每个特征都有一个特征矩阵
优点:参数多,表达能力强
缺点:复杂度高,笨重,容易过拟合
复杂度:相对于n而言都是线性的
简化公式:

FFM模型作为排序模型,效果确实是要优于FM模型的,但是FFM模型对参数存储量要求太多,以及无法能做到FM的运行效率,如果中小数据规模做排序没什么问题,但是数据量一旦大起来,对资源和效率的要求会急剧升高,这是严重阻碍FFM模型大规模数据场景实用化的重要因素。
纯结构化数据还是不适合深度学习,LSTM和CNN做分类还是不太好。
解决过拟合:早停,选较小的k。
一般在几千万训练数据规模下,k取8到10能取得较好的效果
one-hot的比较
FM:

FFM:
“Day=26/11/15”、“Day=1/7/14”、“Day=19/2/15”这三个特征都是代表日期的,可以放到同一个field中
Coutry:一个field
Ad_type一个field
共有3个field
上面共有n=7个特征,共属于3个field(f=3)
eg
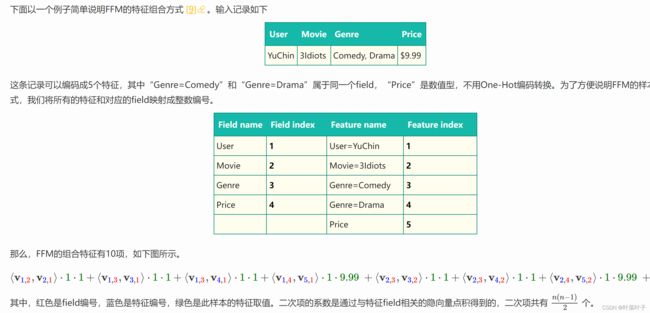
值为1:存在该特征
值为9.99:价格等于9.99
训练注意事项
在训练FFM的过程中,有许多小细节值得特别关注。
第一,样本归一化。FFM默认是进行样本数据的归一化,即 pa.norm 为真;若此参数设置为假,很容易造成数据inf溢出,进而引起梯度计算的nan错误。因此,样本层面的数据是推荐进行归一化的。
第二,特征归一化。CTR/CVR模型采用了多种类型的源特征,包括数值型和categorical类型等。但是,categorical类编码后的特征取值只有0或1,较大的数值型特征会造成样本归一化后categorical类生成特征的值非常小,没有区分性。例如,一条用户-商品记录,用户为“男”性,商品的销量是5000个(假设其它特征的值为零),那么归一化后特征“sex=male”(性别为男)的值略小于0.0002,而“volume”(销量)的值近似为1。特征“sex=male”在这个样本中的作用几乎可以忽略不计,这是相当不合理的。因此,将源数值型特征的值归一化到 [0,1] 是非常必要的。
第三,省略零值特征。从FFM模型的表达式(4)可以看出,零值特征对模型完全没有贡献。包含零值特征的一次项和组合项均为零,对于训练模型参数或者目标值预估是没有作用的。因此,可以省去零值特征,提高FFM模型训练和预测的速度,这也是稀疏样本采用FFM的显著优势。
本文主要介绍了FFM的思路来源和理论原理,并结合源码说明FFM的实际应用和一些小细节。从理论上分析,FFM的参数因子化方式具有一些显著的优势,特别适合处理样本稀疏性问题,且确保了较好的性能;从应用结果来看,站内CTR/CVR预估采用FFM是非常合理的,各项指标都说明了FFM在点击率预估方面的卓越表现。当然,FFM不一定适用于所有场景且具有超越其他模型的性能,合适的应用场景才能成就FFM的“威名”。
效果和参数量级
MovieLens
k=4
f=2
n=6040+3952(用户数加电影数)
epoch=99,test auc: 0.8083788345826268
实现
class FieldAwareFactorizationMachine(torch.nn.Module):
def __init__(self, field_dims, embed_dim):
super().__init__()
print(field_dims, embed_dim)
self.num_fields = len(field_dims)
# n*(f=num_fields)个特征向量
self.embeddings = torch.nn.ModuleList([
torch.nn.Embedding(sum(field_dims), embed_dim) for _ in range(self.num_fields)
])
self.offsets = np.array((0, *np.cumsum(field_dims)[:-1]), dtype=np.long)
for embedding in self.embeddings:
torch.nn.init.xavier_uniform_(embedding.weight.data)
def forward(self, x):
"""
:param x: Long tensor of size ``(batch_size, num_fields)``
"""
x = x + x.new_tensor(self.offsets).unsqueeze(0)
# print(x.shape)
xs = [self.embeddings[i](x) for i in range(self.num_fields)]
