(虚拟环境py3)基于ros实现mask-rcnn,启动摄像头,并输出预测的可视化结果,全步骤记录
第一次发文章,我们实验室和Framatome合作开发的一个核废料分炼机器人,我要做的是unknown objects segmentation,现在要sd-mask_rcnn的算法移植到ros平台上运行,但无奈没有现有的sd-mask_rcnn_ros节点可以直接git,需要我自己写。因为本人coding的经验缺少,我只能仿照mask_rcnn_ros节点,去试着写sd-mask_rcnn_ros节点,所以把mask_rcnn_ros给复现了一下,好废话结束,以下切题。
(保姆教程)记录全部步骤,重要解决几个问题:1. mask_rcnn_ros的节点环境配置;2. 解决cv_bridge在conda的python3环境的兼容问题;3. 连接摄像头(以usb cam为例),输出预测的可视化结果。(以下步骤最好要挂上)
我的配置:ubuntu 18.04, ros melodic, cuda10.0, cudnn7.6.x,conda的python3.7环境(由miniconda3所建)
1. mask_rcnn_ros节点环境配置
1.1 创建conda环境 conda create -n tf1.15 python=3.7,并激活环境tf1.15,如下步骤都在conda环境中进行
1.2 建立一个工作空间 mkdir ws_test, 再cd ws_test(根空间)
1.3 git clone https://github.com/qixuxiang/mask_rcnn_ros.git src/mask_rcnn_ros
1.4 cd src/mask_rcnn_ros
1.5 安装环境包,亦可逐个安装pip install xxx
!!!更改原作者的requirements.txt的环境包版本再pip install,就这么改:
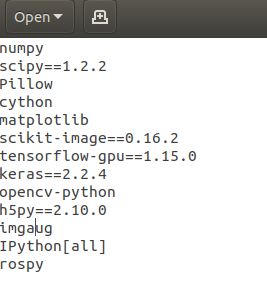
更改后继续 :
pip install -r requirements.txt
#如果网络问题,延长抓包时间 比如 pip --default-timeout=1000 install h5py==2.10.0
1.6 根空间编译+source
cd ws_test
catkin_make
source devel/setup.bash
1.7 cd src/mask_rcnn_ros/nodes, 修改mask_rcnn_node的 class InferenceConfig,添加GPU_COUNT = 1 ,IMAGES_PER_GPU = 1, IMAGE_MIN_DIM = 320,和 IMAGE_MAX_DIM = 448
1.8 在 /mask_rcnn_ros/nodes/visualize.py 中的 indigo 修改为 melodic
sys.path.remove('/opt/ros/melodic/lib/python2.7/dist-packages') #修改后
1.9 安装rospkg
pip install setuptools
pip install -U rosdep rosinstall_generator wstool rosinstall six vcstools
1.10 另打开一个终端启动roscore,而现有终端 在根空间rosrun mask_rcnn_ros mask_rcnn_node运行后 看有没有报错,正常情况下没报错,能加载tensorflow,也能输出config配置,能调用visualize.py,但因为没启动摄像头的节点和实时画面作为输入,不会有任何输出结果,到这一步rosrun没有报错即可, ok了后ctrl+c中断。
break!!能启动rosrun后我们跳出第1.10,先跳到 2.1解决cv_bridge的问题
1.11 自2.5后,激活tf1.15环境,现在可以跑该节点的一个案例,第二步是下载一个1.6G大小的rosbag包
cd ~/ws_test/src/mask_rcnn_ros/scripts
sh download_freiburg3_rgbd_example_bag.sh
再将这个包移动到/mask_rcnn_ros/bags中
cd ws_test
roslaunch mask_rcnn_ros freiburg3_rgbd_example.launch
在跑roslaunch的时候 ,可能会出现如下报错:
<1> 出现在visualize.py的cv2.findContours()报错 ValueError: not enough values to unpack (expected 3, got 2),解决方案为 :_, contours, _ = cv2.findContours 改为 contours, _ = cv2.findContours ;
参考 https://github.com/facebookresearch/maskrcnn-benchmark/issues/339
<2>比如出现报错AttribueError: module 'keras.engine.topology' has no attribute ' load_weights_from_hdf5_group_by_name',解决方案为:pip/conda安装的keras版本<=2.1.6则不会出现这个错误,或者 把model.py的3处topology改为saving就能解决(因为keras在2.2版本时候topology已经被弃用了)
再看是否还有其他报错,一般正常就能跑了。
2. 解决cv_bridge在conda环境的python3中不兼容的问题
(如果cv_bridge在本地py3中运行的教程,去看别人的教程,csdn上有几篇解释,包括stack overflow的这篇,虽然这篇文章的第二个回答错误的,但虚拟的python3中编译cv_bridge是可行的)这里我耗了点时间。
好继续,说一下原因,因在cv_bridge只能在py2中编译,而我们的mask_rcnn_node节点需要在conda的py3环境中运行,而ros却安装在py2的本地环境中,也默认下载了cv_bridge。但conda环境中找不到任何cv_bridge的pip包和conda包,所以无法py3无法编译cv_bridge。只能采取“特殊”方式:
2.1 自步骤1.10, conda deactivate退出任何conda的环境,包括base环境,只在本地的py3环境中,执行
sudo apt-get install python-catkin-tools python3-dev python3-catkin-pkg-modules python3-numpy python3-yaml ros-melodic-cv-bridge
2.2 建立另一个根空间ws_cvbridge,配置catkin config后 再clone cv_bridge的包, 最后编译
(我本地是python3.6.9)
mkdir ws_cvbridge
cd ws_cvbridge
catkin init #编译初始化
catkin config -DPYTHON_EXECUTABLE=/usr/bin/python3 -DPYTHON_INCLUDE_DIR=/usr/include/python3.6m -DPYTHON_LIBRARY=/usr/lib/x86_64-linux-gnu/libpython3.6m.so #配置cmake的路径到本地的py3上
catkin config --install #编译的配置放在install文件中
git clone https://github.com/ros-perception/vision_opencv.git src/vision_opencv #克隆vision opencv到src
catkin build cv_bridge #不用catkin_make原因在于我们只要编译里面的cv_bridge
source install/setup.bash
在编译cv_bridge的时候,如果出现报错:
Could not find the following Boost libraries:
boost_python37
解决方法:(这里给了一个软连接,我这里是用py36链接了boost python37
cd /usr/lib/x86_64-linux-gnu
sudo ln -s libboost_python-py36.so libboost_python37.so #建立动态库软链接
sudo ln -s libboost_python-py36.a libboost_python37.a #建立精态库软链接参考于: Could not find the following Boost libraries: boost_python3 - ROS Answers: Open Source Q&A Forum
2.3 我们再回到之前的根空间ws_test (注意不要切换终端 或者重开一个终端),借用ws_cvbridge的install里面的编译配置
cd ws_test
source devel/setup.bash --extend # extend表示借用(扩展),用个功能借用的同时也不覆盖之前本身catkin_make的source路径
2.4 借完cv_bridge配置路径后 做一次验证 本地敲入python3,(這個時候你conda激活tf1.15環境,敲入py3,發現也能使用cv bridge了)
python3
>>> from cv_bridge.boost.cv_bridge_boost import getCvType
>>> #没有报错 说明本地py3已能编译cv bridge了
(注意 这个--extend配置借用是暂时的,如果重新打开终端或者切换终端还要在使用cv_bridge,要重新回到ws_cvbridge,source install/setup.bash,再回到你现有根空间 source devel/setup.bash --extend借用)
2.5 更改mask_rcnn_node节点第一行的python路径 改为conda的py3的路径,為了在conda中運行ros節點
#!/usr/bin/env python #原来路径
#!/home/chu/miniconda3/envs/tf1.15/bin/python3 #替换为如此
break!!执行完以上步骤 跳转到1.11
3. 连接usb摄像头, 并输出可视化
3.1 git clone usb_cam节点(melodic版本)
cd ws_test/src
git clone https://github.com/ros-drivers/usb_cam.git
3.2 新建maskrcnn的launch文件,调用 话题/usb_cam/image_raw作为input
cat usb_cam/launch/usb_cam-test.launch
#发现倒数第四行:
3.3 编译mask_rcnn_ros和usb_cam节点
cd ~/ws_test
conda activate tf1.15 #激活conda的环境
catkin_make
source devel/setup.bash
3.4 启动usb_cam-test.launch和mask_rcnn_usb.launch
roscore #roscore无所谓是不是在conda环境中
#打开另1个终端
cd ~/ws_test
roslaunch usb_cam usb_cam-test.launch #启动usb cam节点
#再打开另2个终端
conda activate tf1.15 #激活conda的环境
cd ~/ws_cvbridge
source install/setup.bash
cd ~/ws_test
source devel/setup.bash --extend #借cv_bridge的source环境
roslaunch mask_rcnn_ros mask_rcnn_usb.launch #启动maksrcnn usb节点
#再打开另3个终端
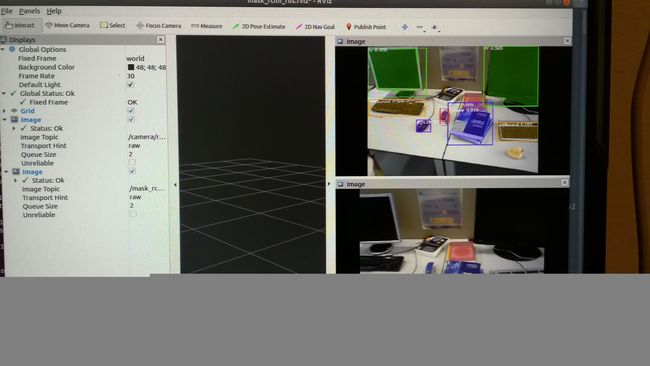
rqt #启动ros节点图和可视化窗口
正常运行的话会得到左边的节点图:

右边image View,选/mask_rcnn/visualization得到如下可视化结果:

結束了。成功復現,有問題的可以在下面留言