# xs=[(batch_size, num_fields, embed_dim),...]
ix = list()
for i in range(self.num_fields - 1):
for j in range(i + 1, self.num_fields):
ix.append(xs[j][:, i] * xs[i][:, j])
ix = torch.stack(ix, dim=1) # (batch_size, 1, embed_dim)
return ix
class FieldAwareFactorizationMachineModel(torch.nn.Module):
"""
A pytorch implementation of Field-aware Factorization Machine.
Reference:
Y Juan, et al. Field-aware Factorization Machines for CTR Prediction, 2015.
"""
def __init__(self, field_dims, embed_dim):
super().__init__()
self.linear = FeaturesLinear(field_dims)
self.ffm = FieldAwareFactorizationMachine(field_dims, embed_dim)
def forward(self, x):
"""
:param x: Long tensor of size ``(batch_size, num_fields)``
"""
ffm_term = torch.sum(torch.sum(self.ffm(x), dim=1), dim=1, keepdim=True)
# print(torch.sum(self.ffm(x), dim=1).shape, ffm_term.shape)
# (batch_size, emb_dim), (batch_size, 1)
x = self.linear(x) + ffm_term
return torch.sigmoid(x.squeeze(1))
3. AFM
AFM:Attentional FM
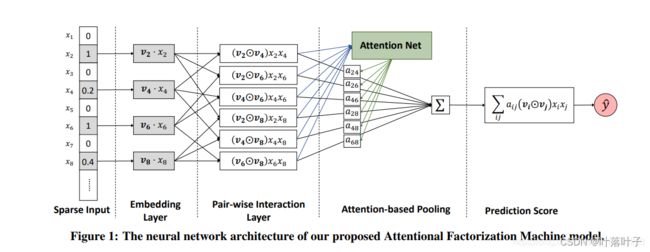

AttentionalFactorizationMachineModel(field_dims, embed_dim=16, attn_size=16, dropouts=(0.2, 0.2))
AttentionalFactorizationMachineModel = Linear+AttentionalFactorizationMachine
内积部分:
class AttentionalFactorizationMachine(torch.nn.Module):
def __init__(self, embed_dim, attn_size, dropouts):
print(embed_dim, attn_size, dropouts)
super().__init__()
self.attention = torch.nn.Linear(embed_dim, attn_size)
self.projection = torch.nn.Linear(attn_size, 1)
self.fc = torch.nn.Linear(embed_dim, 1)
self.dropouts = dropouts
def forward(self, x):
"""
:param x: Float tensor of size ``(batch_size, num_fields, embed_dim)``
"""
print(x.shape)
num_fields = x.shape[1]
row, col = list(), list()
for i in range(num_fields - 1):
for j in range(i + 1, num_fields):
row.append(i), col.append(j)
p, q = x[:, row], x[:, col]
inner_product = p * q # (batch_size, num_fields*(num_fields-1)/2=1, embed_dim)
# self-attention
attn_scores = F.relu(self.attention(inner_product)) # (batch_size, num_fields*(num_fields-1)/2=1, attn_size)
# print(attn_scores.shape)
attn_scores = F.softmax(self.projection(attn_scores), dim=1)# (batch_size, num_fields*(num_fields-1)/2=1, 1)
attn_scores = F.dropout(attn_scores, p=self.dropouts[0], training=self.training)
# 给每个内积一个权重,加权求和
attn_output = torch.sum(attn_scores * inner_product, dim=1)
# sum((batch_size, num_fields*(num_fields-1)/2=1, 1) * (batch_size, num_fields*(num_fields-1)/2=1, embed_dim))
# =(batch_size, embed_dim)
# print(attn_output.shape)
attn_output = F.dropout(attn_output, p=self.dropouts[1], training=self.training)
return self.fc(attn_output)# =(batch_size, 1)
4.FNN/PNN
缺点:对于低阶的组合特征,学习到的比较少。而前面我们说过,低阶特征对于CTR也是非常重要的。
4.1 FNN
先使用预先训练好的FM,得到隐向量,然后作为DNN的输入来训练模型。
缺点在于:受限于FM预训练的效果。
4.2 PNN
PNN
PNN为了捕获高阶组合特征,在embedding layer和first hidden layer之间增加了一个product layer。根据product layer使用内积、外积、混合分别衍生出IPNN, OPNN, PNN*三种类型。

对每一个item,拼接上交叉特征,获得新的特征
class ProductNeuralNetworkModel(torch.nn.Module):
"""
A pytorch implementation of inner/outer Product Neural Network.
Reference:
Y Qu, et al. Product-based Neural Networks for User Response Prediction, 2016.
"""
def __init__(self, field_dims, embed_dim, mlp_dims, dropout, method='inner'):
super().__init__()
num_fields = len(field_dims)
if method == 'inner':
self.pn = InnerProductNetwork()
elif method == 'outer':
self.pn = OuterProductNetwork(num_fields, embed_dim)
else:
raise ValueError('unknown product type: ' + method)
self.embedding = FeaturesEmbedding(field_dims, embed_dim)
self.linear = FeaturesLinear(field_dims, embed_dim)
self.embed_output_dim = num_fields * embed_dim
self.mlp = MultiLayerPerceptron(num_fields * (num_fields - 1) // 2 + self.embed_output_dim, mlp_dims, dropout)
def forward(self, x):
"""
:param x: Long tensor of size ``(batch_size, num_fields)``
"""
embed_x = self.embedding(x) # (batch_size, num_fields=2, embed_dim)
cross_term = self.pn(embed_x) # (batch_size, num_fields*(num_fields-1)/2=1)
x = torch.cat([embed_x.view(-1, self.embed_output_dim), cross_term], dim=1)
# 内积:(batch_size, num_fields * embed_dim+1(product=num_fields*(num_fields-1)/2))
x = self.mlp(x)
return torch.sigmoid(x.squeeze(1))
F M ( x ) = w 0 + ∑ i = 1 n w i x i + ∑ i = 1 n − 1 ∑ j = i + 1 n < v i , v j > x i x j FM(x)=w_0 + \sum_{i=1}^nw_ix_i+\sum_{i=1}^{n-1}\sum_{j=i+1}^n
F F M ( x ) = w 0 + ∑ i = 1 n w i x i + ∑ i = 1 n − 1 ∑ j = i + 1 n < v i , f j , v j , f i > x i x j FFM(x)=w_0 + \sum_{i=1}^nw_ix_i+\sum_{i=1}^{n-1}\sum_{j=i+1}^n
A F M ( x ) = w 0 + ∑ i = 1 n w i x i + P T ∑ i = 1 n − 1 ∑ j = i + 1 n a i j < v i , v j > x i x j AFM(x)=w_0 + \sum_{i=1}^nw_ix_i+P^T\sum_{i=1}^{n-1}\sum_{j=i+1}^na_{ij}
F N N ( x ) = m l p ( l z ) , l z = e m b e d ( x ) , e m b e d FNN(x)=mlp(l_z),l_z=embed(x),embed FNN(x)=mlp(lz),lz=embed(x),embed
P N N ( x ) = m l p ( l z + l p ) , l z = e m b e d ( x ) , l p = 内 积 或 外 积 PNN(x)=mlp(l_z+l_p),l_z=embed(x),l_p=内积或外积 PNN(x)=mlp(lz+lp),lz=embed(x),lp=内积或外积
num_fields = x.shape[1]
row, col = list(), list()
for i in range(num_fields - 1):
for j in range(i + 1, num_fields):
row.append(i), col.append(j)
内积:
torch.sum(x[:, row] * x[:, col], dim=2)
外积
class OuterProductNetwork(torch.nn.Module):
def __init__(self, num_fields, embed_dim, kernel_type='mat'):
super().__init__()
num_ix = num_fields * (num_fields - 1) // 2
if kernel_type == 'mat':
kernel_shape = embed_dim, num_ix, embed_dim
elif kernel_type == 'vec':
kernel_shape = num_ix, embed_dim
elif kernel_type == 'num':
kernel_shape = num_ix, 1
else:
raise ValueError('unknown kernel type: ' + kernel_type)
self.kernel_type = kernel_type
self.kernel = torch.nn.Parameter(torch.zeros(kernel_shape))
torch.nn.init.xavier_uniform_(self.kernel.data)
def forward(self, x):
"""
:param x: Float tensor of size ``(batch_size, num_fields, embed_dim)``
"""
num_fields = x.shape[1]
row, col = list(), list()
for i in range(num_fields - 1):
for j in range(i + 1, num_fields):
row.append(i), col.append(j)
p, q = x[:, row], x[:, col]
if self.kernel_type == 'mat':
kp = torch.sum(p.unsqueeze(1) * self.kernel, dim=-1).permute(0, 2, 1)
return torch.sum(kp * q, -1)
else:
return torch.sum(p * q * self.kernel.unsqueeze(0), -1)
5. DeepFM
DeepFM
https://www.cnblogs.com/xiaoqi/p/deepfm.html
https://zhuanlan.zhihu.com/p/35465875
优点:
- 不需要预训练FM得到隐向量
- 不需要人工特征工程
- 能同时学习低阶和高阶的组合特征
FM模块和Deep模块共享Feature Embedding部分,可以更快的训练,以及更精确的训练学习
缺点:
1 将类别特征对应的稠密向量拼接作为输入,然后对元素进行两两交叉。这样导致模型无法意识到域的概念,FM 与 Deep 两部分都不会考虑到域,属于同一个域的元素应该对应同样的计算

class DeepFactorizationMachineModel(torch.nn.Module):
"""
A pytorch implementation of DeepFM.
Reference:
H Guo, et al. DeepFM: A Factorization-Machine based Neural Network for CTR Prediction, 2017.
"""
def __init__(self, field_dims, embed_dim, mlp_dims, dropout):
super().__init__()
self.linear = FeaturesLinear(field_dims)
self.fm = FactorizationMachine(reduce_sum=True)
self.embedding = FeaturesEmbedding(field_dims, embed_dim)
self.embed_output_dim = len(field_dims) * embed_dim
self.mlp = MultiLayerPerceptron(self.embed_output_dim, mlp_dims, dropout)
def forward(self, x):
"""
:param x: Long tensor of size ``(batch_size, num_fields)``
"""
embed_x = self.embedding(x)
x = self.linear(x) + self.fm(embed_x) + self.mlp(embed_x.view(-1, self.embed_output_dim))
return torch.sigmoid(x.squeeze(1))
与Wide&Deep比较
与 Wide&Deep 的异同:
相同点:都是线性模型与深度模型的结合,低阶与高阶特征交互的融合。
不同点:
- 输入:DeepFM 两个部分共享输入,而 Wide&Deep 的 wide 侧是稀疏输入,deep 侧是稠密输入;
- 人工特征:DeepFM 无需加入人工特征,可端到端的学习,线上部署更方便,Wide&Deep 则需要在输入上加入人工特征提升模型表达能力。
与NFM
DFM:并行
NFM:串行
FM 本来就可以在稀疏输入的场景中进行学习,为什么要跟 Deep 共享稠密输入?
虽然 FM 具有线性复杂度 [公式] ,其中 [公式] 为特征数, [公式] 为隐向量维度,可以随着输入的特征数线性增长。但是经过 onehot 处理的类别特征维度往往要比稠密向量高上一两个数量级,这样还是会给 FM 侧引入大量冗余的计算,不可取。